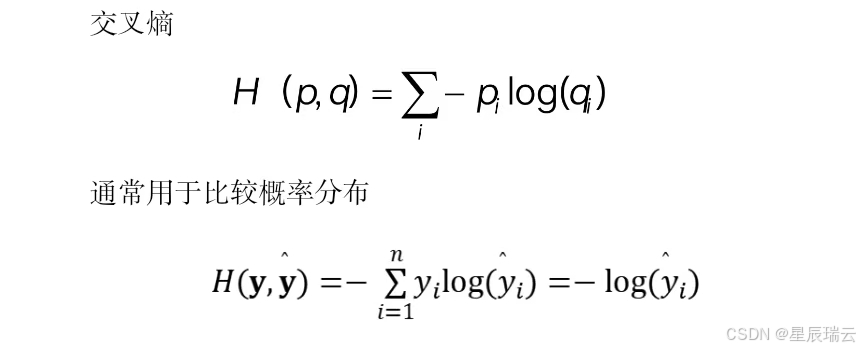机器学习
机器学习(machine learning,ML)是一类强大的可以从经验中学习的技术。通常采用观测数据或与环境交互的形式,机器学习算法会积累更多的经验,其性能也会逐步提高。
分成监督学习和无监督学习(监督学习就是告诉答案,非监督学习就是不告诉答案;差别是有无标签)
监督学习
监督学习(supervised learning)擅⻓在“给定输⼊特征”的情况下预测标签。每个“特征-标签”对都称为一个样本(example)。我们的目标是生成一个模型,能够将任何输⼊特征映射到标签(即预测)。
监督学习的学习过程:
1.回归——平方误差损失函数
回归(regression)是最简单的监督学习任务之一。——房价预测
为什么这个任务可以归类为回归问题呢?本质上是输出决定的。销售价格(即标签)是一个数值。当标签取任意数值时,我们称之为回归问题,此时的目标是生成一个模型,使它的预测非常接近实际标签值。
2.分类——交叉熵
样本属于“哪一类”的问题称为分类问题。分类问题希望模型能够预测样本属于哪个类别。

猫狗识别:二项分类
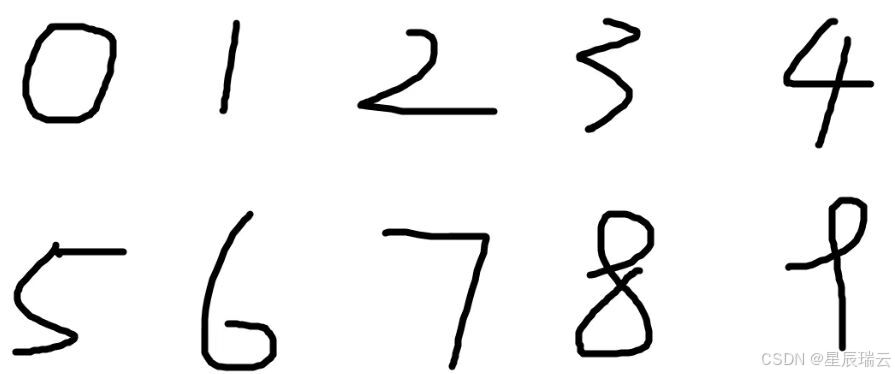
手写数字识别:多项分类
回归是训练一个回归函数来输出一个数值;分类是训练一个分类器来输出预测的类别。
3.标注问题
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)一个样本(一个图片或者一个候选框)中含有多个物体,标注的label也是多个的,多个类间并不是互斥的,多选多比如:多目标检测、短视频分类

4.推荐系统
目标是向特定用户进行“个性化”推荐。例如,对于电影推荐,科幻迷和喜剧爱好者的推荐结果页面可能会有很大不同。
5.序列问题
输入和输出都是可变长度的序列
标记和解析
自动语音识别
文本到语音
机器翻译
无监督学习
数据中不含有标签的机器学习问题。
-
聚类问题
-
主成分分析问题
-
因果关系和概率图模型
-
生成对抗网络
与环境互动
有⼈一直心存疑虑:机器学习的输入(数据)来自哪里?机器学习的输出又将去往何方?
到目前为止,不管是监督学习还是无监督学习,我们都会预先获取大量数据,然后启动模型,不再与环境交互。这⾥所有学习都是在算法与环境断开后进行的,被称为离线学习(offline learning)。
优点是,我们可以孤⽴地进行模式识别,而不必分心于其他问题。缺点是,解决的问题相当有限。
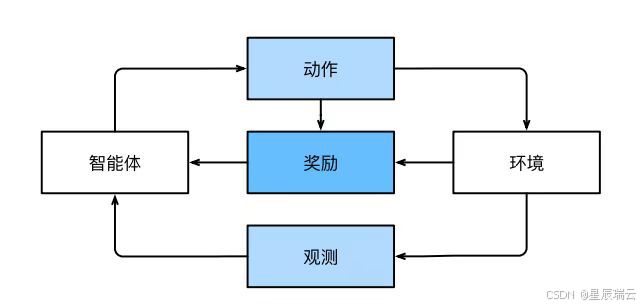
强化学习
智能体在一系列的时间步骤上与环境交互。在每个特定时间点,智能体从环境接收一些观察,并且必须选择一个动作,然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励。此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。
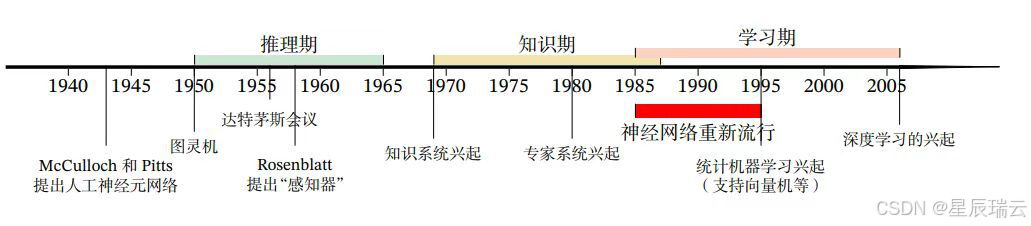
深度学习的发展
21世纪带来了高速互联网,智能手机摄像头、视频游戏等照片共享网站。数据池正在被填满。
廉价又高质量的传感器、廉价的数据存储以及廉价计算的普及,特别是GPU的普及,使大规模的算力唾手可得。
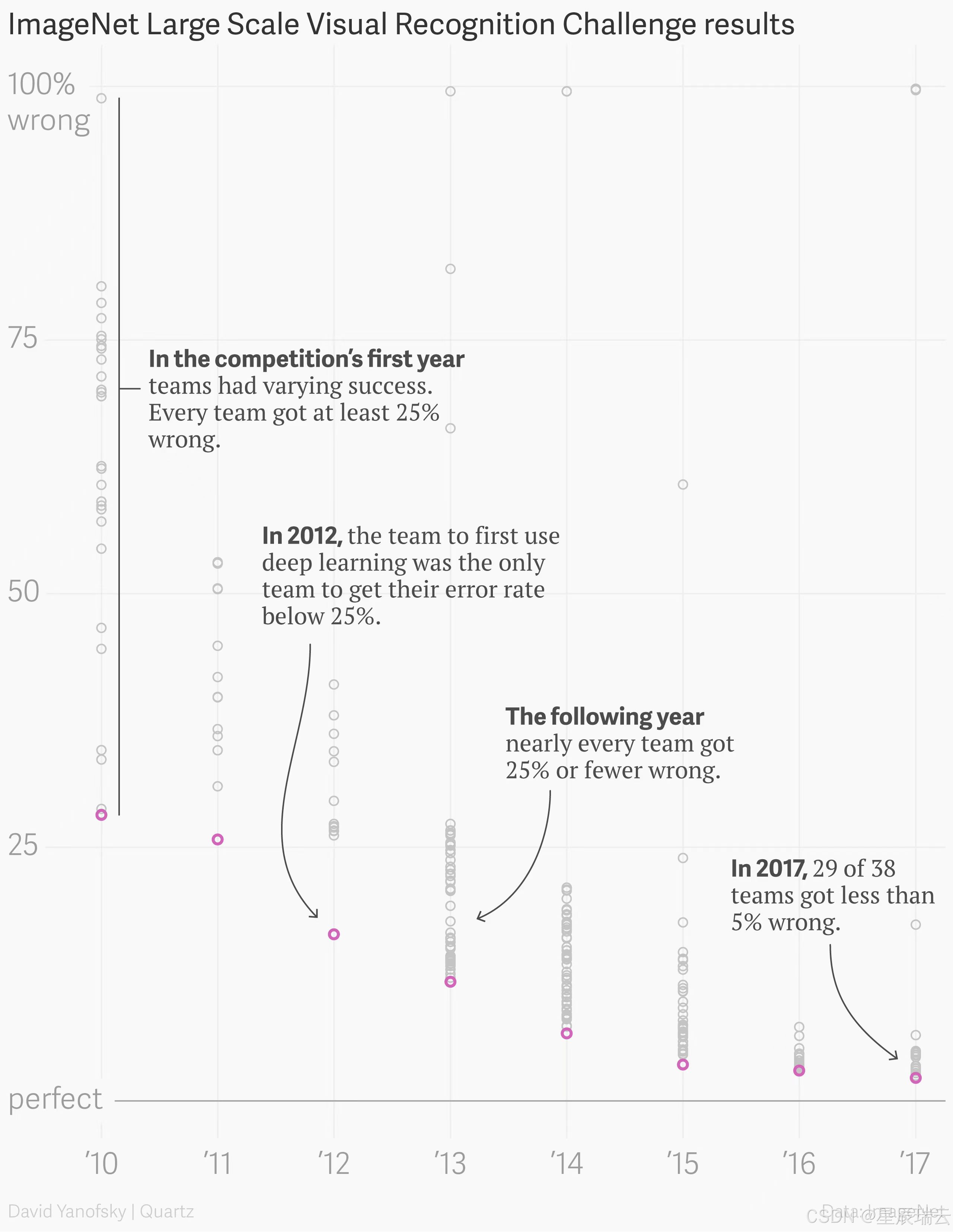
深度学习成功案例:图像分类,目标检测和分割,人脸合成,机器翻译,图像描述,自然语言文本合成等。
1.图像分类(都会转换成数字)

2.目标检测和分割
①置信度(每个虚线框上的数值)

②把图片转成漫画样的(风格迁移)


3.人脸合成

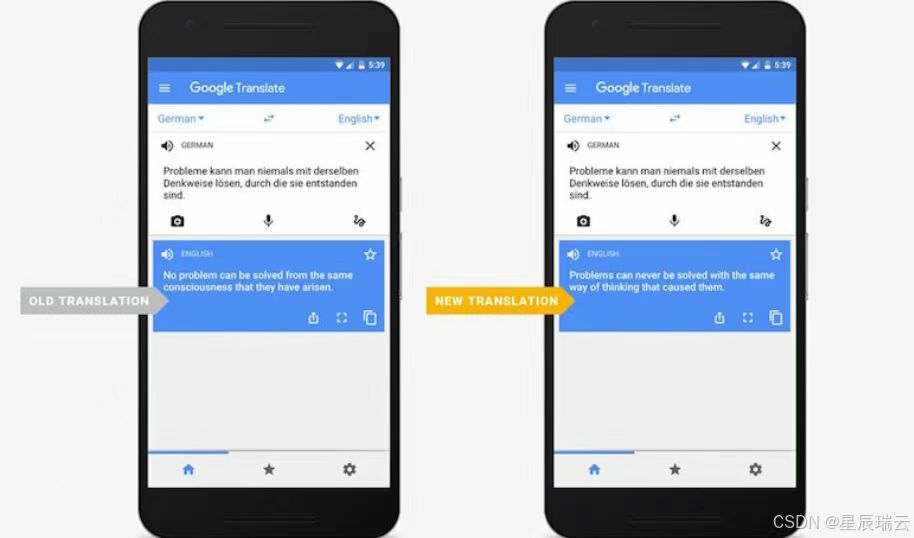
4.机器翻译
5.图像描述

6.自然语言文本合成
图灵测试
人工智能的先驱:艾伦·麦席森·图灵
英国数学家、逻辑学家、计算机科学之父、人工智能之父
“一个人在不接触对方的情况下,通过一种特殊的方式,和对方进行一系列的问答。如果在相当长时间内,他无法根据这些问题判断对方是人还是计算机,那么就可以认为这个计算机是智能的”。
---Alan Turing [1950]《Computing Machinery and Intelligence》
测试者与被测试者(一个人和一台机器)隔开的情况下,通过一些装置(如键盘)向被测试者随意提问。
进行多次测试后,如果机器让平均每个参与者做出超过30%的误判,那么这台机器就通过了测试,并被认为具有人类智能。
深度学习框架
Pytorch 介绍
PyTorch是由Meta AI(Facebook)人工智能研究小组开发的一种基于Lua编写的Torch库的Python实现的深度学习库,目前被广泛应用于学术界和工业界,PyTorch在API的设计上更加简洁、优雅和易懂。因此本课程我们选择PyTorch来进行开源学习。
Pytorch兼容性强
线性回归
y=ax+b,其中y是标签,x是特征
看中一个房,参观了解估计一个价格,出价


神经网络
①
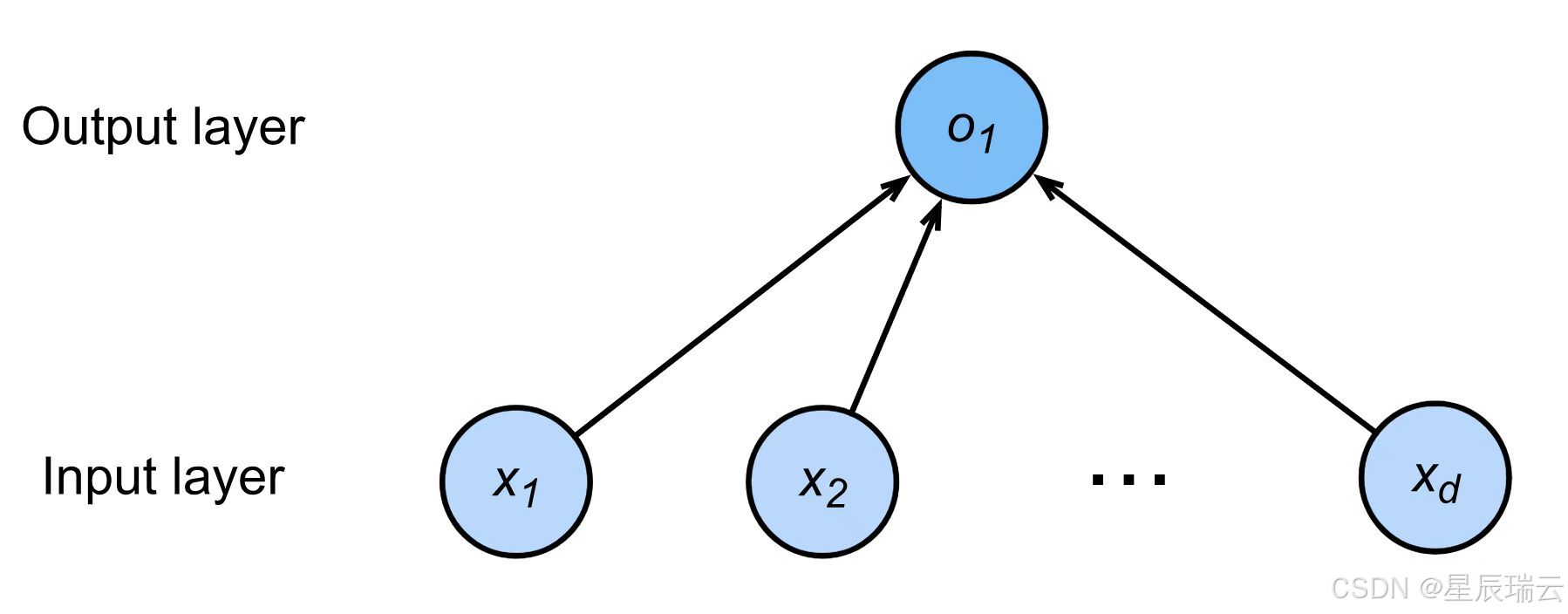
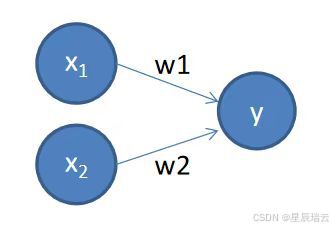
②
损失函数


在人工智能领域,尤其是机器学习和深度学习中,损失函数(Loss Function)是一个非常重要的概念。损失函数用于衡量模型预测值与真实值之间的不一致程度,即模型的误差。在训练过程中,通过优化损失函数,可以使模型的预测更加准确。
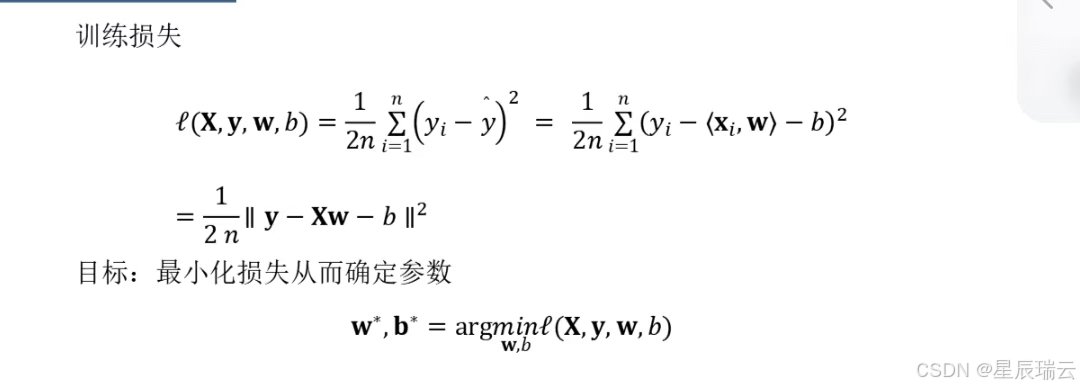
基础优化算法
梯度法
神经网络在学习时找到最优的参数(权重和偏置)——指损失函数取最小值时的参数。我们不知道他在何处能取得最小值,所以使用梯度来寻找函数的最小值的方法就是梯度法。
严格的讲,梯度指示的反向是各点处的函数值减小最多的方向
像
我们发现梯度指向函数的“最低处”(最小值),就像指南针一样,所有的箭头都指向同一点。其次,我们发现离“最低处”越远,箭头越大。
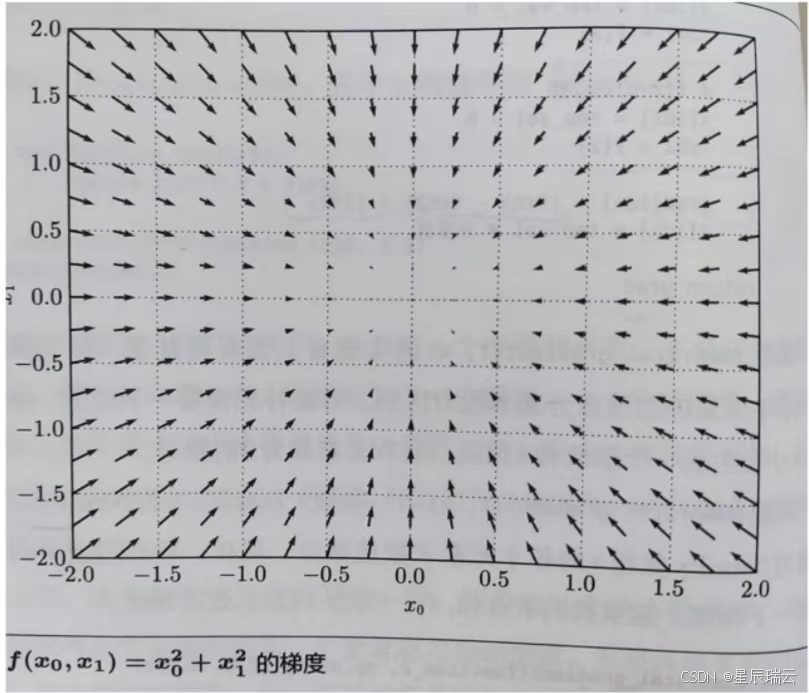
!!! 梯度指示的反向是各点处的函数值减小最多的方向,所以无法保证梯度所指的方向就是函数的最小值或者真正应该前进的方向。但沿着它的方向能最大限度的减小函数的值。所以在寻找函数的最小值的位置任务中,以梯度的信息为线索,决定前进的方向。
流程:在梯度法中,函数的取值从当前位置沿着梯度方向前进一定的距离,然后在新的方向重新求梯度,再沿着新梯度的方向前进,如此反复,不断的沿梯度方向前进。
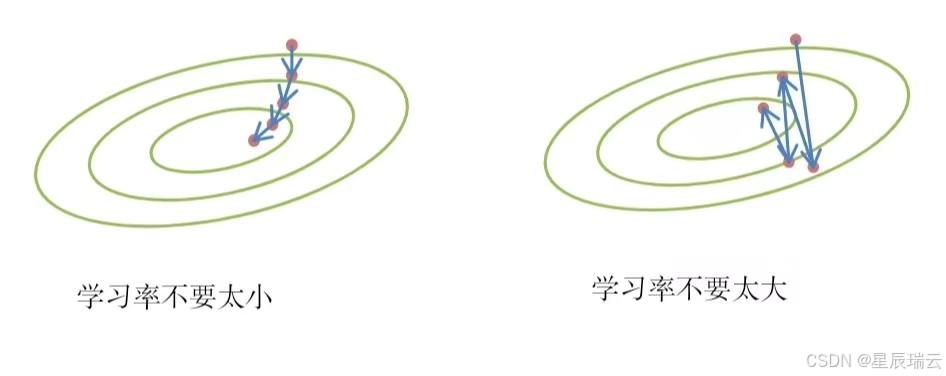
随机梯度下降
它通过不断的在损失函数递减的方向上更新参数来降低误差。
随机梯度下降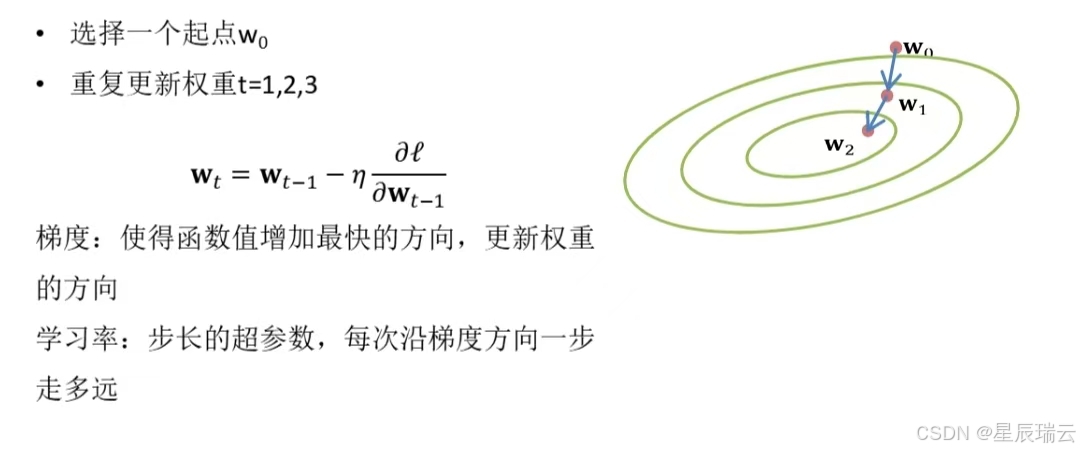


总结:
-
梯度下降通过不断的沿着反梯度方向更新参数求解
-
小批量随机梯度下降是深度学习默认的求解算法
-
两个重要的超参数是批量大小和学习率
Softmax回归
-
回归估计一个连续值
-
分类预测一个离散类别
Kaggle上的分类任务
将人类蛋白质显微镜图像分为28类

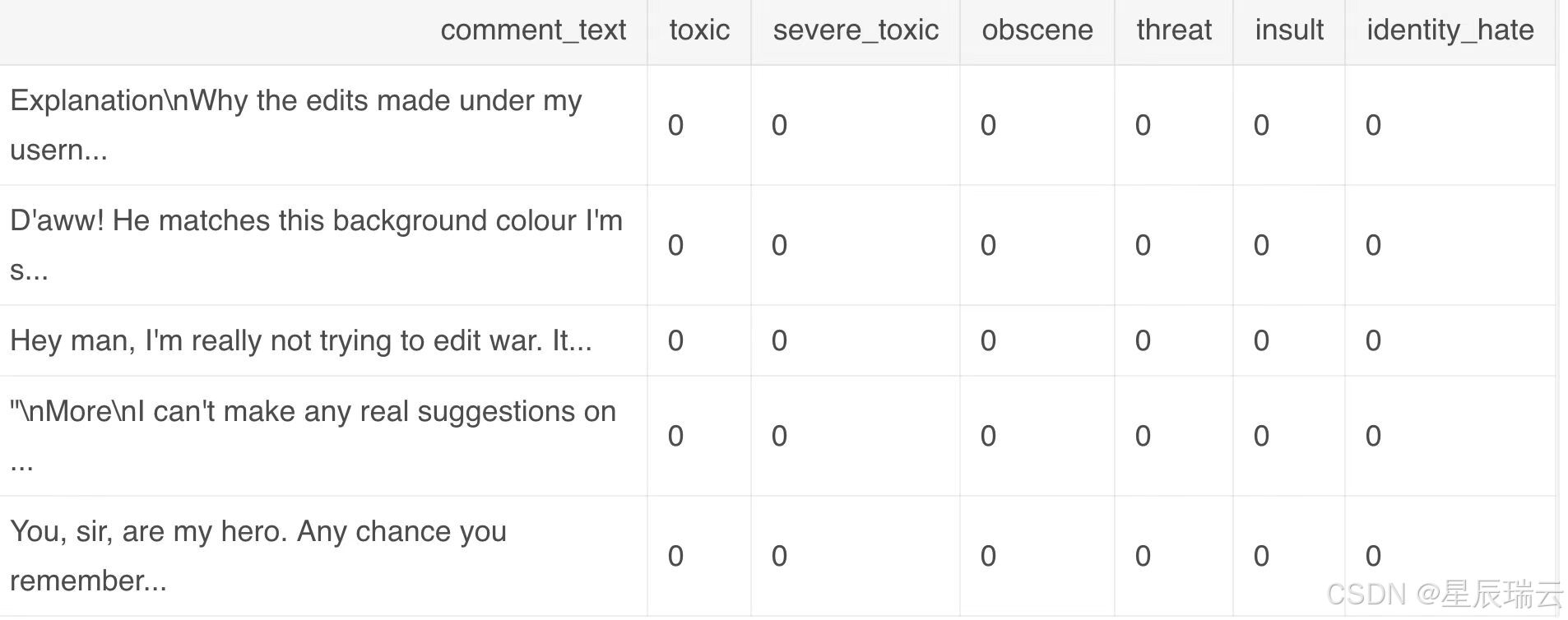
将维基百科上的恶语评论分为7类
从回归到多类分类
回归
单个连续数值输出
自然区间
与真实值的区别作为损失
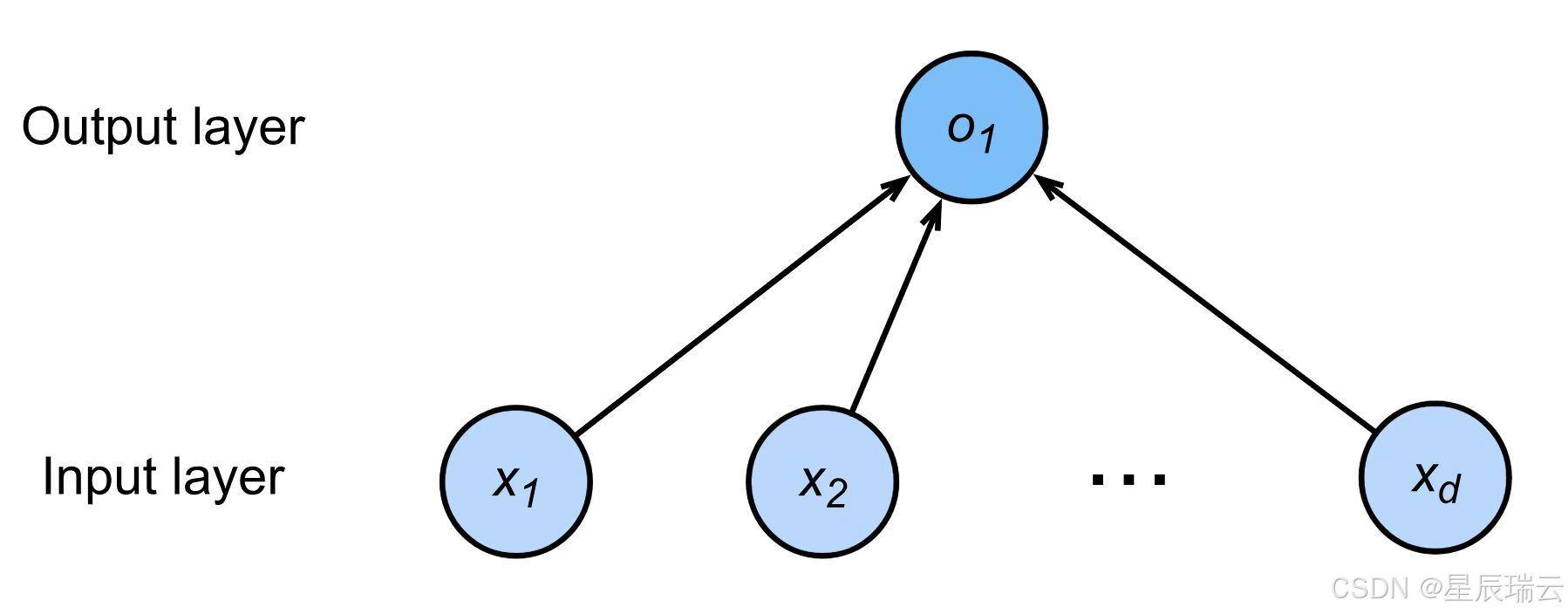
分类
通常多个输出
输出的i表示预测为第i类的置信度
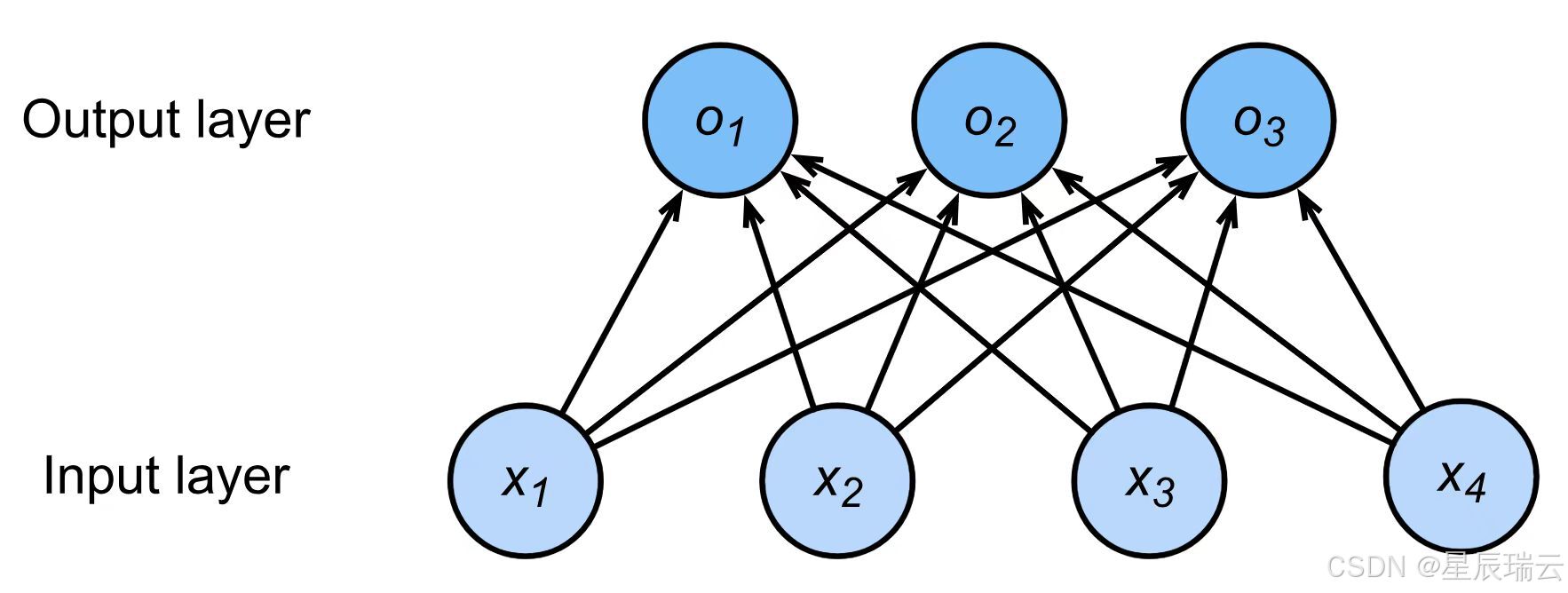

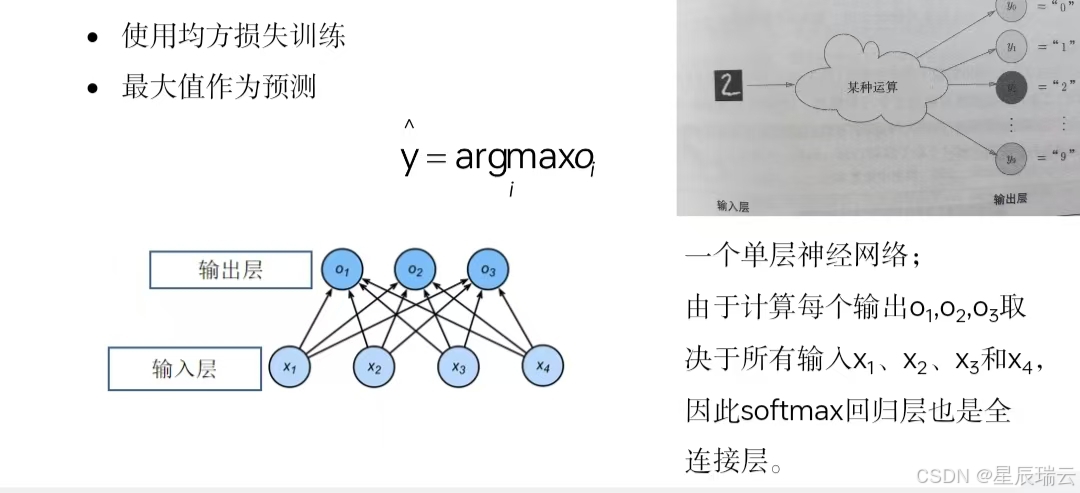
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输出层的神经元数量一般设定为类别的数量。
比如,对于某个输入图像,预测是图中的数字0到9中的哪一个的问题(10类别分类问题),将输出层的神经元设定为10个。

损失函数:
平方损失(L2 损失)
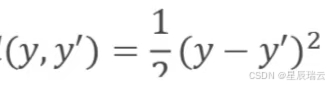
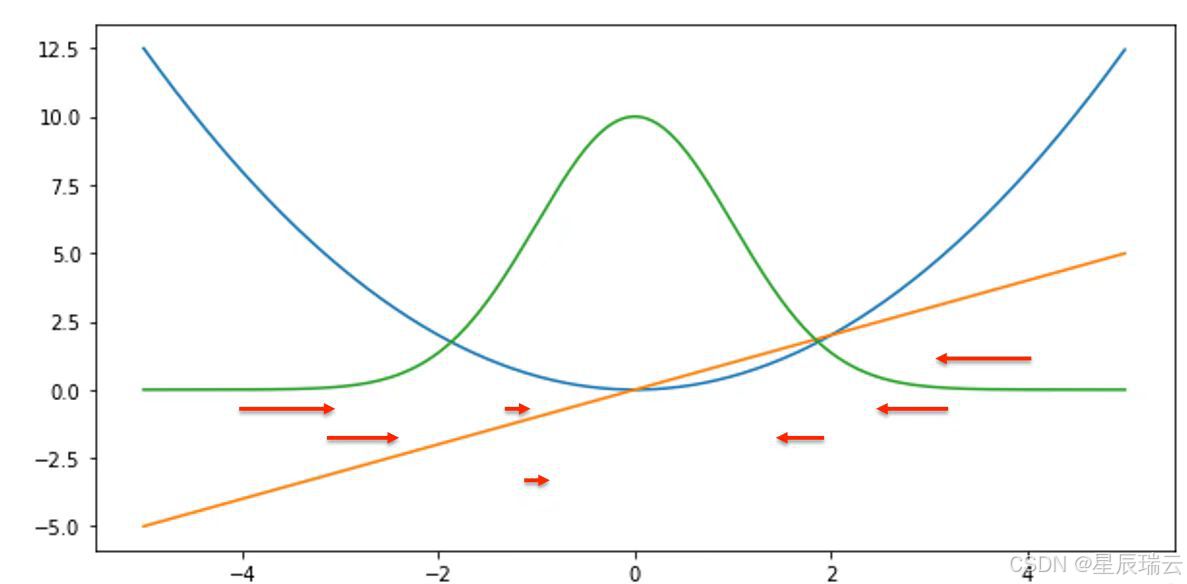
L1 损失
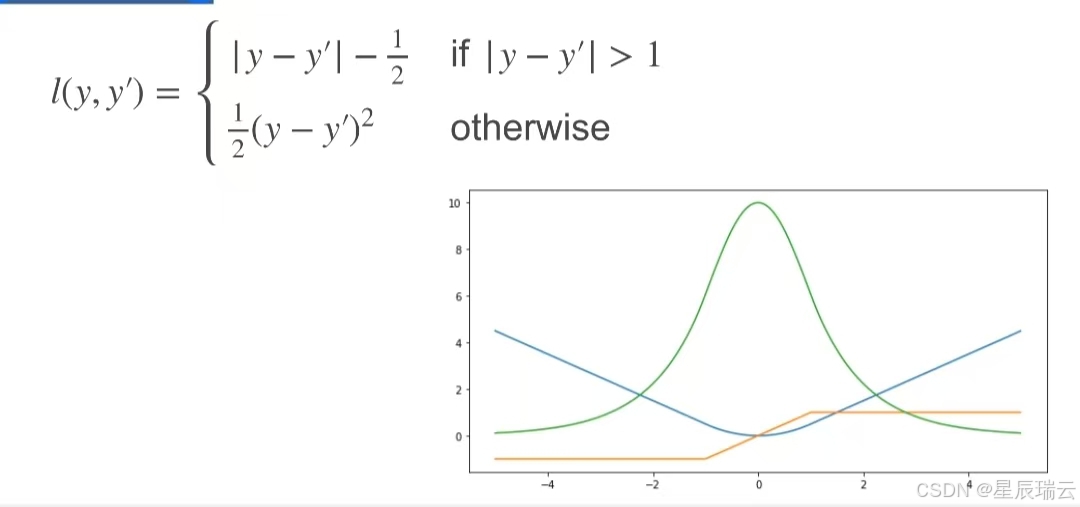
Huber 损失
交叉熵损失