一、赶鸭子上架学建模
10年前大学只学了一些范式建模皮毛,工作后第1个月,领导就让我用维度建模来构建数仓集市。那时我憋红了脸尴尬的问他,什么是维度建模?领导也愣住了,然后开始边吐槽边教。
刚毕业那会内心自尊心又强,不敢轻易问问题,于是顶着压力翻书自学建模。
二、面试必考
几乎所有数仓候选人在面试的时候,都会说负责或参与了数仓建模,那我就认为读者老爷们已有一定的功底,不瞎填充以下名词解释滥竽充数。
-
维度模型Kimball
-
事实表、维度表
-
星型模型、雪花模型
-
维度共享、维度退化
-
事实表、拓展表
-
缓慢变化维SCD
-
命名规范
-
......
让我们直接从业务流程开始。
三、业务背景
Grab是东南亚领先的超级应用平台,提供网约车、外卖等日常生活服务。2021年Grab出行、配送业务在东南亚市占率均列第一,市占率分别为72%、50%。

四、开始建模
建模的标准步骤:
-
梳理业务过程
-
确定粒度
-
确定维度
-
设计事实
1.业务过程
模型设计首先覆盖核心业务过程,而不是所有业务过程。提前定义这些流程,有多少个事实表等等。其中网约车的关键流程包括:

接下来就需要和分析师、产品确定相关业务目标,我们0-1的数仓建设MVP版本都是围绕最初始的核心目标展开。例如:
-
热门目的地(E.g.机场、公园等)的乘车情况;
-
司机完成行程,乘客进行评价情况;
-
每日的乘车次数,计算高峰期的平均价格;
-
......
2.确定粒度
粒度就是数据的“分辨率”,粒度越细,数据越细;
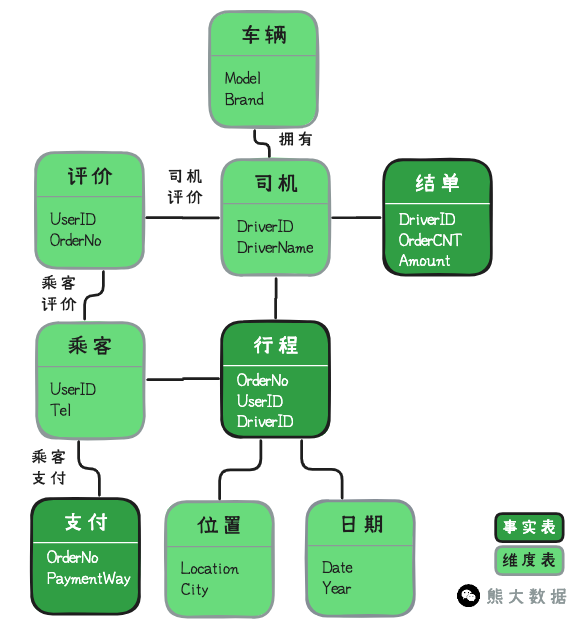
E.g. 行程订单表:订单表的每一条记录都存着司机ID、上下车地点、所用车辆、行驶时间、距离和乘客数量等信息,我们可以把每条记录都当作是一个原子事件。
3. 确定维度
我们描述一个人,可以从多个角度来描述,比如年龄、性别、职业、爱好等,这些角度就是“维度”E.g. 网约车的通常分析维度: 司机维度、乘客维度、时间维度、位置维度、车辆维度、优惠
4. 事实
业务活动的结果数据
E.g. 支付记录的金额、支付时间等
一定要厚脸皮找后端开发团队要ER图,然后基本就可以还原核心的业务过程和数据流
五、模型分层
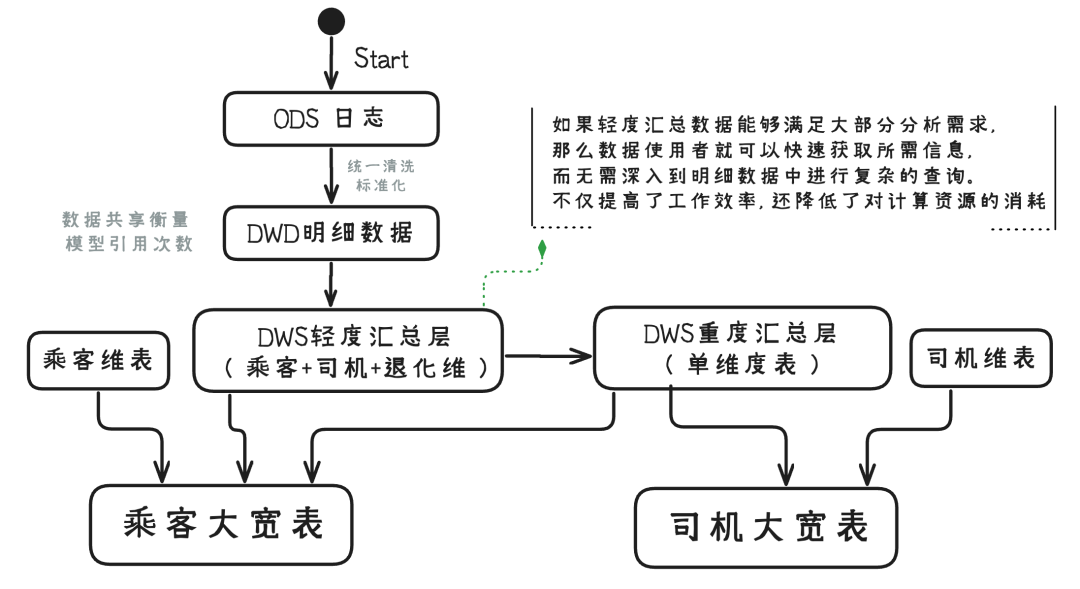
业界通常都会分为5层:ODS-DWD-DWS-ADS-DIM。这种分法对于日增GB量级问题不大,但是日增TB/PB量级以上,可以根据业务适当增加一层轻度汇总表。每层的内涵展开聊聊:
-
DWD :核心作用在于统一清洗和标准化,避免穿透到ODS,造成重复清洗和数据不一致,如果业务变动(ODS数据调整),可以在DWD层做屏蔽,对下游的使用无感;
-
DWS :做了常用的退化维,最细粒度的指标这里都有,支持大部分的指标都可以从这里出,真正体现数仓共享价值的地方; 重度汇总表:通常是单维度表,或是天级别维度,分为增量表(1d/3d/7d/30d)周期的指标,全量表计算历史累计指标。
-
ADS :面向业务数据分析的常用大宽表,做到充分的解耦,满足自身的场景需求。
在分层定位清晰后,基本数据加工流程也就清晰了。
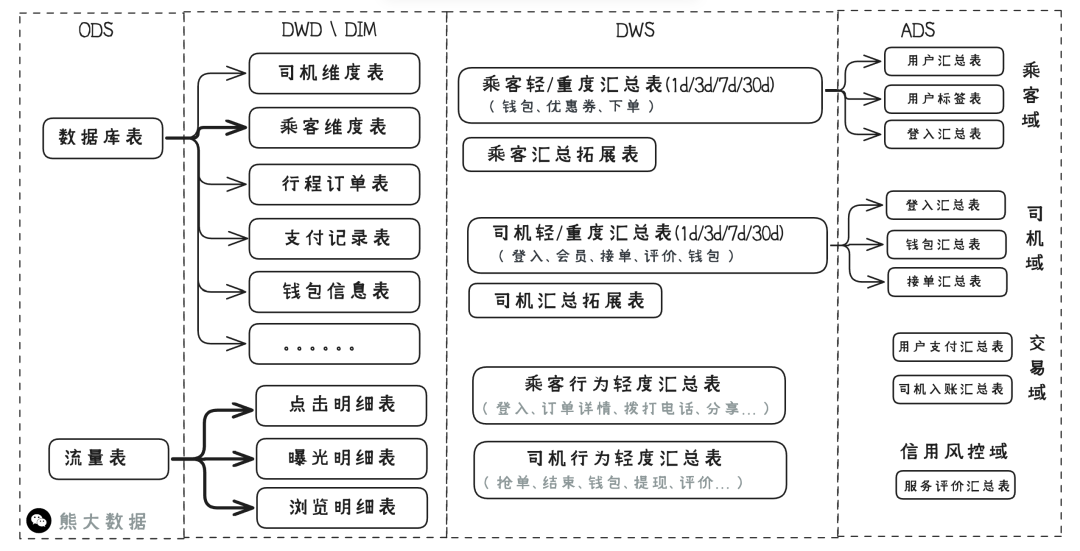
我喜欢采用先分后总思路,先建设不受业务数据干预的公共基础维表和各业务的数据表,强解耦,保持独立,再建设全域乘客和司机维表。
最终合成我们的模型架构:
细节之处见深度
》》司机、乘客、车辆维表设计
-
访问频率非常高,不建议叠加复杂标签,影响SLA的产出;E.g:最近7天是否有接单,则可以放到ext或者单独的标签表中进行存储,做到核心模型与拓展模型分离。
-
车辆维表,理论上一个司机换车的频率很低,可以建设成缓慢变化维度,增加字段: is_valid、start_datetime 、end_datetime。时间久了,SCD表数据量也会很影响性能。我通常保留一张全量表数据,还会创建一张只有最近3个月的数据的表来满足业务实际需求。
》》事实表设计
-
单事实:尤其要关注粒度,比如订单和子订单,共享同一个订单ID。
-
多事实:多个业务过程放到一张事实表中,E.g. (订单创建、司机接单、行程开始、行程结束)这几个这些业务过程紧密相关,都是订单生命周期的一部分,且每个过程都有明确的时间戳和状态变化。这类具有业务过程相似性、数据来源相同的过程就可以合并,而不是生硬的分开,导致用户使用成本和计算存储的成本都降低。
》》轻度汇总
-
最好设计成天级别增量数据表,公共逻辑下沉,指标口径保持一致,不要让公共逻辑多处存在;减少计算复杂度,避免ADS层加载过多数据计算。如果DWS超过100个指标,可以指标水平拆分,并行计算;
》》历史累计
-
基于1d进行累计(不可累加除外。E.g. 去重MAU数)
-
对于最近30天的UV计算可以用bitmap来实现;
》》1d/3d/7d/30d指标
-
合并,运行时间不影响,不解耦。
》》冗余
-
只冗余常用维度,不要听BI什么都加,容易引发更新不及时;
-
不冗余查询速度会不会很慢?
-
查询频率高
-
冗余在DWD还是DWS更合适?
》》流量表设计
-
数据量太大了,优化细节很多,可以另外开一篇文章来单独说流量域的数据建模,想看的话留言:想看。超过10个留言我写一篇。
六、需求开发
-
计算每个司机每月完成单数
-
统计每日热门目的地(机场、公园)
-
高峰期的每程平均价格
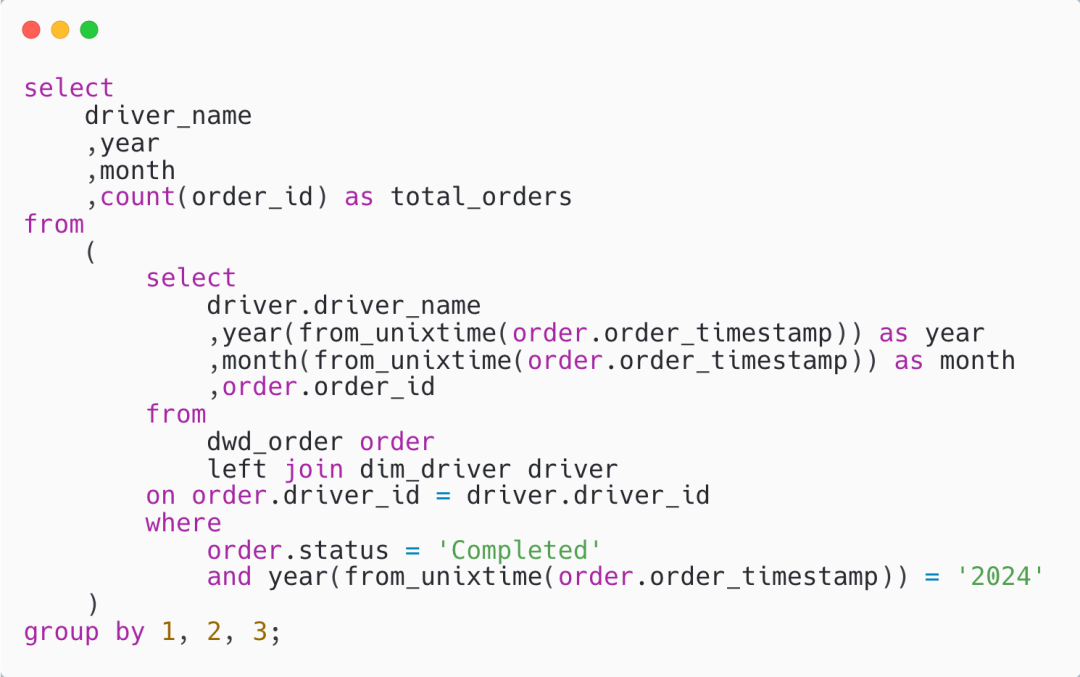


七、常见问题
时区转换
Q1:Grab总部位于新加坡,业务横跨多个国家,汇报时候如何统一全局时区?
A1: ODS\DWD都增加了以GMT+8的新加坡时区字段,如果要计算全局指标,则DWS可以根据Reg字段进行上卷汇总。ODS和DWD的分区字段:region 、local_dt 、reg_dt, tz_type : 枚举值local 或 reg 分别表示local时区和新加坡时区
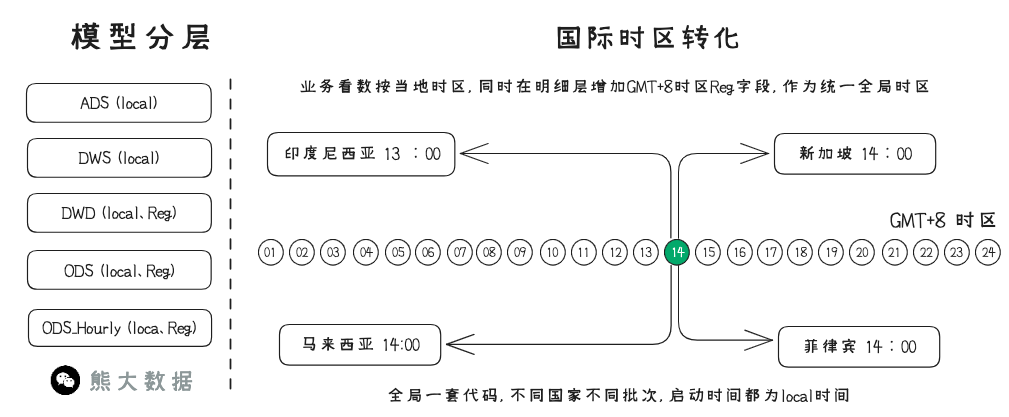
Q2:司机和乘客穿越多个时区情况如何解决?
A2: 使用UTC格式时间戳,UTC不受时区限制,在使用的时候再根据当地时区进行转换,确保在存储和比较不同位置的时间数据是一致的。
价格波动
Q3: 如果高峰期或促销期的价格变化,动态价格存储该如何设计?
A3: 高峰时间价格波动和领券促销的本质就是调价,我们可以设置一个维表dim_promotion,它有promotion_id、start_timestamp 、end_timestamp、discount_rate、promotion_type,为了计算最终的行程价格,我们不讲付款存储在行程订单表中,而放在支付表中。但促销会不太一样,它会多一个实体对象:券。 那就需要单独为这个券设计一个维表,这个券ID我们可以存储在行程订单中,这样少关联一张支付维表,还可以围绕券的维度,去分析哪类人群、距离对券比较敏感,以及发券的效率等等。
司机与车辆关系
Q4: 目前司机表和车辆表是1:N的关系,如果车辆被二手卖之后,重新加入Grab,就出现N:N的关系,如何解决呢?
A4: 目前Grab对车辆的管理是通过生成车辆ID,而不是通过车辆自带的车架号等这种ID来管理。即使同一部汽车“二进宫”,Grab都会重新分配一个新车辆ID,使得内部保持1:N的关系。
跨国时间格式
Q5:如何保障财务统计、业务报表中的工作日和假期/周末如何统一呢?
A5 : 在Kimball一致性的建模里,可以创建一个dim_date的维度表,它由dt_id、day、month、year、quarter、is_holiday、is_weekend、is_business_day、region等组成。这样每次都可以关联dt_id去拿到标准的全局时间格式(日/月/年),统一汇报时间口径。
八、写到最后
从毕业到现在,对模型的认识不断被刷新重建,尤其是后来接触越来越复杂的业务,设计的模型被一次次鞭笞和灵魂拷问(下游吐槽),才积累出心得。
5年后,我又转去做数据治理,开始轮到我吐槽别人的模型:
-
SLA被一个指标严重拖垮;
-
这个指标命名相同,但含义却不一致;
-
每日历史全量表占据太多存储空间,修改TTL又影响Backfill重新写脚本;
-
订单指标重复开发,下游不知道用哪个,每次都来问;
-
Backfill的时候,部分表出现数据短板。
都可以在模型侧解决,不禁再次崇拜🙏🙏🙏前辈总结:
精辟
1. 高内聚、低耦合
2. 核心和拓展模型分离
3. 公共处理逻辑下沉及单一
4. 成本和性能平衡
5. 数据可回滚
本文结束 →
10分钟文章,2周前开始总结,花了1周时间在打磨,如果有所帮助,给点个赞,如果写的不好,评论区告诉我,特别感谢~