以下测试均基于 OLLAMA 部署的deekseek
1.ollama运行语句:
ollama run deepseek-r1:14b --verbose
2.询问模型如下问题:
Describe the phenomenon of quantum entanglement and areas of application
注:ollama首次载入时,会把模型尽可能的载入到显存(vram),显存不足将显著影响运行效率
测试截图:
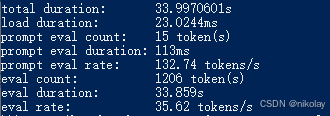
一、AMD 6800XT (显存:16G 系统:WIN10)
运行结果 平均 35token/秒,占用显存(vram) 12G
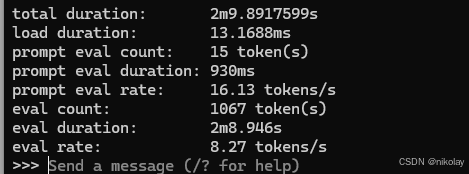
二、NVIDIA 4060 laptop (显存:8G 系统:WIN11+cuda)
可能是笔记本功耗策略的关系GPU的使用率并不高,所以速度相对较慢
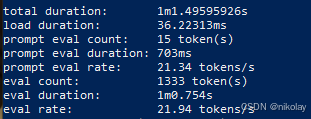
三、NVIDIA 1080ti (显存:11G ubuntu 20.0.4 + cuda)
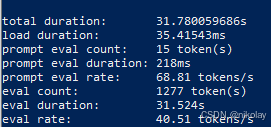
四、NVIDIA 2080ti (显存:11G ubuntu 20.0.4 + cuda)
五、NVIDIA 3060 (显存:12G 系统:ubuntu 20.0.4 + cuda )
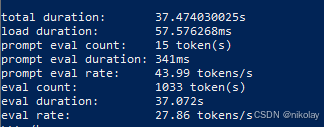
六、NVIDIA 3080 (显存:12G ubuntu 20.0.4 + cuda)
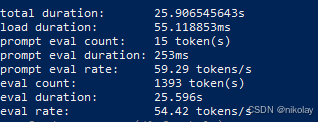
七、NVIDIA 3090 (显存:24G 系统:ubuntu 20.0.4 + cuda )
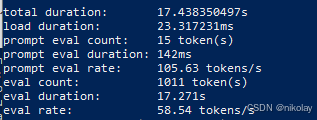
八、NVIDIA 4080 (显存:16G ubuntu 20.0.4 + cuda)
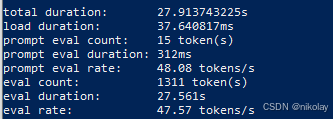
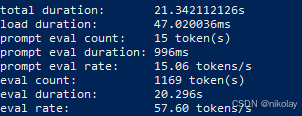
九、NVIDIA P100 (显存:16G 系统:ubuntu 20.0.4 + cuda )
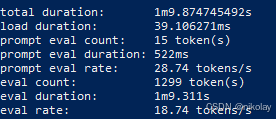
十、NVIDIA V100 (显存:16G 系统:ubuntu 20.0.4 + cuda)
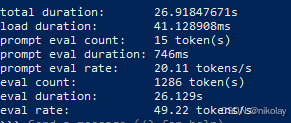
十一、NVIDIA A100 (显存:40G 系统:ubuntu 20.0.4 + cuda)
总结:
| 序号 | 显卡型号 | 显存(G) | eval rate (tokens/s) | 参考价(元) (小黄鱼) |
| 1 | nvidia 1080ti | 11 | 21.94 | 1000 |
| 2 | nvidia 2080ti | 11 | 40.51 | 1550 |
| 3 | nvidia 3060 | 12 | 27.86 | 1300 |
| 4 | nvidia 3080 | 12 | 54.42 | 2300 |
| 5 | nvidia 3090 | 24 | 58.54 | 5500 |
| 6 | nvidia 4080 | 16 | 47.57 | 7000 |
| 7 | amd 6800xt | 16 | 35.62 | 2500 |
| 8 | nv tesla p100 | 16 | 18.74 | 1000 |
| 9 | nv tesla v100 | 16 | 49.22 | 2200 |
| 10 | nv tesla a100 | 40 | 57.60 | 买不起 |
可以看到,如果以大模型应用为目标,显卡并不是越贵越好。
注:参考价为文章发布期间闲鱼的价格,均为单卡PCIE版本!