SparkStreaming数据源 { socket数据源:netcat -用于测试 RDD数据源-用于压力测试 自定义数据源 Kafka数据源(实操中的主要数据源) \text{SparkStreaming数据源} \begin{cases} \text{socket数据源:netcat -用于测试}\\[2ex] \text{RDD数据源-用于压力测试}\\[2ex] \text{自定义数据源}\\[2ex] \text{Kafka数据源(实操中的主要数据源)}\\[2ex] \end{cases} SparkStreaming数据源⎩ ⎨ ⎧socket数据源:netcat -用于测试RDD数据源-用于压力测试自定义数据源Kafka数据源(实操中的主要数据源)
一、SparkStreaming与Kafka的整合(直连方式)
1、SparkStreaming从Kafka消费数据案例一:WordCount1(直接消费)
如果SparkStreaming端中断后重启,在此期间Kafka生产的数据会丢失
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount1")
val ssc = new StreamingContext(conf, Seconds(3))
val params = Map[String, String](
"bootstrap.servers" -> "hadoop101:9092,hadoop102:9092,hadoop103:9092",
"group.id" -> "1015")
KafkaUtils
.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc,
params,
Set("first1015")
)
.flatMap {
case (_, v) =>
v.split("\\W+")
}
.map((_, 1))
.reduceByKey(_ + _)
.print()
ssc.start()
ssc.awaitTermination()
}
}
2、SparkStreaming从Kafka消费数据案例二:WordCount2(with checkpoint)
优点:设置checkpoint保存offset,不会丢数据,也不会重复消费数据,
缺点:是随着时间的推移,checkpoint会产生很多的小文件,这些小文件在HDFS上会对HDFS产生很大的压力
此方案在实操中用的不多,在实操中,数据的跟踪(offset的维护)一般是开发者自己来完成。
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount2 {
def createSSC() = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount1")
val ssc = new StreamingContext(conf, Seconds(3))
// 把offset的跟踪在checkpoint中
ssc.checkpoint("ck1")
val params = Map[String, String](
"bootstrap.servers" -> "hadoop101:9092,hadoop102:9092,hadoop103:9092",
"group.id" -> "1015")
KafkaUtils
.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc,
params,
Set("first1015")
)
.flatMap {
case (_, v) =>
v.split("\\W+")
}
.map((_, 1))
.reduceByKey(_ + _)
.print()
ssc
}
def main(args: Array[String]): Unit = {
/*
从checkpoint中恢复一个StreamingContext,
如果checkpoint不存在, 则调用后面的函数去创建一个StreamingContext
*/
val ssc = StreamingContext.getActiveOrCreate("ck1", createSSC)
ssc.start()
ssc.awaitTermination()
}
}
3、SparkStreaming从Kafka消费数据案例三:WordCount3(自己维护offset)
实操中使用该方案
import kafka.common.TopicAndPartition
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.commons.codec.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaCluster.Err
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaCluster, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount3 {
val groupId = "1015"
val params = Map[String, String](
"bootstrap.servers" -> "hadoop101:9092,hadoop102:9092,hadoop103:9092",
"group.id" -> groupId)
val topics = Set("first1015")
// KafkaUtils KafkaCluster
val cluster: KafkaCluster = new KafkaCluster(params)
/**
* 读取开始的offsets
*/
def readOffsets() = {
// 最终返回的map
var resultMap = Map[TopicAndPartition, Long]()
// 1. 获取这些topic的所有分区
val topicAndPartitionSetEither = cluster.getPartitions(topics)
topicAndPartitionSetEither match {
// 2. 获取topic和分区的信息
case Right(topicAndPartitionSet) =>
// 3. 获取到分区信息和他的offset
val topicAndPartitionToLongEither = cluster.getConsumerOffsets(groupId, topicAndPartitionSet)
topicAndPartitionToLongEither match {
// 没有每个topic的每个分区都已经存储过偏移量, 表示曾经消费购, 而且也维护过这个偏移量
case Right(map) =>
resultMap ++= map
// 表示这个topic的这个分区是第一次消费
case _ =>
topicAndPartitionSet.foreach(topicAndPartition => {
resultMap += topicAndPartition -> 0L
})
}
case _ => // 表示不存在任何topic
}
resultMap
}
/**
* 保持offsets
*/
def saveOffsets(stream: InputDStream[String]) = {
// 保存offset一定从kafka消费到的直接的那个Steram保存
// 每个批次执行一次传递过去的函数
stream.foreachRDD(rdd => {
var map = Map[TopicAndPartition, Long]()
// 如果这个rdd是直接来自于Kafka, 则可以强转成 HasOffsetRanges
// 这类型就包含了, 这次消费的offsets的信息
val hasOffsetRanges: HasOffsetRanges = rdd.asInstanceOf[HasOffsetRanges]
// 所有的分区的偏移量
val ranges: Array[OffsetRange] = hasOffsetRanges.offsetRanges
ranges.foreach(OffsetRange => {
val key = OffsetRange.topicAndPartition()
val value = OffsetRange.untilOffset
map += key -> value
})
cluster.setConsumerOffsets(groupId, map)
})
}
def main(args: Array[String]) = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount3")
val ssc = new StreamingContext(conf, Seconds(3))
val sourceStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, String](
ssc,
params,
readOffsets(),
(handler: MessageAndMetadata[String, String]) => handler.message() // 从kafka读到数据的value
)
sourceStream
.flatMap(_.split("\\W+"))
.map((_, 1))
.reduceByKey(_ + _)
.print(1000)
saveOffsets(sourceStream)
ssc.start()
ssc.awaitTermination()
}
}
二、DStream 转换
DStream 上的原语与 RDD 的类似,分为Transformations(转换)和Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种Window相关的原语。
| Transformation | Meaning |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a function func. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on which func returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream and otherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a function func (which takes two arguments and returns one). The function should be associative and commutative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function. Note: By default, this uses Spark’s default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config property spark.default.parallelism) to do the grouping. You can pass an optional numTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on a DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new “state” DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
1、无状态转换操作
无状态转化操作就是把简单的RDD转化操作应用到每个批次上,也就是转化DStream中的每一个RDD。
1.1 部分无状态转化操作
需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream在内部是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个RDD上的。例如,reduceByKey()会化简每个时间区间中的数据,但不会化简不同区间之间的数据。

举个例子,在之前的wordcount程序中,我们只会统计几秒内接收到的数据的单词个数,而不会累加。
无状态转化操作也能在多个DStream间整合数据,不过也是在各个时间区间内。例如,键值对DStream拥有和RDD一样的与连接相关的转化操作,也就是cogroup()、join()、leftOuterJoin() 等。我们可以在DStream上使用这些操作,这样就对每个批次分别执行了对应的RDD操作。
我们还可以像在常规的 Spark 中一样使用 DStream的union() 操作将它和另一个DStream 的内容合并起来,也可以使用StreamingContext.union()来合并多个流。
1.2 无状态转化操作: transform
transform 原语允许 DStream上执行任意的RDD-to-RDD函数。
把DStream的操作转换为RDD的操作,使用RDD中有但是DStream没有的操作。
可以用来执行一些 RDD 操作, 即使这些操作并没有在 SparkStreaming 中没有。
该函数每一批次调度一次。其实也就是对DStream中的RDD应用转换。
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object TransformDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("Practice").setMaster("local[2]")
val sctx = new StreamingContext(conf, Seconds(3))
val dstream: ReceiverInputDStream[String] = sctx.socketTextStream("hadoop102", 10000)
val resultDStream = dstream.transform(rdd => {
rdd.flatMap(_.split("\\W")).map((_, 1)).reduceByKey(_ + _)
})
resultDStream.print
sctx.start
sctx.awaitTermination()
}
}
2、有状态转换操作
2.1 updateStateByKey
def updateStateByKey[S: ClassTag](updateFunc: (Seq[V], Option[S]) => Option[S]): DStream[(K, S)]
updateStateByKey操作允许在使用新信息不断更新状态的同时能够保留他的状态。需要做两件事情:
- 定义状态. 状态可以是任意数据类型
- 定义状态更新函数. 指定一个函数, 这个函数负责使用以前的状态和新值来更新状态.
在每个阶段, Spark 都会在所有已经存在的 key 上使用状态更新函数, 而不管是否有新的数据在.
updateStateByKey数据流解析:
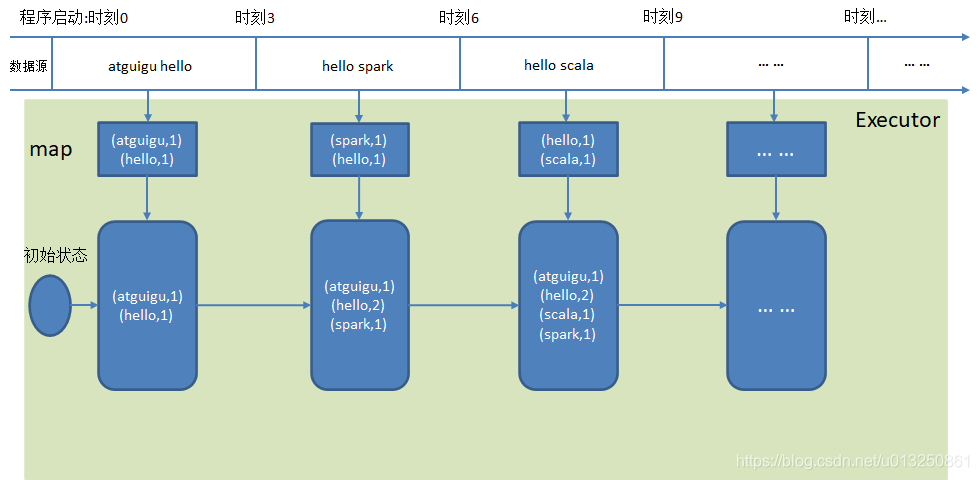
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object StreamingWordCount2 {
def main(args: Array[String]): Unit = {
// 设置将来访问 hdfs 的使用的用户名, 否则会出现全选不够
System.setProperty("HADOOP_USER_NAME", "atguigu")
val conf = new SparkConf().setAppName("StreamingWordCount2").setMaster("local[*]")
// 1. 创建SparkStreaming的入口对象: StreamingContext 参数2: 表示事件间隔
val ssc = new StreamingContext(conf, Seconds(5))
// 2. 创建一个DStream
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop201", 9999)
// 3. 一个个的单词
val words: DStream[String] = lines.flatMap(_.split("""\s+"""))
// 4. 单词形成元组
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
// 开始
/*
1. 定义状态: 每个单词的个数就是我们需要更新的状态
2. 状态更新函数. 每个key(word)上使用一次更新新函数
参数1: 在当前阶段 一个新的key对应的value组成的序列 在我们这个案例中是: 1,1,1,1...
参数2: 上一个阶段 这个key对应的value
*/
def updateFunction(newValue: Seq[Int], runningCount: Option[Int]): Option[Int] = {
// 新的总数和状态进行求和操作
val newCount: Int = (0 /: newValue) (_ + _) + runningCount.getOrElse(0)
Some(newCount)
}
// 设置检查点: 使用updateStateByKey必须设置检查点
ssc.sparkContext.setCheckpointDir("hdfs://hadoop201:9000/checkpoint")
val stateDS: DStream[(String, Int)] = wordAndOne.updateStateByKey[Int](updateFunction _)
//结束
//6. 显示
stateDS.print
//7. 启动流失任务开始计算
ssc.start()
//8. 等待计算结束才推出主程序
ssc.awaitTermination()
ssc.stop(false)
}
}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object UpstateByKeyDemo1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("UpstateByKeyDemo1")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("ck1")
ssc
.socketTextStream("hadoop102", 9999)
.flatMap(_.split("\\W+"))
.map((_, 1))
.updateStateByKey((seq: Seq[Int], opt: Option[Int]) => {
Some(seq.sum + opt.getOrElse(0))
})
.print(1000)
ssc.start()
ssc.awaitTermination()
}
}
2.2 window 操作
Spark Streaming 也提供了窗口计算, 允许执行转换操作作用在一个窗口内的数据.
默认情况下, 计算只对一个时间段内的RDD进行, 有了窗口之后, 可以把计算应用到一个指定的窗口内的所有 RDD 上.
一个窗口可以包含多个时间段. 基于窗口的操作会在一个比StreamingContext的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
观察上图, 窗口在 DStream 上每滑动一次, 落在窗口内的那些 RDD会结合在一起, 然后在上面操作产生新的 RDD, 组成了 window DStream.
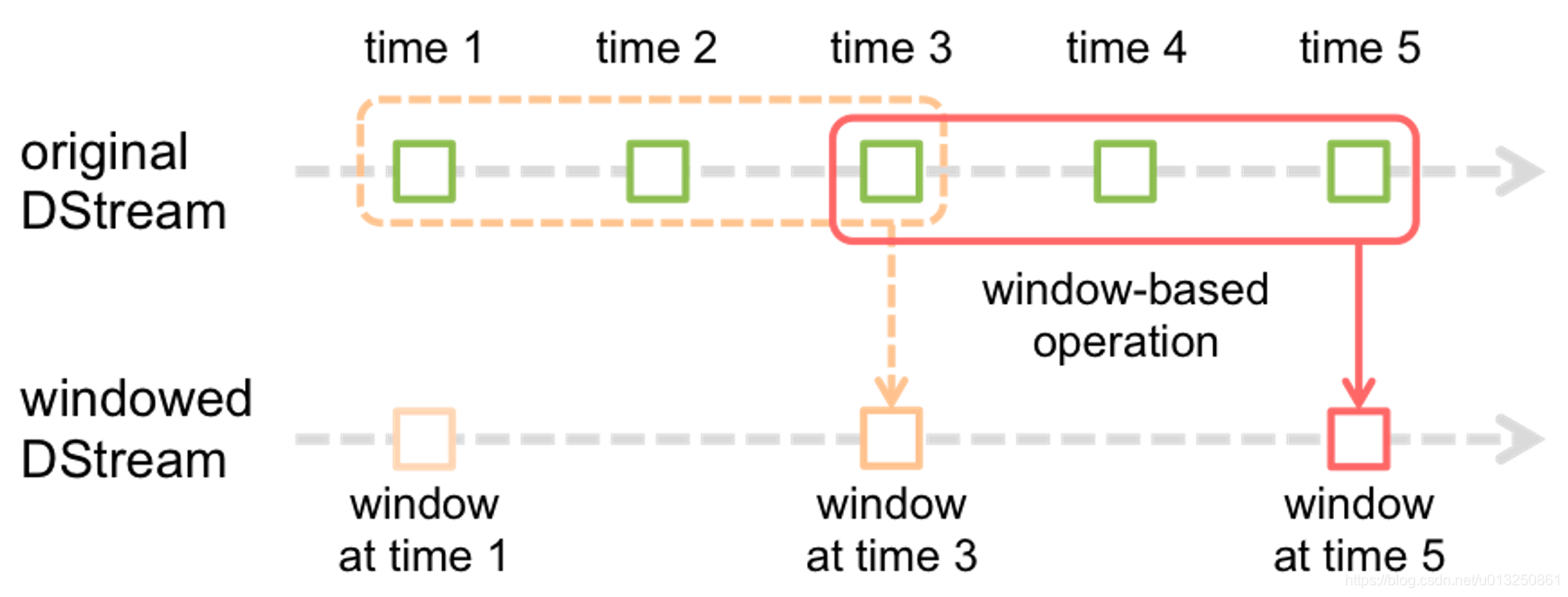
在上面图的情况下, 操作会至少应用在 3 个数据单元上, 每次滑动 2 个时间单位. 所以, 窗口操作需要 2 个参数:
- 窗口长度 – 窗口的持久时间(执行一次持续多少个时间单位)(图中是 3)
- 滑动步长 – 窗口操作被执行的间隔(每多少个时间单位执行一次).(图中是 2 )
注意: 这两个参数必须是源 DStream 的 interval 的倍数.
窗口操作数据流解析:
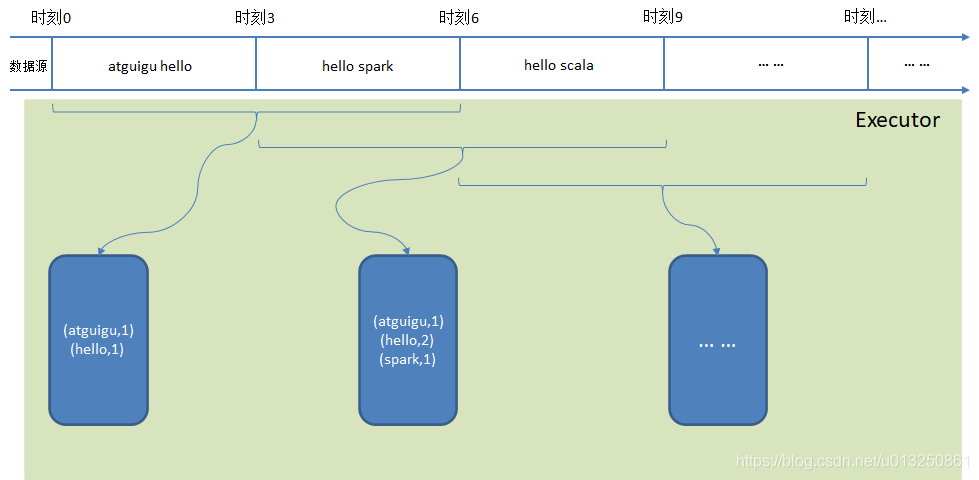
2.2.1 reduceByKeyAndWindow(reduceFunc: (V, V) => V, windowDuration: Duration)

val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
/*
参数1: reduce 计算规则
参数2: 窗口长度
参数3: 窗口滑动步长. 每隔这么长时间计算一次.
*/
val count: DStream[(String, Int)] =
wordAndOne.reduceByKeyAndWindow((x: Int, y: Int) => x + y,Seconds(15), Seconds(10))
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Window1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Window1")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("ck2")
ssc
.socketTextStream("hadoop102", 9999)
.flatMap(_.split("\\W+"))
.map((_, 1))
// 每6秒计算一次最近9秒内的wordCount
.reduceByKeyAndWindow(_ + _, _ - _ , Seconds(9), slideDuration = Seconds(6), filterFunc = _._2 > 0)
.print()
ssc.start()
ssc.awaitTermination()
}
}
2.2.2 reduceByKeyAndWindow(reduceFunc: (V, V) => V, invReduceFunc: (V, V) => V, windowDuration: Duration, slideDuration: Duration)
比没有invReduceFunc高效. 会利用旧值来进行计算.
invReduceFunc: (V, V) => V 窗口移动了, 上一个窗口和新的窗口会有重叠部分, 重叠部分的值可以不用重复计算了. 第一个参数就是新的值, 第二个参数是旧的值.
ssc.sparkContext.setCheckpointDir("hdfs://hadoop201:9000/checkpoint")
val count: DStream[(String, Int)] =
wordAndOne.reduceByKeyAndWindow((x: Int, y: Int) => x + y,(x: Int, y: Int) => x - y,Seconds(15), Seconds(10))
2.2.3 window(windowLength, slideInterval)
基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Window2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Window1")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("ck3")
ssc
.socketTextStream("hadoop102", 9999)
.window(Seconds(9), Seconds(6))
.flatMap(_.split("\\W+"))
.map((_, 1))
.reduceByKey(_ + _)
.print()
ssc.start()
ssc.awaitTermination()
}
}
2.2.4 countByWindow(windowLength, slideInterval)
返回一个滑动窗口计数流中的元素的个数。
2.2.5 countByValueAndWindow(windowLength, slideInterval, [numTasks])
对(K,V)对的DStream调用,返回(K,Long)对的新DStream,其中每个key的的对象的v是其在滑动窗口中频率。如上,可配置reduce任务数量。
三、DStream 输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。
与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个context就都不会启动。
| Output Operation | Meaning |
|---|---|
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging. Python API This is called pprint() in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream’s contents as text files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream’s contents as SequenceFiles of serialized Java objects. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream’s contents as Hadoop files. The file name at each batch interval is generated based on prefix and suffix: “prefix-TIME_IN_MS[.suffix]”. Python API This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function, func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the function func is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
- 连接不能写在driver层面(序列化);
- 如果写在foreach则每个RDD中的每一条数据都创建,得不偿失;
- 增加foreachPartition,在分区创建(获取)。
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
object OutDemo2 {
val props = new Properties()
props.setProperty("user", "root")
props.setProperty("password", "aaaaaa")
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("Window1")
val ssc = new StreamingContext(conf, Seconds(3))
ssc.checkpoint("ck3")
ssc
.socketTextStream("hadoop102", 9999)
.flatMap(_.split("\\W+"))
.map((_, 1))
.updateStateByKey((seq: Seq[Int], opt: Option[Int]) => Some(seq.sum + opt.getOrElse(0)))
.foreachRDD(rdd => {
// 把rdd转成df
// 1. 先创建sparkSession
val spark = SparkSession.builder().config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
// 2. 转换
val df = rdd.toDF("word", "count")
// 3. 写
df.write.mode("overwrite").jdbc("jdbc:mysql://hadoop102:3306/rdd", "word1015", props)
})
ssc.start()
ssc.awaitTermination()
}
}