实验环境搭建
Anaconda安装
Python 的可应用于不同领域业务开发的第三方扩展库来自于不同的机构。它们不仅数量庞大,而且相互之间存在复杂的依赖关系,维护管理起来很麻烦。Anaconda 是一个可对 Python 及其常用扩展库进行下载、安装和自动管理的软件。
可到 Anaconda 官方网站https://www.anaconda.com/products/individual
下载安装包安装。如果官方网站下载速度不稳定,可到
清华大学开源软件镜像站 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
安装完成后,在“开始”菜单里会出现 Anaconda3 的程序组,
在 Anaconda3 程序组里选择点击“Anaconda Navigator”,启动 Navigator 图形化管理界面.
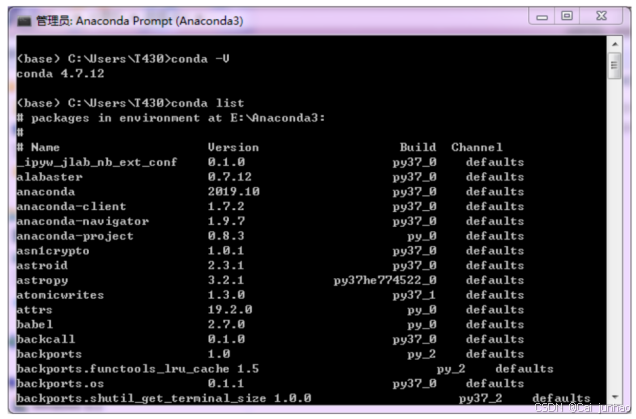
Conda 命令行管理界面通过选择点击“Anaconda Prompt”启动,输入“conda –V”和“conda list”命令,分别查看 Anaconda 的版本号和已经默认安装的包及其版本号

输入“python -V”可以查看该版本的 Anaconda 默认安装的 python 的版本为 3.7.0。输入“python”,启动交互式编程模式,在第一行指出了 python 的版本。
在“>>>”后输入 print(“Hello, World!”)后回车,将在下一行输出“Hello, World!”。

在下图中,最主要用的是jupyter notebook,vs code,pycharm

开发环境
采用 Anaconda 自带的 Spyder 和 Jupyter Notebook 作为开发环境。
Spyder 是图形化集成开发环境,在 Anaconda 程序组里选择点击“Spyder”,或者在 Conda 命令行管理界面里输入“spyder”启动 Spyder。
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,它是一个 Web 应用程序,可将代码、文本说明、数学方程、图表等集合在 一个文档里,表达能力非常强,便于交流。现在很多资料都采用 Jupyter 格式,成为同行交流的重要工具。
安装sklearn和TensorFlow2的CPU版本
1.先将下载源更换为清华大学镜像站。
在 Conda 命令行管理界面中,输入如下四条命令(可到网上搜索相关内容,直接拷贝
到 Conda 命令行管理界面中执行即可,不必逐字输入):
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --set show_channel_urls yes
成功执行后,即将默认下载源更换为清华大学的镜像站,最后一条命令是设置提示通道地址。

2.新建一个专用于机器学习的名为 ml 的环境。
在 conda 命令行管理界面中输入并执行“conda create –n ml”命令后,即新建一个名为 ml 的环境

3.安装扩展库
新建环境是空环境,需要安装各种库,anaconda 会自动安装各种依赖库。安装库的命
令为:conda install ***。
输入并执行“activate ml”命令切换到新建的 ml 环境中。
输入并执行以下命令以安装示例所使用的库:
conda install python=3.7.5
conda install scikit-learn=0.23.2
conda install tensorflow=2.0.0
在新的环境中,还需要安装各种辅助的库,如编程环境 spyder 和 jupyter 等。
Python 初步应用示例-迭代法
迭代法(iteration)又称辗转法或逐次逼近法。迭代法的核心是建立迭代关系式。只有正确的迭代关系式才能取得正确解。
来看一个示例。
假设在空池塘中放入一颗水藻,该类水藻会每周长出三颗新的水藻,问:十周后,池塘中有多少颗水藻?
第 1 周的水藻数量:1;
第 2 周的水藻数量:1 + 1 × 3;
第 3 周的水藻数量:1 + 1 × 3 + (1 + 1 × 3) × 3
…
可以归纳出从当前周水藻数量到下一周水藻数量的迭代关系式。设上周水藻数量为x,
从上周到本周水藻将增加的数量为y,本周的水藻数量为x′,那么在一次迭代中:

迭代开始时,水藻的数量为 1,为迭代法的初始条件。
迭代次数为 9(不包括第一周),为迭代过程的控制条件。
下面给出的代码迭代过程共循环 9 次,用 while 语句来循环实现迭代。一般用一轮循环来实现一次迭代。大家可以自己尝试改用 for 语句方式来实现迭代。
x = 1 # 初始条件:第一周水藻数量 times = 1 # 迭代次数
while times < 10: # 迭代过程
y = 3 * x
x = x + y
times += 1
print("第%d 周的水藻数量:%d" % (times, x))
输出为
第 2 周的水藻数量:4
第 3 周的水藻数量:16
第 4 周的水藻数量:64
第 5 周的水藻数量:256
第 6 周的水藻数量:1024
第 7 周的水藻数量:4096
第 8 周的水藻数量:16384
第 9 周的水藻数量:65536
第 10 周的水藻数量:262144
用迭代法求下列方程的解:

应用迭代法来求解,如何建立迭代关系式呢?

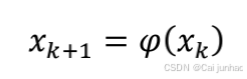


代码如下:
import math #导入math库
x=0
for i in range(100):
x = (6 - x**3 - (math.e**x)/2.0)/5.0 #使用指数函数
print(str(i)+":"+str(x))
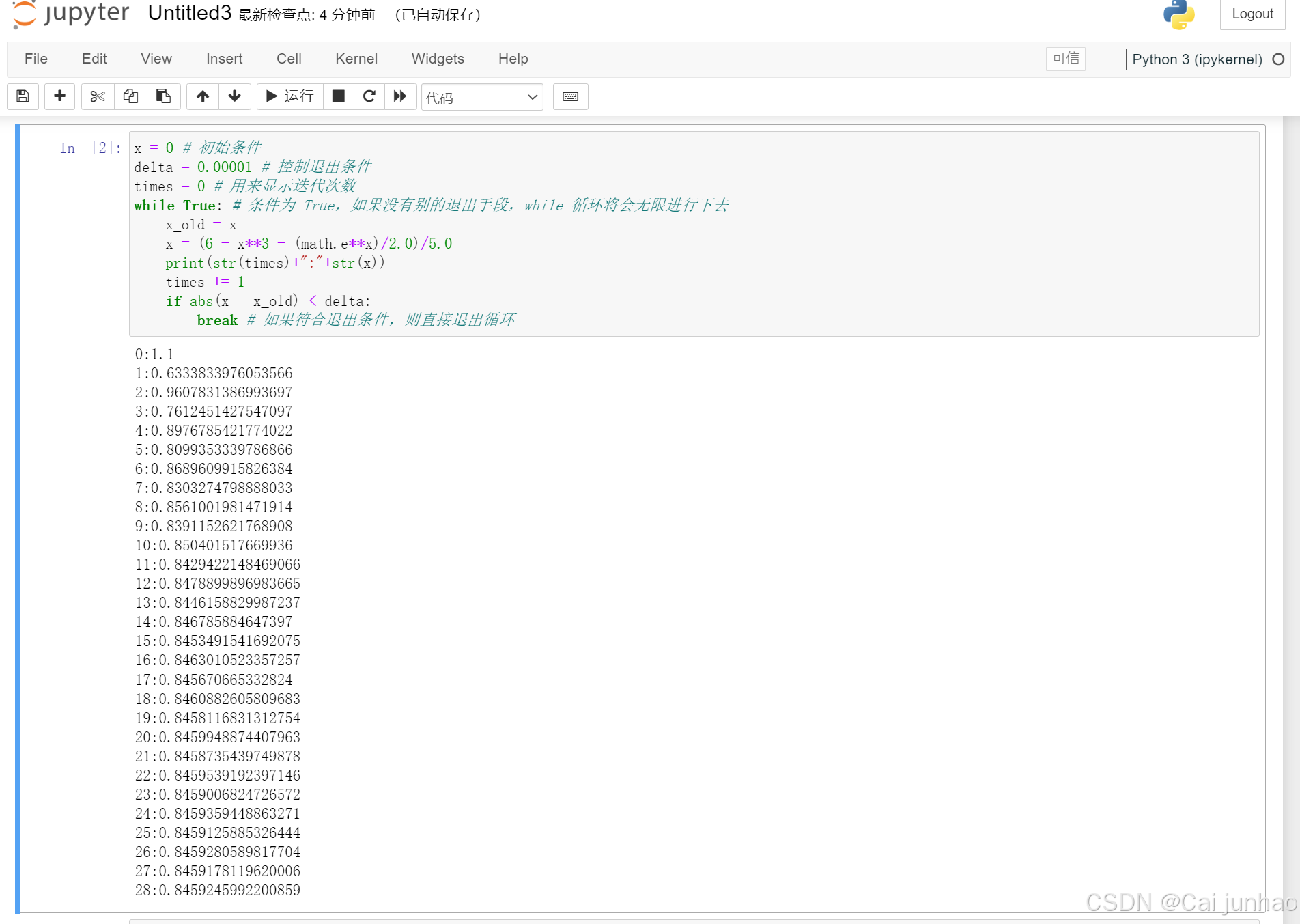
运行结果显示从 28 次迭代开始,收敛于 0.84592。

扩展:下面的给出更常用的采用阈值来控制迭代结束的示例,如果相邻两次迭代的差值小于指定的 delta,则通过 break 语句退出迭代。运行结果显示在第 28 次循环退出迭代。
x = 0 # 初始条件
delta = 0.00001 # 控制退出条件
times = 0 # 用来显示迭代次数
while True: # 条件为 True,如果没有别的退出手段,则死循环
x_old = x
x = (6 - x**3 - (math.e**x)/2.0)/5.0
print(str(times)+":"+str(x))
times += 1
if abs(x - x_old) < delta:
break # 如果符合退出条件,则直接退出循环
Sklearn鸢尾花数据集
准备实验环境
pip更新:Python -m pip install --upgrade pip
sklearn安装:Python -m pip install -u scikit-learn
matplotlib安装:Python -m pip install -u matplotlib
numpy安装:Python -m pip install numpy --ignore-installed numpy
介绍数据集
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。
Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。**数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。**可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
iris以鸢尾花的特征作为数据来源,常用在分类操作中。该数据集由3种不同类型的鸢尾花的各50个样本数据构成。其中的一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的。
该数据集包含了4个属性:
- & Sepal.Length(花萼长度),单位是cm;
- & Sepal.Width(花萼宽度),单位是cm;
- & Petal.Length(花瓣长度),单位是cm;
- & Petal.Width(花瓣宽度),单位是cm;
种类:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),以及Iris Virginica(维吉尼亚鸢尾)
scikit-learn自带一些经典的数据集,如iris,digits,boston house prices,可以直接导入
- 导入方式
form sklearn import datasets
iris=datasets.load_iris() #导入的数据是一种字典形式,特征存储在iris.data中,标签存储在iris.target中
利用数据画出散点图
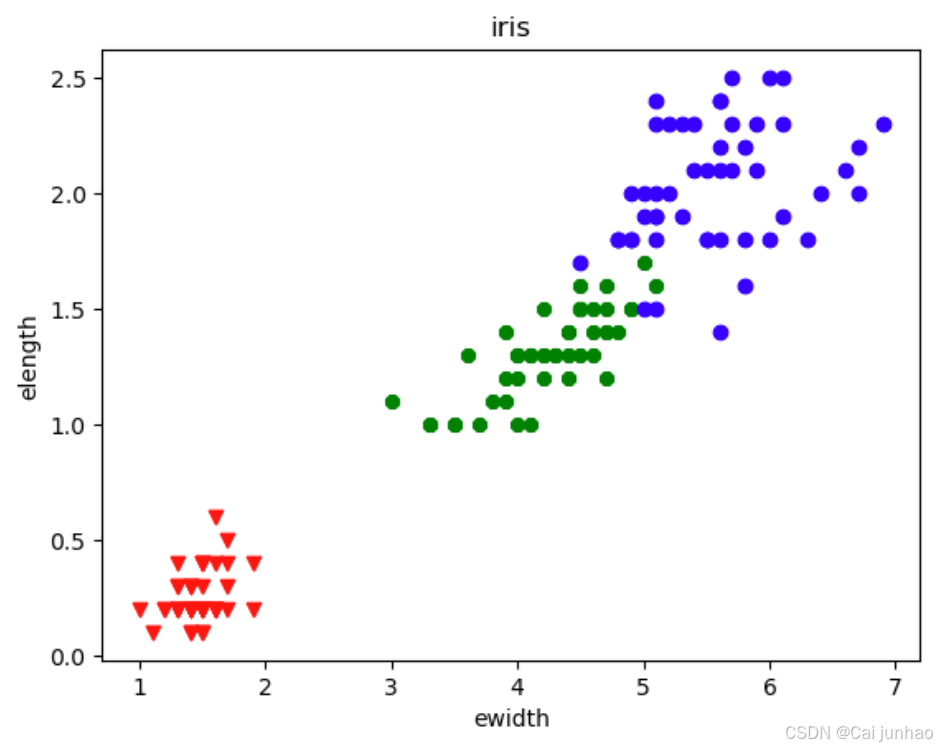
画出散点图,横轴表示萼片宽度,纵轴为萼片长度,倒三角为山鸢尾,绿色圆为北美鸢尾,蓝色圆为变色鸢尾。
代码如下:
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
iris=datasets.load_iris()
irisFeature=iris.data #特征:二维数组,150行4列
irisTarget=iris.target #标签
for i in range(len(irisTarget)): # 遍历每一个标签,即每一个样本的数据
if irisTarget[i]==0:
plt.scatter(irisFeature[i,2], irisFeature[i,3],c="r",marker="v") #花萼长当横坐标,花萼宽纵坐标,c=color颜色,marker点的形状
elif irisTarget[i]==1:
plt.scatter(irisFeature[i,2], irisFeature[i,3], c="g",marker="8")
else:
plt.scatter(irisFeature[i,2], irisFeature[i,3], c="b",marker="o")
plt.title("iris") # 给图取标题
plt.xlabel("ewidth")
plt.ylabel("elength")
plt.show() #显示出来
结果如图:

画出散点图,横轴表示花瓣宽度,纵轴为花瓣长度,倒三角为山鸢尾,绿色圆为北美鸢尾,蓝色圆为变色鸢尾。
from sklearn import datasets
from matplotlib import pyplot as plt
import numpy as np
iris=datasets.load_iris()
irisFeature=iris.data #二维数组,150行4列
irisTarget=iris.target #
for i in range(len(irisTarget)):
if irisTarget[i]==0:
plt.scatter(irisFeature[i,2], irisFeature[i,3],c="r",marker="v") #花瓣长当横坐标,花瓣宽纵坐标,c=color颜色,marker点的形状
elif irisTarget[i]==1:
plt.scatter(irisFeature[i,2], irisFeature[i,3], c="g",marker="8")
else:
plt.scatter(irisFeature[i,2], irisFeature[i,3], c="b",marker="o")
plt.title("iris") # 给图取标题
plt.xlabel("ewidth")
plt.ylabel("elength")
plt.show() #显示出来
结果如下: