
文章目录

💯前言
- DALL·E 3 是 OpenAI 最新的图像生成技术,通过对文本描述的深度理解和生成对抗网络(
GANs)的应用,能够快速生成高质量、细节丰富的图像。本文将从图像生成机制、分辨率与格式选择、多图生成功能、编辑器界面操作及API的使用等多个方面,全面解析 DALL·E 3 的功能与应用场景,为用户在创意设计、广告制作、教育与艺术创作等领域提供深入指导。DALL·E 3 是人工智能领域的一次重要突破,赋能用户实现创意与效率的双重提升。
DALL·E 3
💯DALL·E 3 图像生成介绍(Introduction to DALL·E 3 Image Generation)
- DALL·E 3 是 OpenAI 推出的全新图像生成模型,它在
文本理解能力和图像生成质量上达到了一个新的高度。通过先进的技术架构和精密的数据训练,DALL·E 3 能够根据用户输入的文本描述生成高质量、细节丰富且具有艺术美感的图像。
无论是创意设计、教育应用还是广告制作,DALL·E 3 都展现了其强大的实用性和广泛的应用前景,为用户提供了无限可能的创作工具。
DALL·E
图像质量与分辨率
分辨率的基本介绍
-
DALL·E 3默认生成的图像尺寸为 1024x1024 像素。这种分辨率在图像清晰度、生成速度和传输效率之间达到了良好的平衡,为设计师和艺术家提供了充足的细节,便于进一步创作和编辑。A highly detailed digital artwork, 1024x1024 pixels, showcasing a vibrant and dynamic futuristic cityscape with intricate architecture, neon lights, and bustling activity, perfectly balancing clarity and artistic creativity.

WebP 格式的优势
DALL·E 3采用 WebP 文件格式生成图像。相比传统的 PNG 格式,WebP 支持无损和有损压缩,在保持相同图像质量的前提下文件更小、加载速度更快。这使得 WebP 格式在网络传输中更加高效,同时保证了优秀的视觉效果。A digital poster in WebP format of a breathtaking tropical rainforest, featuring vivid green foliage, exotic flowers, crystal-clear streams, and detailed textures of tree bark, optimized for online use with exceptional visual clarity and reduced file size.

高分辨率选项
- 对于对图像质量要求更高的用户,
DALL·E API提供了多种高分辨率选项,适用于广告设计、高质量打印等专业需求。这些选项能够生成更加细腻的图像细节,通过DALL·E API,用户可以灵活选择适合自己项目的分辨率,全面满足高标准的质量需求。An ultra-high-definition 4K cinematic landscape of a serene mountain range at sunrise, with every detail of the snowy peaks, golden sunlight, and misty valleys meticulously rendered, designed for large-scale printing and exhibition purposes.

图像生成机制的解析
DALL·E 3 使用 生成对抗网络(GANs) 技术,由 生成器 和 判别器 两部分组成:
- 生成器:根据输入的文本描述生成逼真的图像。
- 判别器:判断生成的图像是否与人工创作一致。
通过生成器和判别器的对抗训练,模型逐步学习如何生成越来越精确且逼真的图像。
模型训练和数据处理
DALL·E 3 的训练依赖于海量的图像及其对应的文本描述,这些数据涵盖了不同的背景和主题。通过大规模训练,模型能够理解复杂的文本描述,并将其转化为相应的视觉元素。
例如,输入文本 “手拿苹果的小女孩” 时,模型会识别关键内容:
-
“手”
-
“苹果”
-
“小女孩”
-
然后基于这些关键词生成符合描述的图像。
A little girl holding a bright red apple in her small hands, standing in a serene orchard surrounded by apple trees, golden sunlight streaming through the branches. Her cheerful expression and detailed traditional dress bring the scene to life, capturing the harmony of nature and innocence.

迭代优化和结果精细化
在图像生成过程中,DALL·E 3 进行多轮迭代优化,确保生成的图像不仅符合文本描述,还具有一定的艺术美感。
优化过程包括:
- 调整色彩和光影
- 精细化构图与细节
A hyper-realistic portrait of a majestic lion basking under the golden glow of the sunset, with every detail meticulously rendered—from the soft texture of its mane to the reflective gleam in its amber eyes. The lighting, shadows, and color tones are perfectly balanced, blending realism with artistic elegance.
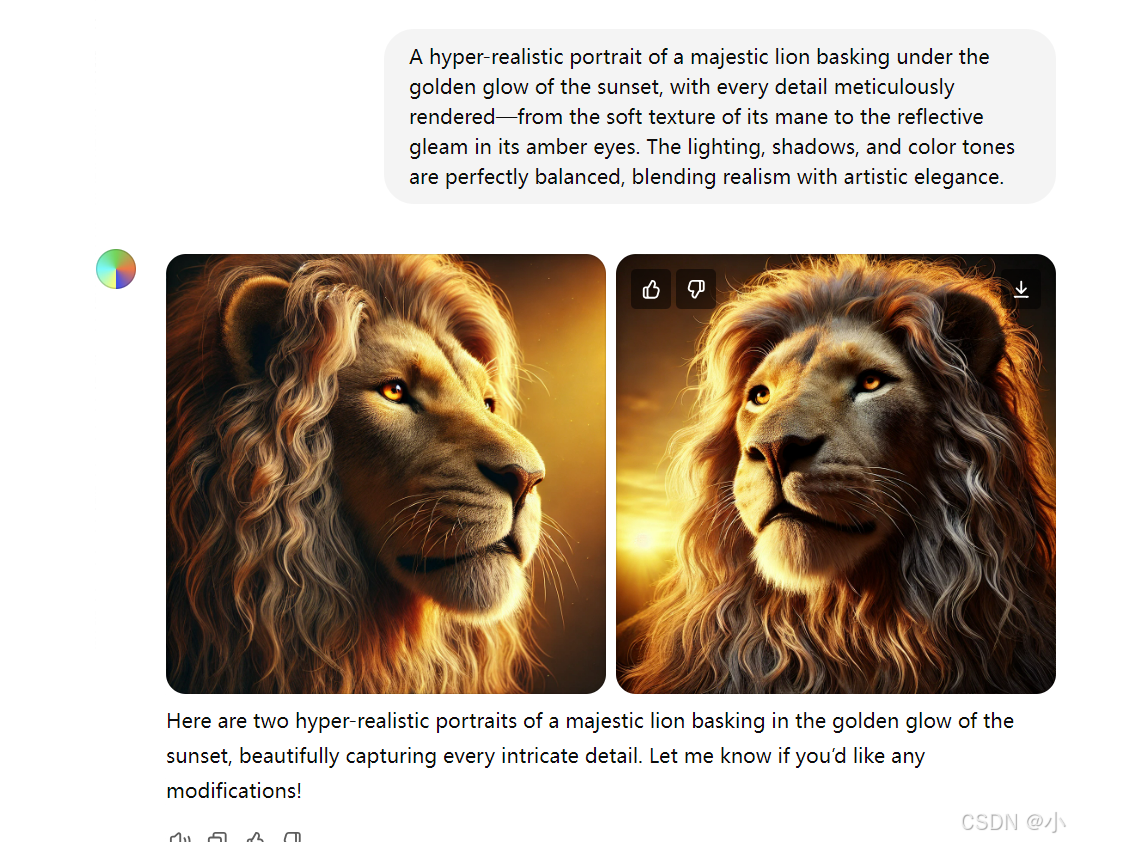
最终生成的图像兼具真实性与艺术吸引力,每次生成的结果都会进一步提升模型的理解和生成能力。
多图生成功能
功能概述
多图生成功能允许用户通过一个文本提示生成多张图像,非常适用于广告创意、艺术探索和教学演示等需要多样视觉表现的场景。用户只需提供简单指令,例如:
- “生成两张描绘不同天气的城市街道的图像”,就可以获得多样化的视觉输出,满足创作需求。
Generate two illustrations of the same urban street, one during a bright and sunny morning with vibrant colors, bustling activity, and clear blue skies; the other on a rainy evening, featuring wet pavement reflecting city lights, people with umbrellas, and a moody atmosphere with diffused light and gray tones.
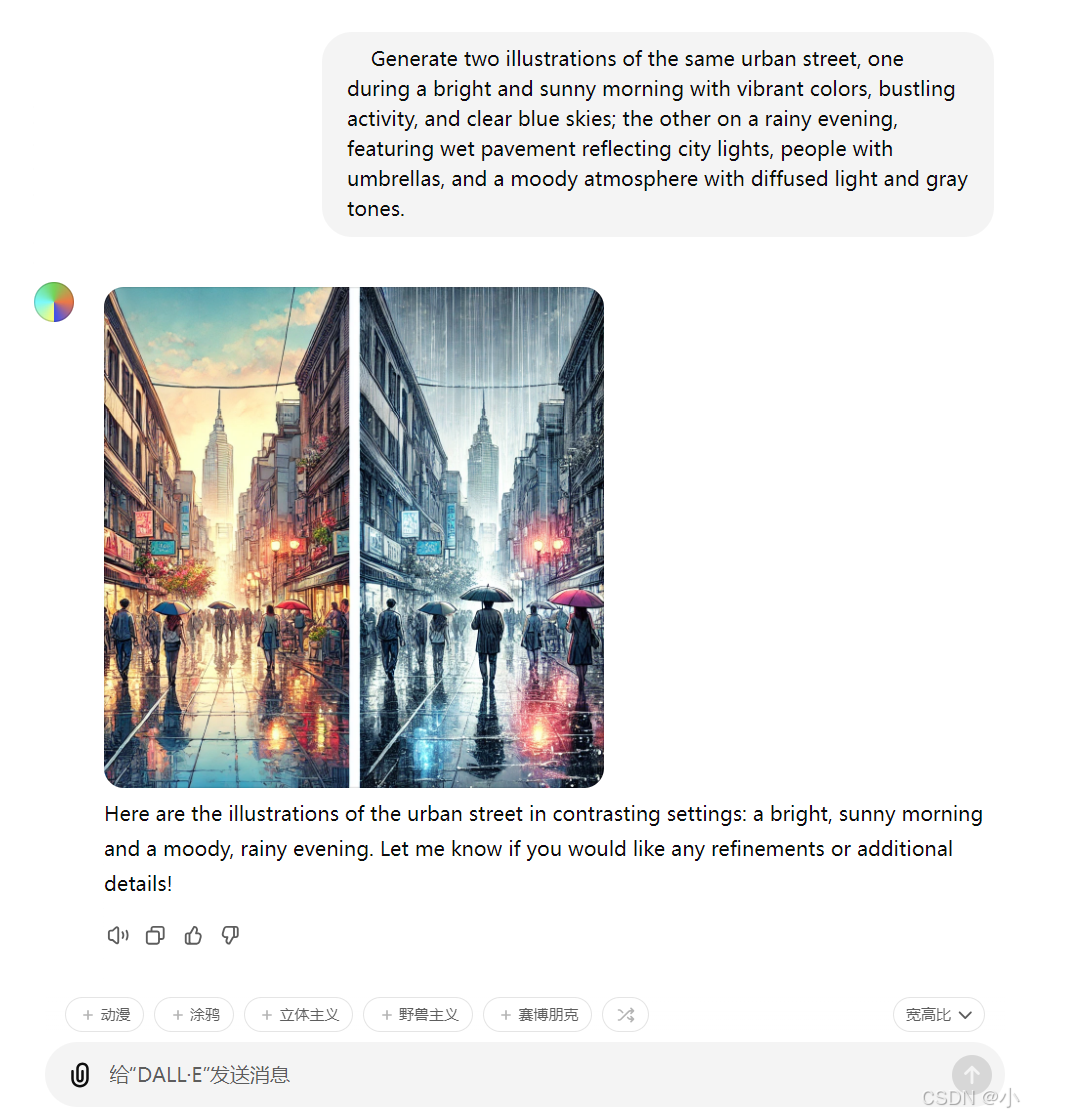
创意和变体的生成
在生成多张图像时,DALL·E 3 会引入变体,使每张图像独特而又风格统一。例如:
用户输入指令:
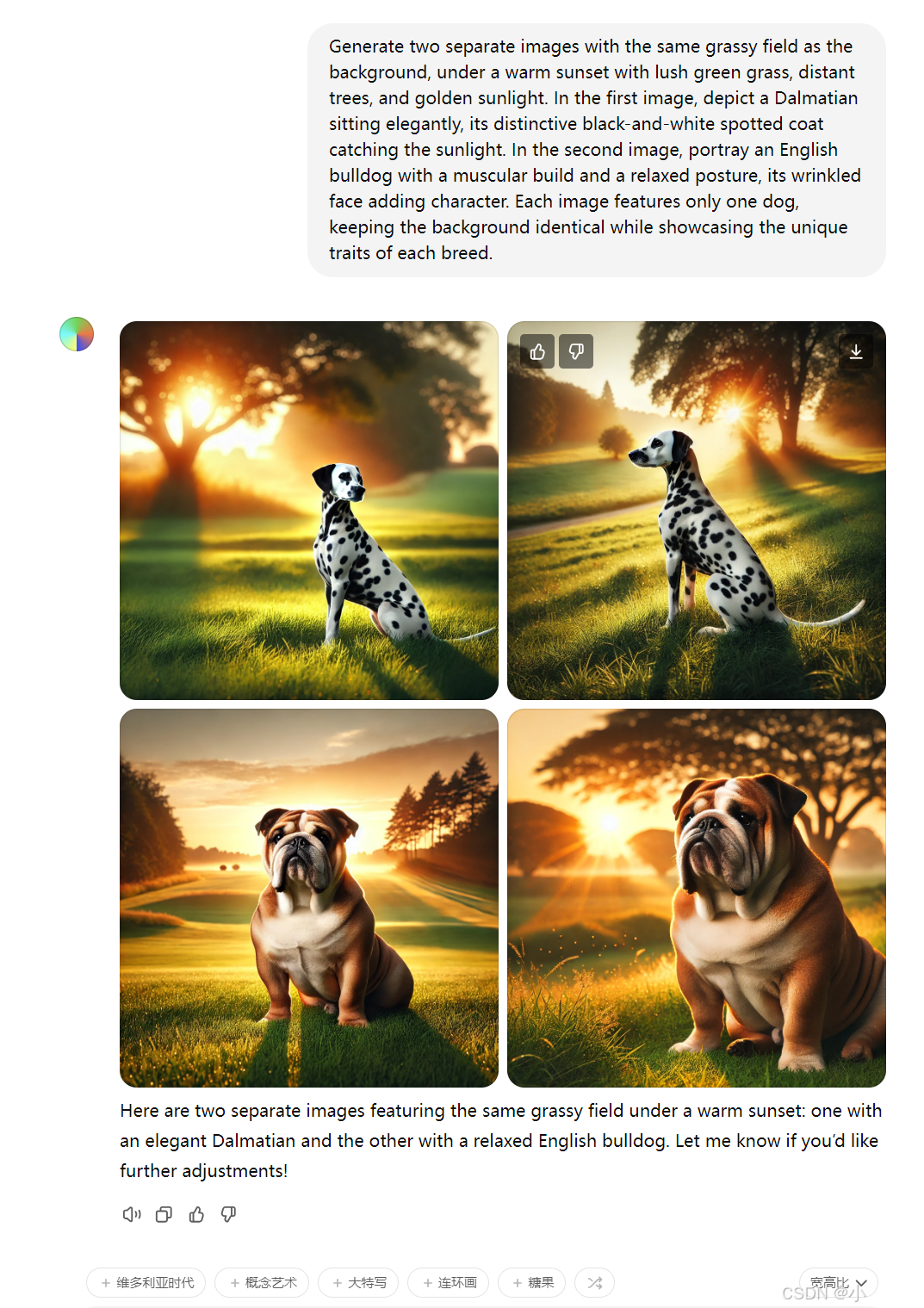
- “两张坐在草地上的狗的图像,第一张是斑点狗,第二张是斗牛犬”,
DALL·E 3将生成两张图像,分别展示斑点狗和斗牛犬在类似环境中的不同表现,从而体现创意的多样性和细节的差异化。Generate two separate images with the same grassy field as the background, under a warm sunset with lush green grass, distant trees, and golden sunlight. In the first image, depict a Dalmatian sitting elegantly, its distinctive black-and-white spotted coat catching the sunlight. In the second image, portray an English bulldog with a muscular build and a relaxed posture, its wrinkled face adding character. Each image features only one dog, keeping the background identical while showcasing the unique traits of each breed.
应用案例和实践建议
多图生成功能能够支持用户在设计和内容创建过程中进行视觉比较与筛选。以下是一些实际应用场景和建议:
- 创意发展:在设计初期快速生成多种概念图,通过比较选择最佳方案。
Generate four different concept illustrations for a futuristic urban skyline. Each image features a distinct design approach: one with sleek glass skyscrapers and hovering drones, one with eco-friendly vertical gardens integrated into the architecture, one with vibrant neon lights in a cyberpunk aesthetic, and one with minimalist white futuristic domes under a bright blue sky. Focus on presenting varied styles to inspire creative development.

- 市场营销:为不同市场生成多种广告概念图,从中挑选最符合目标群体需求的方案。
Generate three advertising poster concepts for a luxury perfume. The first image showcases a minimalist black-and-gold design with a glowing perfume bottle surrounded by abstract geometric shapes. The second features a romantic, pastel-themed background with soft flower petals encircling the bottle. The third is bold and dramatic, with a dark stormy backdrop and lightning illuminating the bottle in vivid detail. Each image caters to a distinct target audience.

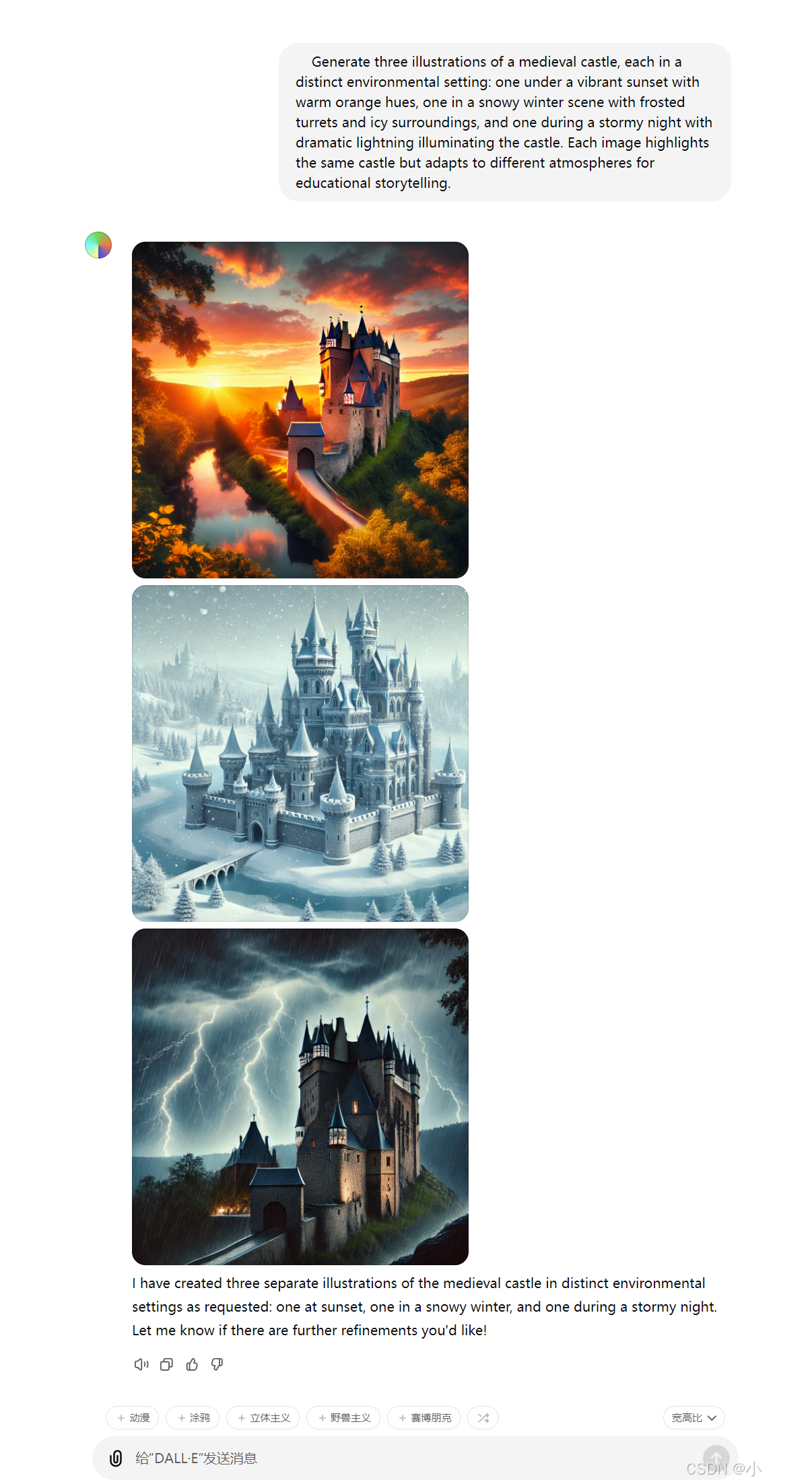
- 教学与展示:用于演示相同主题在不同风格、环境或场景下的表现,丰富课堂教学或艺术展示内容。
Generate three illustrations of a medieval castle, each in a distinct environmental setting: one under a vibrant sunset with warm orange hues, one in a snowy winter scene with frosted turrets and icy surroundings, and one during a stormy night with dramatic lightning illuminating the castle. Each image highlights the same castle but adapts to different atmospheres for educational storytelling.
这一功能的多样化输出可以显著提升创作效率,并助力用户更好地实现创意目标。
💯使用 DALL·E 编辑器界面(Using the DALL·E Editor Interface)
编辑器界面概述
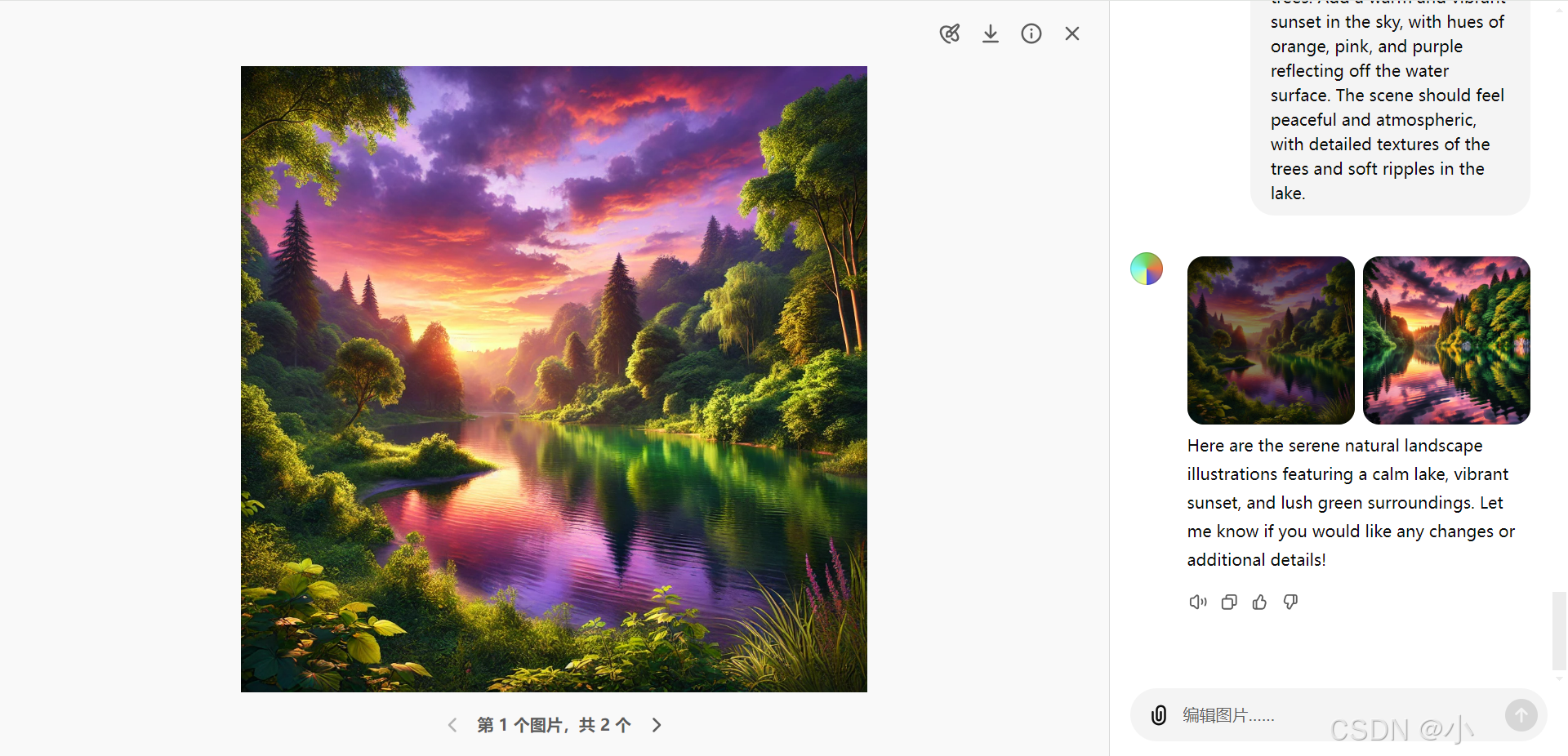
DALL·E 编辑器 提供了一个直观且易于操作的界面,用户可以:
- 选择图像的特定区域并应用不同的编辑操作。
- 支持添加、删除或修改图像的某些部分,以满足个性化定制需求。
- 为用户提供了灵活的图像编辑功能,适合创意设计与精细化调整。
A serene natural landscape featuring a calm lake surrounded by dense green trees. Add a warm and vibrant sunset in the sky, with hues of orange, pink, and purple reflecting off the water surface. The scene should feel peaceful and atmospheric, with detailed textures of the trees and soft ripples in the lake.

编辑工具
编辑器配备了一系列高效工具,帮助用户实现多种操作:
- 选择工具:精确选定图像中的特定区域。
- 大小调整:轻松调整选定区域的尺寸。
- 撤销与重做:确保操作可以快速回溯或重复。
- 清除选择:重置当前选定区域。
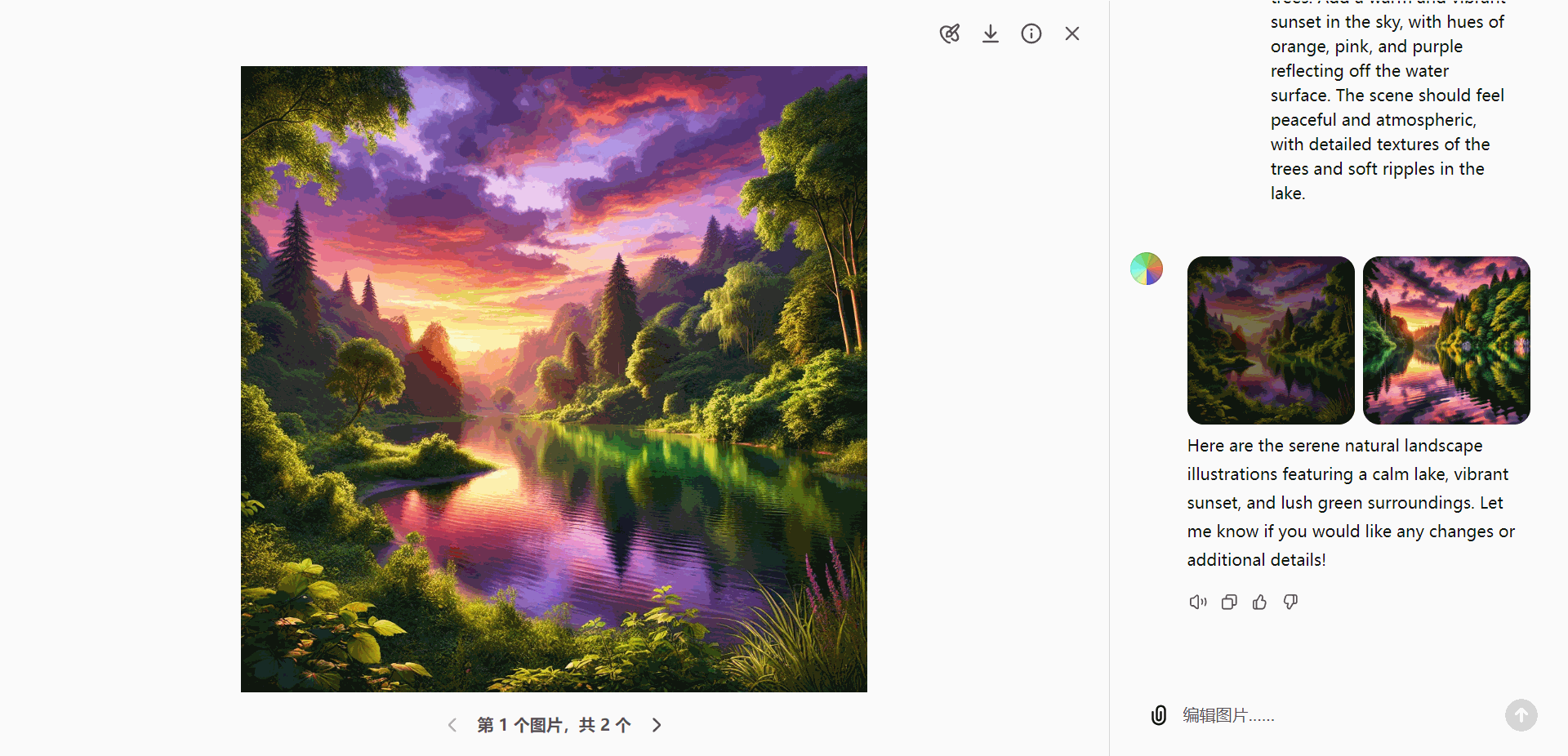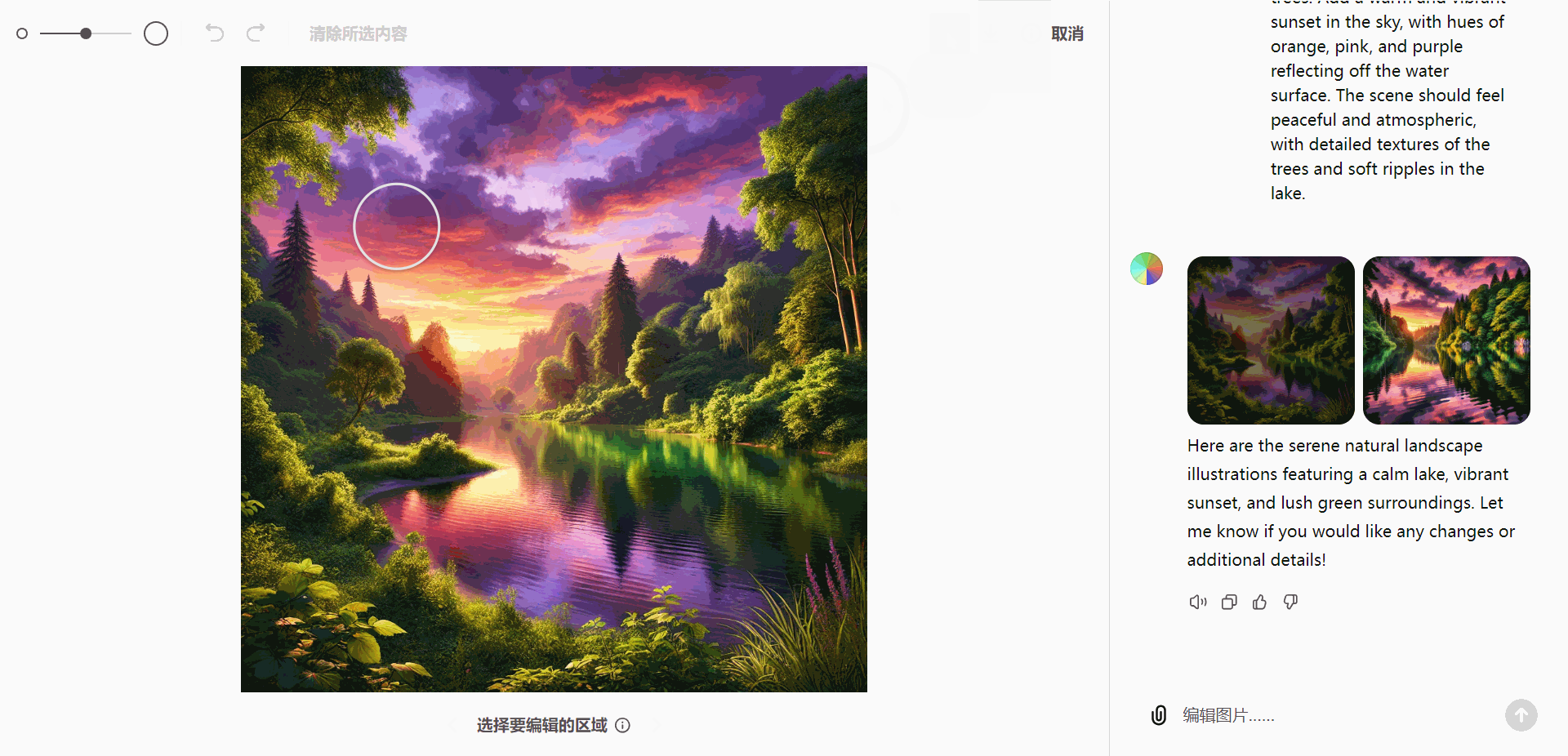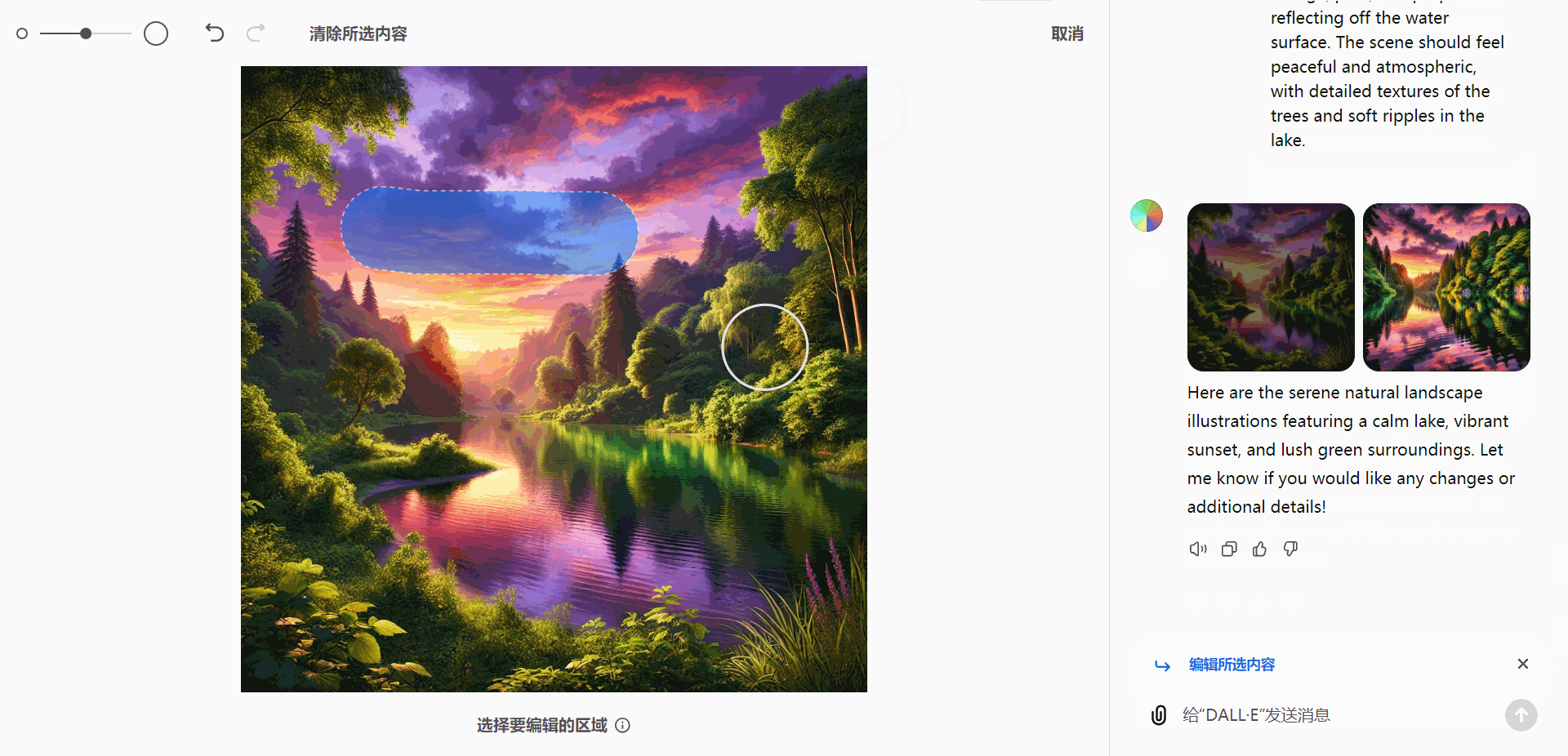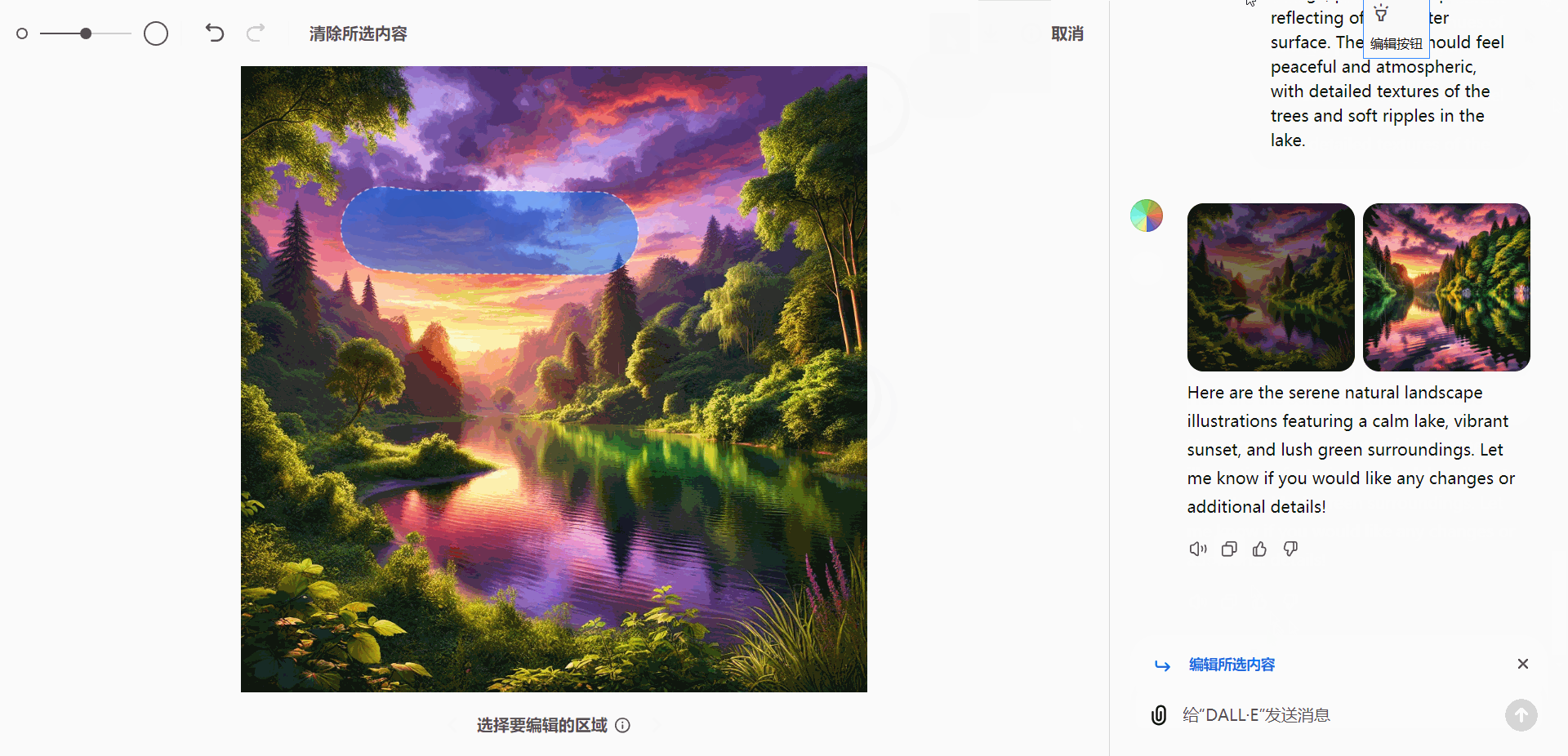
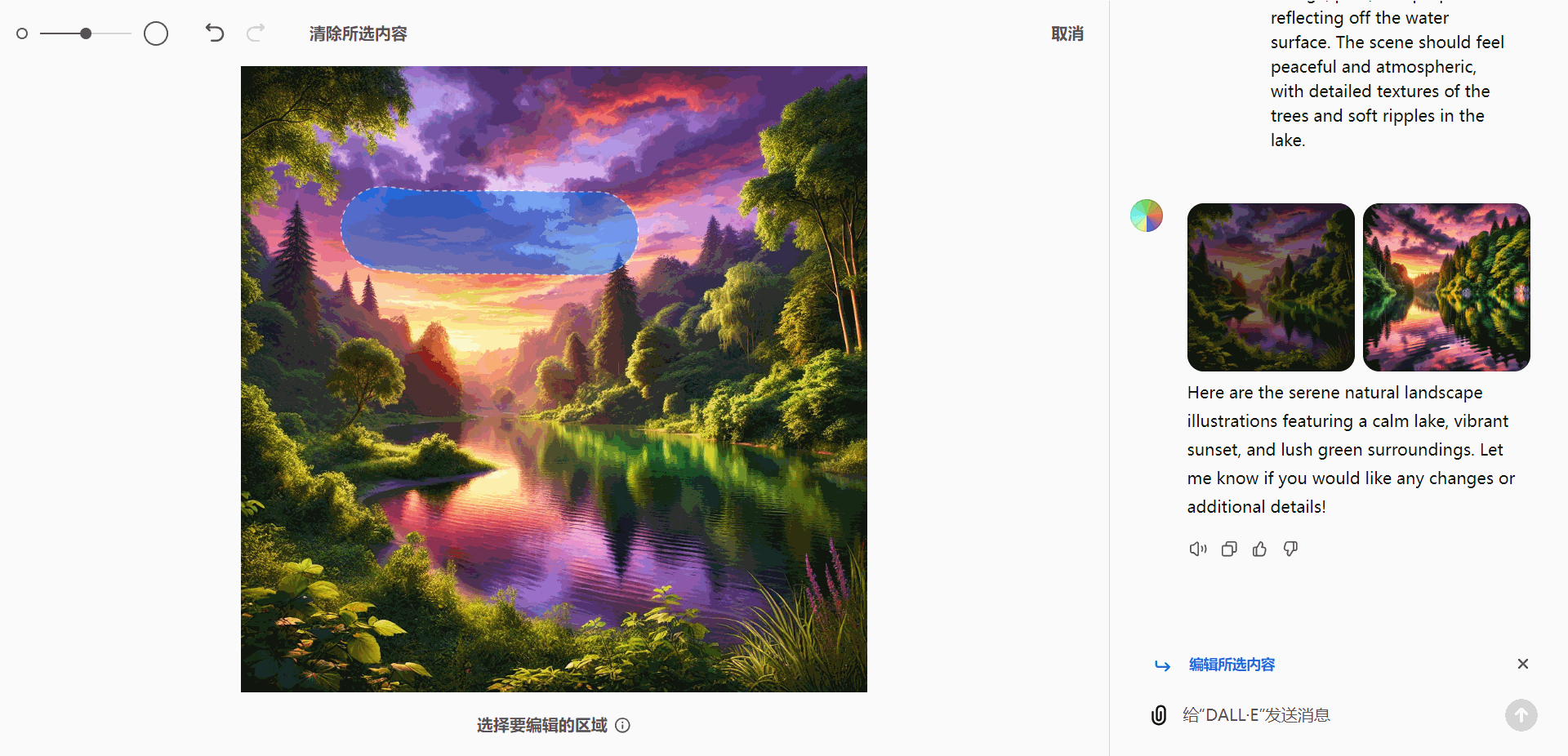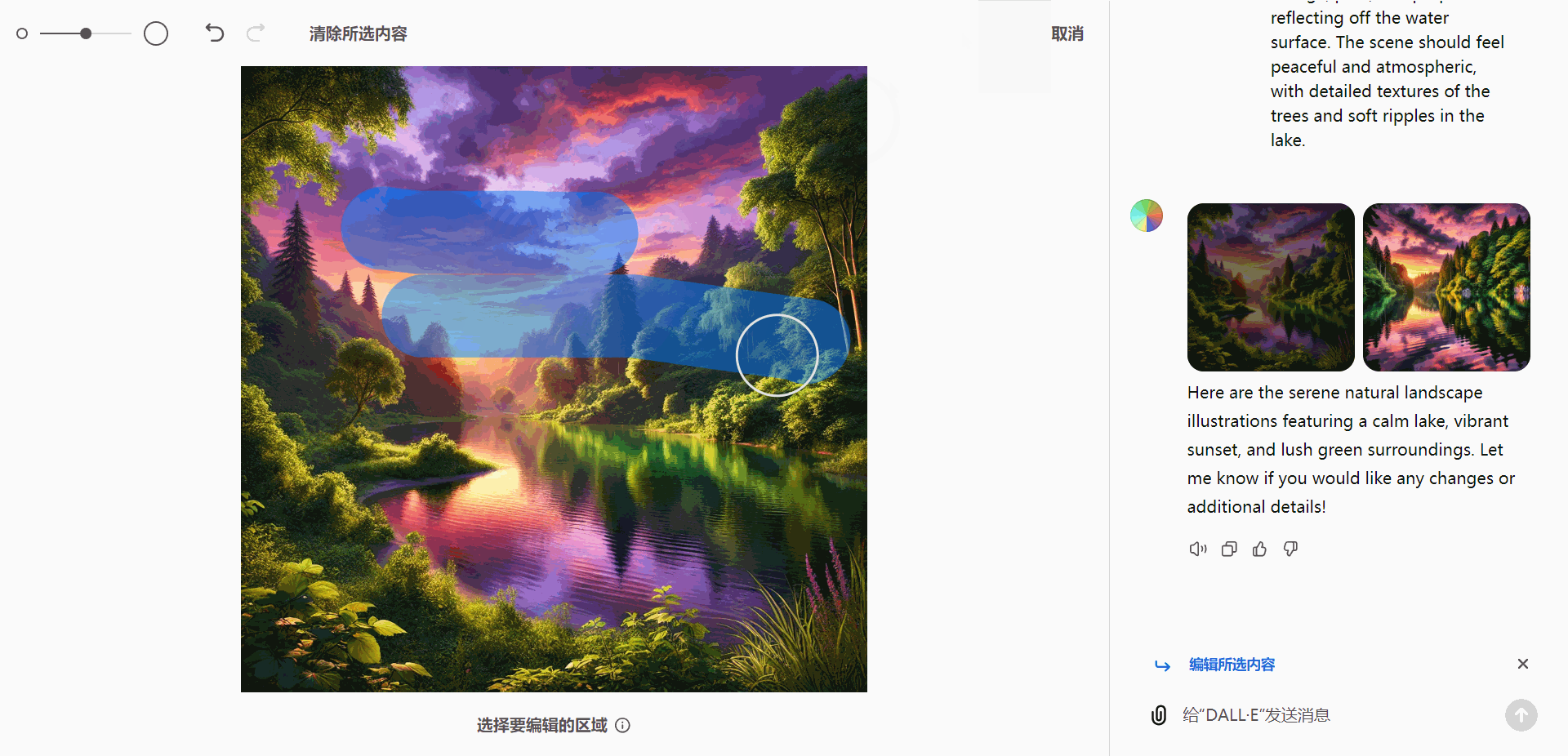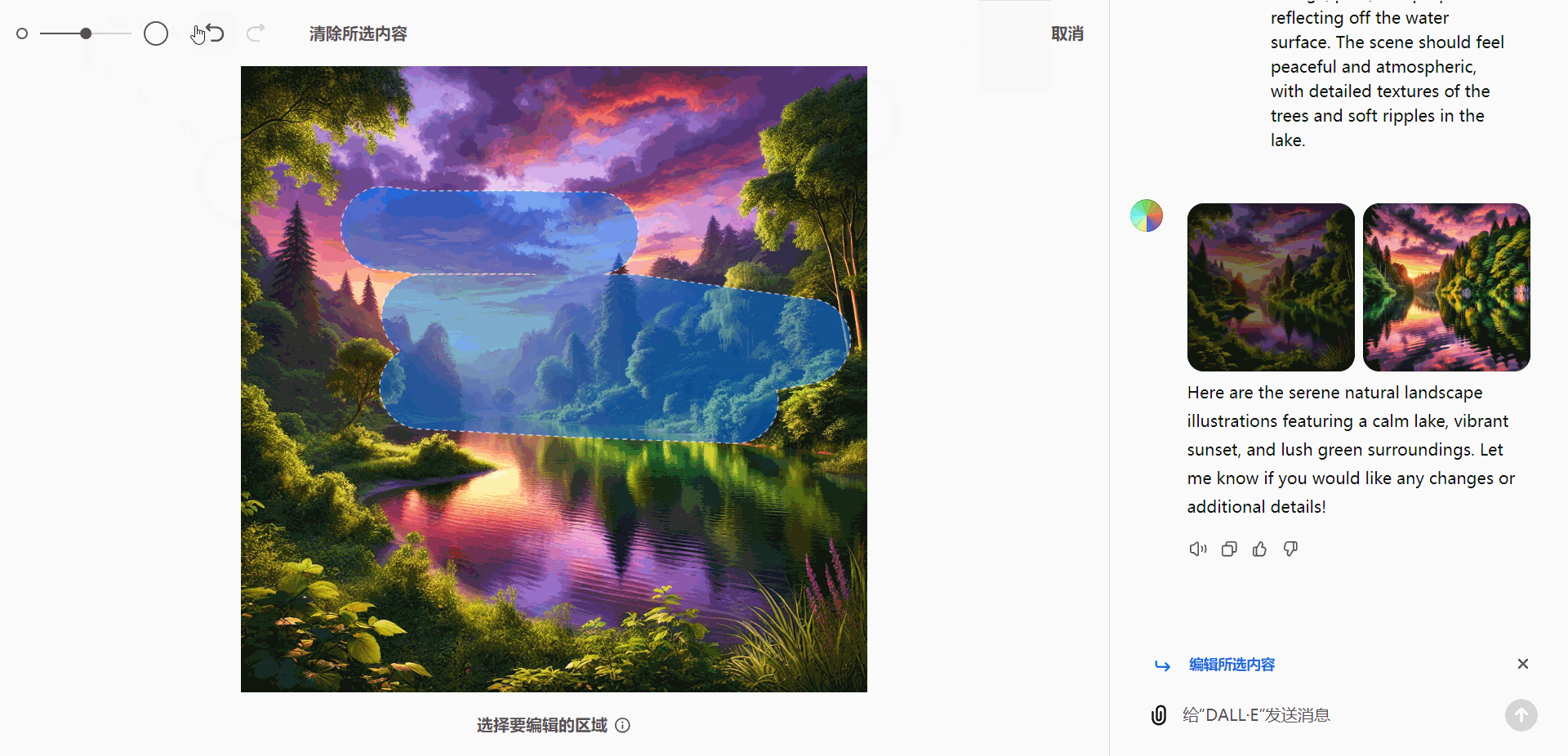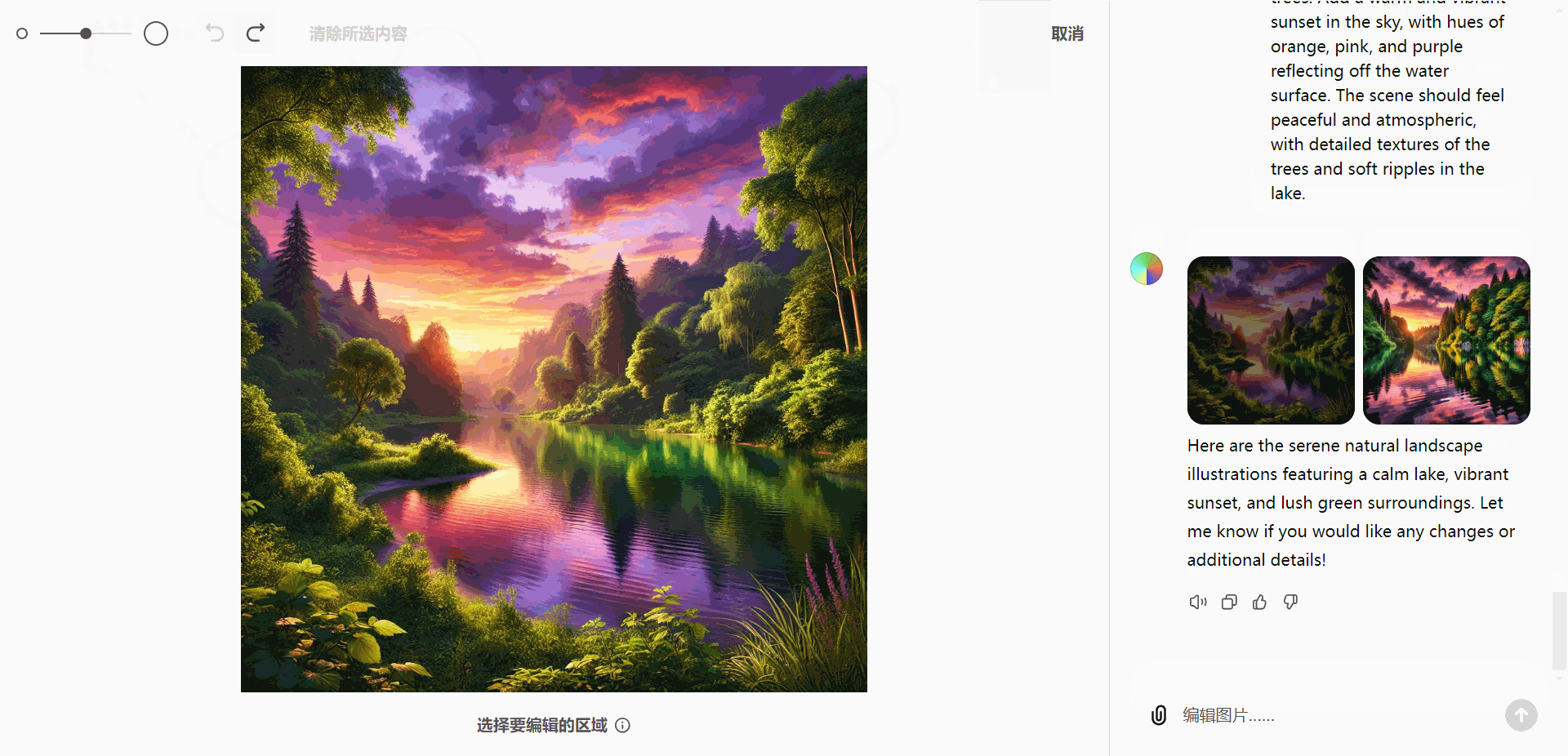
这些工具赋予用户全面的编辑控制能力,方便灵活定制图像效果。
高级编辑技巧
DALL·E 编辑器 不仅适用于基础操作,还支持以下高级编辑技巧:
- 调整色彩平衡:改变图像的整体色调和氛围。
- 增强特定细节:突出图像中的关键元素。
- 更改图像构图:优化视觉效果,提升艺术表现力。
实际应用
编辑器的功能可广泛应用于多种创作场景:
- 优化自然景观:选择图像中的天空,并添加日落效果,提升画面氛围。
- 动态人物调整:选中图像中的人物,更改其表情或姿态。
- 提升图像适配性:通过编辑调整,使图像更适合不同的上下文需求。
A calm natural landscape featuring a serene lake surrounded by dense green trees and distant mountains under a clear blue sky. The water is still, reflecting the surrounding scenery, creating a peaceful and untouched atmosphere.

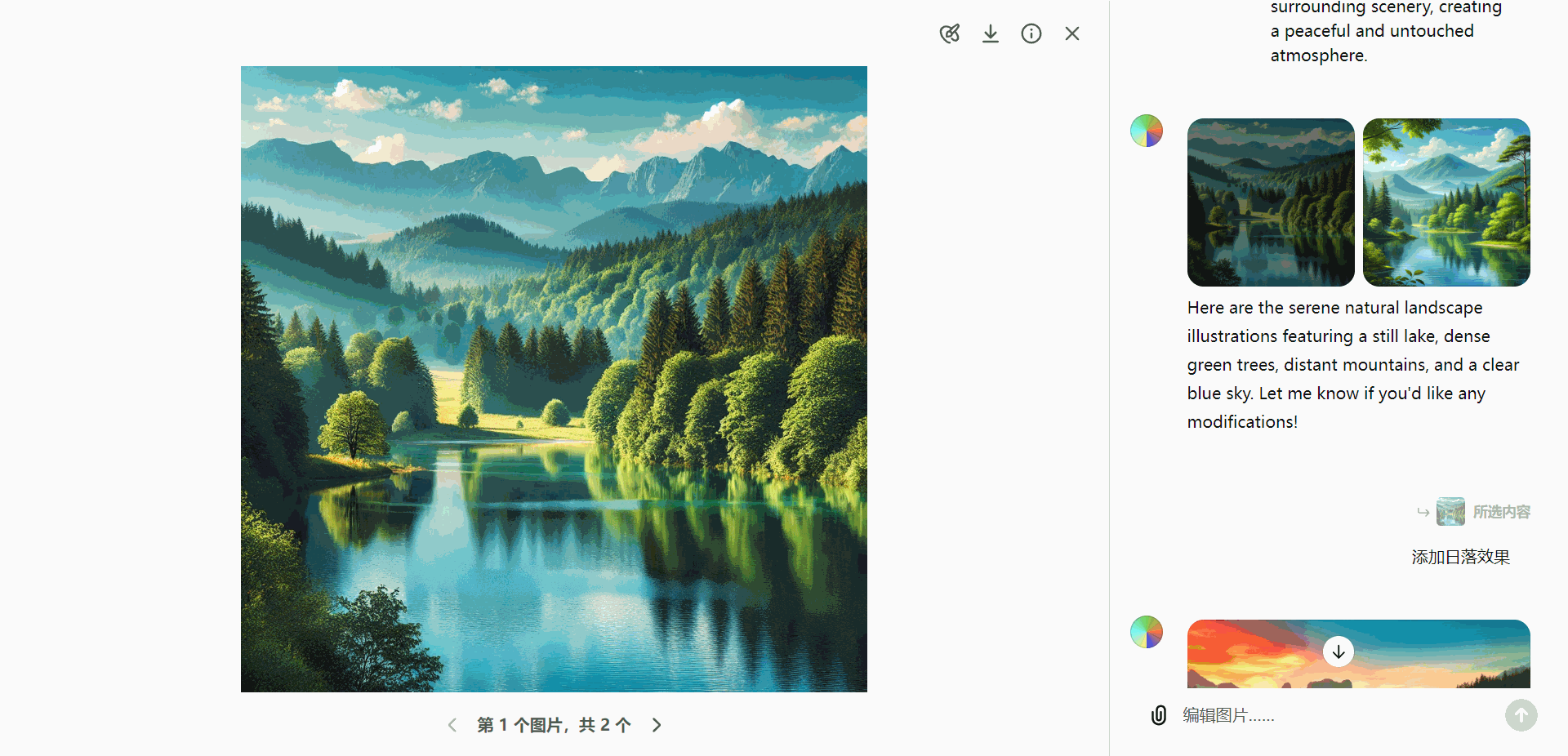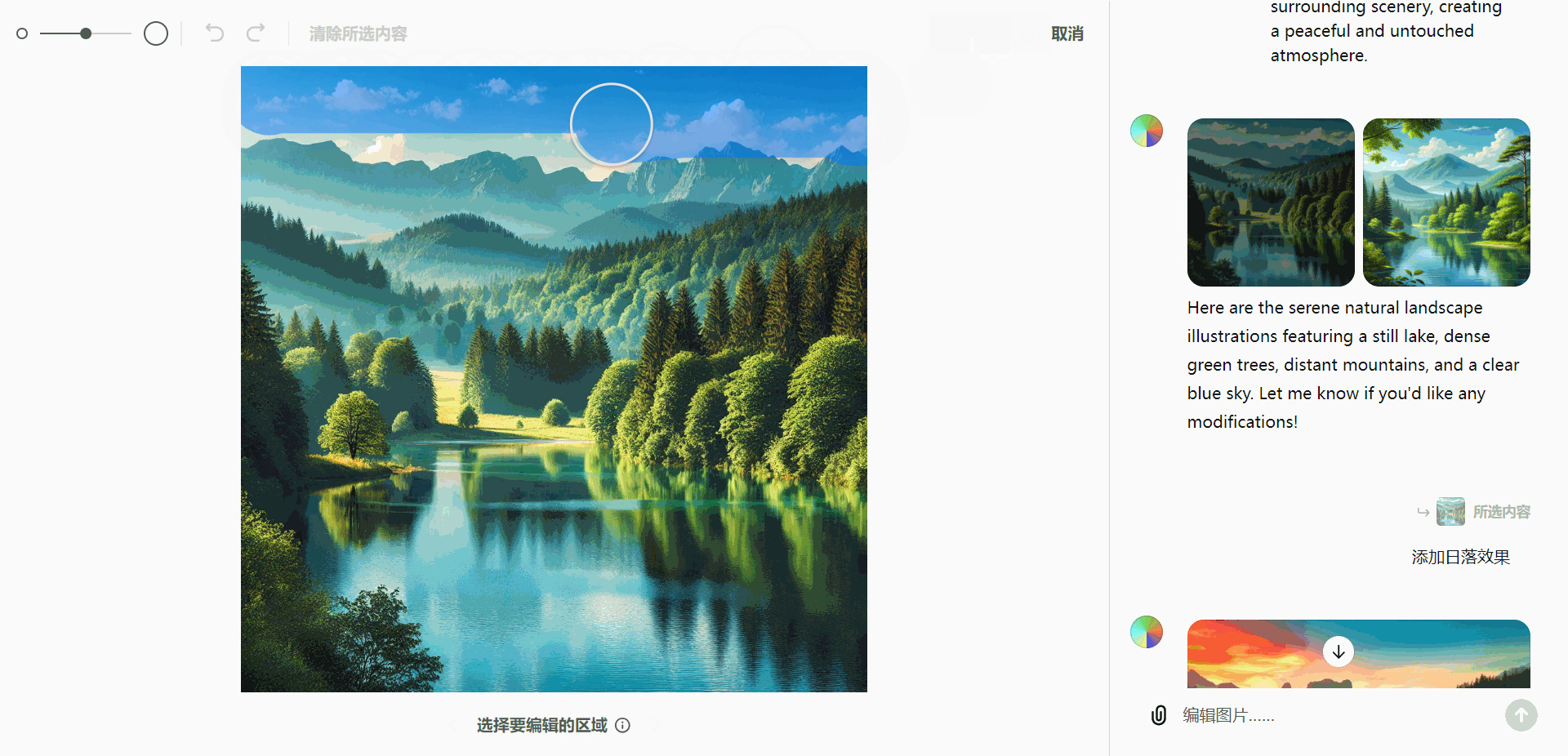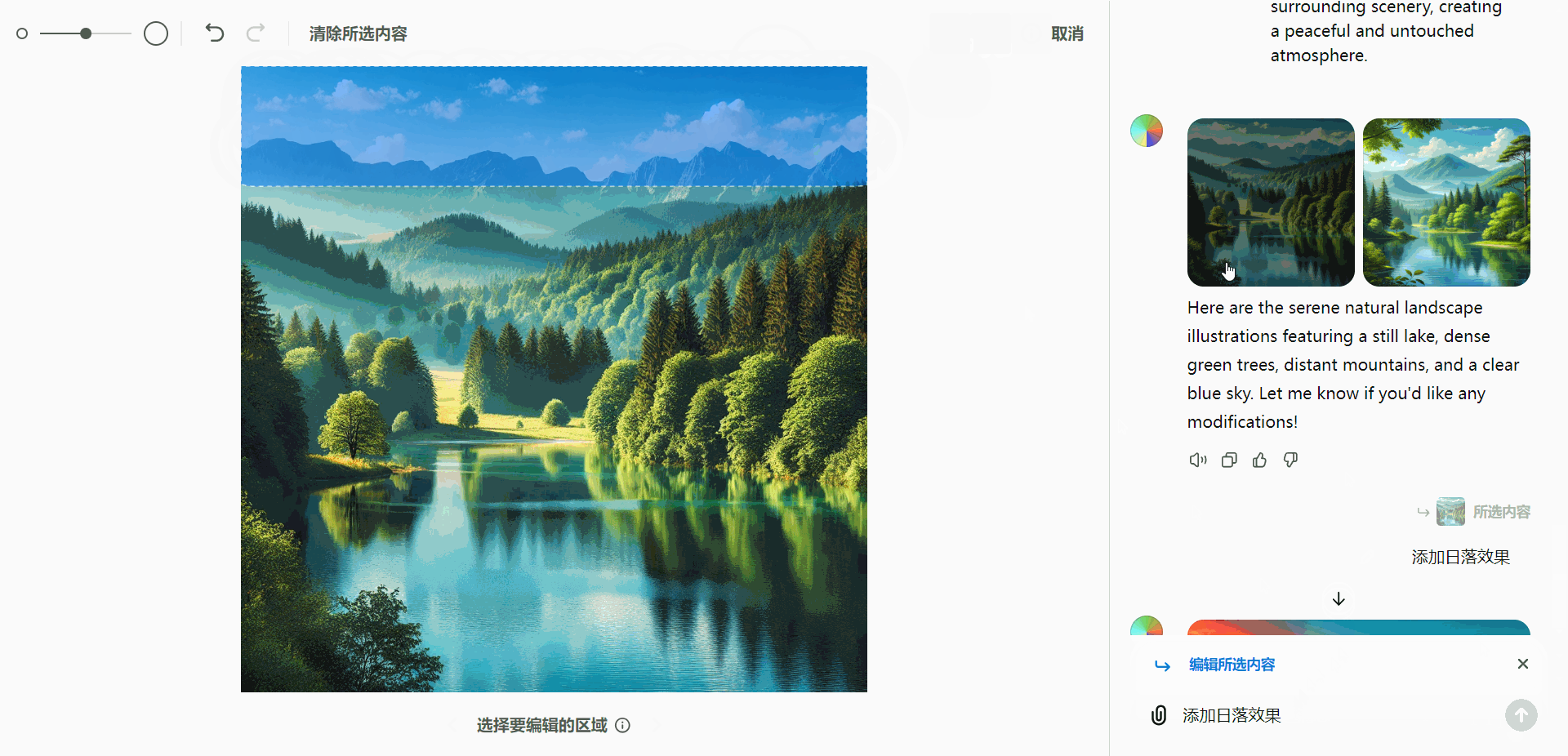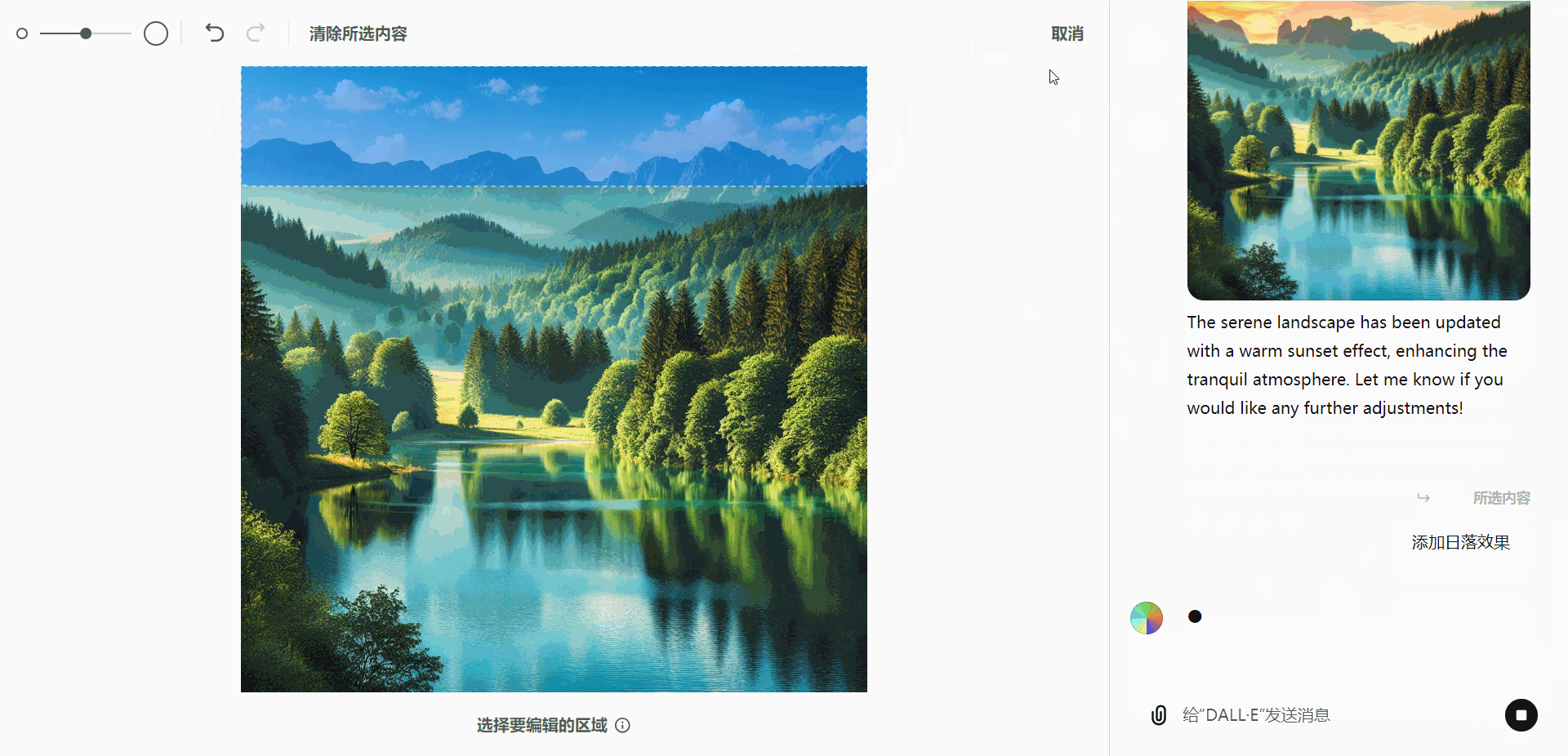
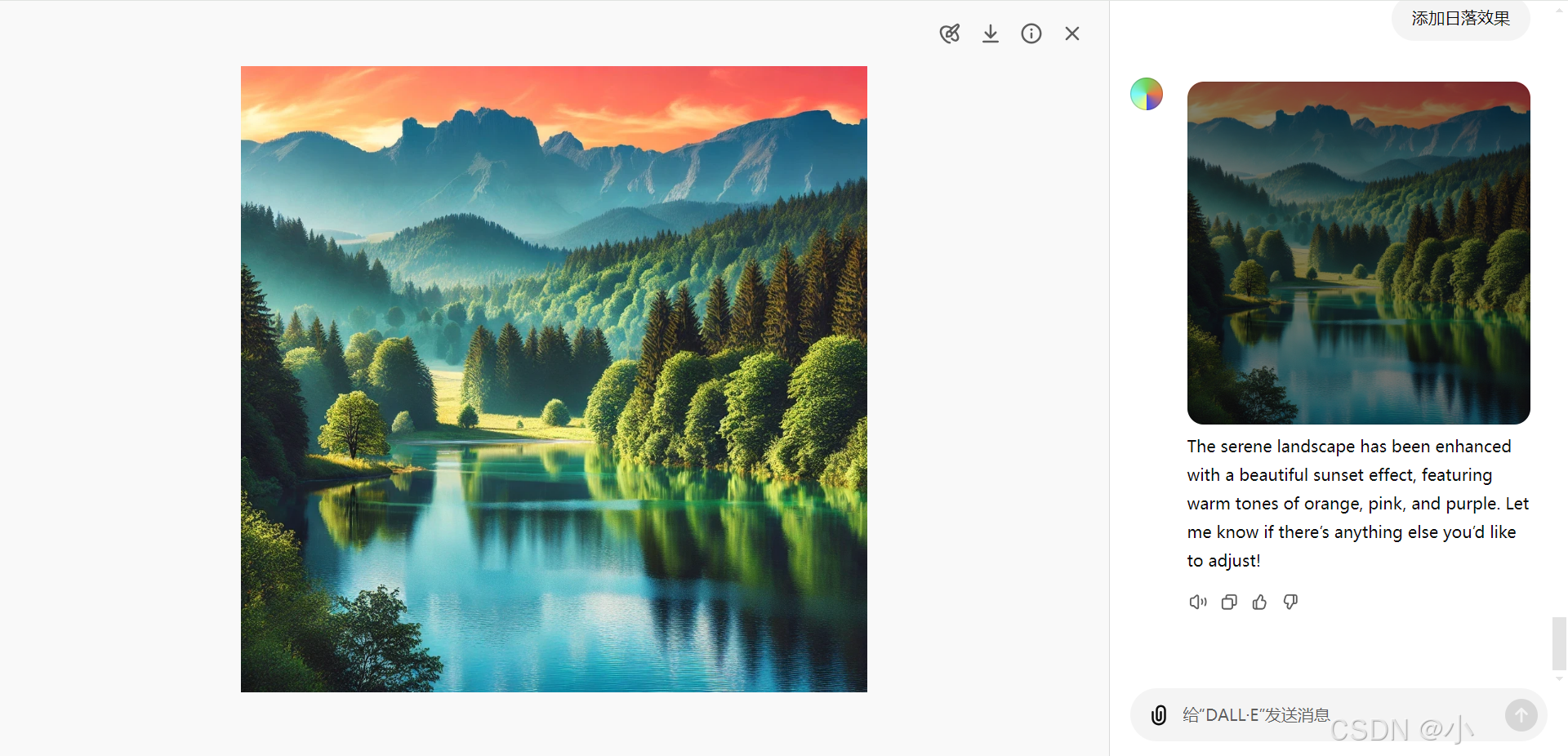
实际应用示例
DALL·E 编辑器 的实际应用场景涵盖了对象移除和新元素添加等操作:
- 移除对象:
假设生成的图像中包含一只鸟,而用户希望去除这只鸟:- 使用选择工具高亮显示鸟的部分。
- 发送“删除对象”指令,即可移除该部分内容。
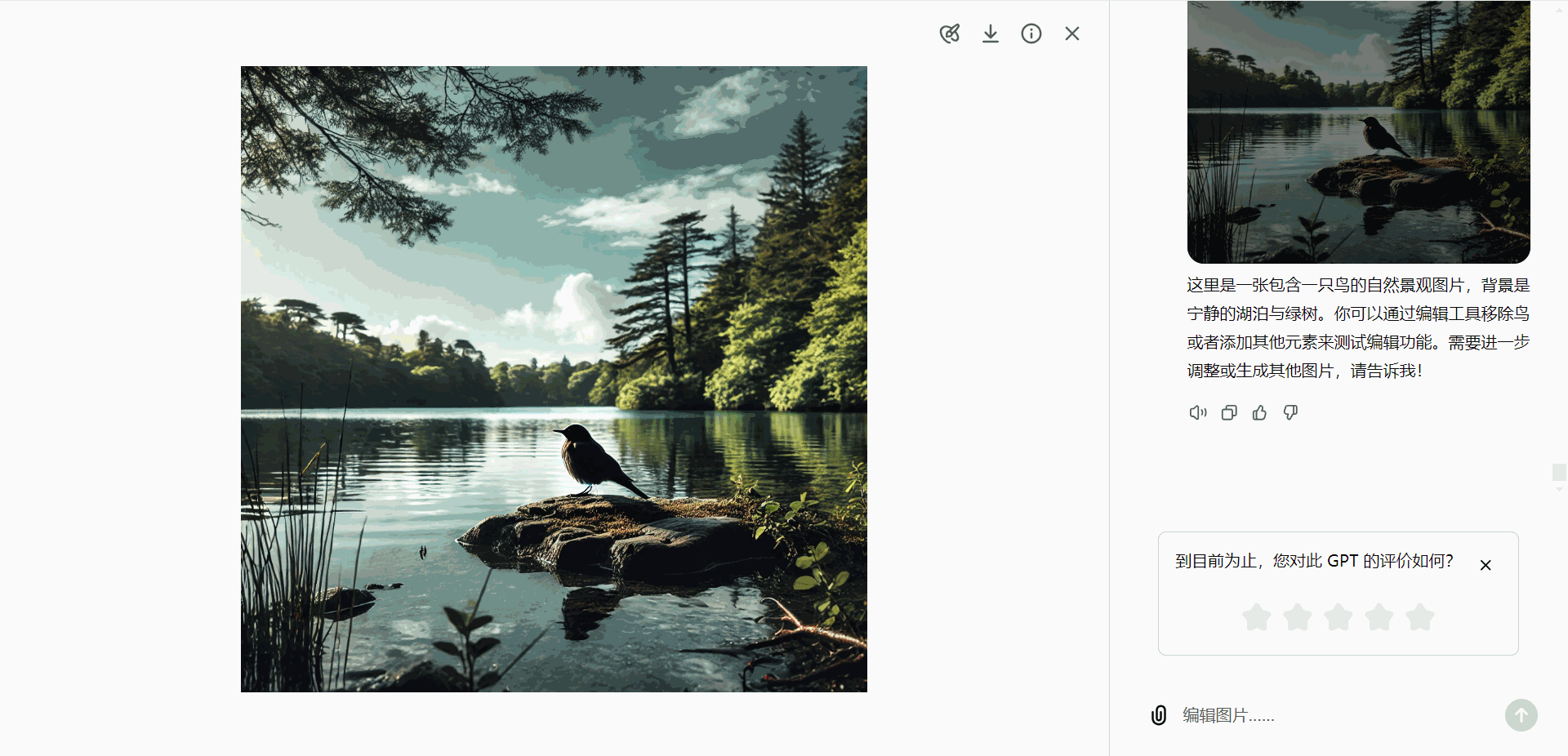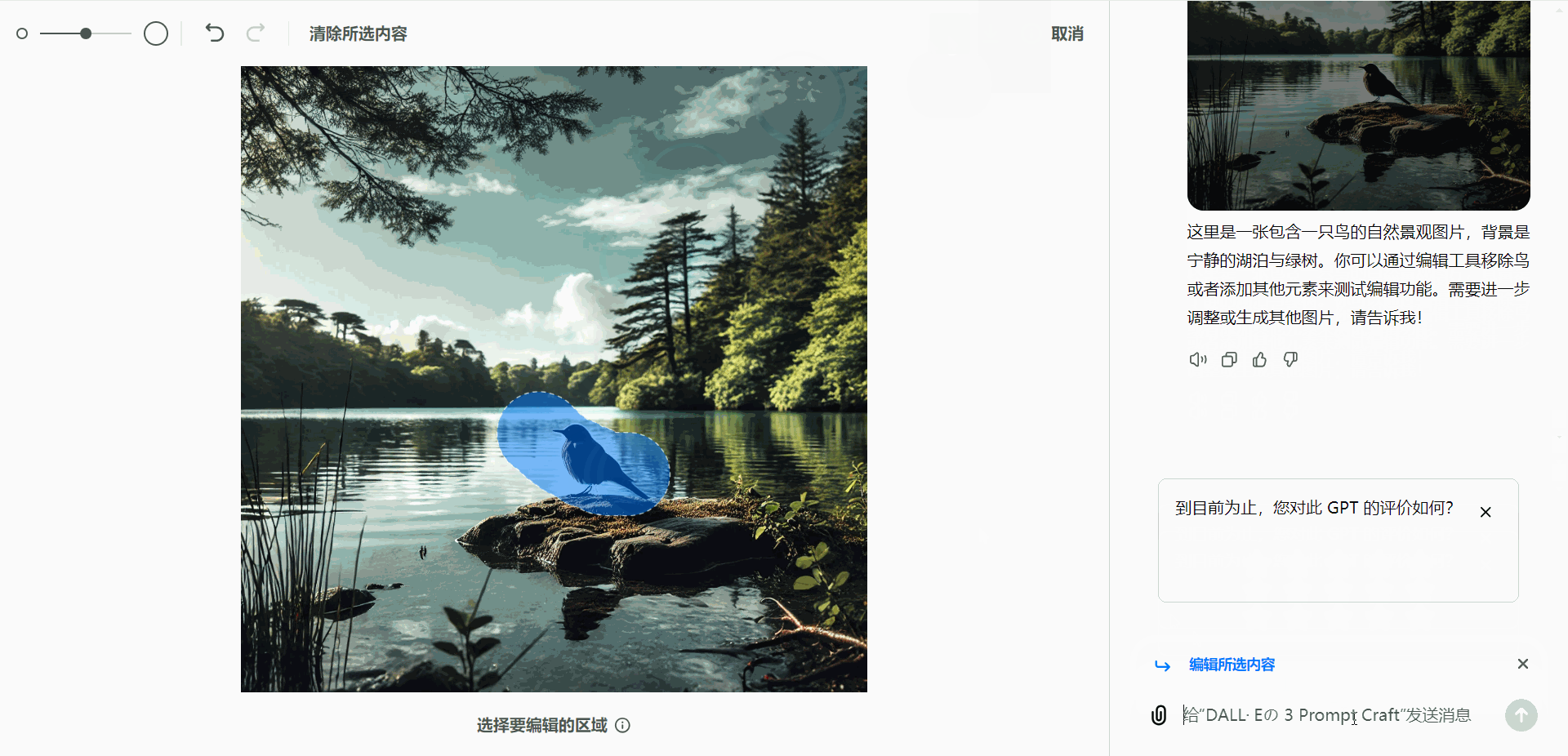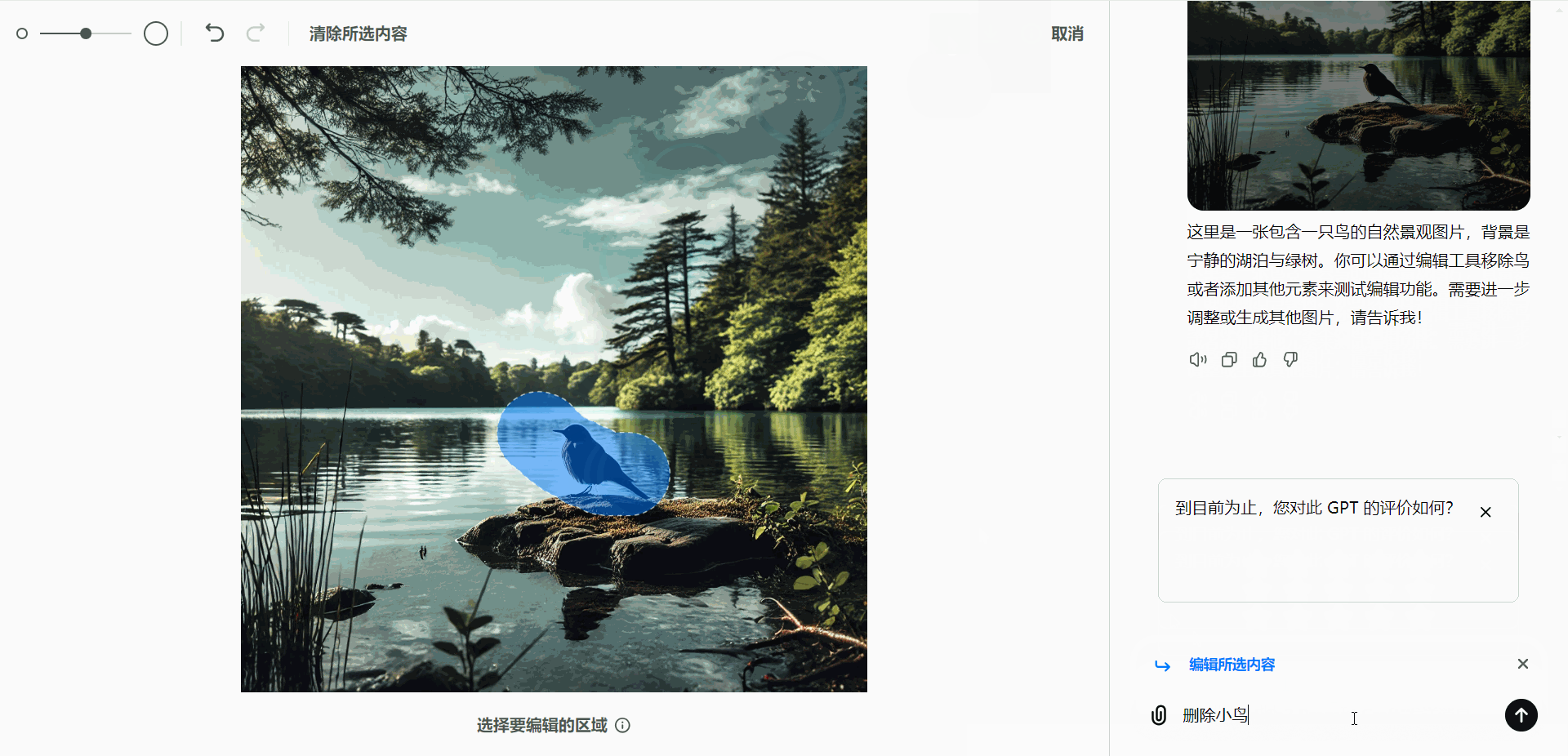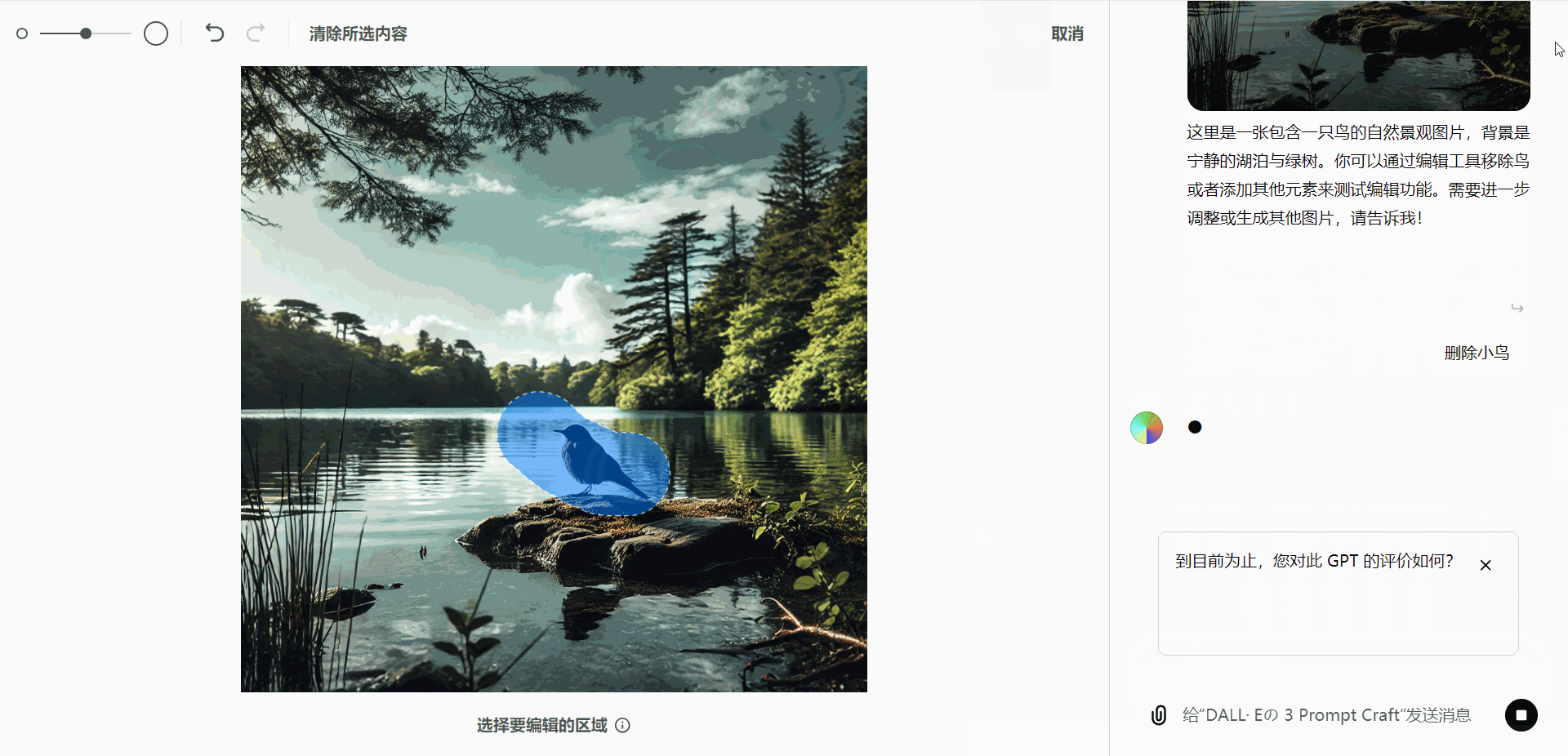
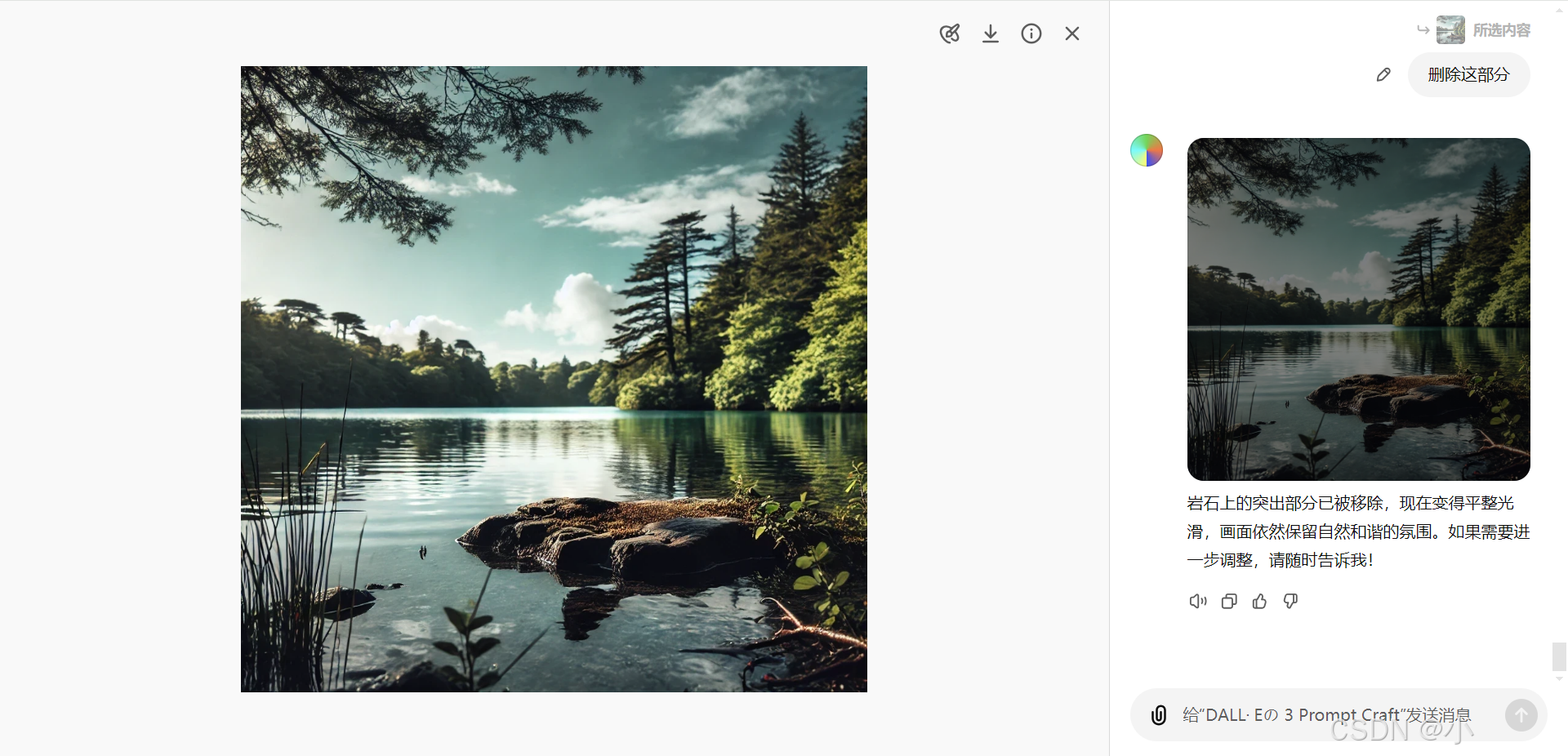
- 添加新元素:
如果用户需要在图像中添加元素(如飞机):- 选择需要添加的区域。
- 输入相应的编辑指令,即可生成并插入新元素。
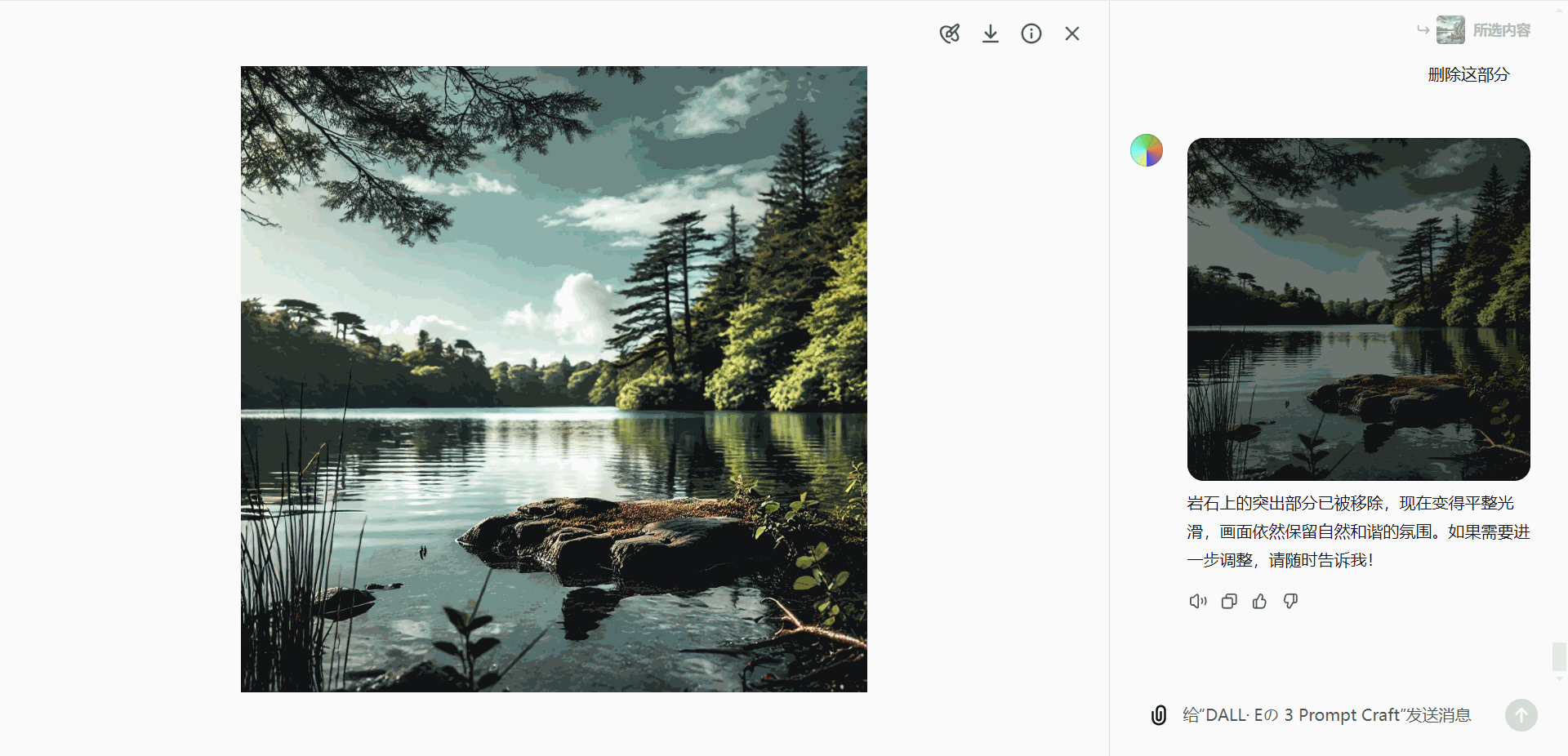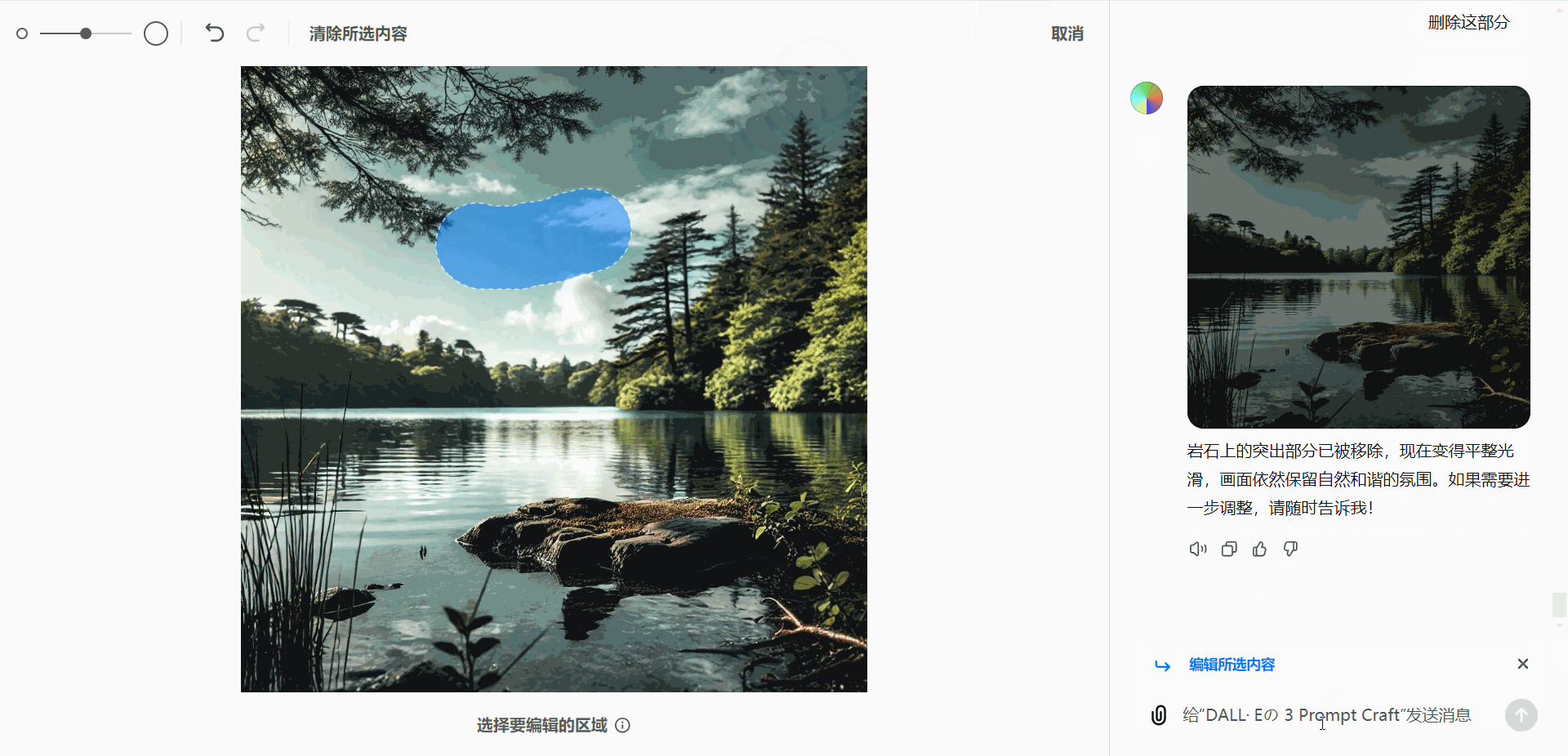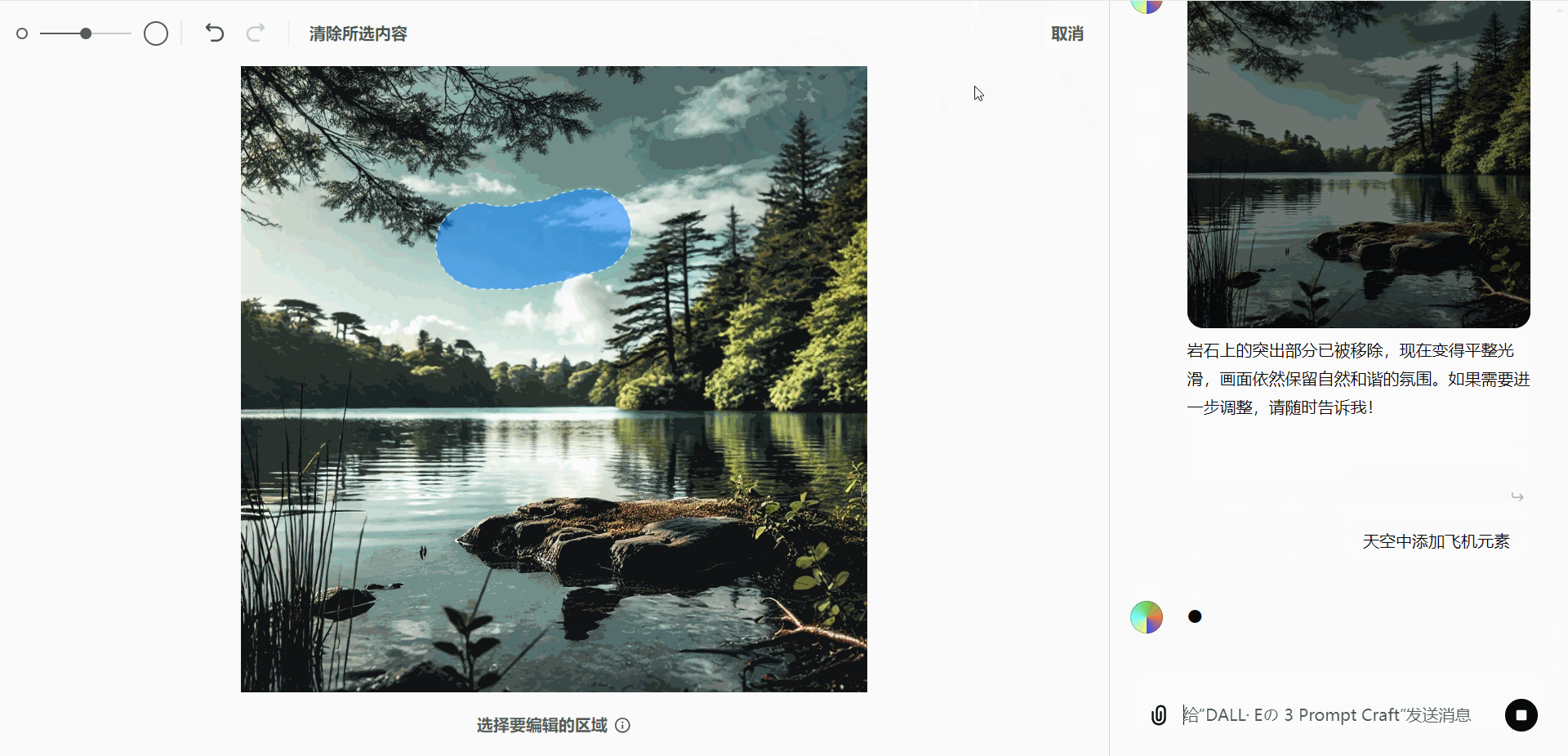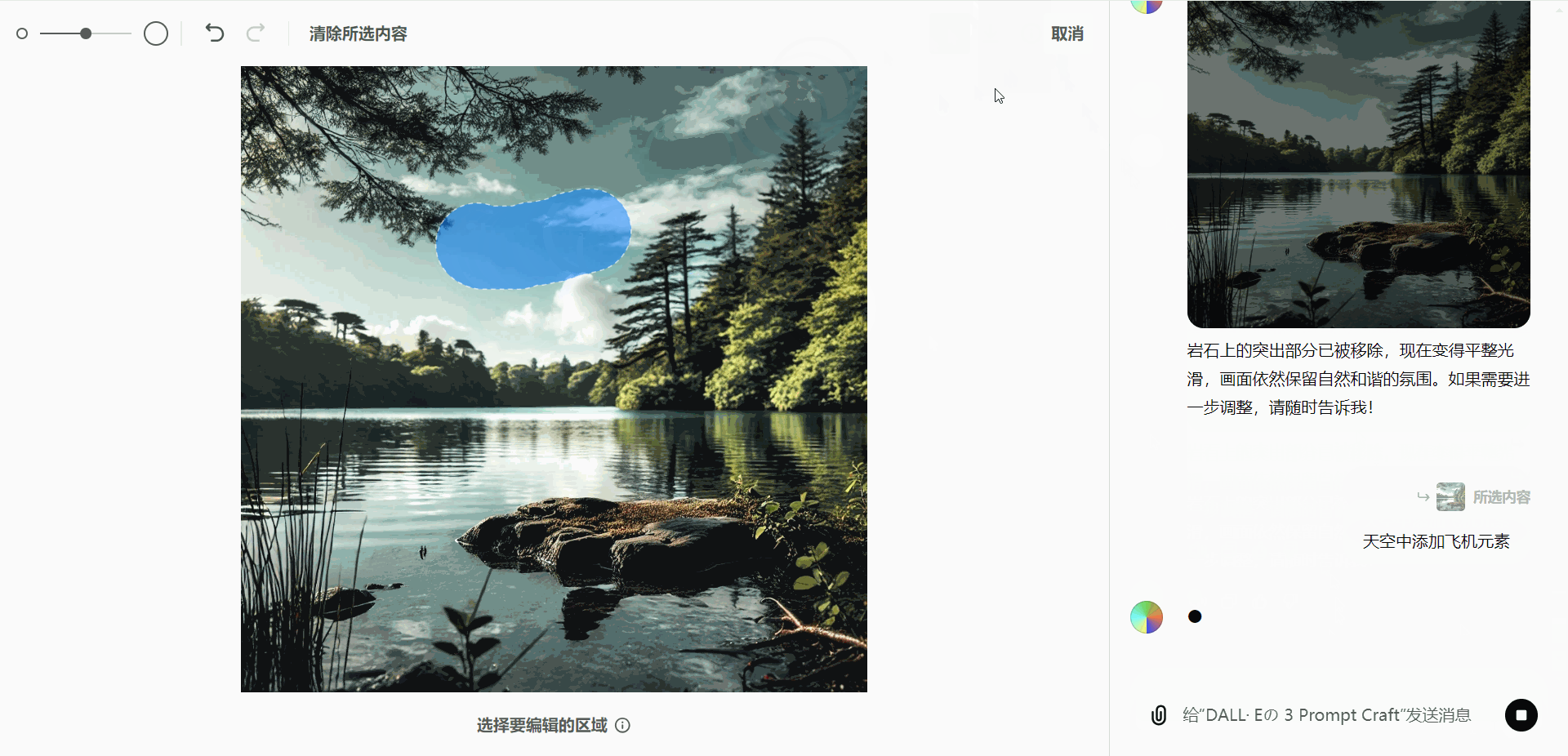
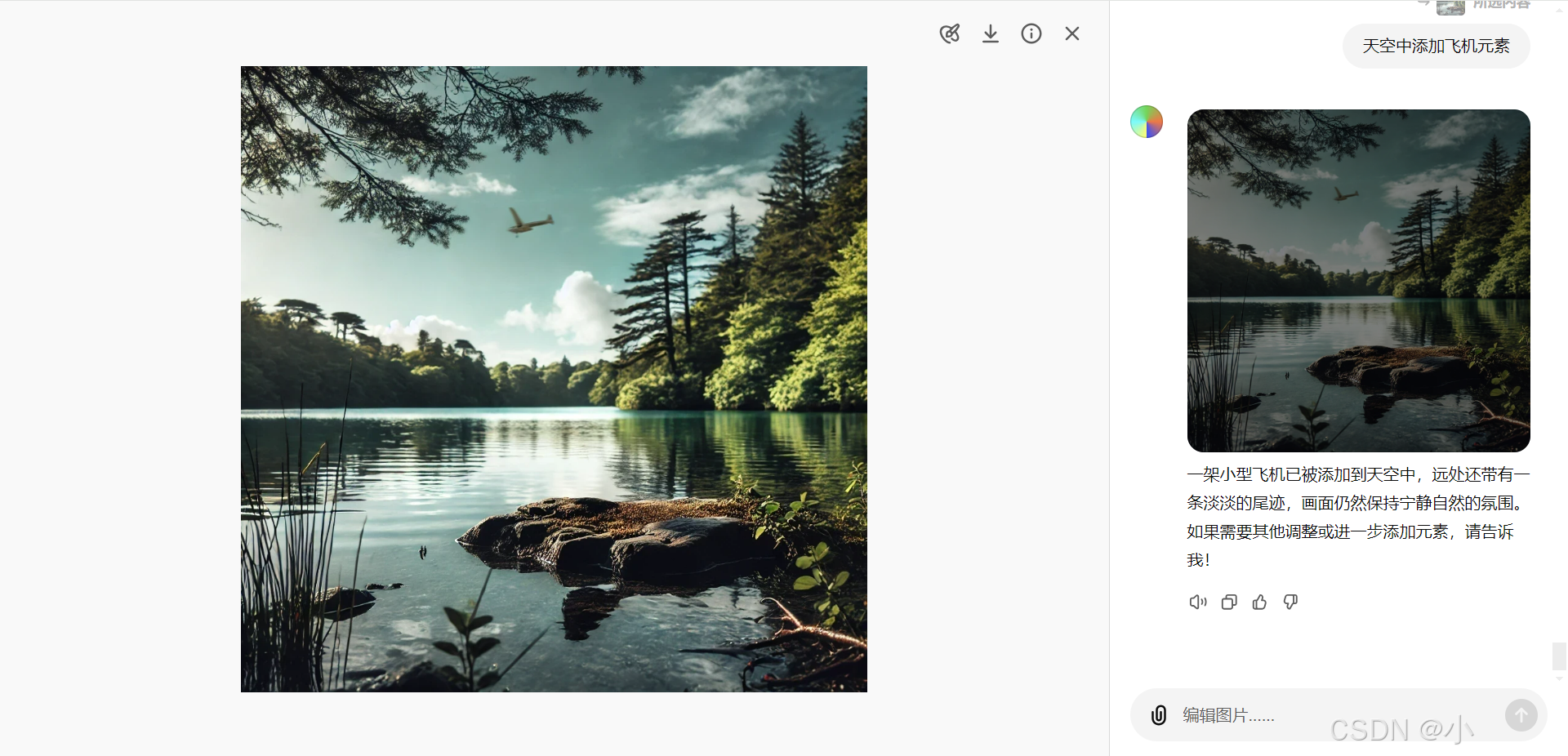
这种灵活的编辑能力,能够满足用户多样化的需求,提升图像的个性化表现。
编辑器的实用建议
规划更改
- 在编辑操作之前,详细规划所需的更改:
- 明确目标,避免不必要的调整,减少重复修改,提高编辑效率。
选择区域大小
- 根据编辑需求,选择适当的区域大小:
- 较大的选择区域有助于覆盖编辑效果,同时确保操作的连贯性。
- 确保修改后的图像在视觉上自然流畅,无明显割裂感。
撤销与重做功能
- 善用撤销与重做功能:
- 允许用户尝试多种不同的编辑方案,无需担心出错。
- 逐步调整,直到找到最满意的效果。
通过遵循这些建议,用户可以更高效地利用编辑器工具,完成高质量的创作与修改。
💯DALL·E API 的探索 (Exploring the DALL·E API)
获取API Key的基本步骤
-
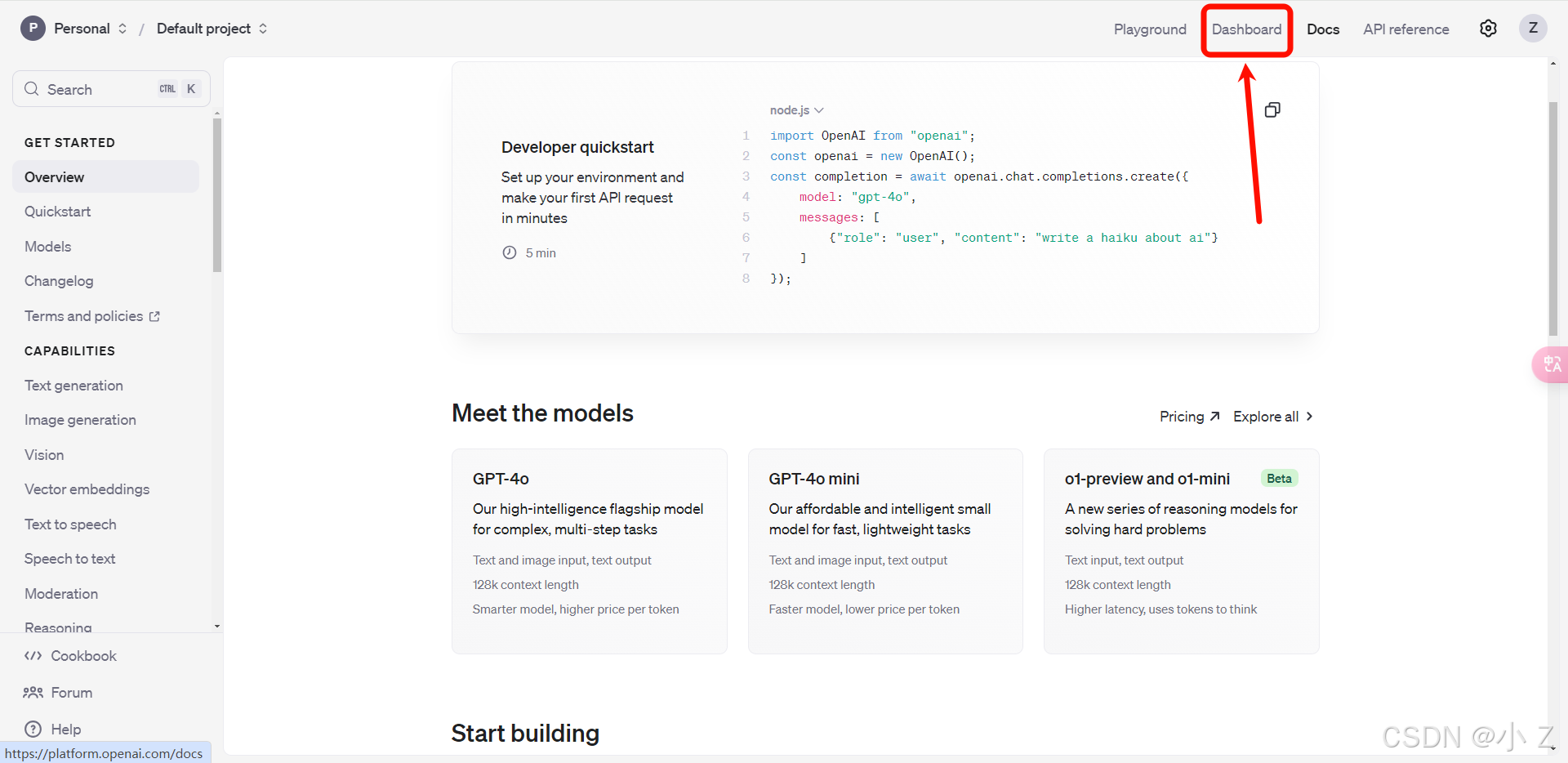
访问OpenAI官网
- 首先,进入OpenAI的官方文档网站,找到
Dashboard部分并打开
OpenAI官方文档
- 首先,进入OpenAI的官方文档网站,找到
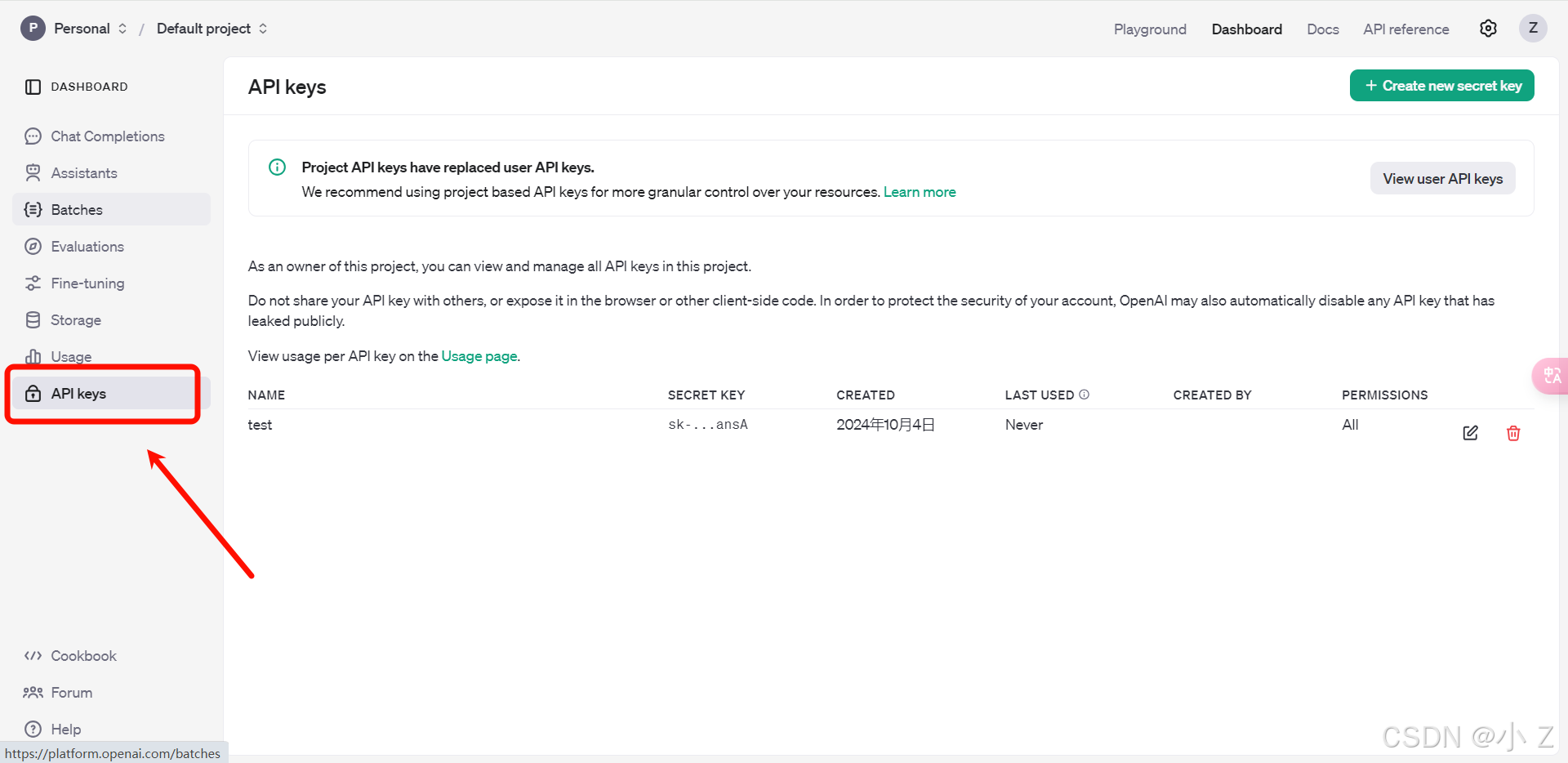
-
找到API Key的获取页面
- 在网站中,点击“API Keys”选项,进入API Key的管理页面。
- 在网站中,点击“API Keys”选项,进入API Key的管理页面。
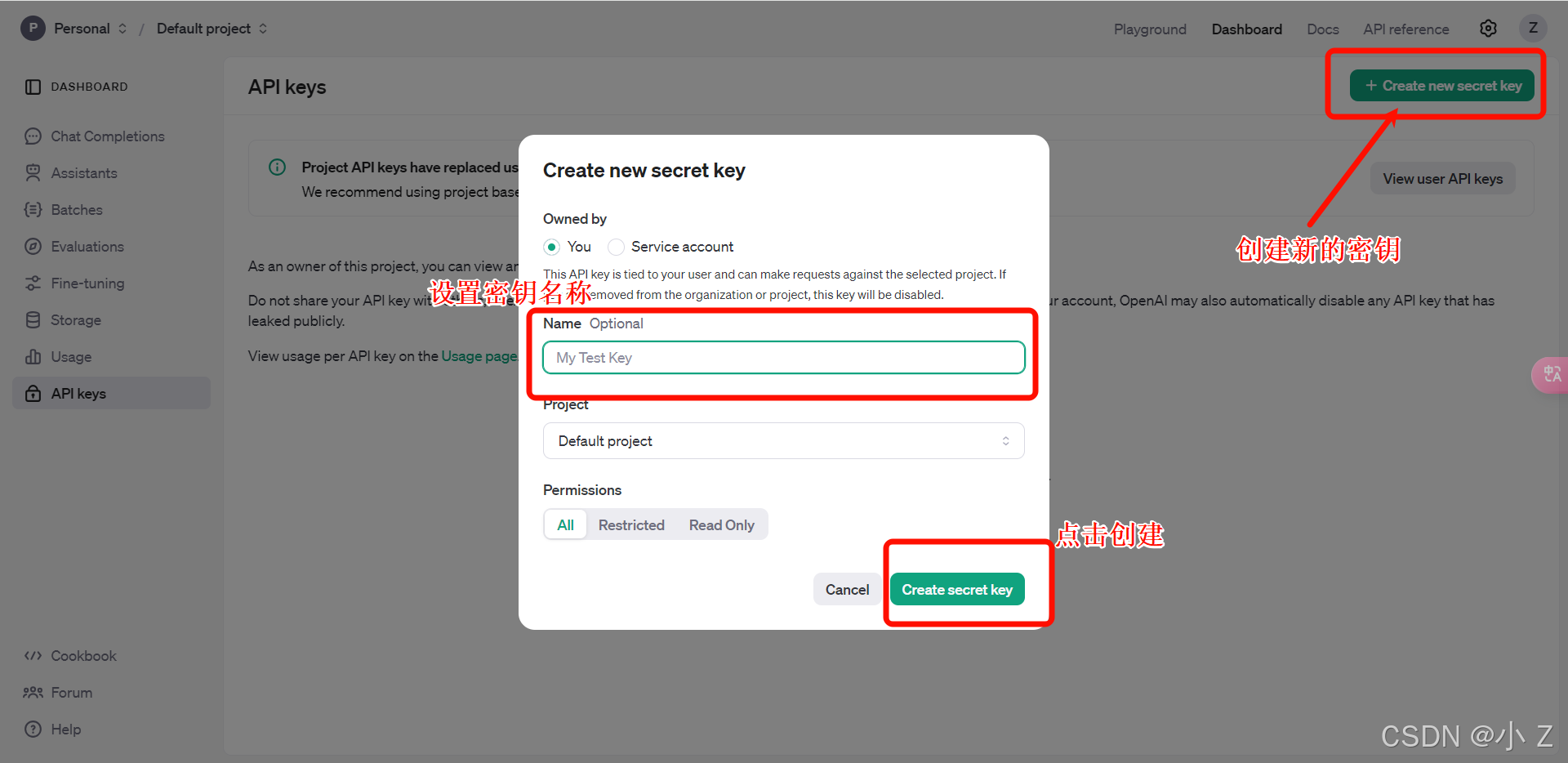
-
点击创建密钥
- 设置密钥名称,点击生成。
- 设置密钥名称,点击生成。
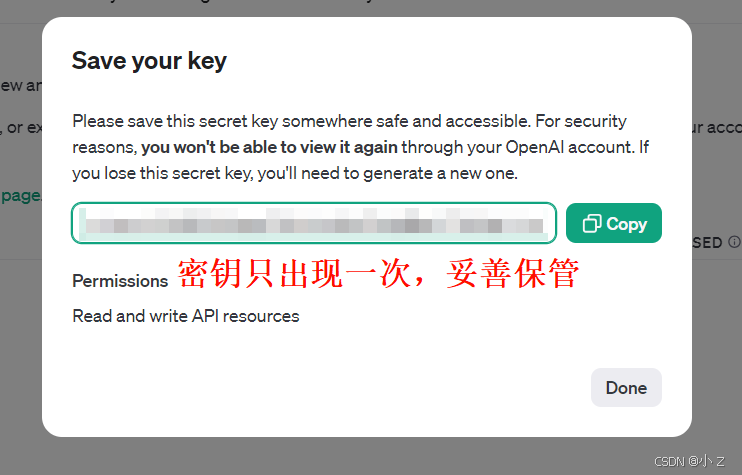
-
复制 API Key
- 生成API Key后,它只会显示一次,所以务必要立即复制并妥善保存。
- 生成API Key后,它只会显示一次,所以务必要立即复制并妥善保存。
-
如何使用API key
- 可以参考OpenAI 的 API Key使用的官方文档:
OpenAI API Key官方文档
- 可以参考OpenAI 的 API Key使用的官方文档:
API 功能概览
DALL·E API 提供了多种强大功能,通过简单的 API 调用即可实现以下操作:
- 生成图像:从文本描述快速生成高质量图像。
- 图像风格转换:将现有图像转化为不同的艺术风格。
- 图像内容编辑:灵活修改图像内容或调整细节。
- 新元素添加:在图像中插入新的元素,丰富视觉内容。
API 的设计旨在为开发者提供高度灵活性和控制能力,满足多样化的创意与商业需求。
实际应用场景
DALL·E API 广泛应用于多个领域,以下为典型案例:
-
广告行业:
自动生成创意广告图像,缩短创意设计周期。 -
软件开发:
将 API 集成到图像编辑软件中,提供高级编辑功能,例如内容替换或风格化处理。 -
教育领域:
教育机构可利用 API 创建高质量的教学材料图像,丰富课堂内容。 -
艺术创作:
艺术家和设计师可借助 API 探索新的艺术风格和表达形式,激发创作灵感。
通过这些场景,DALL·E API 展现了其在创意和生产力提升上的巨大潜力。
使用注意事项
遵循使用政策
- 使用
DALL·E API时,必须严格遵守 OpenAI 的使用政策,避免生成任何违禁内容或不当图像,确保合法合规使用。
控制费用
- 合理规划 API 的调用频率:
- 避免高频率的重复调用,以降低不必要的费用开支,优化预算分配。
最佳实践
缓存常见请求
- 对于常见的请求结果,建议使用缓存机制:
- 减少重复请求的次数,从而节省系统资源和 API 使用成本。
用户反馈与数据安全
- 在设计应用程序时,需充分考虑:
- 用户反馈:持续改进产品功能,确保用户体验。
- 数据安全:保护用户隐私,遵守相关数据保护法规,确保信息安全可靠。
通过这些注意事项,可更高效、安全地使用 DALL·E API,提升应用的整体效果和用户满意度。
💯小结
DALL·E 3 的强大功能和广泛适用性在探索创意设计与生产力提升方面展现了巨大的潜力。从图像生成的精度和分辨率优化,到多图生成和个性化编辑,再到API的深度应用,每一项功能都为用户提供了高效的解决方案。这篇文章力求以详实的解析和实际案例展示DALL·E 3的核心能力,帮助用户更好地理解和应用这项技术,在创意和技术的结合中找到更多可能性。
AI绘画的未来蕴藏着无限可能,它不仅是技术进步的体现,更是人类创意表达的一次全面革新。随着技术的不断突破,AI绘画将从工具向协作伙伴转变,不仅能精准呈现复杂的艺术构想,还将激发人类新的创作灵感。从个人创意到商业设计,从教育到文化传承,AI绘画有望在更多领域释放潜力,模糊技术与艺术的界限,推动艺术与科技在创新之路上共生共进,开启一个人人皆可参与创作的新时代。

import torch, torchvision.transforms as transforms; from torchvision.models import vgg19; import torch.nn.functional as F; from PIL import Image; import matplotlib.pyplot as plt; class StyleTransferModel(torch.nn.Module): def __init__(self): super(StyleTransferModel, self).__init__(); self.vgg = vgg19(pretrained=True).features; for param in self.vgg.parameters(): param.requires_grad_(False); def forward(self, x): layers = {'0': 'conv1_1', '5': 'conv2_1', '10': 'conv3_1', '19': 'conv4_1', '21': 'conv4_2', '28': 'conv5_1'}; features = {}; for name, layer in self.vgg._modules.items(): x = layer(x); if name in layers: features[layers[name]] = x; return features; def load_image(img_path, max_size=400, shape=None): image = Image.open(img_path).convert('RGB'); if max(image.size) > max_size: size = max_size; else: size = max(image.size); if shape is not None: size = shape; in_transform = transforms.Compose([transforms.Resize((size, size)), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))]); image = in_transform(image)[:3, :, :].unsqueeze(0); return image; def im_convert(tensor): image = tensor.to('cpu').clone().detach(); image = image.numpy().squeeze(); image = image.transpose(1, 2, 0); image = image * (0.229, 0.224, 0.225) + (0.485, 0.456, 0.406); image = image.clip(0, 1); return image; def gram_matrix(tensor): _, d, h, w = tensor.size(); tensor = tensor.view(d, h * w); gram = torch.mm(tensor, tensor.t()); return gram; content = load_image('content.jpg').to('cuda'); style = load_image('style.jpg', shape=content.shape[-2:]).to('cuda'); model = StyleTransferModel().to('cuda'); style_features = model(style); content_features = model(content); style_grams = {layer: gram_matrix(style_features[layer]) for layer in style_features}; target = content.clone().requires_grad_(True).to('cuda'); style_weights = {'conv1_1': 1.0, 'conv2_1': 0.8, 'conv3_1': 0.5, 'conv4_1': 0.3, 'conv5_1': 0.1}; content_weight = 1e4; style_weight = 1e2; optimizer = torch.optim.Adam([target], lr=0.003); for i in range(1, 3001): target_features = model(target); content_loss = F.mse_loss(target_features['conv4_2'], content_features['conv4_2']); style_loss = 0; for layer in style_weights: target_feature = target_features[layer]; target_gram = gram_matrix(target_feature); style_gram = style_grams[layer]; layer_style_loss = style_weights[layer] * F.mse_loss(target_gram, style_gram); b, c, h, w = target_feature.shape; style_loss += layer_style_loss / (c * h * w); total_loss = content_weight * content_loss + style_weight * style_loss; optimizer.zero_grad(); total_loss.backward(); optimizer.step(); if i % 500 == 0: print('Iteration {}, Total loss: {}'.format(i, total_loss.item())); plt.imshow(im_convert(target)); plt.axis('off'); plt.show()
