目录
2.4Thread Local Storage(线程局部存储) --TLS
一、高并发内存池的结构
当前很多服务及应用程序都是基于多线程来进行开发和实现的,环境多数为多核多线程,在申请访问内存时,会存在激烈的锁竞争问题。C/C++中malloc本身以及有很高的效率,而Google的tcmalloc在多线程高并发场景下有更优秀的效率。
而博主此次做的项目从以下三个方面来进行问题的解决和处理:
1、性能问题。
2、多线程环境下,竞争锁的问题。
3、申请释放内存时,产生的内存碎片问题。
而根据tcmalloc中的实现方式,我们的concurrent memory pool主要由以下3个部分构成:
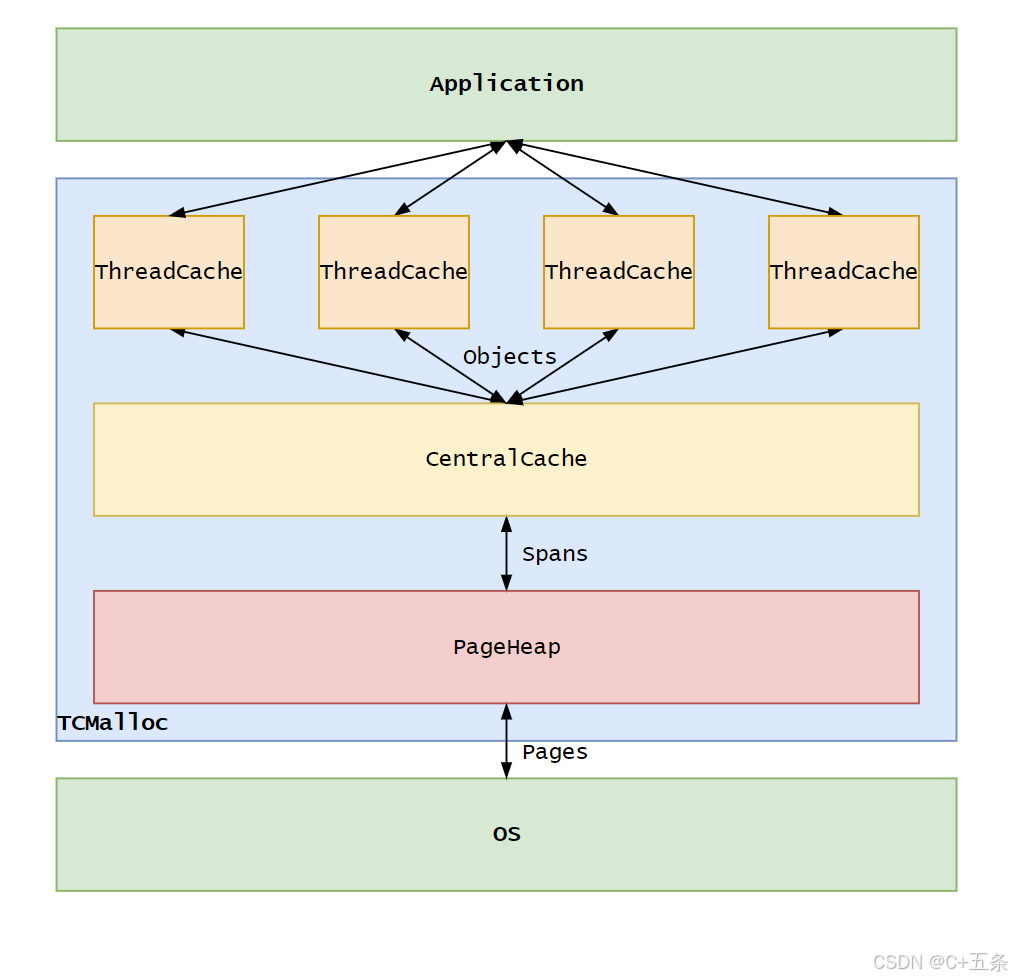
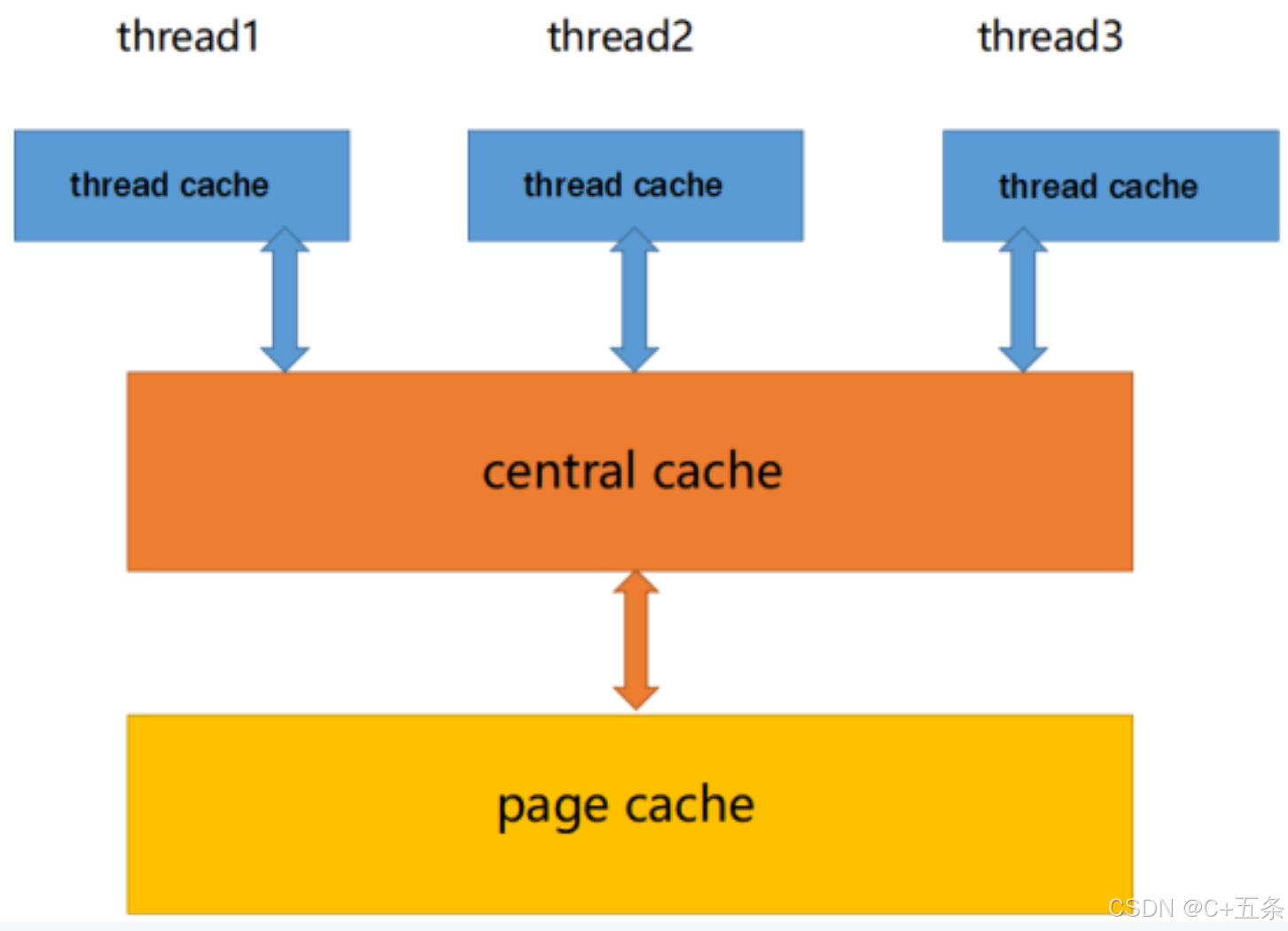
二、thread cache的实现
考虑到每次线程可能申请的内存大小都不一样,有可能是1字节也有可能是256kb,而为了满足不同的申请需求,通过哈希加链表就可以完美解决这个问题,当申请不同大小的内存时就到不同的下标位置中的链表头部去拿去数据,当然,这里也并不是无脑从1字节到256kb直接每个字节对应一个位置,设计师在这里对内存对齐的方式以及哈希映射的方式都做了优化。在博主看来,频繁的竞争和申请锁会导致程序的效率大大降低,高并发内存池之所以这样设计,目的就是在于当线程去申请小内存时,可以直接在每个已经开辟好的小内存池中之际拿去数据,避免一遍遍执行加锁程序从而消耗掉过多时间,可见开发tcmalloc的程序员对整个C++语言及底层系统体系的了解已经到了出神入化的地步。
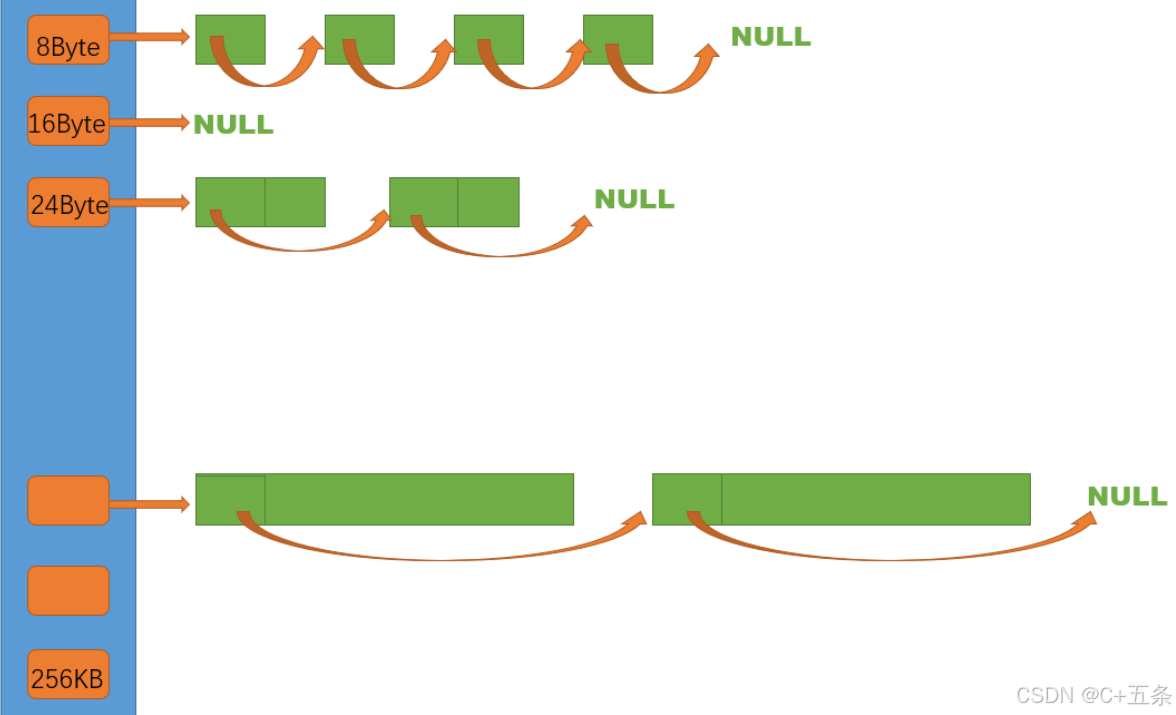
2.1Free List自由链表的构建及实现
thread cache内部只能申请小于等于256KB的内存,当申请空间大于256KB时会直接从上层中的page cache中获取。而为了方便我们进行对thread cache更好的管理和应对线程申请时更高效的处理,一种合理高效的数据结构是不可缺少的。
而既然要实现高效的内存分配及内存碎片管理,链表无疑是最好的方式之一,构建一个void*的自由链表,这样在申请数据和管理数据时,哈希表每个下标所对应的就有一个对应大小不同的链表,申请时直接根据申请的大小在固定的下标所对应的链表中进行头删操作将头部元素返回,当释放空间时,再找到该空间所对应哈希表的下标,然后将需要释放的内存进行头插操作。
using std::cout;
using std::endl;
static const size_t MAX_BYTES = 256 * 1024;
static const size_t NFREELIST = 208;
static void*& NextObj(void* obj)
{
return *(void**)obj;
}
//管理切分好的小对象的自由请求
class FreeList
{
public:
void Push(void* obj)//不能实例化,此时是内存管理,只谈大小不谈类型
{
assert(obj);
NextObj(obj) = _freelist;//将obj前4/8位取出来以后作为存放下一位的地址的指针,然后通过&来返回
_freelist = obj;
}
void* Pop()
{
assert(_freelist);
void* obj = _freelist;
_freelist = NextObj(obj);
return obj;
}
bool Empty()
{
return _freelist == nullptr;//每个线程都有208个_freelist为了避免初始化时产生大量随机值,所以默认给nullptr
}
private:
void* _freelist = nullptr;
};
2.2哈希桶的实现
| 对应申请内存范围(Byte) | 下标之间内存间隔(对齐数) | 自由链表对应下标(从0开始) |
| [1 , 128] | 8Byte | [0 , 16) |
| (128 , 1024] | 16Byte | [16 , 72) |
| (1024 , 8*1024] | 128Byte | [72 , 128) |
| (8*1024 , 64*1024] | 1024Byte(1KB) | [128 , 184) |
| (64*1024 , 256*1024] | 8 * 1024Byte(8KB) | [184 , 208) |
结合我们上面介绍的,要对对齐方式以及映射方式进行优化。按照以往的思路和经验,每个大小都对应一个下标和链表,找下标时也是根据要申请的内存大小去查找下标,但是这样就需要创建一个个数多达256*1024个链表有256*1024个下标的哈希桶,实在是恐怖如斯,光是创建个哈希桶,都损耗了一部分空间。而如果按照固定的大小进行内存对齐,比如8字节,申请1-8给8,申请9-16给16,就算是这样给,依旧需要256*128个链表,而如果把对齐数调大直接变成1024字节,申请1-1024直接给1024字节,申请1025-2048直接给2048,这样设计线程还没申请几个变量thread cache内存就干没了,产生的内存碎片(内碎片)也会非常的大,只申请了1,却给了1024,着实离谱。
而tcmalloc采用了更加灵活的方式来处理问题,在申请内存的内存对齐问题上,按以上区间进行划分并设置不同的对齐数,当申请的字节数位于1-128时,对齐数设置为8,也就是8个8个字节去划分8 16 24 32...128,如果申请的空间不是8的倍数就向上进行补齐,比如申请1就直接给8,申请9就直接给16,而当申请的字节数在129-1024大小时,就按16位进行划分和补齐,依次往上进行,这样做的好处在于针对申请不同的大小给与不同的对齐方式,大大减少了内存碎片的产生,经过计算严格将内存碎片控制在10%左右。采取这种按区间划分设置对齐数的方式在减少内存碎片产生的同时也将哈希桶的个数控制在208个以内。
而在查找内存所对应的哈希桶下标时,也采用类似的方式来进行控制根据当前已经经过对齐后的size大小,减去上一个区间最大的数,然后再通过除上当前对齐数计算出在当前区间的第几个哈希桶,然后拿之前桶的总个数加上所在当前区间个数,就可以得到在哪个哈希桶。然后通过头插头删的方式来删除或申请数据。
class SizeClass
{
public:
//内存对齐,前128都按8字节为单位进行对齐,1-8全给8字节,9-16全给16字节,相当于向上对齐取整
//129-1024按16字节进行对齐,比如要申请129,直接给144
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
static inline size_t RoundUp(size_t bytes)
{
if (bytes <= MAX_BYTES)
{
if (bytes <= 128)
{
return _RoundUp(bytes, 8);
}
else if (bytes <= 1024)
{
return _RoundUp(bytes, 8);
}
else if (bytes <= 8 * 1024)
{
return _RoundUp(bytes, 8);
}
else if (bytes <= 64 * 1024)
{
return _RoundUp(bytes, 8);
}
else if (bytes <= 256 * 1024)
{
return _RoundUp(bytes, 8);
}
else
{
assert(false);
return -1;
}
}
}
//1+7 8
//2 9
//...
//8 15
//9+7 16
//10 17
//...
//16 23 23依旧不够整除8,23/8=2 依旧是第二个桶
//需要开辟的空间大小size加上对齐数-1然后除对齐数,这时就能得到在第几个桶,因为下标从0开始再-1就找到桶的位置
//因为对齐数都是2的整数次方,所以align_shit是左移位数比如8,传过来就是3,移位操作更加的快速
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + 1 << align_shift - 1) >> align_shift) - 1;
}
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
//每个区间有多少个链/桶
static int group_array[4] = { 16,56,56,56 };
if (bytes <= 128)
{
return _Index(bytes, 3);
}
else if (bytes <= 1024)
{
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024)
{
return _Index(bytes - 1024, 7) + group_array[1];
}
else if (bytes <= 64 * 1024)
{
return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];
}
else if (bytes <= 256 * 1024)
{
return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
}
else
{
assert(false);
}
return -1;
}
};2.3ThreadCache的封装与实现
//ThreadChache.cpp
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{...}
void* ThreadCache::Allocate(size_t size)//申请空间
{
assert(size <= MAX_BYTES);
size_t alignSize = SizeClass::RoundUp(size);
size_t index = SizeClass::Index(alignSize);
if (!_freelist[index].Empty())
{
return _freelist[index].Pop();
}
else
{
return FetchFromCentralCache(index, alignSize);
}
}
void ThreadCache::Deallocate(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAX_BYTES);
//size_t alignSize = SizeClass::RoundUp(size);
//还回来时不需要再去做对齐,因为申请时申请到的就是对齐完毕的,释放时肯定是桶内存在的
size_t index = SizeClass::Index(size);
_freelist[index].Push(ptr);
}
//
//ThreadCache.hpp
class ThreadCache
{
public:
//申请和释放内存对象
void* Allocate(size_t size);//申请空间
void Deallocate(void* ptr, size_t size);
//从缓存中心获取对象
void* FetchFromCentralCache(size_t index, size_t size);//跟下一层去获取联动
private:
FreeList _freelist[NFREELIST];
};
//每个线程都有一个这样的指针
//Thread Local Storage(线程局部存储) --TLS
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;//static只在当前文件可见避免链接冲突2.4Thread Local Storage(线程局部存储) --TLS
通过使用TLS,让每个线程在创建时都创建出一个独一无二的指向自己ThreadCache的TLS,每个线程通过TLS无锁的获取自己的专属ThreadCache对象。这样就避免了线程在访问临界区资源时需要频繁加锁的问题,更好的让线程去并发的进行执行。
#include "Common.h"//封装了Freelist和哈希桶的对齐查找逻辑
#include "ThreadCache.h"
static void* ConcurrentAlloc(size_t size)//申请
{
//每个线程通过TLS无锁的获取自己的专属ThreadCache对象
if (pTLSThreadCache == nullptr)
{
pTLSThreadCache = new ThreadCache;
}
return pTLSThreadCache->Allocate(size);
}
static void ConcurrentFree(void* ptr,size_t size)//释放
{
assert(pTLSThreadCache);
pTLSThreadCache->Deallocate(ptr,size);
}