数据库中的增删改查操作、聚合函数、内置函数、分组查询
CRUD简介
CURD是对数据库中的记录进⾏基本的增删改查操作:
• Create (创建)
• Retrieve (读取)
• Update (更新)
• Delete (删除)
Create 新增
语法
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES
(value_list) [, (value_list)] ...
value_list: value, [, value] ...
示例
# 创建一个用于演示的表
create table users(
id bigint,
name varchar(20) comment '用户名'
);
单⾏数据全列插⼊
• value_list 中值的数量必须和定义表的列的数量及顺序⼀致
• 字符串类型的值用英文的单引号包裹
# 插入第一条记录
# 字符串类型的值用英文的单引号包裹
insert into users values (1,'张三');
# 插入第二条记录
insert into users values (2,'李四');
# 查询结果
select * from users;

单⾏数据指定列插⼊
• value_list 中值的数量必须和指定列数量及顺序⼀致
# 指定了具体要插入的列
insert into users(id, name) values (3,'王五');
# 查询结果
select * from users;
没有指定ld这一列时,只写一个name的值,ld这一列就会用默认的值去填充,这个默认值就是NULL
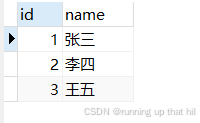

insert into users(name) values('王五');
# 查询结果
select * from users;

多⾏数据指定列插⼊
• 在⼀条INSERT语句中也可以指定多个value_list,实现⼀次插⼊多⾏数据
# 每个value_list表示一行数据
insert into users(id, name) values (4,'赵六'),(5,'钱七');
# 查询结果
select * from users;

Retrieve 检索
语法
SELECT
[DISTINCT]
select_expr [, select_expr] ...
[FROM table_references]
[WHERE where_condition]
[GROUP BY {col_name | expr}, ...]
[HAVING where_condition]
[ORDER BY {col_name | expr } [ASC | DESC], ... ]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
⽰例
构造数据
-- 创建考试成绩表
DROP TABLE IF EXISTS exam;
CREATE TABLE exam (
id bigint,
name VARCHAR(20),
chinese DECIMAL(3,1),
math DECIMAL(3,1),
english DECIMAL(3,1)
);
-- 插入测试数据
INSERT INTO exam (id,name, chinese, math, english) VALUES
(1,'唐三藏', 67, 98, 56),
(2,'孙悟空', 87.5, 78, 77),
(3,'猪悟能', 88, 98, 90),
(4,'曹孟德', 82, 84, 67),
(5,'刘玄德', 55.5, 85, 45),
(6,'孙权', 70, 73, 78.5),
(7,'宋公明', 75, 65, 30);
Select
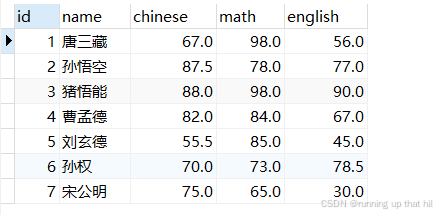
全列查询
• 查询所有记录
# 使用 * 可以查询表中所有列的值
select * from exam;
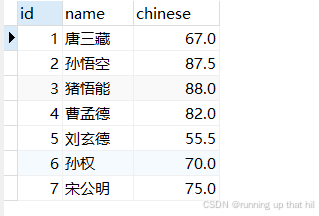
指定列查询
• 查询所有⼈的编号、姓名和语⽂成绩
select id,name,chinese from exam;
在select后⾯的查询列表中指定希望查询的列,可以是⼀个也可以是多个,中间⽤逗号隔开
指定列的顺序与表结构中的列的顺序⽆关
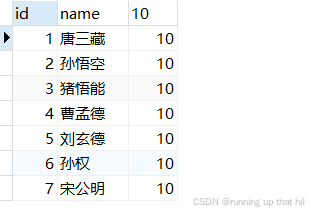
查询字段为表达式
• 常量表达式
# 表达式本身就是一个常数
select id,name,10 from exam;
# 也可以是常量的运算
select id,name,10+1 from exam;
• 把所有学⽣的语⽂成绩加10分
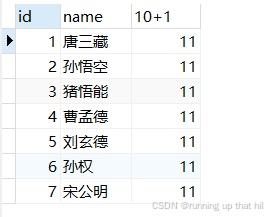
# 表达式中包含一个字段
select id,name,chinese + 10 from exam;
• 计算所有学⽣语⽂、数学和英语成绩的总分
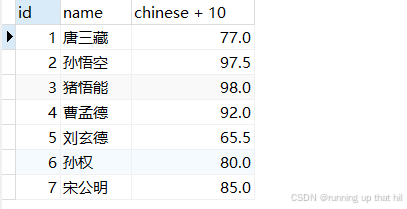
# 表达式包含多个字段
select id,name,chinese+math+english from exam;
为查询结果指定别名
语法
SELECT column [AS] alias_name [, ...] FROM table_name;
AS可以省略,别名如果包含空格必须⽤单引号包裹
⽰例
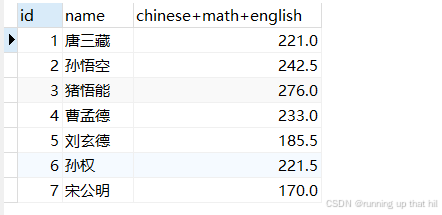
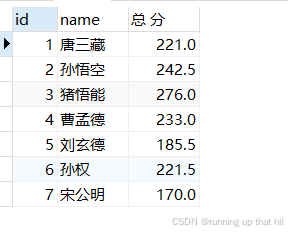
• 为总分这⼀列指定别名
# select id,name,chinese+math+english as '总分' from exam;
# select id,name,chinese+math+english '总分' from exam;
# select id,name,chinese+math+english as 总分 from exam;
select id,name,chinese+math+english 总分 from exam;
表头以别名显示
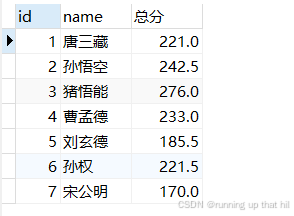
select id,name,chinese+math+english '总 分' from exam;
select id,name,chinese+math+english 总 分 from exam;
结果去重查询
- 查询当前所的数学成绩
select math from exam;
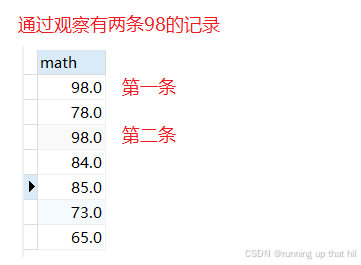
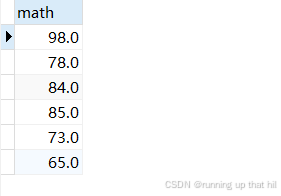
- 在结果集中去除重复记录,可以使⽤DISTINCT
# 去重查询
select distinct math from exam;
使⽤DISCTINCT去重时,只有查询列表中所有列的值都相同才会判定为重复
select distinct id,math from exam;

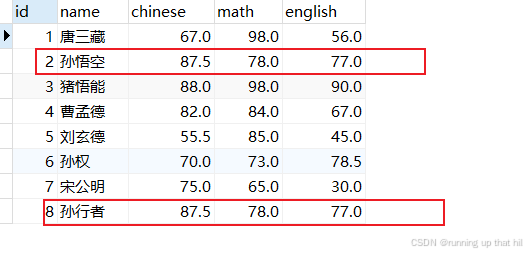
insert into exam values (8, '孙行者', 87.5, 78, 77);
select * from exam;
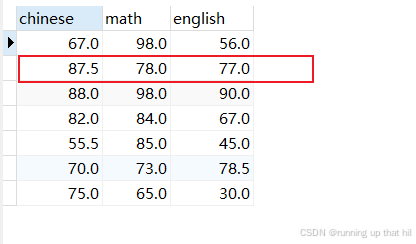
select distinct chinese, math, english from exam;
去重时,只有查询结果中所有的列都相同才会被认定为重复记录
去重后,重复记录只保留一条
注意:
• 查询时不加限制条件会返回表中所有结果,如果表中的数据量过⼤,会把服务器的资源消耗殆尽
• 在⽣产环境不要使用不加限制条件的查询
Order by 排序
语法
-- ASC 为升序(从⼩到⼤)
-- DESC 为降序(从⼤到⼩)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...] ORDER BY {col_name | expr } [ASC | DESC], ... ;
没有写排序规则的时候默认是升序排序
⽰例
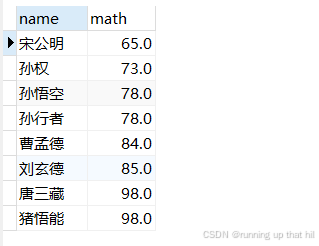
• 按数学成绩从低到⾼排序(升序)
# 按数学成绩从低到高排序(升序)
# select name,math from exam order by math;
select name,math from exam order by math ASC;
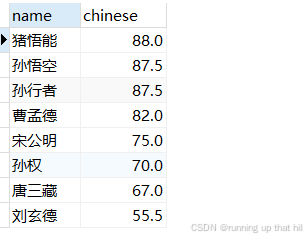
• 按语⽂成绩从⾼到低排序(降序)
# 按语文成绩从⾼到低排序(降序)
select name,chinese from exam order by chinese DESC;
• 按英语成绩排序
insert into exam values (9, '孙大圣', 87.5, 78, null);
select * from exam;
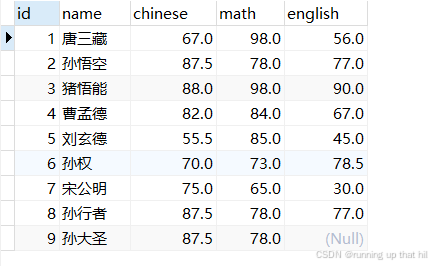
# 按英语成绩从高到低排序
select name,english from exam order by english DESC;
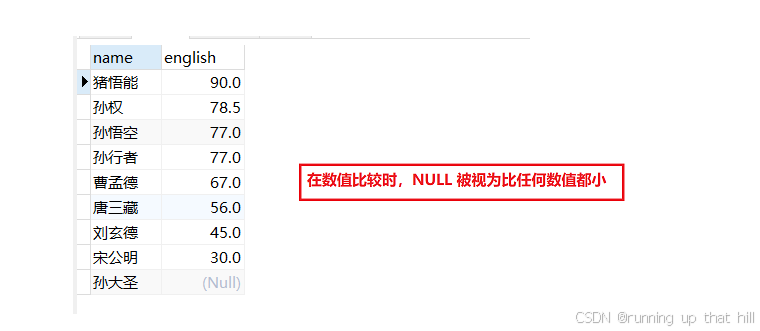
# 按英语成绩从低到高排序
select name,english from exam order by english ASC;
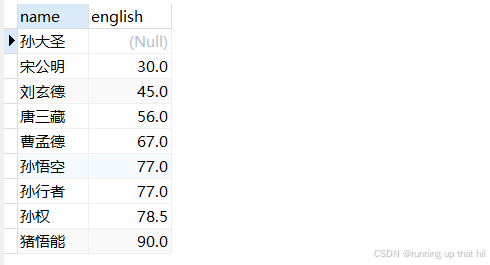
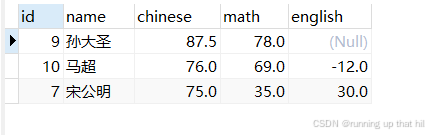
insert into exam values (10, '马超', 76, 99, -12);
select * from exam;
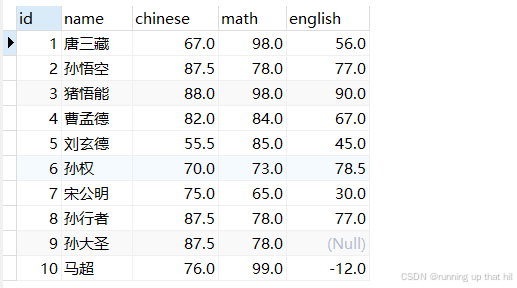
select name,english from exam order by english DESC;
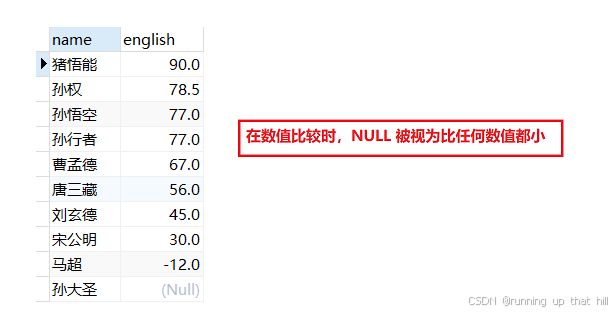
mysql中NULL 比较特殊:
1.不论和什么值进行运算,返回的值都是NULL
2.NULL 始终被判定为FALSE
3.NULL 的值不是我们以前学习过的其他编程语言中的0,在MYSQL中他就是NULL
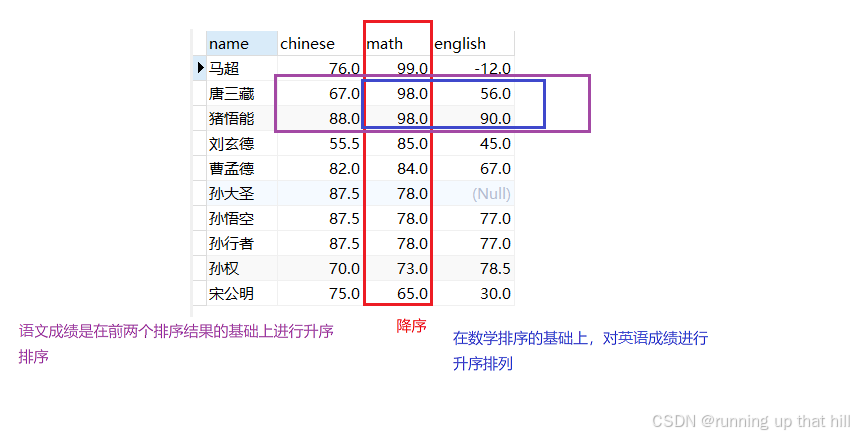
• 查询同学各⻔成绩,依次按数学降序,英语升序,语⽂升序的⽅式显⽰
可以对多个字段进行排序,排序的优先级与书写顺序相关
可以为每个字段指定不同的排序规则
先按数学降序排列,再按英语升序排列,再按语文进行升序排列
select name,chinese,math,english from exam order by math DESC, english ASC, chinese ASC;
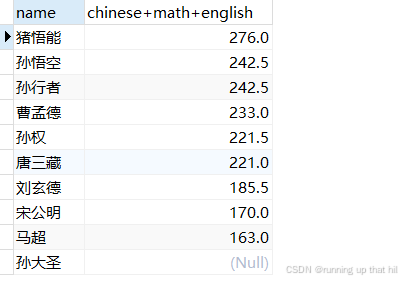
• 查询同学及总分,由⾼到低排序
select name,chinese+math+english from exam order by chinese+math+english DESC;
不论和什么值进行运算,返回的值都是NULL
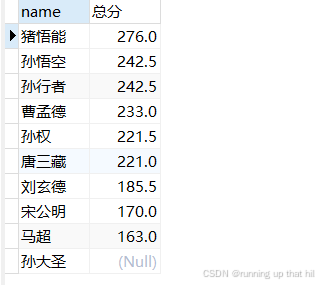
• 可以使⽤列的别名进⾏排序
# select name,chinese+math+english as 总分 from exam order by 总分 DESC;
select name,chinese+math+english 总分 from exam order by 总分 DESC;
注意
• 查询中没有ORDER BY ⼦句,返回的顺序是未定义的,永远不要依赖这个顺序
• ORDER BY ⼦句中可以使⽤列的别名进⾏排序
• NULL 进⾏排序时,视为⽐任何值都⼩,升序出现在最上⾯,降序出现在最下⾯
Where 条件查询
语法
SELECT
select_expr [, select_expr] ... [FROM table_references]
WHERE where_condition
根据指定的一些条件,过滤掉不符合条件的记录,把符合条件的记录返回给用户
可以通过一些运算符,比如说比较运算符,逻辑运算符
⽐较运算符
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | ⼤于,⼤于等于,⼩于,⼩于等于 |
| = | 等于,对于NULL的⽐较不安全,⽐如NULL = NULL结果还是NULL |
| <=> | 等于,对于NULL的⽐较是安全的,⽐如NULL <=> NULL结果是TRUE(1) |
| !=, <> | 不等于 |
| value BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果a0 <= value <= a1,返回TRUE或1,NOT BETWEEN则取反 |
| value IN (option, …) | 如果value 在optoin列表中,则返回TRUE(1),NOT IN则取反 |
| IS NULL | 是NULL |
| IS NOT NULL | 不是NULL |
| LIKE | 模糊匹配,% 表⽰任意多个(包括0个)字符;_ 表⽰任意⼀个字符,NOT LIKE则取反 |



逻辑运算符
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意⼀个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
⽰例
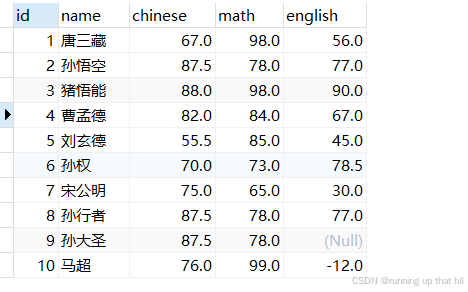
基本查询
select * from exam;
• 查询英语不及格的同学及英语成绩 ( < 60 )
# 查询英语不及格的同学及英语成绩 ( < 60 )
select id,name,english from exam where english < 60;
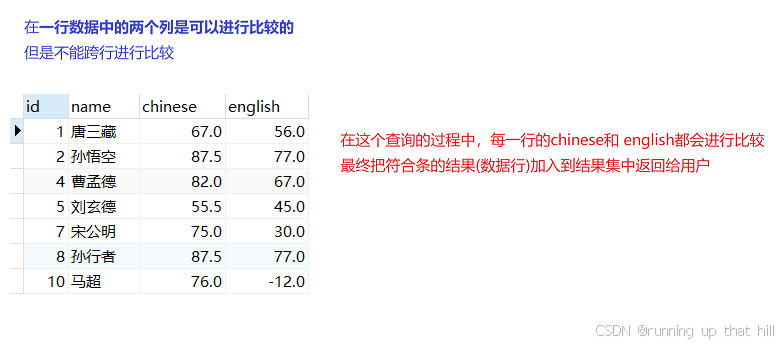
• 查询语⽂成绩⾼于英语成绩的同学

# 查询语文成绩高于英语成绩的同学
select id,name,chinese,english from exam where chinese > english;
• 总分在 200 分以下的同学
# 总分在 200 分以下的同学
select id,name,(chinese+math+english) from exam where (chinese + math + english) < 200;
• 总分在 200 分以下的同学并按升序排序
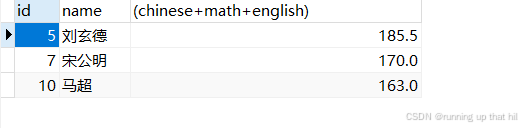

# 总分在 200 分以下的同学并按升序排序
select id,name,(chinese+math+english) as total from exam where (chinese+math+english) < 200 order by total;
出现这种现象是和MYSQL内部的实现有关,换句话说就是和MYSQL执行SQL语句的顺序有关
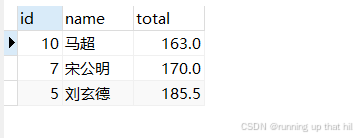

- 如果要在数据中查某些数据,首先要确定表,先执行from
- 在查询的过程中要根据指定的查询条件把符合条件的数据过滤出来,这时执行的就是where子句
(在执行where条件的时候total还没有被定义) - 执行select后面的指定的列,这些列是需要加入到最终的结果集中
- 排序操作,根据order by子句中指定的列名和排序规则进行最后的排序
AND和OR
• 查询语⽂成绩⼤于80分且英语成绩⼤于80分的同学
# 查询语文成绩大于80分且英语成绩大于80分的同学
select id,name,chinese,english from exam where chinese > 80 and english > 80;
• 查询语⽂成绩⼤于80分或英语成绩⼤于80分的同学

# 查询语文成绩大于80分或英语成绩大于80分的同学
select id,name,chinese,english from exam where chinese > 80 or english > 80;
只要一个条件满足就符合整个的查询条件
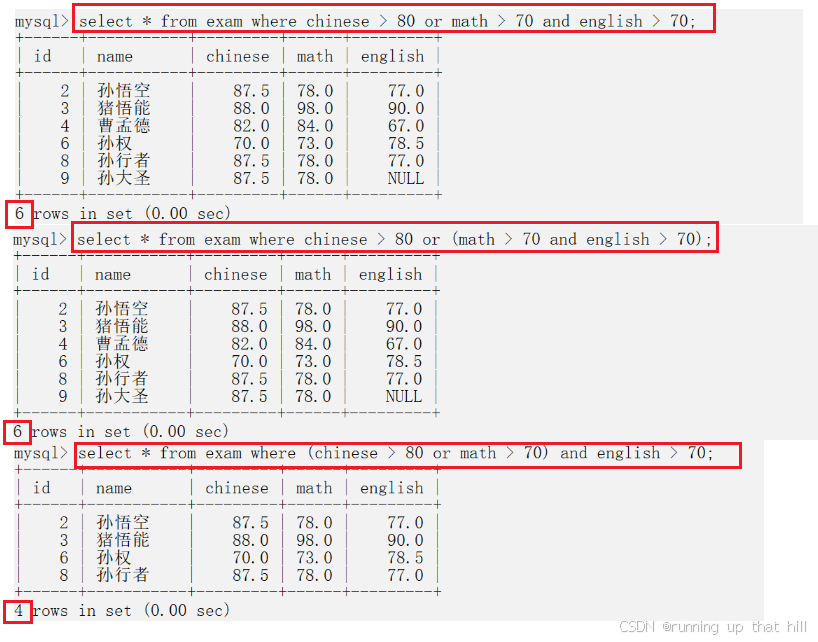
• 观察AND和OR的优先级
select * from exam where chinese > 80 or math > 70 and english > 70;
select * from exam where chinese > 80 or (math > 70 and english > 70);
select * from exam where (chinese > 80 or math > 70) and english > 70;
根据返回的结果可以得出一个结论:
AND 的优先级是大于OR的
NOT > AND > OR
建议用的时候还是手动加括号
范围查询
• 语⽂成绩在 [80, 90] 分的同学及语⽂成绩
# 语文成绩在 [80, 90] 分的同学及语文成绩
# 使用BETWEEN AND 实现
select id,name,chinese from exam where chinese BETWEEN 80 AND 90;
# 使用 AND 实现
select id,name,chinese from exam where chinese >= 80 and chinese <= 90;
• 数学成绩是 78 或者 79 或者 98 或者 99 分的同学及数学成绩
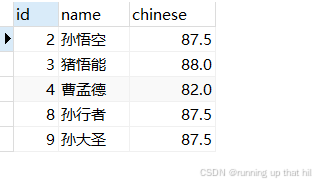
# 数学成绩是 78 或者 79 或者 98 或者 99 分的同学及数学成绩
# 使用 IN 实现
select id,name,math from exam where math IN (78,79,98,99);
# 使用 OR 实现
select id,name,math from exam where math=78 OR math=79 OR math=98 OR math=99;
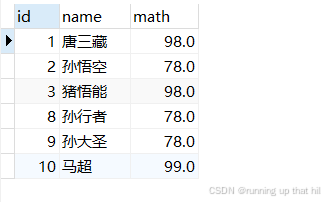
模糊查询
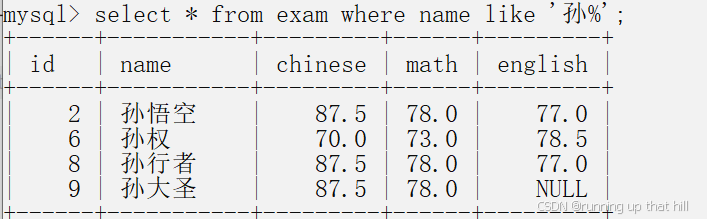
• 查询所有姓孙的同学
select * from exam where name like '孙%';
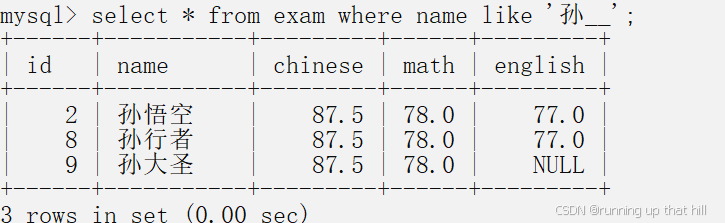
• 查询姓孙且姓名共有两个字同学
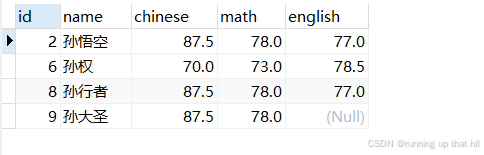
# 查询姓孙且姓名共有两个字同学
select * from exam where name like '孙_';
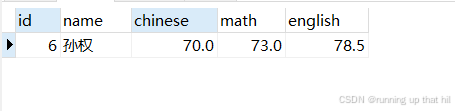
NULL的查询
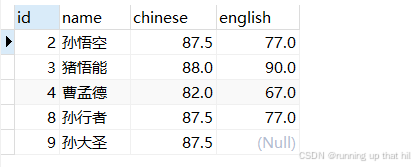
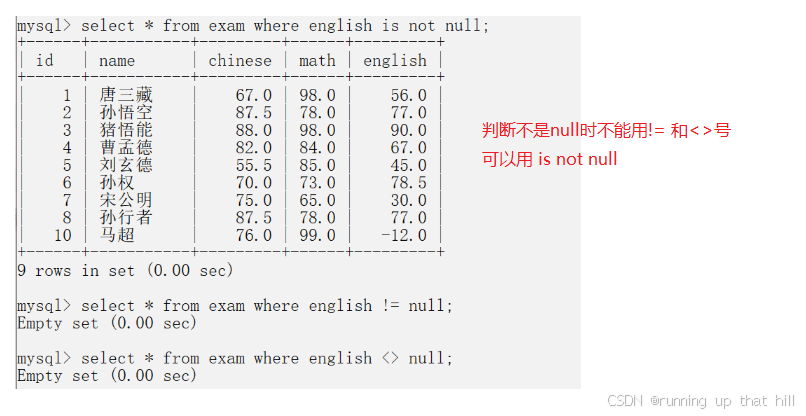
• 查询英语成绩为NULL的记录
# 查询英语成绩为NULL的记录
# 使用 is null
select * from exam where english IS NULL;
# 使用 <=>
select * from exam where english <=> null;
• 查询英语成绩不为NULL的记录

# 查询英语成绩不为NULL的记录
# 使用 is not null
select * from exam where english is not null;
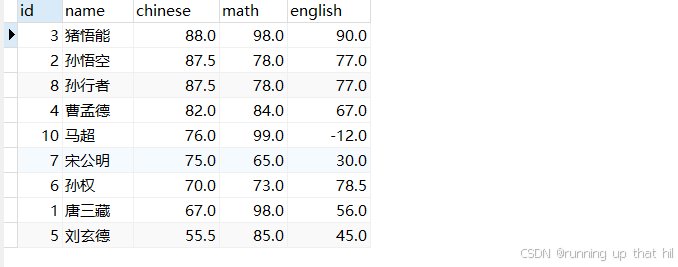
• 所有英语成绩不为NULL的同学,按语⽂成绩从⾼到低排序
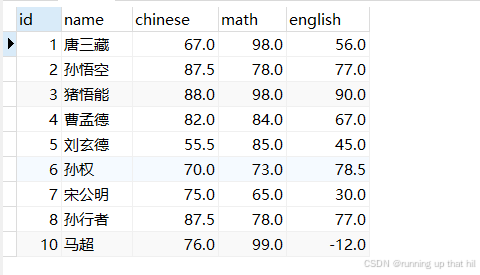
# 所有英语成绩不为NULL的同学,按语文成绩从高到低排序
select * from exam where english is not null order by chinese DESC;
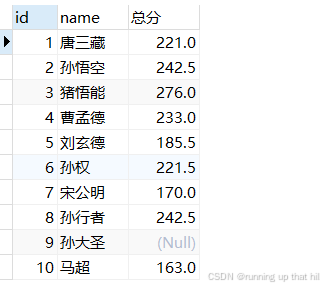
• NULL与其他值进⾏运算结果为NULL
# 观察结果中的总分
select id,name,(chinese+math+english) as 总分 from exam;
注意
• WHERE条件中可以使⽤表达式,但不能使⽤别名
• AND的优先级⾼于OR,在同时使⽤时,建议使⽤⼩括号()包裹优先执⾏的部分
• 过滤NULL时不要使⽤等于号(=)与不等于号(!= , <>)
• NULL与任何值运算结果都为NULL
分⻚查询
不加限制记录条数的查询是不安全的,通过分页查询可以有效的控制一次查询出来的结果集中的记录的条数,可以有效的减少数据库服务器的压力,同时对于用户也比较友好
语法
-- 起始下标为 0
-- 从 0 开始,筛选 num 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT num;
-- 从 start 开始,筛选 num 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT start, num;
-- 从 start 开始,筛选 num 条结果,⽐第⼆种⽤法更明确,建议使⽤
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT num OFFSET start;
⽰例
select * from exam order by id desc limit 2;
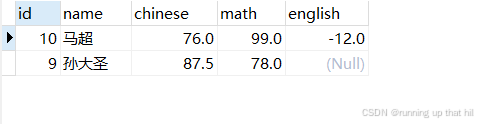
select * from exam order by id desc limit 0, 2;
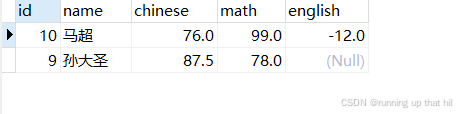
select * from exam order by id desc limit 1, 2;
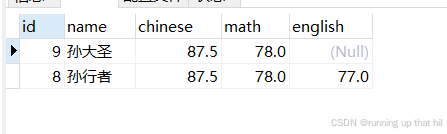

select * from exam order by id desc limit 2 offset 0;
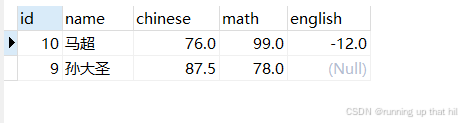
select * from exam order by id desc limit 2 offset 1;
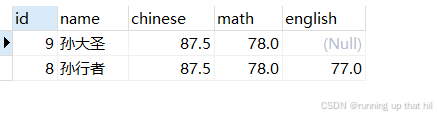
# 查询第一页数据
select * from exam limit 4 offset 0;
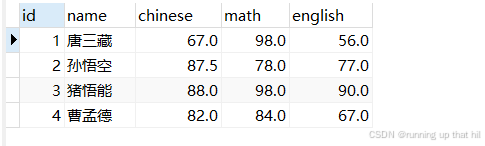
# 查询第二页数据
select * from exam limit 4 offset 4;
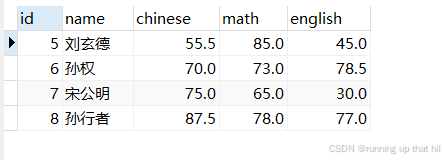
#查询第三页数据,没有达到limit的条数限制,也不会有任何影响,有多少条就显示多少条
select * from exam limit 4 offset 8
Update 修改
语法
UPDATE [LOW_PRIORITY] [IGNORE] table_reference
SET assignment [, assignment] ...
[WHERE where_condition]
[ORDER BY ...]
LIMIT row_count
• 对符合条件的结果进⾏列值更新
示例
• 将孙悟空同学的数学成绩变更为 80 分
# 查看原始数据
select * from exam where name = '孙悟空';

# 更新操作
update exam set math = 80 where name = '孙悟空';
# 查看结果,数学成绩更新成功
select * from exam where name = '孙悟空';
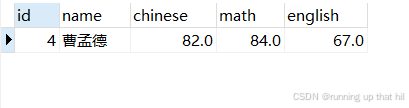
• 将曹孟德同学的数学成绩变更为 60 分,语⽂成绩变更为 70 分

# 查看原始数据
select * from exam where name = '曹孟德';
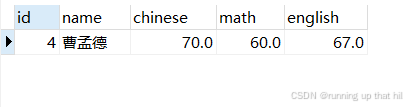
# 更新操作
update exam set math = 60, chinese = 70 where name = '曹孟德';
# 查看结果,成绩更新成功
select * from exam where name = '曹孟德';
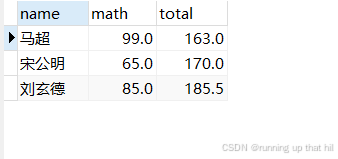
• 将总成绩倒数前三的 3 位同学的数学成绩减去 30 分
# 查看原始数据
select name, math, (chinese+math+english) as total from exam where (chinese+math+english) is not null order by total ASC limit 3;
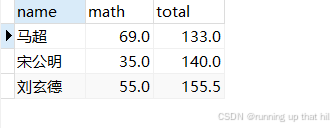
# 更新操作
update exam set math=math-30 where (chinese+math+english) is not null order by (chinese+math+english) ASC limit 3;
# 查看结果,成绩更新成功
select name, math, (chinese+math+english) as total from exam where (chinese+math+english) is not null order by total ASC limit 3;
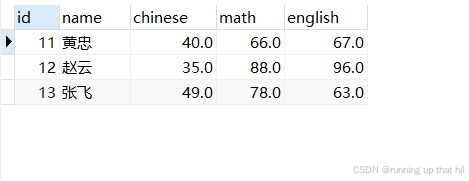
• 把所有语文成绩低于50的同学的语文成绩更新为原来的2倍
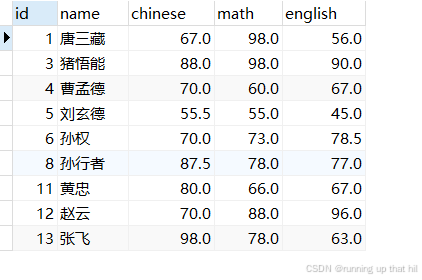
insert into exam values(11,'黄忠',40,66,67),(12,'赵云',35,88,96),(13,'张飞',49,78,63);
# 查看原始数据
select * from exam where chinese < 50;
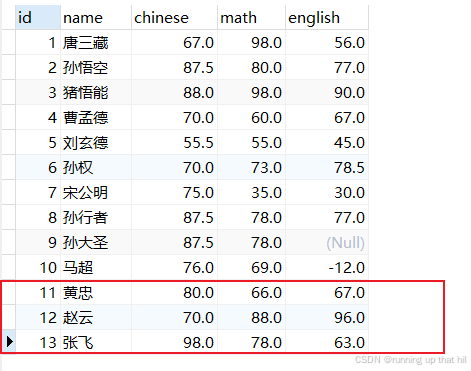
# 更新操作
update exam set chinese = chinese * 2 where chinese < 50;
# 查看结果,成绩更新成功
select * from exam;
Update 注意事项
• 以原值的基础上做变更时,不能使⽤math += 30这样的语法
• 不加where条件时,会导致全表数据被列新,谨慎操作
Delete 删除
语法
DELETE FROM tbl_name [WHERE where_condition] [ORDER BY ...] [LIMIT row_count]
示例
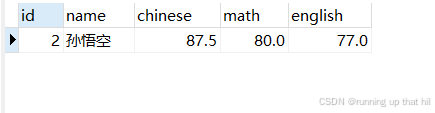
• 删除孙悟空同学的考试成绩
# 查看原始数据
select * from exam where name = '孙悟空';
# 删除操作
delete from exam where name = '孙悟空';
# 查看结果
select * from exam where name = '孙悟空';
select * from exam;
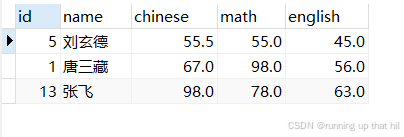
• 删除英语成绩倒数前三的同学的所有考试成绩

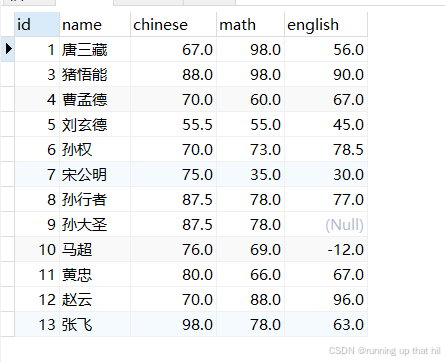
# 查看原始数据
select * from exam order by english ASC limit 3;
# 删除操作
delete from exam order by english ASC limit 3;
# 查看结果
select * from exam order by english ASC limit 3;
select * from exam;
Delete注意事项
• 执⾏Delete时不加条件会删除整张表的数据,谨慎操作
截断表
语法
TRUNCATE [TABLE] tbl_name
示例
# 准备测试表
drop table if exists t_truncate;
create table t_truncate(
id bigint PRIMARY key auto_increment,
name varchar(20)
);
# 插入测试数据
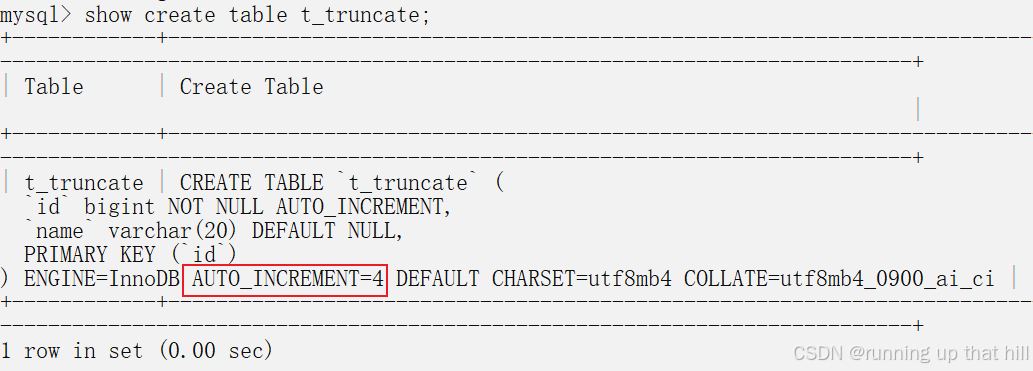
insert into t_truncate(name) values ('A'),('B'),('C');
# 查看测试表
select * from t_truncate;

# 查看建表结构,AUTO_INCREMENT=4
show create table t_truncate;
# 截断表,注意受影响的行数是0
truncate table t_truncate;

# 查看表中的数据
select * from t_truncate;

# 查看表结构,AUTO_INCREMENT已被重置为0
show create table t_truncate;
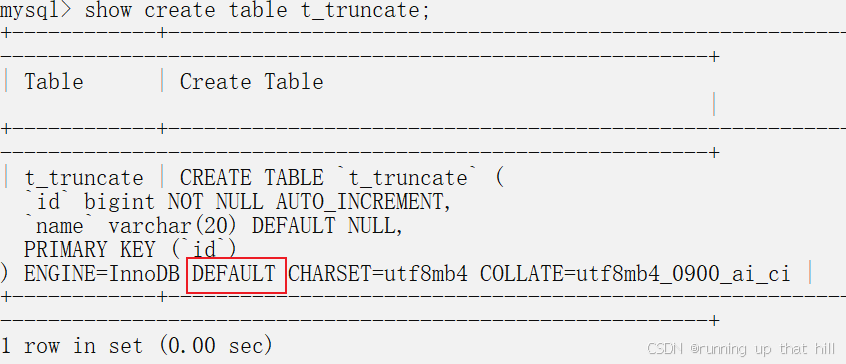
# 继续写入数据
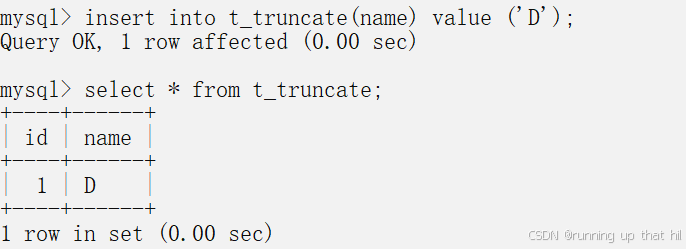
insert into t_truncate(name) value ('D');
# 自增主键从1开如计数
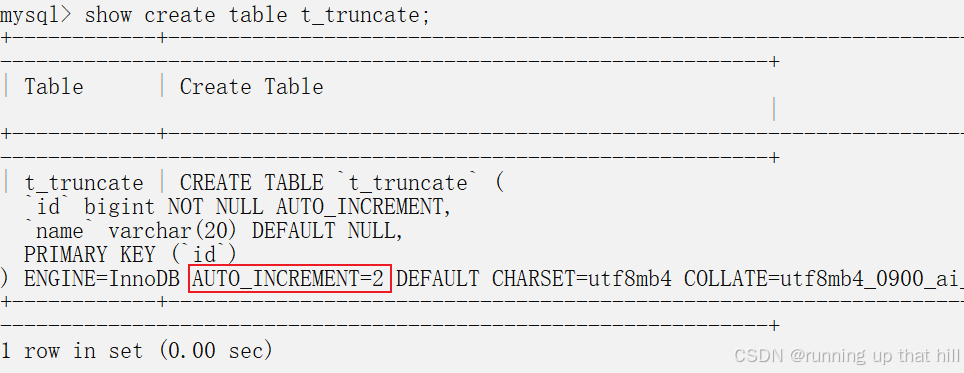
select * from t_truncate;
# 再次查看表结构,AUTO_INCREMENT=2
show create table t_truncate;
Truncate注意事项
• 只能对整表操作,不能像 DELETE ⼀样针对部分数据
• 不对数据操作所以⽐DELETE更快,TRUNCATE在删除数据的时候,不经过真正的事物,所以⽆法
回滚
• 会重置 AUTO_INCREMENT 项
插⼊查询结果
语法
INSERT INTO table_name [(column [, column ...])] SELECT ...
⽰例
• 删除表中的重复记录,重复的数据只能有⼀份
# 创建测试表,并构造数据
drop table if exists t_recored;
create table t_recored(
id bigint,
name varchar(20)
);
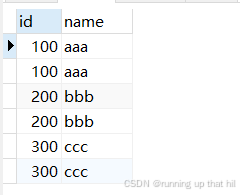
# 插入测试数据
insert into t_recored values
(100, 'aaa'),
(100, 'aaa'),
(200, 'bbb'),
(200, 'bbb'),
(300, 'ccc'),
(300, 'ccc');
# 查看结果
select * from t_recored;
• 实现思路:原始表中的数据⼀般不会主动删除,但是真正查询时不需要重复的数据,如果每次查询
都使⽤DISTINCT进⾏去重操作,会严重效率。可以创建⼀张与 t_recored 表结构相同的表,把
去重的记录写⼊到新表中,以后查询都从新表中查,这样真实的数据不丢失,同时⼜能保证查询效
率
# 创建⼀张新表,表结构与t_recored相同
create table t_recored_new like t_recored;
# 新表中没有记录
select * from t_recored_new;

# 原表中的记录去重后写入到新表
insert into t_recored_new select distinct * from t_recored;

# 查询新表中的记录,实现去重
select * from t_recored_new;
# 新表与原来重命名
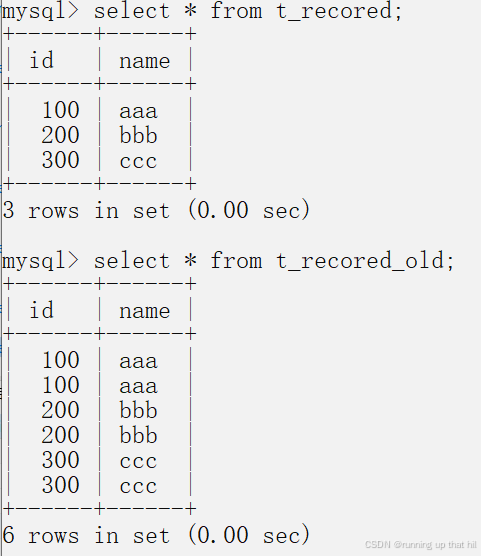
rename table t_recored to t_recored_old, t_recored_new to t_recored;

# 查询重命名后表中的记录,实现需求且原来中的记录不受影响
select * from t_recored;
select * from t_recored_old;
聚合函数
聚合查询本质上是针对数据表中的行和行进行运算,之前的表达式查询,是对一行记录中的列和列之间进行运算,比如: 语文成绩+数学成绩+英语成绩
常⽤函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最⼤值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最⼩值,不是数字没有意义 |
COUTN
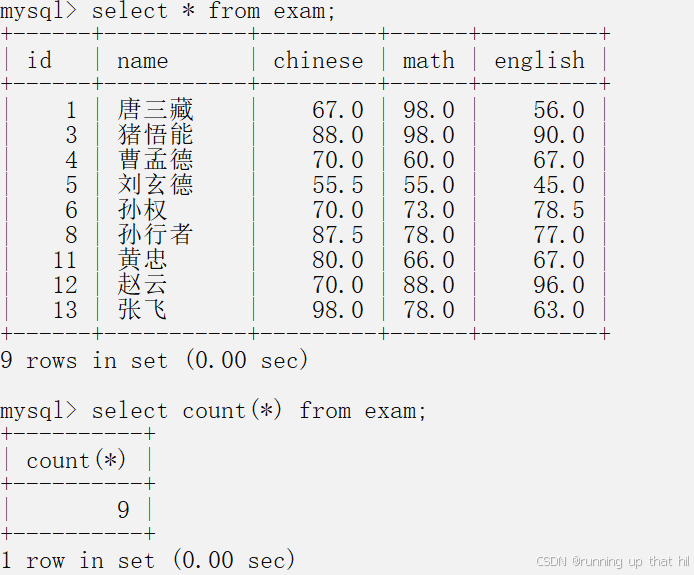
• 统计exam表中有多少记录
# 使用 * 做统计
select * from exam;
select count(*) from exam;
# 使用常量做统计
select count(1) from exam;

• 统计有多少学⽣参加数学考试
# 统计有多少学生参加数学考试
# 使用指定列做统计
select count(math) from exam;
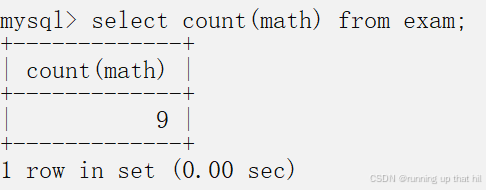
insert into exam values (14, '司马懿', 90, 88, NULL);
select * from exam;
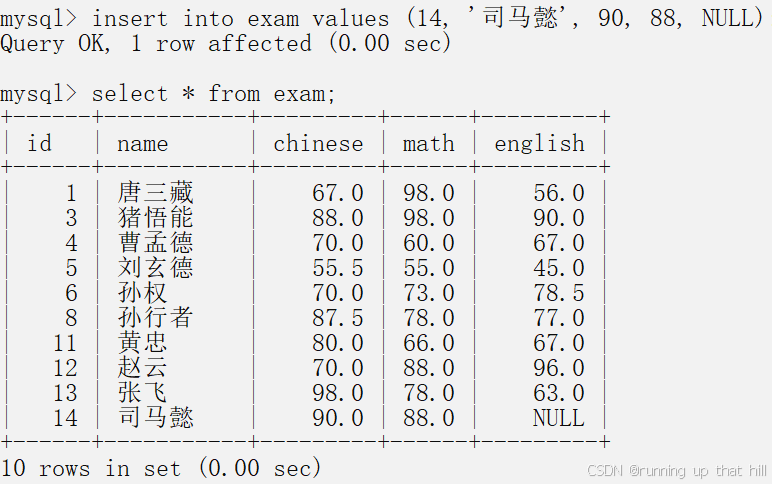
• 统计有多少学⽣参加英语考试
select count(id) from exam;
# count(列名),如果说列中有NULL值则不会被统计在内
select count(english) from exam;
• 统计语⽂成绩⼩于60分的学⽣个数
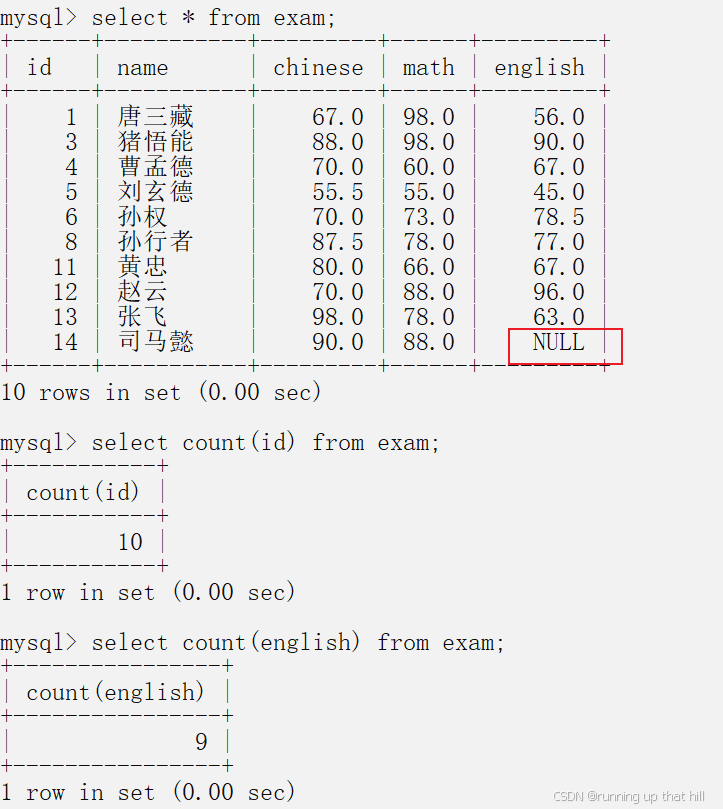
# 统计语文成绩小于60分的学生个数
# 加入where条件
select count(chinese) from exam where chinese < 60;

SUM
把查询结果中所有行中的指定列进行相加,注意: 列的数据类型必须是数值型,不能是字符或日期。
结果在一个临时表中,结果不受表中字段长度约束
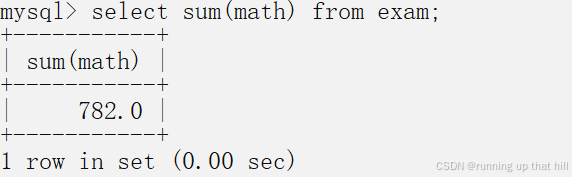
• 统计所有学⽣数学成绩总分
# 统计所有学生数学成绩总分
select sum(math) from exam;
• 统计所有学⽣英语成绩总分
# 统计所有学生英语成绩总分
# 值为NULL的列不参与统计
select * from exam;
select sum(english) from exam;
• 不能统计⾮数值的列

# 不能统计非数值的列
select sum(name) from exam;
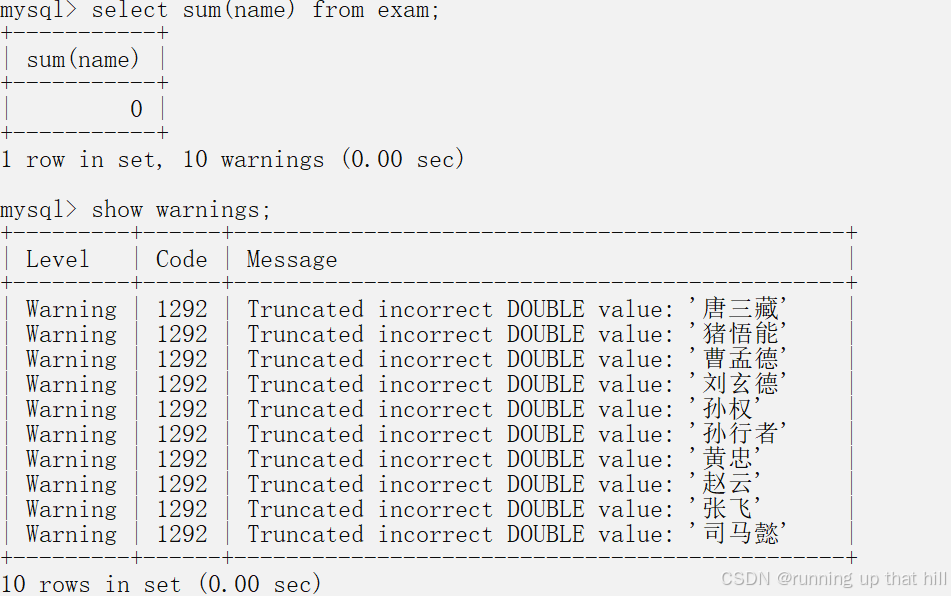
AVG
• 统计英语成绩的平均分
# 统计英语成绩的平均分
# NULL值不参与统计
select avg(english) from exam;
• 统计平均总分
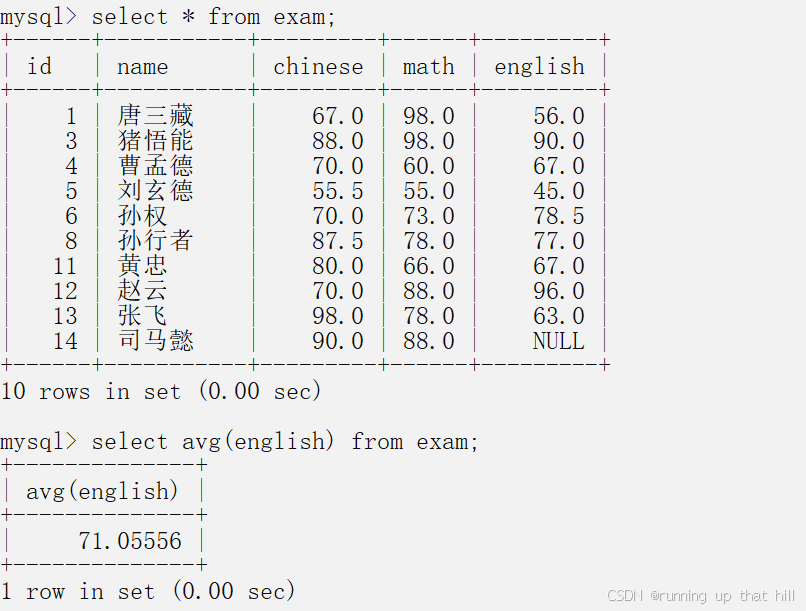
# 统计平均总分
select sum(chinese+math+english) from exam;
select sum(chinese+math+english) as 总分 from exam;

MAX
• 查询英语最⾼分
# 查询英语最高分
select max(english) from exam;
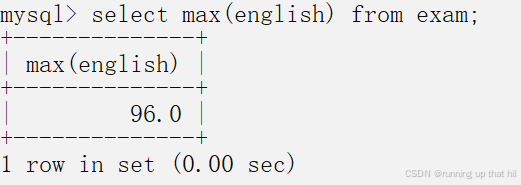
MIN
• 查询 > 70 分以上的数学最低分
# 查询 > 70 分以上的数学最低分
select min(math) from exam where math > 70;
• 查询数学成绩的最⾼分与英语成绩的最低分

# 查询数学成绩的最高分与英语成绩的最低分,NULL值不参与统计
# 可以使用多个聚合函数
select max(math) '数学最高分', min(english) '英语最低分' from exam;

Group by 分组查询
GROUP BY ⼦句的作⽤是通过⼀定的规则将⼀个数据集划分成若⼲个⼩的分组,然后针对若⼲个
分组进⾏数据处理,⽐如使⽤聚合函数对分组进⾏统计。
语法
SELECT {col_name | expr} ,... ,aggregate_function (aggregate_expr)
FROM table_references
GROUP BY {col_name | expr}, ...
[HAVING where_condition]
• col_name | expr:要查询的列或表达式,可以有多个,必须在 GROUP BY ⼦句中作为分组的依
据
• aggregate_function:聚合函数,⽐如COUNT(), SUM(), AVG(), MAX(), MIN()
• aggregate_expr:聚合函数传⼊的列或表达式,如果列或表达式不在 GOURP BY ⼦句中,必须
包含中聚合函数中
示例
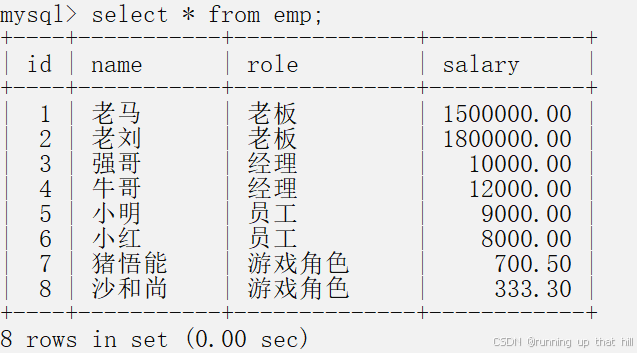
• 准备测试表及数据职员表emp,列分别为:id(编号),name(姓名),role(⻆⾊),salary(薪⽔)
drop table if exists emp;
create table emp (
id bigint primary key auto_increment,
name varchar(20) not null,
role varchar(20) not null,
salary decimal(10, 2) not null
);
insert into emp values (null, '老马', '老板', 1500000.00);
insert into emp values (null, '老刘', '老板', 1800000.00);
insert into emp values (null, '强哥', '经理', 10000.00);
insert into emp values (null, '牛哥', '经理', 12000.00);
insert into emp values (null, '小明', '员工', 9000.00);
insert into emp values (null, '小红', '员工', 8000.00);
insert into emp values (null, '猪悟能', '游戏角色', 700.5);
insert into emp values (null, '沙和尚', '游戏角色', 333.3);
select * from emp;
• 统计每个⻆⾊的⼈数
# 统计每个角色的人数
select role,count(*) from emp group by role;
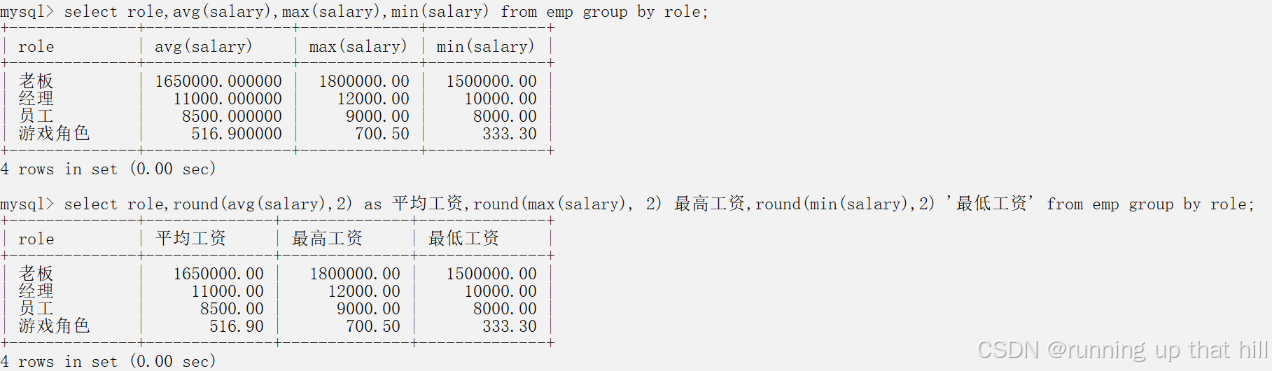
• 统计每个⻆⾊的平均⼯资,最⾼⼯资,最低⼯资

# 统计每个角色的平均工资,最高工资,最低工资
select role,avg(salary),max(salary),min(salary) from emp group by role;
select role,round(avg(salary),2) as 平均工资,round(max(salary), 2) 最高工资,round(min(salary),2) '最低工资' from emp group by role;
having⼦句
使⽤GROUP BY 对结果进⾏分组处理之后,对分组的结果进⾏过滤时,不能使⽤ WHERE ⼦句,⽽要使⽤ HAVING ⼦句
where 是对表中每一行的真实数据进行过滤的
having 是对group by 之后,计算出来的结果进行过滤的
• 显示平均⼯资低于1500的⻆⾊和它的平均⼯资
# 显示平均工资低于1500的角色和它的平均工资,并按升序排序
select role,avg(salary) from emp group by role having avg(salary) < 1500 order by avg(salary) ASC;
select role,avg(salary) 平均工资 from emp group by role having 平均工资 < 1500 order by avg(salary) ASC;
select role,avg(salary) 平均工资 from emp group by role having 平均工资 < 1500 order by 平均工资 ASC;

Having 与Where 的区别
• Having ⽤于对分组结果的条件过滤
• Where ⽤于对表中真实数据的条件过滤
内置函数
⽇期函数
| 函数 | 说明 |
|---|---|
CURDATE() | 返回当前⽇期,同义词 CURRENT_DATE , CURRENT_DATE() |
CURTIME() | 返回当前时间,同义词 CURRENT_TIME , CURRENT_TIME([fsp]) |
NOW() | 返回当前⽇期和时间,同义语 CURRENT_TIMESTAMP ,CURRENT_TIMESTAMP |
DATE(data) | 提取date或datetime表达式的⽇期部分 |
ADDDATE(date,INTERVAL exprunit) | 向⽇期值添加时间值(间隔),同义词 DATE_ADD() |
SUBDATE(date,INTERVAL exprunit) | 向⽇期值减去时间值(间隔),同义词 DATE_SUB() |
DATEDIFF(expr1,expr2) | 两个⽇期的差,以天为单位,expr1 - expr2 |
示例
• 获取当前⽇期
# 获取当前日期
select CURDATE();
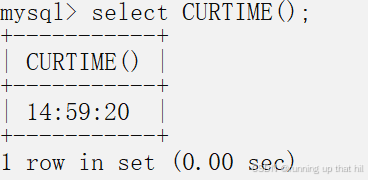
• 获取当前时间

# 获取当前时间
select CURTIME();
• 获取当前⽇期和时间
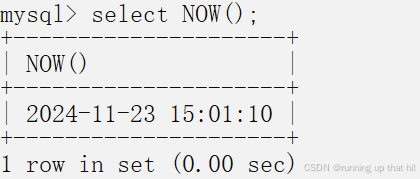
# 获取当前日期和时间
select NOW();
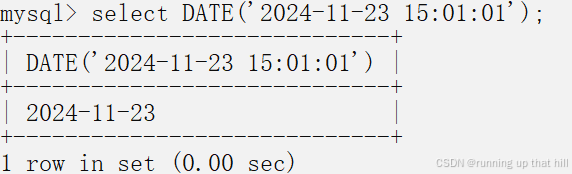
• 提取指定datatime的⽇期部分
# 提取指定datatime的日期部分
select DATE('2024-11-23 15:01:01');
• 在给定⽇期的基础上加31天
# 在给定日期的基础上加31天
select ADDDATE('2024-11-23',INTERVAL 31 DAY);
• 在给定⽇期的基础上减去1⽉
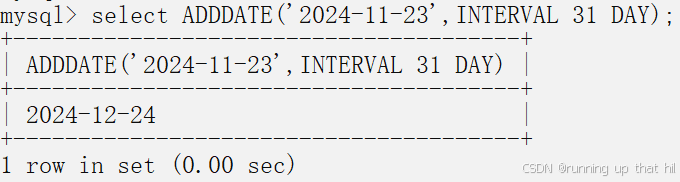
# 在给定日期的基础上减去1月
select SUBDATE('2024-1-23',INTERVAL 1 MONTH);
• 计算两个⽇期之间相差多少天

# 计算两个日期之间相差多少天
# 在计算时只使用日期部分
select DATEDIFF('2024-12-31 23:59:59','2024-12-30');

# 表达式1表示的日期早于表达式2表示的日期时返回负数
select DATEDIFF('2024-12-30', '2024-12-31 23:59:59');

参考链接
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html
https://dev.mysql.com/doc/refman/8.0/en/expressions.html#temporal-intervals
字符串处理函数
| 函数 | 说明 |
|---|---|
CHAR_LENGTH(str) | 返回给定字符串的⻓度,同义词 CHARACTER_LENGTH() |
LENGTH(str) | 返回给定字符串的字节数,与当前使⽤的字符编码集有关 |
CONCAT(str1,str2,...) | 返回拼接后的字符串 |
CONCAT_WS(separator,str1,str2,...) | 返回拼接后带分隔符的字符串 |
LCASE(str) | 将给定字符串转换成⼩写,同义词 LOWER() |
UCASE(str) | 将给定字符串转换成⼤写,同义词UPPER() |
HEX(str), HEX(N) | 对于字符串参数str, HEX()返回str的⼗六进制字符串表⽰形式,对于数字参数N, HEX()返回⼀个⼗六进制字符串表⽰形式 |
INSTR(str,substr) | 返回substring第⼀次出现的索引 |
INSERT(str,pos,len,newstr) | 在指定位置插⼊子字符串,最多不超过指定的字符数 |
SUBSTR(str,pos),SUBSTR(str FROM pos FOR len) | 返回指定的子字符串,同义词SUBSTRING(str,pos) |
SUBSTRING(str FROM pos FOR len) REPLACE(str,from_str,to_str) | 把字符串str中所有的from_str替换为to_str,区分⼤⼩写 |
STRCMP(expr1,expr2) | 逐个字符⽐较两个字符串,返回 -1, 0 , 1 |
LEFT(str,len) ,RIGHT(str,len) | 返回字符串str中最左/最右边的len个字符 |
LTRIM(str) , RTRIM(str) ,TRIM(str) | 删除给定字符串的前导、末尾、前导和末尾的空格 |
TRIM([{LEADING | TRAILING | BOTH } [remstr] FROM] str) | 删除给定符串的前导、末尾或前导和末尾的指定字符串 |
示例
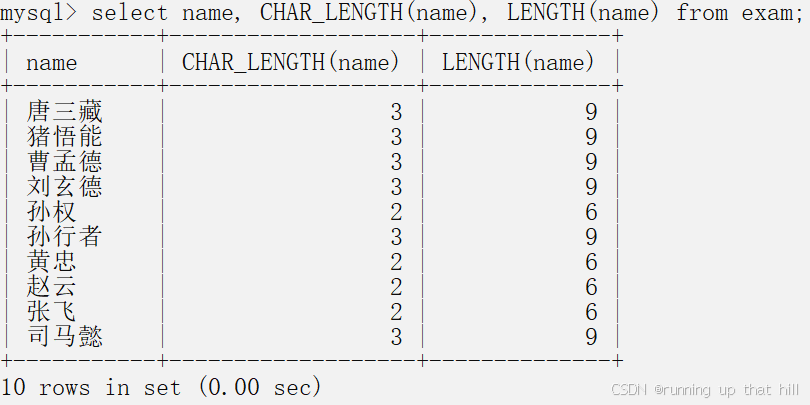
• 显⽰所有参加考试的学⽣姓名、姓名字符数和字节⻓度
# 显示所有参加考试的学生姓名、姓名字符数和字节长度
select name, CHAR_LENGTH(name), LENGTH(name) from exam;
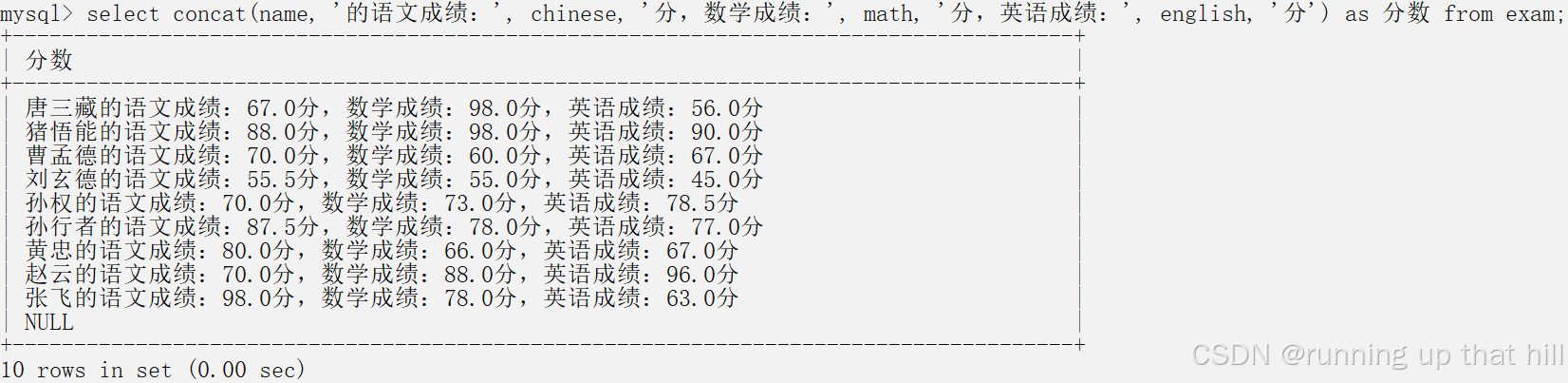
• 显示学生的考试成绩,格式为 “XXX的语⽂成绩:XXX分,数学成绩:XXX分,英语成绩:XXX分”
# 显示学生的考试成绩,格式为 "XXX的语文成绩:XXX分,数学成绩:XXX分,英语成绩:XXX分"
select concat(name, '的语文成绩:', chinese, '分,数学成绩:', math, '分,英语成绩:', english, '分') as 分数 from exam;
• 拼接后的字符串⽤逗号隔开
# 拼接后的字符串用逗号隔开
select CONCAT_WS(',',name,chinese,math,english) 分数 from exam;
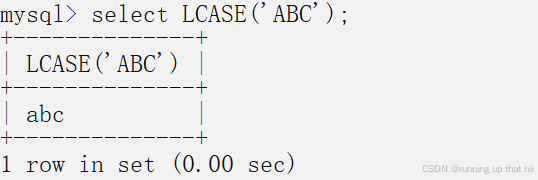
• 将给定字符串转换成⼩写

# 将给定字符串转换成小写
select LCASE('ABC');
• 将给定字符串转换成⼩写
# 将给定字符串转换成大写
select UCASE('abc');
• 转换为⼗六进制
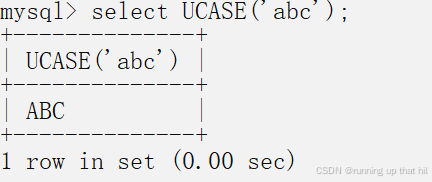
# 转换为十六进制
select HEX('hello MySQL');
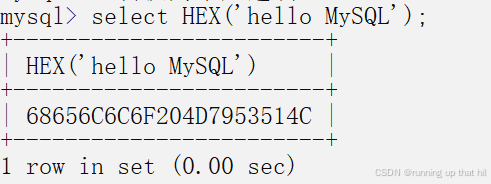
# 数字
select HEX(15);
• 子字符串第一次出现的索引
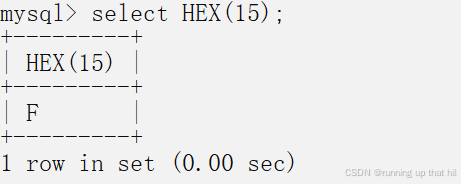
# 子字符串第一次出现的索引
select INSTR('hello MySQL','sql');
• 指定位置插⼊⼦字符串
# 指定位置插入子字符串
# 在指定位置插入
select INSERT('hello database',7,0,'MySQL ');
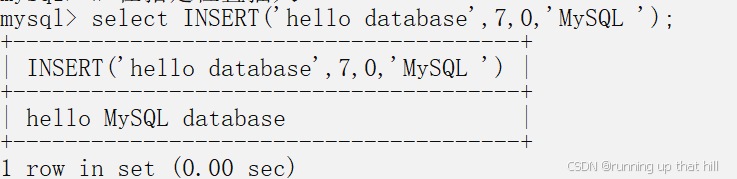
# 覆盖20位,如果从写入点往后不足20位相当于删除后面所有字符
select INSERT('hello database',7,20,'MySQL ');
• 返回指定的⼦字符串
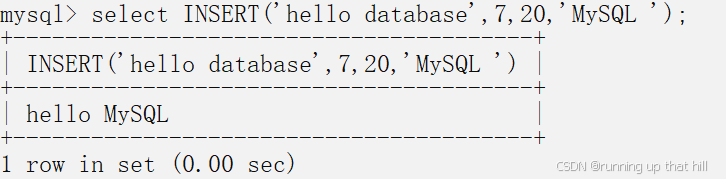
# 返回指定的子字符串
# 从'hello MySQL'的第七个字符开始截取
select SUBSTR('hello MySQL',7);
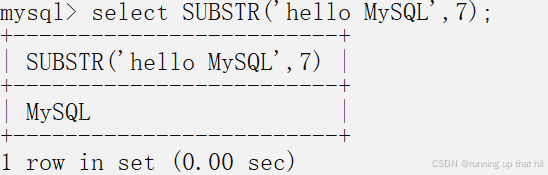
# 从'hello MySQL'的第七个字符开始截取1个字符
select SUBSTR('hello MySQL' FROM 7 FOR 1);
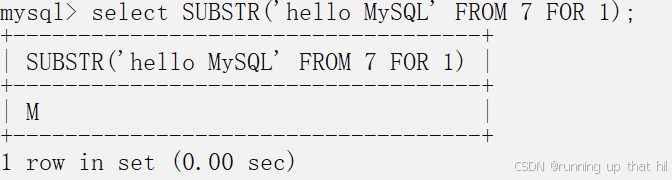
# 从'hello MySQL'的第七个字符开始截取10个字符,不足10个读到整个字符串结尾
select SUBSTR('hello MySQL' FROM 7 FOR 10);
• 替换字符串
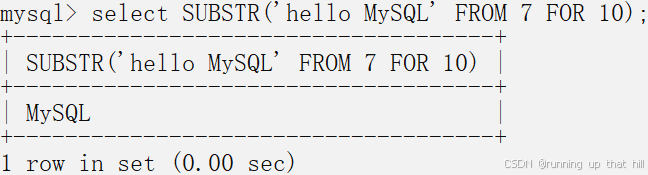
# 替换字符串
# 把Database替换成MySQL, 区分大小写
select REPLACE('hello Database','Database','MySQL');
• ⽐较两个字符串
# 比较两个字符串
# 观察返回的结果
select STRCMP('text','text1');
select STRCMP('text','text');
select STRCMP('text1','text');
• 返回字符串str中最左/最右边的len个字符

# 返回字符串str中最左/最右边的len个字符
# 最左边的5个字符
select LEFT('hello MySQL', 5);
# 最右边的5个字符
select RIGHT('hello MYSQL', 5);
• 删除给定字符串的前导、末尾、前导和末尾的空格

# 删除给定字符串的前导、末尾、前导和末尾的空格
select ' ABC', LTRIM(' ABC'),'ABC ',RTRIM('ABC '),' ABC ',TRIM(' ABC ');
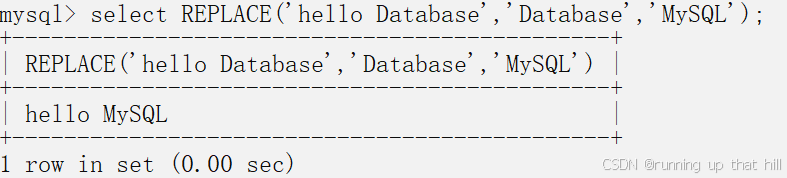
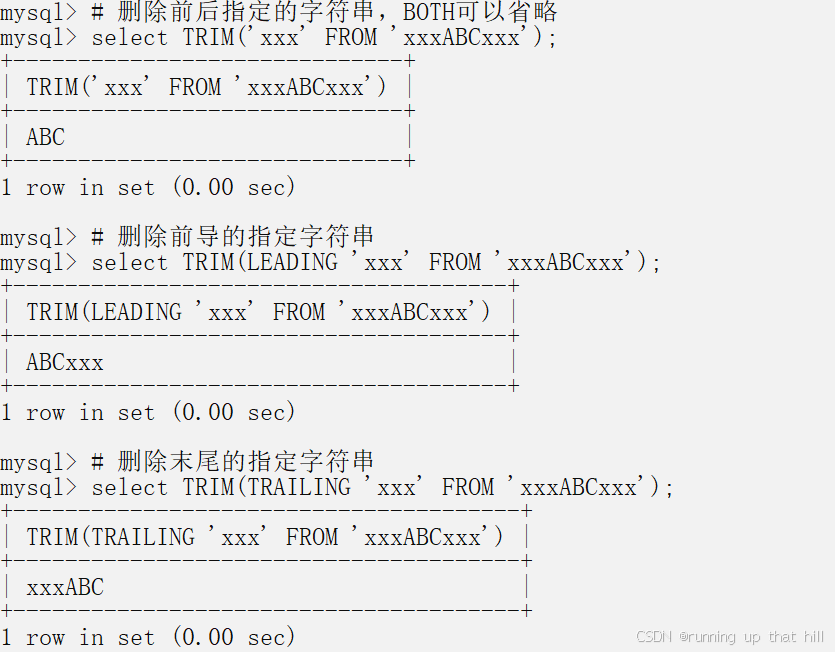
• 删除给定符串的前导、末尾或前导和末尾的指定字符串

# 删除给定符串的前导、末尾或前导和末尾的指定字符串
# 删除前后指定的字符串,BOTH可以省略
select TRIM('xxx' FROM 'xxxABCxxx');
# 删除前导的指定字符串
select TRIM(LEADING 'xxx' FROM 'xxxABCxxx');
# 删除末尾的指定字符串
select TRIM(TRAILING 'xxx' FROM 'xxxABCxxx');
参考链接
https://dev.mysql.com/doc/refman/8.0/en/string-functions.html
数学函数
| 函数 | 说明 |
|---|---|
ABS(X) | 返回X的绝对值 |
CEIL(X) | 返回不⼩于X的最⼩整数值,同义词是 CEILING(X) |
FLOOR(X) | 返回不⼤于X的最⼤整数值 |
CONV(N,from_base,to_base) | 不同进制之间的转换 |
FORMAT(X,D) | 将数字X格式化为“#,###,###”的格式。##',四舍五⼊到⼩数点后D位,并以字符串形式返回 |
RAND([N]) | 返回⼀个随机浮点值,取值范围 [0.0, 1.0) |
ROUND(X), ROUND(X,D) | 将参数X舍⼊到⼩数点后D位 |
CRC32(expr) | 计算指定字符串的循环冗余校验值并返回⼀个32位⽆符号整数 |
示例
• 返回-3.14的绝对值
# 返回-3.14的绝对值
select abs(-3.14);
• 返回不⼩于20.36的最⼩整数值

# 返回不小于20.36的最小整数值
select CEIL(20.36);

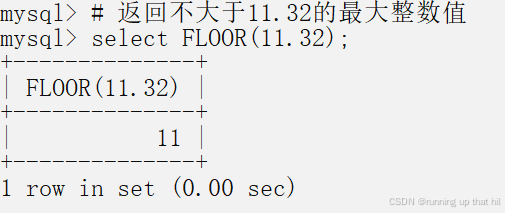
• 返回不⼤于11.32的最⼩整数值
# 返回不大于11.32的最大整数值
select FLOOR(11.32);
• 10进制转为16进制
# 10进制转为16进制
select CONV(15,10,16);

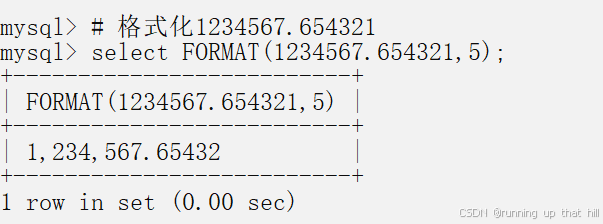
• 格式化1234567.654321
# 格式化1234567.654321
select FORMAT(1234567.654321,5);
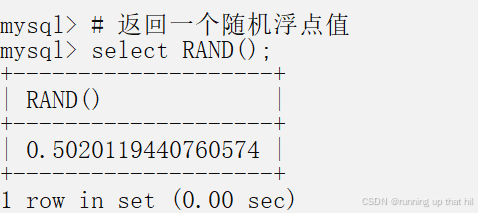
• 返回⼀个随机浮点值
# 返回一个随机浮点值
select RAND();
• 舍弃到⼩数点后6位
# 舍弃到小数点后6位
select ROUND(RAND(),6);

# 生成一个6位数的随机数
select ROUND(RAND(),6) * 1000000;

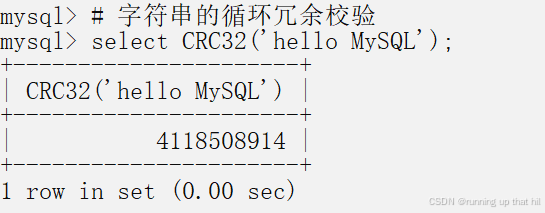
• 字符串的循环冗余校验
# 字符串的循环冗余校验
select CRC32('hello MySQL');
参考链接
https://dev.mysql.com/doc/refman/8.0/en/numeric-functions.html
其他常⽤函数
| 函数 | 说明 |
|---|---|
version() | 显⽰当前数据库版本 |
database() | 显⽰当前正在使⽤的数据库 |
user() | 显⽰当前⽤户 |
md5(str) | 对⼀个字符串进⾏md5摘要,摘要后得到⼀个32位字符串 |
ifnull(val1, val2) | 如果val1为NULL,返回val2,否则返回 val1 |
示例
• 显示当前数据库版本
# 显示当前数据库版本
select version();
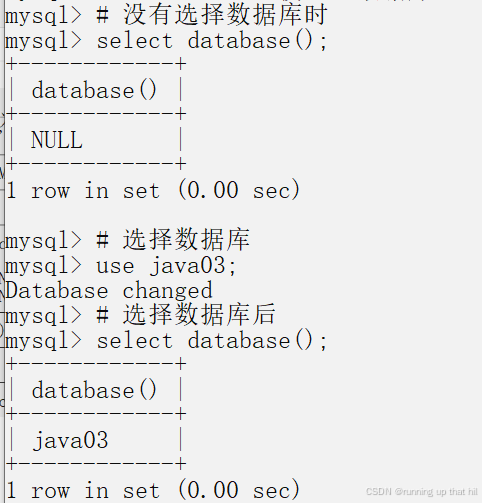
• 显⽰当前正在使⽤的数据库

# 显示当前正在使用的数据库
# 没有选择数据库时
select database();
# 选择数据库
use java03;
# 选择数据库后
select database();
• 显⽰当前⽤户
# 显示当前用户
select user();
• 对⼀个字符串进⾏md5加密
# 对一个字符串进行md5加密
select MD5('hello world');
• ifnull函数
# ifnull函数
# 第一个参数不为NULL, 返回第一个参数的值
select IFNULL('database','MySQL');
# 第一个参数为NULL, 返回第二个参数的值
select IFNULL(NULL,'MySQL');

关于这篇文章的内容先了解到这里,希望这篇文章对大家有帮助,谢谢大家的阅读!!!