什么是分布式事务?
在单体应用中,事务管理相对简单,通过数据库的ACID特性(原子性、一致性、隔离性、持久性)来确保数据的一致性。然而,随着业务的发展,系统架构逐渐演变为微服务架构,多个服务之间需要协同工作。这时候,事务管理变得复杂起来,因为数据操作分布在不同的服务和数据库上。
常见的分布式事务解决方案
在讨论本地消息表之前,我们先了解一下常见的分布式事务解决方案:
1. 二阶段提交(2PC)
二阶段提交协议是经典的分布式事务协议,分为准备阶段和提交阶段。在准备阶段,协调者向所有参与者询问是否可以提交事务,如果所有参与者都同意,进入提交阶段;否则,进入回滚阶段。
虽然2PC可以保证事务的一致性,但它存在一些问题:
-
性能开销大:准备阶段和提交阶段需要两次网络通信,增加了延迟。
-
单点故障:协调者的故障会导致整个事务挂起。
-
锁定资源:在准备阶段,参与者会锁定资源,影响系统的并发性。
2. 三阶段提交(3PC)
三阶段提交协议是对二阶段提交的改进,增加了一个预提交阶段,以减少单点故障和提高系统的容错性。但它仍然存在性能开销大和实现复杂度高的问题。
3. TCC(Try-Confirm/Cancel)
TCC模型将事务分为三个阶段:
-
Try阶段:预留资源
-
Confirm阶段:确认执行
-
Cancel阶段:取消执行
TCC比2PC更灵活,但需要业务层面实现补偿逻辑,增加了开发成本。
4. 本地消息表
接下来,我们重点介绍一种比较简单、实用且高效的解决方案——本地消息表。
本地消息表的原理
本地消息表是一种通过在本地数据库中记录消息状态来实现分布式事务的方法。其核心思想是将业务操作和消息记录放在同一个本地事务中,确保它们要么同时成功,要么同时失败。然后,通过一个独立的消息调度器异步地将消息发送到消息队列中,从而实现跨服务的事务一致性。
具体流程如下:
-
业务操作与消息记录:在同一个本地事务中,完成业务操作并将消息记录插入本地消息表。
-
消息调度器:一个独立的消息调度器不断扫描本地消息表,找到需要发送的消息,并将其发送到消息队列。
-
消费消息:其他服务从消息队列中消费消息,并执行相应的业务操作。
通过这种方式,我们将跨服务的分布式事务问题转化为本地事务问题,利用本地数据库的ACID特性,确保业务操作和消息记录的一致性。
本地消息表的实现步骤
通过本地消息表(也称为可靠消息表)实现分布式事务是一种常见的做法,用于保证在分布式环境中消息的可靠传递和事务的一致性。以下是使用本地消息表实现分布式事务的一般步骤:
-
消息生产方(也就是发起方),需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
-
消息消费方(也就是发起方的依赖方),需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
-
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。
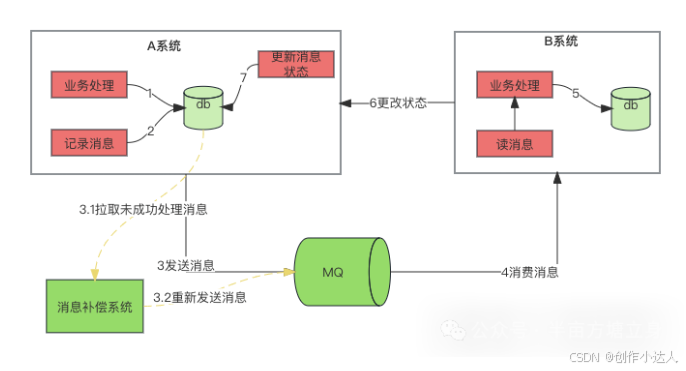
以下是具体步骤:
0. 创建本地消息表:
在数据库中创建一个本地消息表,用于存储待发送的消息以及消息的发送状态和相关信息。表结构可以包含字段如下:
-
message_id:消息的唯一标识。 -
message_body:消息内容。 -
status:消息状态,如待发送、已发送等。 -
create_time:消息创建时间。 -
其他字段,如重试次数、发送时间等。
1. 业务处理: 业务处理时通常进行db变更
2. 将业务变更信息插入记录表:在业务逻辑中,当需要发送消息时,首先将消息插入到本地消息表中,设置状态为待发送。
3. 发送消息,1、2、3步骤在同一个本地事务中。如果本地事务执行成功,提交本地事务和消息表的记录;如果本地事务失败,回滚本地事务和消息表的记录。
3.1、3.2. 消息确认机制:
单独创建一个后台线程或定时任务,定时扫描本地消息表中状态为待发送的消息,并将这些消息发送到消息队列。在成功发送到消息队列后,将消息表中对应的状态修改为已发送。此外,可以根据需要实现消息发送失败后的重试机制。
4. B系统消费消息:
消费者监听消息队列,解析消息内容。
5. B系统进行业务逻辑处理:
进行业务逻辑处理,更改DB。此步骤必须要保证幂等性。
4、5 如果失败依赖3.1、3.2的定时投放
6. 确认消费完成:
当消息消费完成后,调用A系统进行状态变更
6、7如果失败相当于两个分布式系统的数据已经一致了,但是本地消息表的状态还是错的。这种情况下借助3.1、3.2的重新投放策略,让下游幂等处理再更改消息表的状态也能解决。或者A系统也可以查询B系统的处理状态,如果成功直接更改状态
注意事项
使用本地消息表实现分布式事务可以确保消息在分布式环境中的可靠传递和一致性。然而,需要注意以下几点:
-
消息的幂等性: 消费者一定需要保证接口的幂等性,消息的幂等性非常重要,以防止消息重复处理导致的数据不一致。
-
本地消息表的设计: 本地消息表的设计需要考虑到消息状态、重试次数、创建时间等字段,以便实现消息的跟踪和管理。
-
定时任务和重试机制: 需要实现定时任务或者重试机制来确保消息的可靠发送和处理。
本地消息表实现分布式事务缺点及解决方式
-
数据大时,消息堆积,扫表效率慢
-
定时扫表存在延迟问题
消息堆积、扫表效率慢
-
索引优化:在消息表中对状态字段增加索引,以加速扫表操作。索引可以加速消息的检索和筛选,从而提高操作效率。
-
分页查询:将扫表操作划分为多次分页查询,避免一次性查询大量数据造成的性能问题。
-
表较大时进行分库分表:如果表较大可以进行分库分表操作。
-
多线程分段查询:
-
如果有业务标识,可以通过业务标识进行多线程分段扫表查询。
-
如果没有业务标识可以按区间查询比如线程1查询0-1000的数据,线程2查询1001-2000的数据。
-
定时任务扫表延迟问题
定时任务可能由于各种原因导致扫表延迟,进而影响事务处理的实时性。以下是一些应对方法:
-
异步发送MQ改为同步调用接口:异步改为同步调用B系统接口,如果失败了再进行异步发送MQ消息。
-
发送MQ延迟消息,去掉定时任务,避免大量扫表处理。
-
分布式定时任务:使用分布式定时任务框架,将定时任务分散到多个节点上执行,以减少单个节点的压力,同时提高定时任务的稳定性和准确性。
-
增加资源:增加定时任务执行节点的数量,以提高并发处理能力,减少延迟。