本文为为🔗365天深度学习训练营内部文章
原作者:K同学啊
一 导入数据
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
import seaborn as sns
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset,DataLoader
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
'''
导入数据
'''
df = pd.read_csv('heart.csv')
print(df)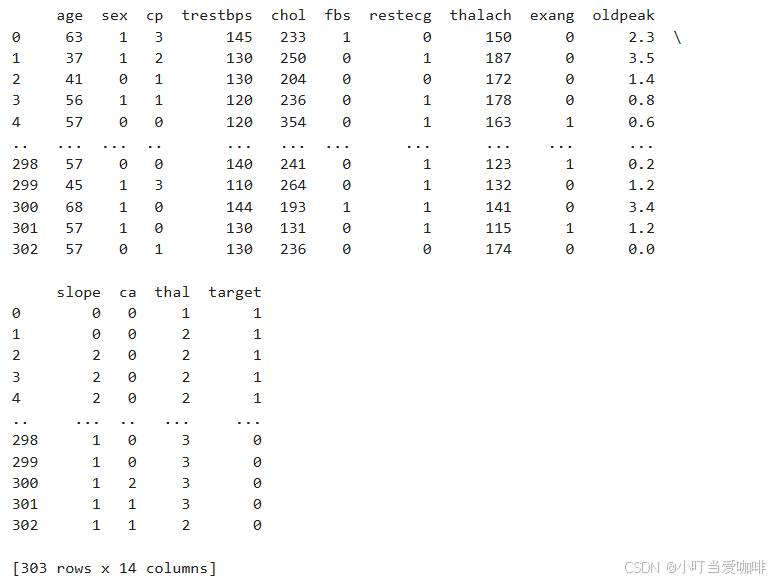
二 构建数据集
'''
构建数据集
'''
# 1. 标准化
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
sc = StandardScaler()
X = sc.fit_transform(X)
# 2.划分数据集
X = torch.tensor(np.array(X),dtype=torch.float32)
y = torch.tensor(np.array(y),dtype=torch.int64)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.1,random_state=14)
# 3.构建数据加载器
train_dl = DataLoader(TensorDataset(X_train,y_train),batch_size=64,shuffle=False)
test_dl = DataLoader(TensorDataset(X_test,y_test),batch_size=64,shuffle=False)三 模型训练
'''
模型训练
'''
# 1.构建模型
class model_rnn(nn.Module):
def __init__(self):
super(model_rnn,self).__init__()
self.rnn0 = nn.RNN(input_size=13,hidden_size=200,num_layers=1,batch_first=True)
self.fc0 = nn.Linear(200,50)
self.fc1 = nn.Linear(50,2)
def forward(self,x):
out,hidden1 = self.rnn0(x)
out = self.fc0(out)
out = self.fc1(out)
return out
model = model_rnn()
print(model)

四 定义训练函数
# 2.定义训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss五 定义测试函数
def t(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss六 训练
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.Adam(model.parameters(),lr=learn_rate)
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = t(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss))
print('Done')Epoch: 1, Train_acc:46.7%, Train_loss:0.698, Test_acc:54.8%,Test_loss:0.689 Epoch: 2, Train_acc:59.6%, Train_loss:0.682, Test_acc:58.1%,Test_loss:0.682 Epoch: 3, Train_acc:71.3%, Train_loss:0.666, Test_acc:58.1%,Test_loss:0.676 Epoch: 4, Train_acc:77.2%, Train_loss:0.652, Test_acc:54.8%,Test_loss:0.670 Epoch: 5, Train_acc:81.6%, Train_loss:0.637, Test_acc:54.8%,Test_loss:0.665 Epoch: 6, Train_acc:82.4%, Train_loss:0.623, Test_acc:58.1%,Test_loss:0.659 Epoch: 7, Train_acc:80.9%, Train_loss:0.609, Test_acc:58.1%,Test_loss:0.654 Epoch: 8, Train_acc:81.2%, Train_loss:0.594, Test_acc:58.1%,Test_loss:0.649 Epoch: 9, Train_acc:81.6%, Train_loss:0.580, Test_acc:58.1%,Test_loss:0.644 Epoch:10, Train_acc:81.6%, Train_loss:0.565, Test_acc:58.1%,Test_loss:0.639 Epoch:11, Train_acc:82.0%, Train_loss:0.550, Test_acc:58.1%,Test_loss:0.634 Epoch:12, Train_acc:82.0%, Train_loss:0.535, Test_acc:58.1%,Test_loss:0.630 Epoch:13, Train_acc:82.0%, Train_loss:0.520, Test_acc:58.1%,Test_loss:0.625 Epoch:14, Train_acc:82.0%, Train_loss:0.504, Test_acc:58.1%,Test_loss:0.621 Epoch:15, Train_acc:82.0%, Train_loss:0.488, Test_acc:58.1%,Test_loss:0.617 Epoch:16, Train_acc:82.4%, Train_loss:0.473, Test_acc:58.1%,Test_loss:0.614 Epoch:17, Train_acc:83.1%, Train_loss:0.457, Test_acc:61.3%,Test_loss:0.611 Epoch:18, Train_acc:83.1%, Train_loss:0.442, Test_acc:61.3%,Test_loss:0.608 Epoch:19, Train_acc:83.8%, Train_loss:0.427, Test_acc:64.5%,Test_loss:0.605 Epoch:20, Train_acc:85.7%, Train_loss:0.412, Test_acc:61.3%,Test_loss:0.603 Epoch:21, Train_acc:86.4%, Train_loss:0.398, Test_acc:64.5%,Test_loss:0.601 Epoch:22, Train_acc:87.1%, Train_loss:0.383, Test_acc:64.5%,Test_loss:0.600 Epoch:23, Train_acc:87.9%, Train_loss:0.370, Test_acc:64.5%,Test_loss:0.600 Epoch:24, Train_acc:88.2%, Train_loss:0.357, Test_acc:67.7%,Test_loss:0.601 Epoch:25, Train_acc:88.2%, Train_loss:0.344, Test_acc:71.0%,Test_loss:0.602 Epoch:26, Train_acc:88.6%, Train_loss:0.332, Test_acc:71.0%,Test_loss:0.605 Epoch:27, Train_acc:89.3%, Train_loss:0.321, Test_acc:71.0%,Test_loss:0.609 Epoch:28, Train_acc:89.3%, Train_loss:0.310, Test_acc:67.7%,Test_loss:0.614 Epoch:29, Train_acc:89.3%, Train_loss:0.300, Test_acc:67.7%,Test_loss:0.620 Epoch:30, Train_acc:90.1%, Train_loss:0.290, Test_acc:67.7%,Test_loss:0.627 Epoch:31, Train_acc:90.1%, Train_loss:0.281, Test_acc:71.0%,Test_loss:0.635 Epoch:32, Train_acc:90.8%, Train_loss:0.272, Test_acc:71.0%,Test_loss:0.644 Epoch:33, Train_acc:90.8%, Train_loss:0.264, Test_acc:67.7%,Test_loss:0.654 Epoch:34, Train_acc:90.8%, Train_loss:0.257, Test_acc:64.5%,Test_loss:0.663 Epoch:35, Train_acc:90.8%, Train_loss:0.249, Test_acc:64.5%,Test_loss:0.673 Epoch:36, Train_acc:90.8%, Train_loss:0.243, Test_acc:64.5%,Test_loss:0.683 Epoch:37, Train_acc:91.9%, Train_loss:0.236, Test_acc:64.5%,Test_loss:0.693 Epoch:38, Train_acc:92.3%, Train_loss:0.230, Test_acc:64.5%,Test_loss:0.703 Epoch:39, Train_acc:92.3%, Train_loss:0.224, Test_acc:64.5%,Test_loss:0.714 Epoch:40, Train_acc:92.3%, Train_loss:0.218, Test_acc:64.5%,Test_loss:0.724 Epoch:41, Train_acc:92.3%, Train_loss:0.213, Test_acc:61.3%,Test_loss:0.736 Epoch:42, Train_acc:92.3%, Train_loss:0.207, Test_acc:61.3%,Test_loss:0.748 Epoch:43, Train_acc:93.4%, Train_loss:0.202, Test_acc:58.1%,Test_loss:0.760 Epoch:44, Train_acc:93.8%, Train_loss:0.197, Test_acc:58.1%,Test_loss:0.772 Epoch:45, Train_acc:93.8%, Train_loss:0.192, Test_acc:58.1%,Test_loss:0.784 Epoch:46, Train_acc:94.5%, Train_loss:0.187, Test_acc:58.1%,Test_loss:0.798 Epoch:47, Train_acc:94.9%, Train_loss:0.182, Test_acc:58.1%,Test_loss:0.812 Epoch:48, Train_acc:94.9%, Train_loss:0.177, Test_acc:58.1%,Test_loss:0.826 Epoch:49, Train_acc:95.2%, Train_loss:0.172, Test_acc:54.8%,Test_loss:0.842 Epoch:50, Train_acc:95.2%, Train_loss:0.167, Test_acc:54.8%,Test_loss:0.858 Done
七 结果可视化
1.准确率和损失值
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()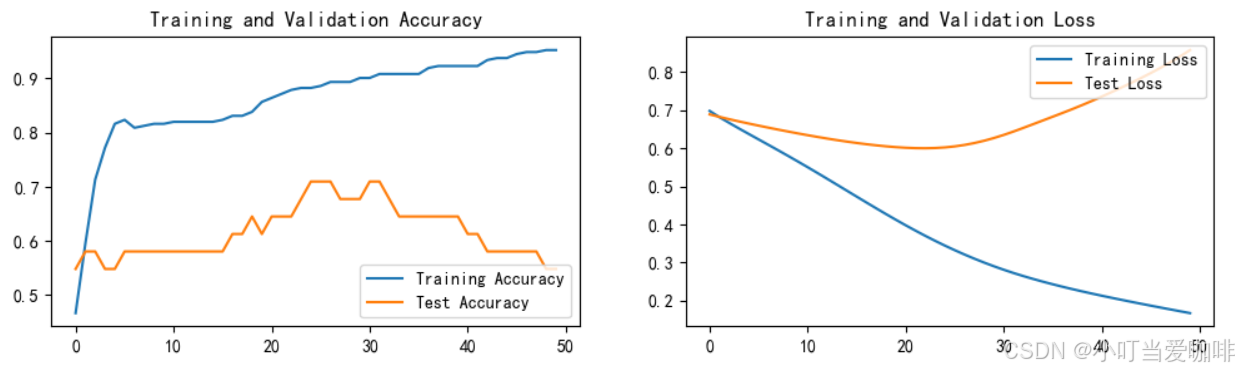
2.混淆矩阵
'''
绘制混淆矩阵
'''
print('=============输入数据shape为==============')
print('X_test.shape:',X_test.shape)
print('y_test.shape:',y_test.shape)
pred = model(X_test.to(device)).argmax(1).cpu().numpy()
print('\n==========输出数据shape为==============')
print('pred.shape:',pred.shape)
from sklearn.metrics import confusion_matrix,ConfusionMatrixDisplay
# 计算混淆矩阵
cm = confusion_matrix(y_test,pred)
plt.figure(figsize=(6,5))
plt.suptitle('')
sns.heatmap(cm,annot=True,fmt='d',cmap='Blues')
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
plt.title('Confusion Matrix',fontsize=12)
plt.xlabel('Pred Label',fontsize=10)
plt.ylabel('True Label',fontsize=10)
plt.tight_layout()
plt.show()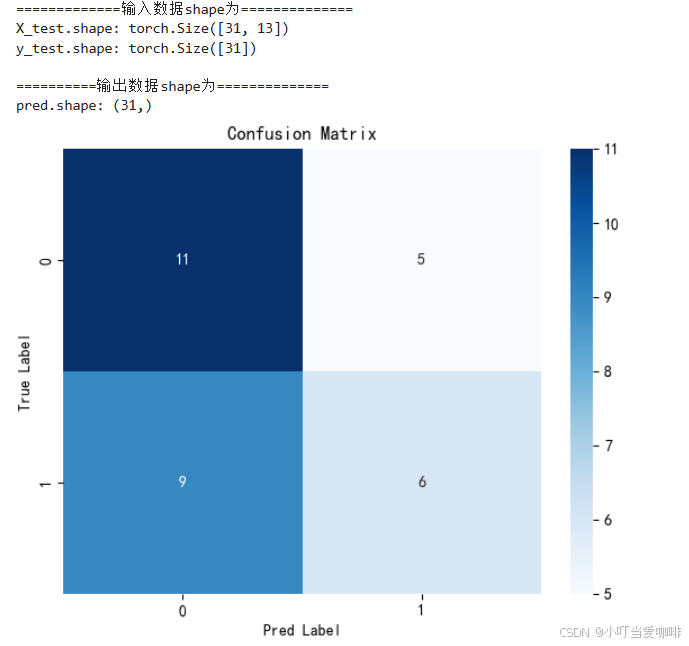
八 使用模型进行预测
'''
使用模型进行预测
'''
test_X = X_test[0].reshape(1,-1)
pred = model(test_X.to(device)).argmax(1).item()
print('模型预测结果为:',pred)
print('=='*20)
print('0:不会患心脏病')
print('1:可能患心脏病')模型预测结果为: 0 ======================================== 0:不会患心脏病 1:可能患心脏病