企业面试真题----阿里巴巴
1.HashMap为什么不是线程安全的?
首先hashmap就是为单线程设计的,并不适合于多线程环境,而hashmap的线程不安全原因主主要是以下两个原因:
死循环
死循环问题发生在jdk1.8之前(不包含1.8),造成死循环的原因要满足三个条件:添加操作是头插法,触发扩容操作,多线程并发执行时才可能会触发死循环问题。但是在1.8之后就修复了这个死循环问题(将头插法改成尾插法)。
数据覆盖
数据覆盖也很好理解,就是在hashmap中添加操作不是一个原子性操作。例如,有两个线程a,b,线程a根据key的hashcod()方法按位与再右移16位得到一个哈希槽的位置,此时判断到该哈希槽没有元素,可以将值插入,但此时线程a的时间片用完了,此时线程b做了同样的判断操作,发现该位置没有元素,就将其值插入,此时cpu调度的时间片又回到了线程a,但线程a不会再进行判断操作,而是直接插入,此时就将线程b的值给覆盖住了。这就是数据覆盖问题,在以后的jdk版本中数据覆盖问题也是没有解决的
2.进程间是如何进行通讯的?
首先这是一个操作系统的问题,问的是进程之间的通讯方式。而进程之间的通讯方式有管道通讯,消息队列通讯,共享内存通讯,信号量通讯等
管道:他是一种半双工的通讯方式,数据流之间只能进行单向通信,比较适合于一些具有父子进程的通讯方式,它在内核中开辟一块缓冲区,一个进程向缓冲区写入数据,另一个进程从缓冲区读取数据。比如,在 Linux 系统中,通过pipe系统调用可以创建一个管道,会返回两个文件描述符,一个用于读,一个用于写。
消息队列:消息队列是由消息的链表组成,存放在内核中,并由消息队列标识符标识。进程可以向消息队列中添加消息(发送消息),也可以从消息队列中读取消息(接收消息)。消息队列克服了信号承载信息量少、管道只能承载无格式字节流以及缓冲区大小受限等缺点,能传递有格式的数据块。
共享内存:共享内存是最快的一种进程间通信方式,它允许多个进程共享同一块物理内存空间。不同进程可以将这块共享内存映射到自己的虚拟地址空间中,对这块内存进行读写操作就可以实现数据的交换和共享,不过通常需要配合信号量等同步机制来防止出现数据不一致等并发问题。
信号量:信号量本质上是一个计数器,主要用于多个进程间的同步,协调它们对共享资源的访问。它可以控制多个进程对共享资源的并发访问数量,避免出现多个进程同时操作同一资源导致的数据不一致等问题。例如,初始化信号量的值为 1,意味着同一时刻只允许一个进程访问对应的共享资源,当一个进程获取到信号量(进行 P 操作,使信号量的值减 1)后,其他进程需要等待该进程释放信号量(进行 V 操作,使信号量的值加 1)才能访问。
补充:其实一般问的比较多的是线程间的通信,在java中线程间的通信主要有以下几种:
Object -> wait/notify/notifyAll
Condition -> await/signal/signalAll
LockSupport -> park/unpark
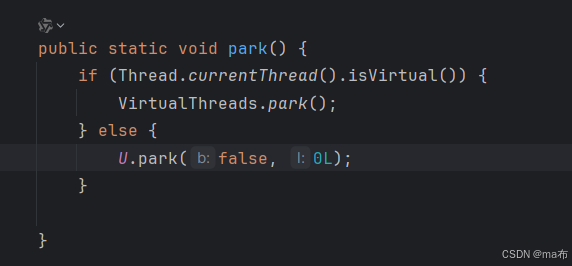
上面三个主要的区别就是:Object 底下的方法是随机唤醒线程,Condition 底下的方法是可以以线程组的方式唤醒,而LockSupport底下的是可以唤醒指定的线程。
3.线程池的核心线程与非核心线程有什么区别?
首先线程池的主要作用就是线程的复用和节省频繁创建线程时带来的性能开销。在线程池中有七大参数:核心线程数,最大线程数,临时线程数,临时线程的存活时间,任务队列,线程工厂,拒绝策略。其中的临时线程就是非核心线程。
主要区别:
**1.创建的时间不同:**核心线程是在当有任务来的时候就会创建核心线程,而临时线程是当任务队列满了以后,但还未到达最大线程时会创建临时线程。
2.生命周期不同:核心线程是创建后不会被销毁的,除非发生异常情况。而临时线程在空闲状态(即没有任务可执行)持续一定时间(这个时间由keepAliveTime参数指定)后,线程池会尝试回收这些临时线程,将其销毁,释放系统资源。
4.MVCC是如何实现的?
MVCC主要是由Undo log版本链 + Read View这两部分来实现的。
Undo log版本链:
它是由一条条的 Undo log 记录串联起来形成的一个类似链表的结构,用于记录数据在不同事务操作阶段下的历史版本信息。而Undo log 是数据库的一种回滚日志,用于记录数据的更新操作之前的数据,防止在事务失败或者异常后进行回滚的。
Read View:它是数据库在某个特定时刻为一个正在执行的事务生成的一个视图,用于决定该事务能看到哪些版本的数据,也就是基于这个视图去从众多数据的历史版本(由 Undo log 版本链所记录的数据不同时刻的版本)中筛选出符合要求的版本来供事务读取。读视图主要由四部分组成:当前正在活跃的事务ID集合,最小的事务ID,最大的事务ID,当前事务ID四部分。
当前正在活跃的事务:这部分包含了在生成 Read View 时刻,系统中所有正在执行但尚未提交的事务的 ID。
最小的事务:它代表了系统中当前已创建的事务里最小的事务 ID。一般来说,小于这个最小事务 ID 的数据版本对应的事务已经完成且提交了,是相对比较 “陈旧” 且稳定的版本,更有可能对当前读取事务可见。
最大的事务:最大事务 ID 用于界定数据版本是否是在 Read View 生成之后才出现的情况。如果一个数据版本对应的事务 ID 大于这个最大事务 ID,那就意味着这个版本是在当前 Read View 生成之后才被创建的,对于正在基于该 Read View 进行读取的事务来说必然是不可见的
Read View的判断规则如下:
1.首先从undo log链中获取当前数据行的事务id与当前事务id进行对比,如果相等就直接返回数据,如果没有则进行下一步。
2.如果当前最新数据行的事务id < 最小事务id,说明在查询前,其他数据的事务已经提交了是可见的,因此直接返回数据即可,若不满足就进行下一步。
3.如果当前最新数据行的事务id > 最大事务id,说明正在执行的事务还没有提交是不可见的。
4.如果当前最新数据行的事务id 位于最大事务和最小事务之间又分为两种情况:
如果当前最新数据行的事务id在活跃事务列表之中,说明事务还没有提交,数据不可见
如果当前最新数据行的事务id不在活跃事务列表之中,说明事务已经执行完,数据可见
以上就是Read View的判断规则
5.TCP的拥塞控制是什么?
TCP有八大特性:确认应答,连接管理,超时重传,流量控制,滑动窗口,拥塞控制,延迟应答,捎带应答
那么拥塞控制什么???
在网络中,如果数据量过多可能会造成网络拥塞,TCP 有一套算法来监测和应对这种情况。例如,通过慢启动、拥塞避免、快重传、快恢复等算法来动态调整发送窗口大小,控制发送数据的速率,以缓解网络拥塞状况,防止网络性能急剧下降。
拥塞控制是针对于数据流的发送方的,当出现网络抖动和其他原因时,调整数据发送方的数据包大小,便于缓解网络情况。
6.TCP与UDP有什么区别?
主要区别:
1.tcp是面向有连接的,而udp是面向无连接的。这里说的连接指的是在数据传输之前要进行双方的确认,tcp有三次握手机制来确定对方是在线的是可以接收数据的。而udp在数据传输之前是不需要确定对方在不在的,容易出现数据丢失问题。
2.tcp的可靠性更高,因为基于tcp的八大特性,他的数据传输是比较可靠的,但udp是没有这些特性的,但是udp得传输速度是很快的。
3.二者的应用场景也是不同的:
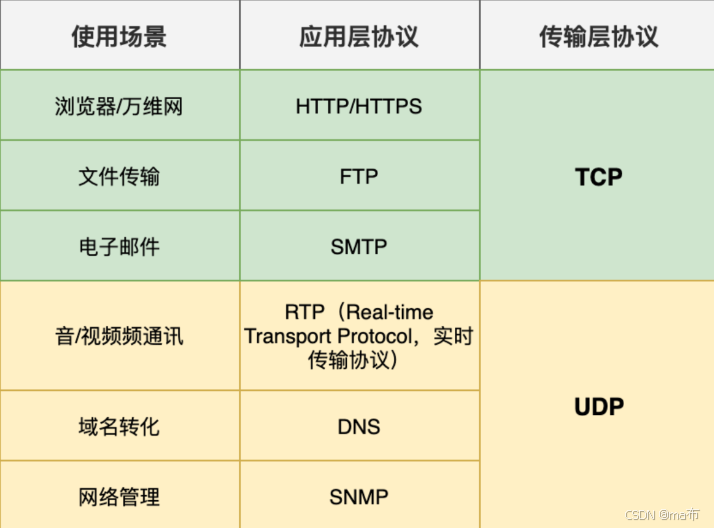
7.TCP的流量控制?
TCP 通过滑动窗口机制来实现流量控制,接收方会根据自己的接收能力告知发送方自己的接收窗口大小,发送方会根据这个窗口大小来控制发送的数据量,避免发送过多的数据导致接收方处理不过来而出现数据丢失等问题。
tcp的流量控制是针对于数据接收方的,不要将这个与拥塞控制搞混!!!
8.JDK Proxy和CG lib有什么区别?
JDK Proxy和CG lib主要是动态代理实现的两种方式,但主要区别有以下几点:
1.来源不同:JDK Proxy是Java自带的动态代理,只能代理实现了接口的代理类,而CG lib是一个第三方库,他无需被代理对象是不是接口,但是被代理类不能是final修饰。
2.原理不同:JDK Proxy底层是依赖于java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来实现。Proxy类是创建代理对象的关键类,而InvocationHandler接口则定义了代理对象在调用方法时的具体行为逻辑。是基于反射来实现的。而CG lib的底层是生成被代理类的子类来实现的。
9.BeanFactory和FactoryBean有什么区别?
BeanFactory是 Spring 框架的核心接口之一,它是 Spring 容器的顶层抽象,负责管理和维护 Spring 中的 Bean(也就是 Java 对象)。它提供了一种高级的配置机制以及对 Bean 实例化、配置和管理的功能,简单来说,就是它掌控着 Spring 应用中各个对象的创建、装配以及生命周期等诸多事宜。BeanFactory采用的是延迟初始化策略,也就是只有在真正需要使用某个 Bean 的时候,才会去实例化它。
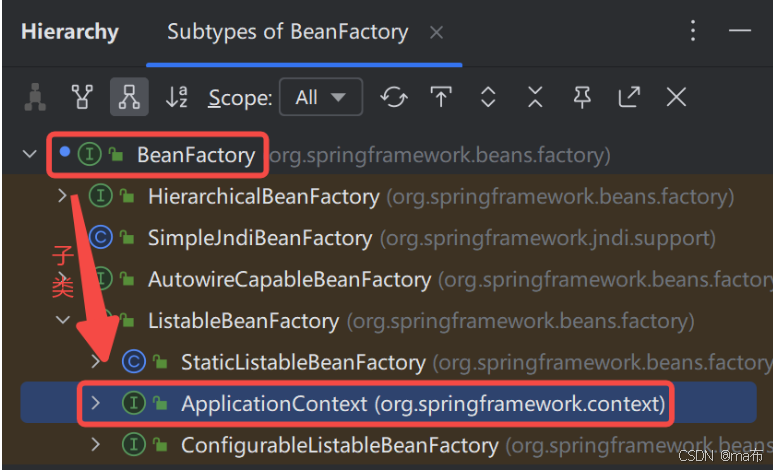
XmlBeanFactory:这是早期 Spring 版本中常用的基于 XML 配置文件的BeanFactory实现类,不过后来逐渐被功能更强大的ApplicationContext相关实现类替代,但在一些简单场景或者学习了解BeanFactory基本原理时还是会涉及到它。ApplicationContext:它是BeanFactory的子接口,功能更加强大,不仅具备BeanFactory的基本功能,还额外提供了如国际化支持、事件发布与订阅、资源加载等更多高级功能,是实际开发中使用更为广泛的 Spring 容器实现形式。
FactoryBean是一个接口,它本身也是一种特殊的 Bean,其设计目的在于让开发者能够自定义 Bean 的创建逻辑。通过实现这个接口,开发者可以控制某个具体 Bean 的实例化过程,不仅仅局限于常规的通过构造函数或者简单的配置属性来创建 Bean,而是可以按照自己期望的复杂方式去生成 Bean 实例。
- 类型转换与隐藏实现细节:
FactoryBean返回的对象类型不一定就是其自身实现类的类型,它通过getObjectType方法明确返回实际创建的 Bean 对象的类型,这样在 Spring 容器中获取该 Bean 时,得到的就是getObject方法中返回的那个对象,能够方便地进行类型转换等操作,同时隐藏了复杂的创建过程细节,外部使用者只关心最终获取到的可用 Bean 实例就好。 - 控制单例与否:通过
isSingleton方法可以指定创建出来的 Bean 是否是单例的。如果返回true,那么 Spring 容器在整个生命周期内只会创建一个该 Bean 的实例,后续获取都是同一个;如果返回false,则每次获取时都会重新创建一个新的 Bean 实例。 - 与 BeanFactory 的关系:
FactoryBean是在BeanFactory管理 Bean 的大框架下发挥作用的,它为BeanFactory提供了一种更灵活的 Bean 创建方式,让 Spring 容器能够处理那些需要特殊创建逻辑的 Bean 情况,丰富了 Spring 容器创建和管理 Bean 的手段。
10.Bean的创建流程?
Bean的创建流程主要是以下几步:实例化,属性赋值,初始化(初始化前置处理,初始化方法调用,初始化后置调用)使用,销毁
实例化:主要就是给Bean分配内存空间,调用Bean的构造方法
属性赋值:在创建实例后,通过依赖注入给Bean的属性赋值
初始化:
初始化前置处理:会调用所有实现了BeanPostProcessor接口的类的postProcessorBeforeInitialization方法
初始化方法调用:通过注解或实现InitializingBean接口
初始化后置调用: 会调用所有实现了BeanPostProcessor接口的类的postProcessorAfterInitialization方法
使用:在经历过以上三步完成后,就可以执行bean的业务逻辑了
销毁:关闭容器就会销毁Bean
11.JVM的区域划分?
JVM是由类加载器,执行引擎,本地方法库,运行时数据区域构成的。而运行时数据区域又是由:虚拟机栈,本地方法栈,堆,程序计数器,方法区构成
虚拟机栈:用于存储方法调用和局部变量,操作数栈,方法的返回地址等
本地方法栈:JVM主要由c++完成,本地方法栈存放的就是c++的一些函数库
堆:主要存放对象的实例,是运行时数据区域最大的一块内存,几乎所有的对象都在堆上分配内存
程序计数器:主要记录程序到了哪一步,主要存储当前程序字节码指令的地址
方法区:用于存放类的结构信息,例如,类的结构,字段,方法,静态变量等。
12.堆的组成?
堆是运行时数据区域最大的一块内存区域:
年轻代:年轻代是堆内存中用来存放新创建对象的区域,大部分新创建的对象都会首先在这里进行分配内存。它被设计为可以快速进行垃圾回收的结构,因为在这个区域中对象的生命周期通常较短,很多对象很快就会变成垃圾(也就是不再被使用的对象),需要被回收释放内存空间。年轻代又被细分为以下两个区域:
- Eden 区:这是年轻代中最大的一个区域,新创建的对象通常首先会被分配到 Eden 区的内存空间中。例如,当我们在 Java 代码中通过
new关键字创建一个新的对象时,只要 Eden 区还有足够的空闲内存,这个对象就会在这里分配内存,像Object obj = new Object();这样简单的对象创建操作,对象大概率就初始分配在 Eden 区。 - Survivor 区:Survivor 区又分为
Survivor0(也常称作from区)和Survivor1(也常称作to区),它们的大小一般是相同的,两个区主要用于在垃圾回收过程中存放那些经过一次垃圾回收后仍然存活的对象。当 Eden 区进行垃圾回收(在年轻代中这种垃圾回收称作 Minor GC)后,存活下来的对象会被转移到其中一个 Survivor 区(比如Survivor0),下一次 Minor GC 时,Eden 区和当前使用的 Survivor 区(Survivor0)中存活的对象会被一起转移到另一个 Survivor 区(Survivor1),如此反复,对象会在两个 Survivor 区之间来回复制转移,并且每经过一次这样的转移,对象的年龄(通过对象头中的一个字段来记录)就会加 1,直到对象的年龄达到一定阈值(可以通过 JVM 参数进行配置,默认是 15),这些对象就会被晋升(Promotion)到年老代中。
老年代:年老代主要用于存放那些经过多次垃圾回收后仍然存活的对象,也就是生命周期相对较长的对象。
在 Java 8 之前,永久代是堆内存中的一部分,它主要用于存放类的相关信息,比如类的字节码、常量池、静态变量、方法等信息。
年龄达到一定阈值(可以通过 JVM 参数进行配置,默认是 15),这些对象就会被晋升(Promotion)到年老代中。
老年代:年老代主要用于存放那些经过多次垃圾回收后仍然存活的对象,也就是生命周期相对较长的对象。
在 Java 8 之前,永久代是堆内存中的一部分,它主要用于存放类的相关信息,比如类的字节码、常量池、静态变量、方法等信息。
元空间:Java 8 将永久代废弃,取而代之的是元空间。元空间并不在堆内存之中,而是使用本地内存(Native Memory)来存放类的元数据等信息。这样做的好处是,它的内存大小不再受限于 JVM 堆内存的设置,可以根据实际应用的需要动态地使用本地内存,在一定程度上缓解了原来永久代容易出现内存溢出的问题,并且提高了类加载等相关操作的灵活性。