目录
概念
正则表达式 - 正则表达式用来定义一个规则 - 通过这个规则计算机可以检查一个字符串是否符合规则 或者将字符串中符合规则的内容提取出来 - 正则表达式也是JS中的一个对象, 所以要使用正则表达式,需要先创建正则表达式的对象
如何创建一个正则表达式
可以使用以下两种方法构建一个正则表达式:
1.使用一个正则表达式字面量,其由包含在斜杠之间的模式组成,如下所示:
// 使用字面量来创建正则表达式:/正则/匹配模式
reg = /a/i
2.调用RegExp对象的构造函数
new RegExp() 可以接收两个参数(字符串) 1.正则表达式,即检查的规则标准 2.匹配模式,如下所示:
let reg = new RegExp("a", "i") // 通过构造函数来创建一个正则表达式的对象
编写一个正则表达式的模式(规则)
一个正则表达式模式是由简单的字符所构成的,比如 /abc/;或者是简单和特殊字符的组合,比如 /abc/ 或 /Chapter (\d+).\d/。最后的例子中用到了括号,它在正则表达式中常用作记忆设备,可以用来拆分获取到的字符串。即这部分所匹配的字符将会被记住以备后续使用
使用简单模式
简单模式是由你想直接找到的字符构成。
比如,/abc/ 这个模式就能且仅能匹配 "abc" 字符按照顺序同时出现的情况。
使用特殊字符
当你需要匹配一个不确定的字符串时,比如寻找一个或多个 "b",或者寻找空格,可以在模式中使用特殊字符。
比如,你可以使用 /ab*c/ 去匹配一个单独的 "a" 后面跟了零个或者多个 "b",同时后面跟着 "c" 的字符串:*的意思是前一项出现零次或者多次。在字符串 "cbbabbbbcdebc" 中,这个模式匹配了子字符串 "abbbbc"。
特殊字符的完整列表和描述
| 字符 | 描述 | 实例 |
|---|---|---|
| | | 在正则表达式中表示或 | |
| [] | 表示或(字符集) | [a-z] 任意的小写字母 [A-Z] 任意的大写字母 [a-zA-Z] 任意的字母 [0-9]任意数字 |
| [^] | 表示除了 | [^x] 除了x |
| . | 表示除了换行外的任意字符 | |
| |转义字符 | ||
| \w | 任意的单词字符 [A-Za-z0-9_] | |
| \W | 除了单词字符 [^A-Za-z0-9_] | |
| \d | 任意数字 [0-9] | |
| \D | 除了数字 [^0-9] | |
| \s | 空格 | |
| \S | 除了空格 | |
| \b | 单词边界 | |
| \B | 除了单词边界 | |
| ^ | 表示字符串的开头 | |
| $ | 表示字符串的结尾 |
量词
| 量词 | 描述 |
|---|---|
| {m} | 正好m个 |
| {m,} | 至少m个 |
| {m,n} | m-n个 |
| + | 匹配前面一个表达式 1 次或者多次。等价于 {1,} |
| * | 任意数量的a |
| ? | 0-1次 {0,1} |
通过标志进行高级搜索
正则表达式有六个可选参数 (flags) 允许全局和不分大小写搜索等。这些参数既可以单独使用也能以任意顺序一起使用,并且被包含在正则表达式实例中。语法:
let re = /pattern/flags;
亦或者:
let re = new RegExp("pattern", "flags");
| 标志(flags) | 搜索 |
|---|---|
| g | 全局搜索 |
| i | 不区分大小写搜索。 |
| m | 多行搜索。 |
| s | 允许 . 匹配换行符。 |
| u | 使用 unicode 码的模式进行匹配。 |
| y | 执行“粘性 (sticky)”搜索,匹配从目标字符串的当前位置开始。 |
使用正则表达式
正则表达式可以被用于 RegExp 的 exec 和 test 方法以及 String 的 match、replace、search 和 split 方法。
使用test()检查字符串是否符合我们的正则表达式;使用exec()获取字符串中符合正则表达式的内容;
| 方法 | 描述 |
|---|---|
| exec | 一个在字符串中执行查找匹配的 RegExp 方法,它返回一个数组(未匹配到则返回 null)。 |
| test | 一个在字符串中测试是否匹配的 RegExp 方法,它返回 true 或 false。 |
| match | 一个在字符串中执行查找匹配的 String 方法,它返回一个数组,在未匹配到时会返回 null。 |
| matchAll | 一个在字符串中执行查找所有匹配的 String 方法,它返回一个迭代器(iterator)。 |
| search | 一个在字符串中测试匹配的 String 方法,它返回匹配到的位置索引,或者在失败时返回 -1。 |
| replace | 一个在字符串中执行查找匹配的 String 方法,并且使用替换字符串替换掉匹配到的子字符串。 |
| split | 一个使用正则表达式或者一个固定字符串分隔一个字符串,并将分隔后的子字符串存储到数组中的 String 方法。 |
<script>
let str = "abcaecafcacc"
// 提取出str中符合axc格式的内容
// g表示全局匹配
let re = /a(([a-z])c)/ig
let result = re.exec(str)
console.log(result)//['abc', 'bc', 'b', index: 0, input: 'abcaecafcacc', groups: undefined]
//循环遍历数组
while(result){
console.log(result[0], result[1], result[2])
result = re.exec(str)
}
//abc bc b
// aec ec e
//afc fc f
//acc cc c
</script>
示例
提取手机号
从一串字母(dajsdh13715678903jasdlakdkjg13457890657djashdjka13811678908sdadadasd)中提取出来11位手机号显示出来
分析:
我们根据题目要求用自己的语言来描述出来所需规则:电话号是11位,普通电话号码第一位只能是1,第二位不能是1、2所以是3~9,后面9位没有限制:
1 3 501789087
1 3~9 任意九个数字
所以正则表达式可以设置为如下表达式,然后根据exec()来提取出来
/1[3-9]\d{9}/g
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<script>
let re = /1[3-9]\d{9}/g
let str =
"dajsdh13715678903jasdlakdkjg13457890657djashdjka13811678908sdadadasd"
let result
while (result = re.exec(str)) {
console.log(result[0])
}
</script>
</head>
<body></body>
</html>
结果:

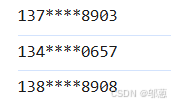
隐秘手机号
将上题提取出来的手机号隐去中间四位显示出来
我们可以在提取手机号的代码中对正则表达式加以改进,使其能够进行分片,应使用括号如:
/(1[3-9]\d)\d{4}(\d{4})/g随后我们可以数组索引和连接符来显示:
console.log(result[1]+"****"+result[2])1
完整代码:
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<script>
let re = /(1[3-9]\d)\d{4}(\d{4})/g
let str =
"dajsdh13715678903jasdlakdkjg13457890657djashdjka13811678908sdadadasd"
let result
while (result = re.exec(str)) {
console.log(result[1]+"****"+result[2])
}
</script>
</head>
<body></body>
</html>
结果:
测试是否符合手机号规则
re = /^1[3-9]\d{9}$/
console.log(re.test("13456789042"))//ture