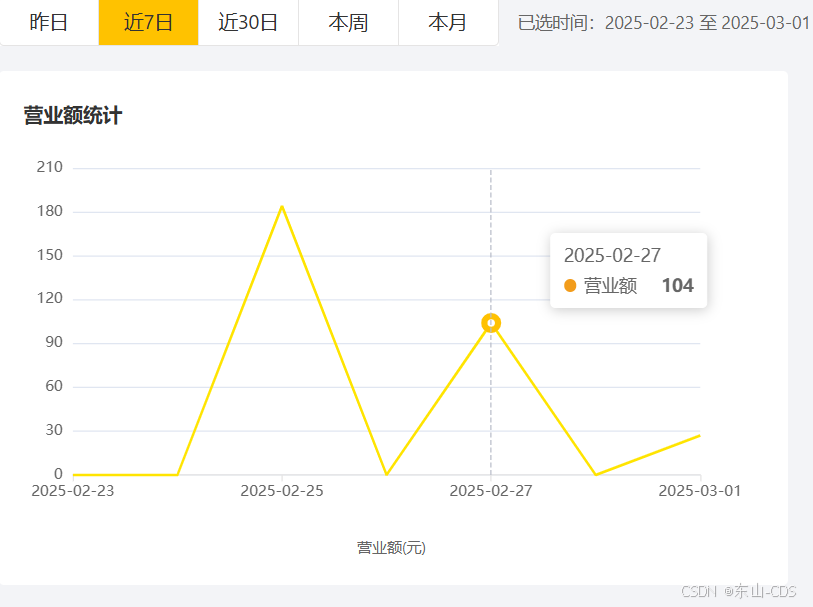
一、业务场景简介
1.场景引入
在开发业务统计模块时我们常用到Apache ECharts进行报表展示,这种场景往往需要多维的数据集,我们代入具体的业务场景:以一家餐厅的日营业额动态折线统计报表为例,商家存有一张订单表,订单表具体属性如下
create table orders
(
id bigint auto_increment comment '主键'
primary key,
number varchar(50) null comment '订单号',
status int default 1 not null comment '订单状态 1待付款 2待接单 3已接单 4派送中 5已完成 6已取消 7退款',
user_id bigint not null comment '下单用户',
address_book_id bigint not null comment '地址id',
order_time datetime not null comment '下单时间',
checkout_time datetime null comment '结账时间',
pay_method int default 1 not null comment '支付方式 1微信,2支付宝',
pay_status tinyint default 0 not null comment '支付状态 0未支付 1已支付 2退款',
amount decimal(10, 2) not null comment '实收金额',
remark varchar(100) null comment '备注',
phone varchar(11) null comment '手机号',
address varchar(255) null comment '地址',
user_name varchar(32) null comment '用户名称',
consignee varchar(32) null comment '收货人',
cancel_reason varchar(255) null comment '订单取消原因',
rejection_reason varchar(255) null comment '订单拒绝原因',
cancel_time datetime null comment '订单取消时间',
estimated_delivery_time datetime null comment '预计送达时间',
delivery_status tinyint(1) default 1 not null comment '配送状态 1立即送出 0选择具体时间',
delivery_time datetime null comment '送达时间',
pack_amount int null comment '打包费',
tableware_number int null comment '餐具数量',
tableware_status tinyint(1) default 1 not null comment '餐具数量状态 1按餐量提供 0选择具体数量'
)
comment '订单表' collate = utf8mb3_bin;2.需求分析(已知商家会不定期停店休息,且只有已完成状态的订单计入营业额)
2.1初步分析
绘制日营业额折线统计图需要向前端返回横坐标日期数据集,纵坐标营业额数据集:
- 对于日期,前端先传给我们起始和终止日期(考虑到当前工作日未结束,终止日期精确到上一个工作日 yyyy-MM-dd),所以这部分可以直接采用循环在逻辑层生成连续的日期数据集;
List<LocalDate> dateList=new ArrayList<>();
dateList.add(begin);
while (!begin.equals(end)){
begin=begin.plusDays(1);
dateList.add(begin);
}- 对于营业额数据集则需要我们进行查表,很容易根据条件得到单日的营业额数据查询语句
#查询三月一日的营业额(这里时间并不准确,用作分析演示)
select
order_time,
SUM(amount) AS daily_revenue
from orders
where status=5 and order_time between '2025-03-01' and '2025-03-01 23:59:59'
group by order_time2.2问题发现
- 首先前端给我们的数据格式为yyyy-MM-dd的日期对象,并未不够精确,且sql所需参数为字符串;
- 其次作为Echart的横纵坐标数据集需要一一对应,但不定期调休即当日无单这一情况查询结果为空,可能会造成营业额字段缺失,横纵数据集不对应的情况。
二、问题初步解决(这部分太低效仅用作展示,可直接跳过)
1.精确时间并格式转换
LocalDateTime bt = LocalDateTime.of(begin, LocalTime.MIN);//'00:00'
LocalDateTime et = LocalDateTime.of(end, LocalTime.MAX);//'23:59:59.999999999'.
//转为字符串
String start = bt.toString();
String stop = et.toString();
2.将营业额查询结果与时间一一对应,且为null的转为0
select
SUM(amount) AS daily_revenue
from orders
where status=5 and order_time between #{begin} and #{end}
group by order_timepublic TurnoverReportVO getTurnOverStatistics(LocalDate begin, LocalDate end) {
List<LocalDate> dateList=new ArrayList<>();
dateList.add(begin);
while (!begin.equals(end)){
begin=begin.plusDays(1);
dateList.add(begin);
}
List<BigDecimal> revenue=new ArrayList<>();
for (LocalDate date : dateList) {
LocalDateTime bt = LocalDateTime.of(date, LocalTime.MIN);//'00:00'
LocalDateTime et = LocalDateTime.of(date,LocalTime.MAX);//'23:59:59.999999999'.
Integer completed = Orders.COMPLETED;//此处常量即status完成状态
BigDecimal reve=orderMapper.getDailyRevenue(bt,et,completed);
//结果为null转为0
reve=reve==null? BigDecimal.valueOf(0) :reve;
revenue.add(reve);
}
// 返回数据集
return TurnoverReportVO.builder()
.dateList(StringUtils.join(dateList,","))
.turnoverList(StringUtils.join(revenue,","))
.build();
}这样的方式虽然初步解决了需求,但是代码比较臃肿,不宜维护,并且将查询放入循环,多次调用Mapper接口操作数据库会降低效率,一般建议将查询操作一次性结束。
三、SQL调优
接下来我将直接介绍两种日期序列生成的优化方式 ,各有优劣,后文我将详细介绍。
1.方法一
注意:此处为更好演示参数为直接填入,应用时应将其改为对应参数名
SELECT
d.date AS order_date,
COALESCE(SUM(o.amount), 0) AS daily_revenue
FROM (
SELECT CURDATE() - INTERVAL (a.a + (10 * b.a) + (100 * c.a)) DAY as date
FROM (SELECT 0 as a UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) as a
CROSS JOIN (SELECT 0 as a UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) as b
CROSS JOIN (SELECT 0 as a UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) as c
) d
LEFT JOIN orders o ON DATE(o.order_time) = d.date and o.status=5
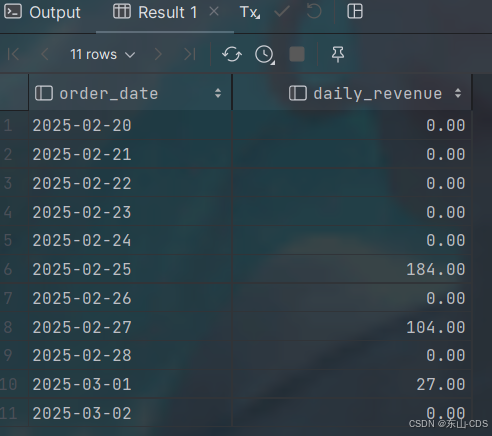
WHERE d.date BETWEEN '2025-02-20' AND '2025-03-02'
GROUP BY d.date
ORDER BY d.date;查询结果为
1.1段落解析
-
SELECT 0 as a:生成一个包含单个数字0的临时表; -
UNION ALL SELECT 1:将1添加到结果中,以此类推,最终生成一个包含0到9的数字表;a --- 0 1 2 3 4 5 6 7 8 9 -
CROSS JOIN:笛卡尔积操作,将两个表中的每一行进行组合; -
通过三个表的笛卡尔积(
a,b,c),我们可以生成10 * 10 * 10 = 1000个组合。a.a | b.a | c.a ----|-----|----- 0 | 0 | 0 0 | 0 | 1 ... 9 | 9 | 9 -
COALESCE(..., 0):如果某一天没有订单,SUM(o.amount)会返回NULL,COALESCE函数将其转换为0。 -
CURDATE():返回当前日期(如2025-03-02); -
INTERVAL 321 DAY:向前推321天; -
CURDATE() - INTERVAL ... DAY:从当前日期向前推若干天。 -
a.a + (10 * b.a) + (100 * c.a):通过数学组合生成从0到999的数字序列:
例如,a.a = 1, b.a = 2, c.a = 3,则1 + (10 * 2) + (100 * 3) = 321,这样可以生成从0到999的连续数字。 -
将生成的数字组合转换为连续的日期序列:
SELECT CURDATE() - INTERVAL (a.a + (10 * b.a) + (100 * c.a)) DAY as date; -
GROUP BY d.date:按日期分组,计算每天的营业额。 -
ORDER BY d.date:按日期排序,确保结果是连续的。
除此之外都是一些基本的连接和限制条件,虽然看起来复杂,但实际执行效率很高,因为生成的日期序列是基于数学计算的。与此同时该方式也具有一定局限,如果传入的日期参数区间超出了我们生成的时间序列就会失效,比如此处不可超出当前日期以前999天。
2.方法二:
基于递归CTE(Common Table Expression):
递归CTE通过递归地生成每一行数据,直到满足某个终止条件。对于日期序列,我们可以从开始日期开始,逐天递增,直到达到结束日期。
WITH RECURSIVE DateSequence AS (
-- 递归的初始部分:从开始日期开始
SELECT DATE('2025-02-20') AS date
UNION ALL
-- 递归部分:每次递增一天,直到达到结束日期
SELECT DATE(date) + INTERVAL 1 DAY
FROM DateSequence
WHERE DATE(date) < DATE('2025-03-01')
)
SELECT
ds.date AS order_date,
COALESCE(SUM(o.amount), 0) AS daily_revenue
FROM
DateSequence ds
LEFT JOIN
-- 此处左连接时先将表中精确到秒的数据用DATE转化到日
orders o ON DATE(o.order_time) = ds.date AND o.status = 5
GROUP BY
ds.date
ORDER BY
ds.date2.2段落解析
-
WITH:是公共表表达式(CTE)的关键字,用于定义一个临时的结果集,可以在查询中多次引用; -
RECURSIVE:表示这个 CTE 是递归的,即它可以引用自身来生成数据; -
DateSequence:是递归 CTE 的名称,可以根据需要自定义名称; -
每次递归时,将当前日期加一天(
+ INTERVAL 1 DAY)。
在MySQL 8.0及以上版本中,可以使用递归CTE来生成任意日期范围的连续日期序列。这种方法更加灵活,可以轻松生成从开始日期到结束日期的所有日期,而不会受到999天的限制,但8.0版本以下无法使用。
3.逻辑层补全调整
public TurnoverReportVO getTurnOverStatistics(LocalDate begin, LocalDate end) {
List<LocalDate> dateList=new ArrayList<>();
dateList.add(begin);
String start = begin.toString();
String stop = end.toString();
while (!begin.equals(end)){
begin=begin.plusDays(1);
dateList.add(begin);
}
List<BigDecimal> revenue=orderMapper.getDailyRevenue(start,stop, Orders.COMPLETED);
return TurnoverReportVO.builder()
.dateList(StringUtils.join(dateList,","))
.turnoverList(StringUtils.join(revenue,","))
.build();
}经过优化,逻辑层代码也变得更加简洁容易维护,动态图表如下: