目录
本代码所使用的数据集中,标签为1的数据仅有五千多条,而标签为0的数据有二十八万条。为了使数据集中我们最关注的标签1的预测成功的概率,即1的召回率尽量更高,本代码将采用SVM算法提高性能。由于SVM算法处理大数据集时速度过慢,并且样本数据不均衡,本代码还将采用下采样处理数据,并绘制AUC-ROC曲线评价性能。
1.读取数据并预处理
import pandas as pd
import numpy as np
"""
数据读取与划分
"""
data = pd.read_csv('creditcard.csv')
'''数据标准化: Z标准化'''
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data['Amount'] = scaler.fit_transform(data[['Amount']])
data = data.drop(['Time'] , axis=1)2.下采样
#下采样解决样本不均衡问题
positive_eg= data[data['Class'] == 0] #获取到了所有标签(class)为 0的数据
negative_eg = data[data['Class'] == 1] #获取到了所有标签(class)为 1的数据
np.random.seed(seed=4)
positive_eg = positive_eg.sample(len(negative_eg)) #sample表示随机从参数中抽取数据
# #拼接数据
data_c = pd.concat([positive_eg, negative_eg]) # 把两个pandas数据组合
print(data_c)3.数据切分
'''训练集使用下采样数据,测试集使用原始数据进行预测'''
from sklearn.model_selection import train_test_split
#对下采样数据划分
X = data_c.drop('Class', axis=1) #对data_c数据进行划分。
y = data_c.Class
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)
# #对原始数据集进行切分,用于后期的测试
X_whole = data.drop('Class', axis=1)
y_whole = data.Class
x_train_w, x_test_w, y_train_w, y_test_w= train_test_split(X_whole, y_whole, test_size = 0.2, random_state = 0)4.使用SVM算法
# svm算法
clf = svm.SVC(C=5, kernel='rbf', gamma=0.5, probability=True)
# C:惩罚因子 rbf:径向基核函数 gamma:控制核函数的标准差
# probability=True:添加置信度,后续绘制ROC曲线
clf.fit(x_train, y_train)
5.测试
'''小训练集数据进行测试'''
from sklearn import metrics
train_predicted = clf.predict(x_train)
print(metrics.classification_report(y_train, train_predicted)) # 小数据集的训练数据集
'''使用测试集数据进行测试[小测试集]'''
test_predicted = clf.predict(x_test)
print(metrics.classification_report(y_test, test_predicted)) # 小数据集的测试数据集
'''使用测试集数据进行测试[大测试集]'''
test_predicted_big = clf.predict(x_test_w) #大测试数据集进行预测
#绘制混淆矩阵
print(metrics.classification_report(y_test_w, test_predicted_big))
cm_plot(y_test_w, test_predicted_big).show())大测试数据集预测的结果:
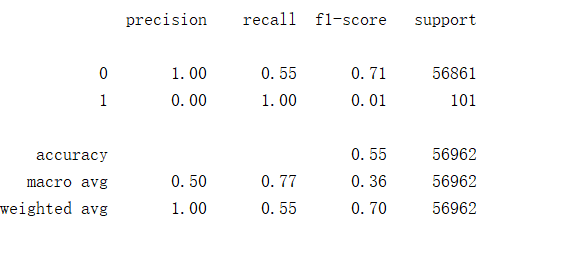
成功提高了标签为1的召回率。
6.绘制AUC-ROC曲线
'''AUC值的计算'''
y_pred_proba = clf.predict_proba(x_test_w)
a = y_pred_proba[:, 1]
auc_result = metrics.roc_auc_score(y_test_w, a)
'''绘制ROC-AUC曲线'''
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve #得到不同阈值的ROC
#计算ROC曲线的点
fpr, tpr, thresholds = roc_curve(y_test_w, a)
#绘制ROC曲线
plt.figure()
plt.plot(fpr, tpr, color= 'darkorange', lw=2, label='ROC curve(area=%0.2f)'% auc_result)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') #函数绘制一条从点(0,0)到点(1,1)的线段。
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend()
plt.show()
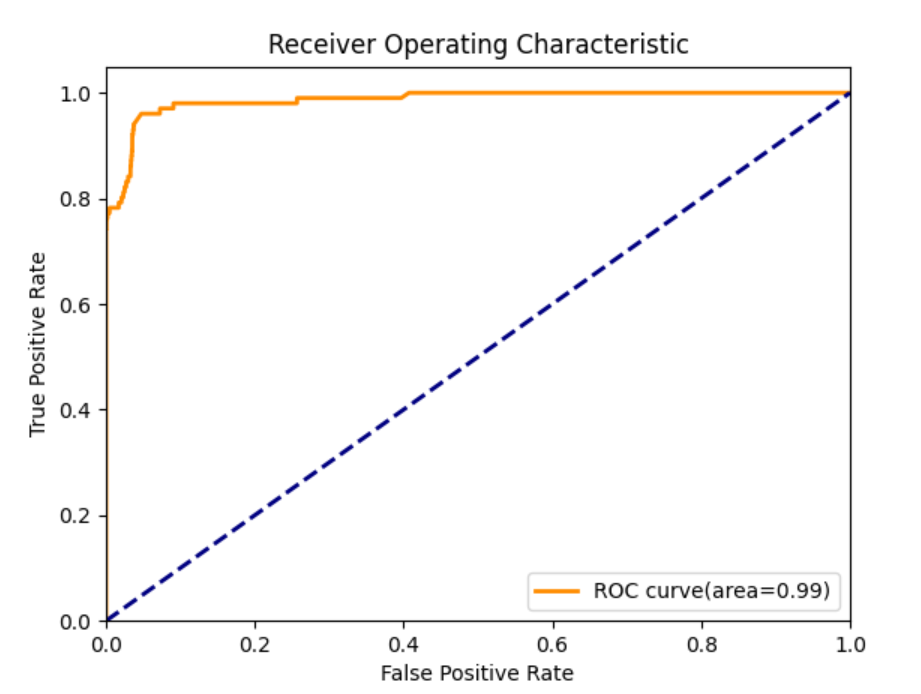
AUC达到了0.99,证明分类的性能良好。