
👨💻个人主页:@开发者-曼亿点
👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅!
👨💻 本文由 曼亿点 原创
👨💻 收录于专栏:机器学习
⭐🅰⭐
—

文章目录
⭐前言⭐
介绍了机器学习的数据预处理、特征工程、算法以及预测,这一章将重点介绍深度学习。随着人工智能逐渐升温人脸识别、语音识别和文本的深度分析已经越来越多地应用到我们的日常生活中。另外通过在工作中不断地了解一些客户的需求,我发现客户对深度学习或者是神经网络相关算法的咨询比重正在增加。这就意味着随着各大 IT公司营销活动的推广或各种行业媒体的宣传,人工智能领域的一些名词(如云计算、深度学习和 GPU 计算等)已经被很多人所熟识。然而绝大部分的人虽然听说过深度学习算法,但是并不清楚其中的一些原理,所需要有一些篇幅来对深度学习常接触到的知识进行介绍。
🎶 一、深度学习概述
深度学习(DeepLearning)算法是目前业内关注度非常高的一类算法,甚至很多技术分享或者技术会议,一听说有深度学习,马上就会引起广泛的关注。
下面就介绍一下深度学习的一些概念。首先,随着深度学习的发展,我们的生活中出现了哪些新的变化?最近比较火的一些技术营销,如 AlphaGo 和阿里云的 ET 机器人,它们的背后其实都是人工智能领域的深度学习算法的一些成果。通过一些媒介可以了解到很多机器人都具备与人对话以及人脸识别的能力。人工智能给人们的印象就像是能通过些机器算法来模拟人的思维过程,这也是人工神经网络算法诞生的原因,深度学习算法也是从人工神经网络算法衍生而来的。
(1)深度学习的发展
深度学习算法起源于人类对大脑神经元的模仿。1958年,约翰霍普金斯大学的 DavidHubel 和 Torsten Wiese! 做了这样一个实验,他们给猫的大脑神经元处接入了电极,用来测量猫的视觉与神经元之间的关联。他们在猫的眼前展示各种各样形状的物品,希望发现是否在大脑中的某一个部位对特定的一类特征会有固定的反应。最后他们发现了一种神经元细胞叫作方向感知神经元( orientation selective cel),这种边缘性的反应是猫的神经元细胞,只在物体的边缘朝向某个方向时才会活跃。通过这个实验,人们发现了一些生理学上的规律,生物在识别某些个体的时候,大脑内部是做了层层抽象的,这些抽象就像通过神经元把每种事物拆分成颗粒,然后通过对这些颗粒的理解来做出一些反应。当我们看到一张张人脸的时候,其实在大脑内部已经把每一张面孔抽象成一个一个小颗粒(如下图所示)
研究发现,这种抽象工作不是一蹴而就的,而是通过神经元的逐层抽象来实现的,这就构成了神经网络的一个基础架构,深度学习也继承了这种架构。
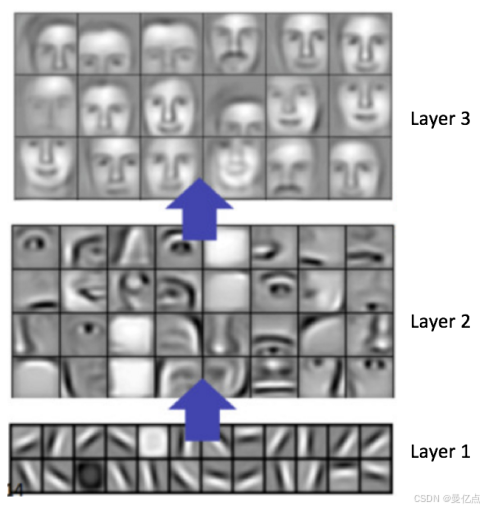
数据通过输入层流入整个算法架构。例如,如果输入数据是一张人脸图片,那么在隐藏层1和隐藏层 2(隐藏层的数量可以很多,这里只画出两层)中人脸被抽象成颗粒,每个隐藏层的神经元会判断输入数据某一部分的特征信息,最终输出判断结果。在这样仿生物脑神经的架构基础上诞生了人工神经网络,深度学习算法就是继承了这样的架构,并且最终由机器学习界泰斗 Hinton 做出了算法层面的变革,将深度学习推向新高度。2006年,Hinton 发表了一篇关于深度学习的论文 A Fast Learning Algorithm for Deep Belief Nets,这篇论文真正开启了学术界和工业界关于深度学习的浪潮。深度学习很快在语音、图像、文太的学习和理解方面有了颠覆性的发展。
(2)深度学习算法与传统算法的比较
深度学习归根结底也是机器学习的一种,如果说要做机器学习分类的话,除了分成险督学习、无监督学习、半监督学习和增强学习之外,从算法网络深度的角度来看还可以分成浅层学习算法和深度学习算法。
1.浅层学习算法
浅层学习(Shallow Learning),顾名思义就是隐藏层比较少的神经网络,我们可以把支持向量机(SVM)和逻辑回归(LR)这样的算法都看作浅层学习,也可以叫作常规的机器学习算法,因为这些学习方法并没有涉及多层次的不断抽象特征的过程,算法的架构相比于深度学习比较简单。以逻辑回归为例,只是把数据带入 Sigmoid 公式,然后利用梯度下降或者其他方法,并通过结果和预测值之间的差值计算梯度,然后不断减小梯度以达到回归系数收敛。现在提到的浅层学习都是监督学习,那么监督学习之所以能生成模型并目对预测集进行预测,它的核心思想是最优化代价函数。浅层的算法计算中,通过求解梯度找到函数最优化搜索的方向。但是这一思想仅限于浅层的机器学习算法,因为在浅层算法中,层数较少,很容易通过计算梯度把目标列的影响向前传递。然而在深度学习算法当中因为隐藏层很多,每一层可以理解成一个函数式,在求解每一层的偏导系数的时候需要老虑多层复合函数的变量偏导,所以用传统浅层算法的思想对多层次的深度学习网络进行训练可能就无法达到比较理想的效果。
另一点浅层算法与深度学习算法不同的地方在于对特征的处理方面。第4章中也介绍了特征对一个算法正确性的影响。浅层算法在处理一些分类场景时,都要通过特征抽象或者是特征衍生这些方式来人为地构造特征,这些特征的好坏不单考验工程师的业务经验,同时也对模型训练有至关重要的影响。购物行为的这种结构化数据,下表所示。
| 用户昵称 | 用户ID | 用户购买次数 | 用户性别 | 是否购买 |
|---|---|---|---|---|
| 小明 | 4212 | 3 | 1 | 1 |
| 小红 | 2141 | 2 | 0 | 0 |
对于表上表所示的这种结构化数据,其特征很容易抽象,但如果是图像或者语音文件这样的数据的特征可能非常复杂,单靠人工规则构造特征是非常难以实现的,这都分复杂特征的处理也是浅层机器学习和深度学习的区别之处。
前面介绍了浅层学习的内容,可以看出在算法的模型调优思想以及特征处理两方面浅层学习和深度学习还是有一定差别的。目前随着统计学理论以及计算能力的发展,逻回归和支持向量机等算法已经得到了非常普遍的应用,如在推荐系统或者是一些分类场下的应用。在处理特征环境不复杂的一些场景中,浅层学习往往能达到比较好的效果,但是针对图片、语音、文本这种特征环境复杂的数据,可能就需要深度学习算法更多地发挥作用。
2.深层学习算法
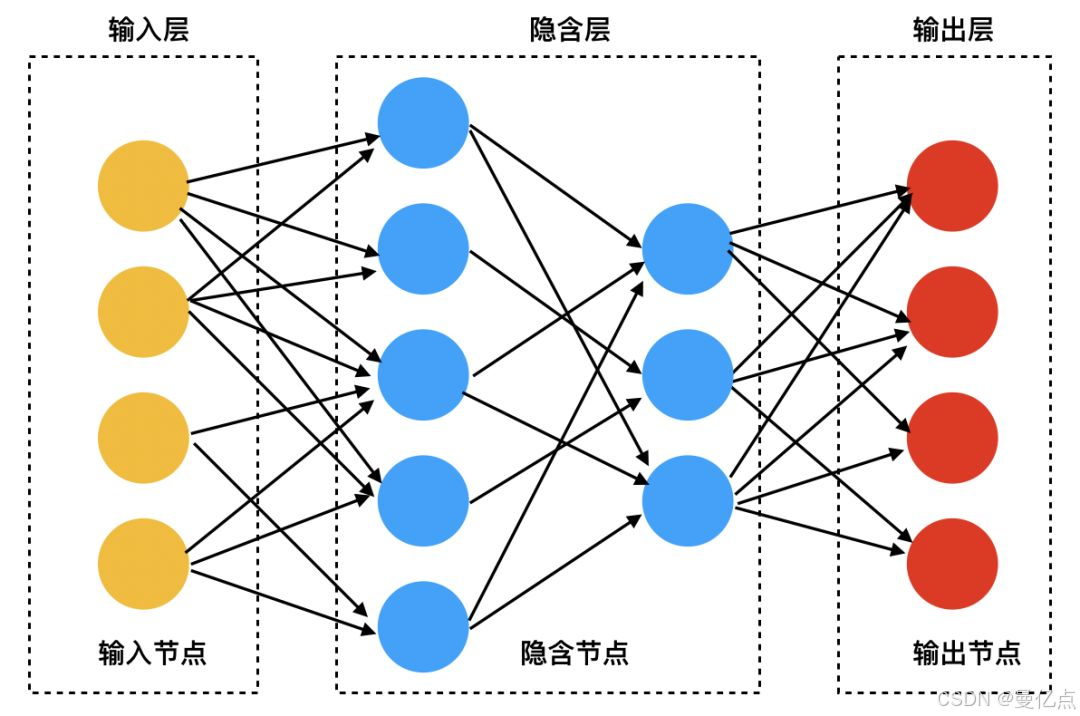
深度学习,从字面意思来看,突出的是“深”这个特点。算法的结构方面可以看到深度学习继承了神经网络的特点,也是由多层次组成的。如下图中每个圆圈模仿的是大脑神经元,在数学中呈现的是计算节点。
深度学习是由输入层、隐藏层和输出层3部分组成,隐藏层可以包含很多层,可以是7 层、8层,甚至更多。相对比于浅层学习,深度学习显然在计算层次上更为复杂。因头深度学习的隐藏层很多,如果单纯使用浅层算法的模型优化思想来优化每一层的参数会对模型精度有非常不利的影响,所以在模型训练方面,深度学习采用了另一种思想–反向传播算法。
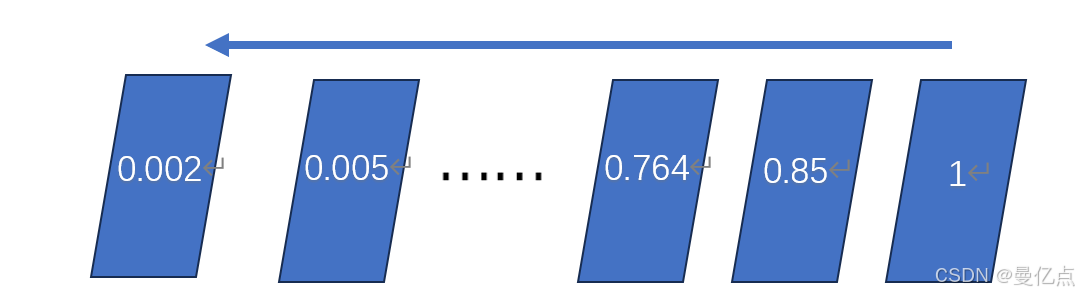
反向传播算法又称 BP算法(backpropagation algorithm),是一种监督学习算法。BP算法的核心思想是求导的链式法则。BP算法常被用来求解神经网络中的最优化问题,跟浅层算法的最优化求解不同的地方是 BP 算法可以用链式法则对每一层迭代计算梯度,链式计算可以理解为当通过 BP算法进行模型优化的时候,在求解梯度时可以考虑整个丛后到前的全部链路的偏导,然后对每一层的权重进行更新。虽然 BP算法是深度学习中一种简单高效的最优化算法,但是如果要应用到多层次的深度学习当中,那么目标列对前面每层的影响一定是逐层衰减的。如图所示,如果把最终的目标列对每一层的影响抽象成一个数值,那么在算法模型中如果有很多隐藏层出现,BP 算法的目标值对前方隐藏层的影响一定是逐层衰减的,这种衰减会造成模型的极大不准确,所以在深度学习的模型优化过程中往往需要通过很多辅助手段来优化 BP 算法。
下面简单介绍优化的思想,深度学习训练模型的过程是双向训练的,从输入到输出作为第一条链路,从输出到输入是第二条链路。
先讲第一条链路,深度学习自下而上的训练,每一次只针对一层网络进行训练,训练结果作为下一层的输入。这个过程有一点像模型系统对数据不断细化的抽象过程。例如,有一条输入数据是猫的头像图片,那么可能在第一层先抽象出猫的一些像素,然后在下面的一些隐藏层抽象出猫的一些线条,最后逐渐抽象出猫的轮廓。最终的模型整体效能就是辨识出输入数据是否是对猫的描述。那么第二条链路,也就是自上而下的这条链路,主要是借助反向传播的方式对每一层的参数进行调优,因为深度学习常常有超过5层的隐藏层,每一层的参数调优也是对结果有非常大影响的,这两条链路都涉及了很多数学方法的优化。
其实上文介绍的模型训练的逐层训练就是深度学习对特征不断抽象的过程。深度学习和浅层学习另一个特别大的区别体现在对特征的处理上,在浅层学习当中,特征都是通过入的手工加工和提取生成的,对图形数据这种特征复杂的场景扩展性很差。深度学习可以通过算法自动构建特征,将特征映射到不同的维度空间中,下面介绍深度学习逐层抽象幷且构建特征的自动编码算法。
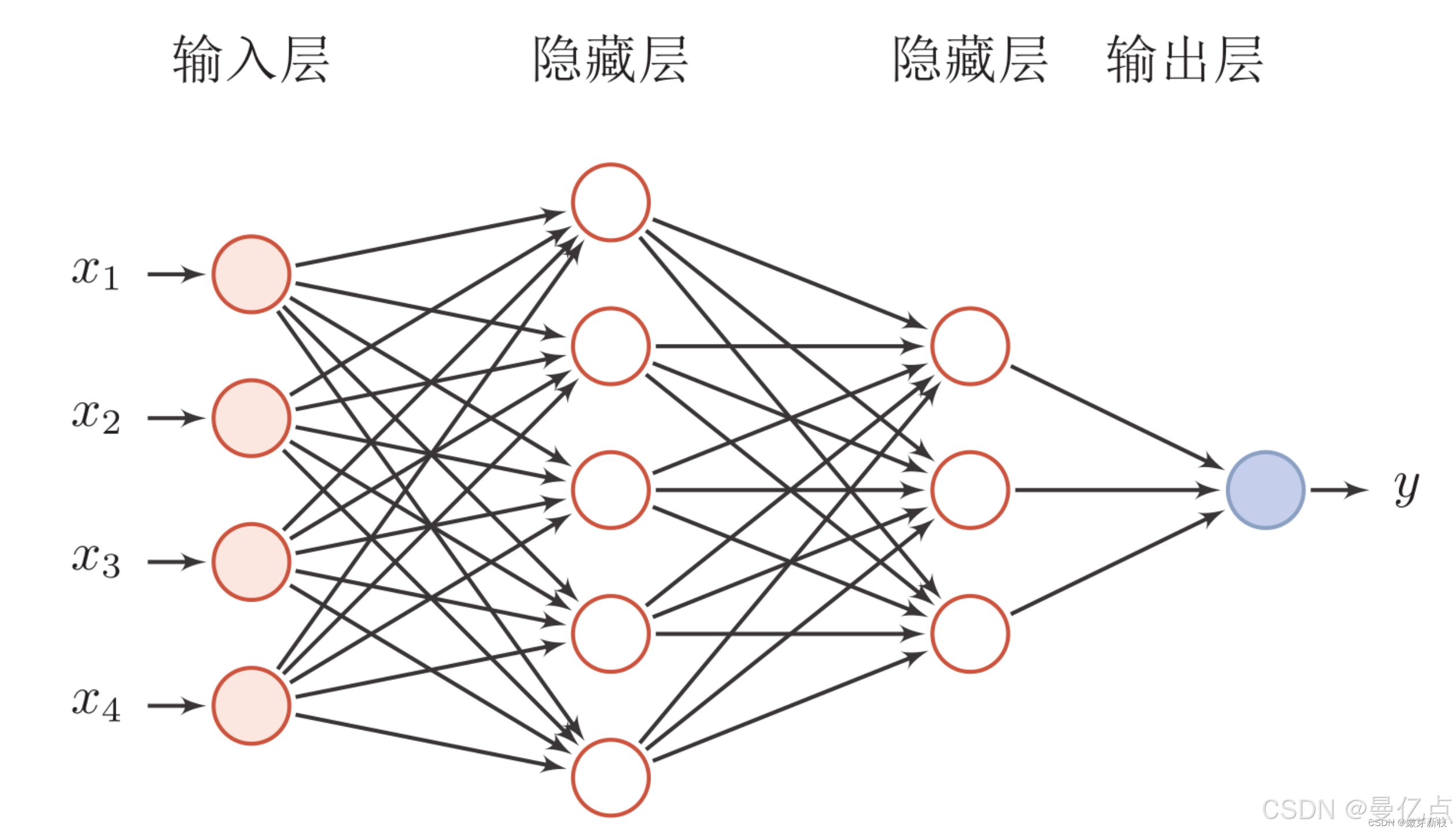
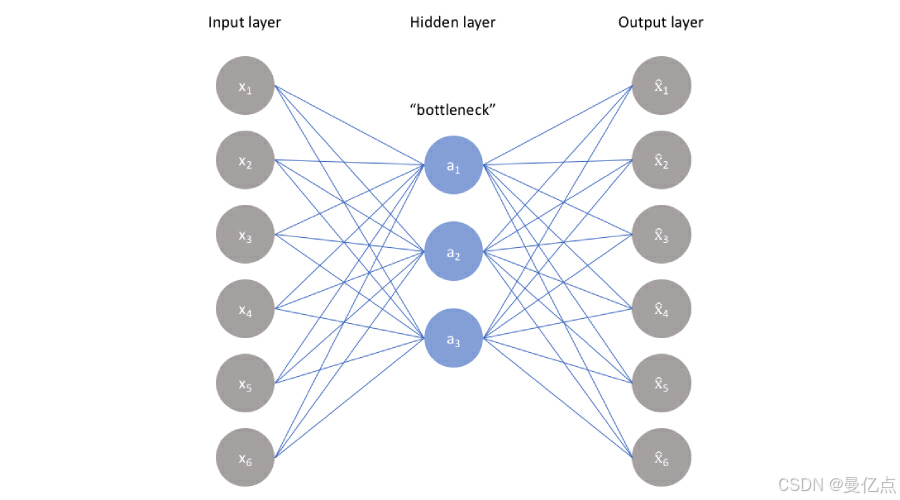
自动编码(AutoEncoder)的核心思想就是通过训练生成一个的数F,使F(x)约等于x也就是得到一个函数使输入和输出尽可能相等。做这件事有什么意义呢?我们先来观察下图。
如图 所示,每个圆圈代表一个神经元,如果输入是5个神经元的数据x,通过 3个神经元的转换输出的数据是 F(x),如果 F(x)≈x,也就意味着可以通过3维的数据重构了5 维的输入数据,而且重构的数据与原始数据几乎相同。这个流程中做了信息的压缩,也就是说可以利用输入数据之间的相关性,通过自动的特征提取,利用低维的特征来还原高维数据。如果应用到图像模型的识别中,就相当于找到了一种方法可以通过点、边及线条还原出一副图像,这些点、边及线条就是通过自动编码挖掘出来的特征。
以上就是深度学习的模型训练以及特征抽取的一些介绍,介绍得比较简单。总体来说深度学习在特征非常复杂的场景下会有比较好的表现,如图像识别、语音识别和文本分析这样的场景。

🎶 二、深度学习的常见结构
了解深度学习的读者一定经常听到几个深度学习的常用结构:DNN、CNN和RNN深度学习的结构种类非常多,这3种是出现频率比较高的。其实这3种结构的模型并不是并列关系,DNN 是表示有深度学习网络的算法的统称,CNN主要是一种空间概念上的度学习结构,RNN 是时间概念上的深度学习结构。下面就来分别介绍一下这3种深度学模型。
(1)深度神经网络
深度神经网络(Deep Neural Network,DNN),从字面意思来理解的话,特指层次比较深的神经网络,其结构如图。
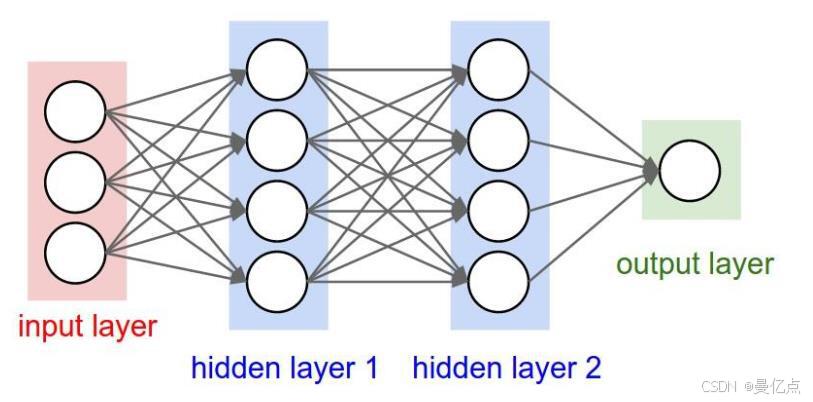
DNN 是由深度学习领域的大师 GeoffHinton 创造的并且被应用到各种场景之中。DNN泛指多层次的神经网络,这些模型的隐藏层之间彼此相连。只是针对处理数据的种类和特点不同,衍生出各种不同的结构,如后面介绍的CNN 和 RNN。
(2)卷积神经网络
卷积神经网络(ConvolutionalNeuralNetwork,CNN),是一种比较特殊的深度学习结构,主要是通过卷积来解决空间上一些复杂特征的问题。什么是空间问题呢?比较典型的就是图片识别问题。我们平时接触到很多车牌识别和人脸识别背后的模型训练都是依赖于CNN 的。之所以卷积神经网络神对图片这种类型的数据有比较好的训练效果,是因为图片的特征非常复杂。因为算法只能处理规范标准的数据,所以对图片数据需要进行一次二进制的转换才可以进入算法模型进行训练。具体转化效果如图6-8所示(图片源自ABeginner’s Guide To Understanding Convolutional Neural Networks)。

在非结构化数据的数制转换过程中,图片数据会按照像素和大小被转换成矩阵状的二进制数据。例如,图片被转化成 32x32x3的数组,32x32 表示的是图片像素,可以看作图片的长乘以高,乘以3表示 RGB(代表颜色)值。基于这样的数据形态,如果针对每个像素点都进行特征训练,那么每一个隐藏层需要被训练的参数会非常庞大。而如果每隐藏层的参数都过于复杂很容易造成局部过拟合的问题(参考第1章的介绍)。为了解这种大量特征参数训练的问题,CNN 利用卷积核作为权重的向下传导中介,大大地降了每一层的计算复杂度。
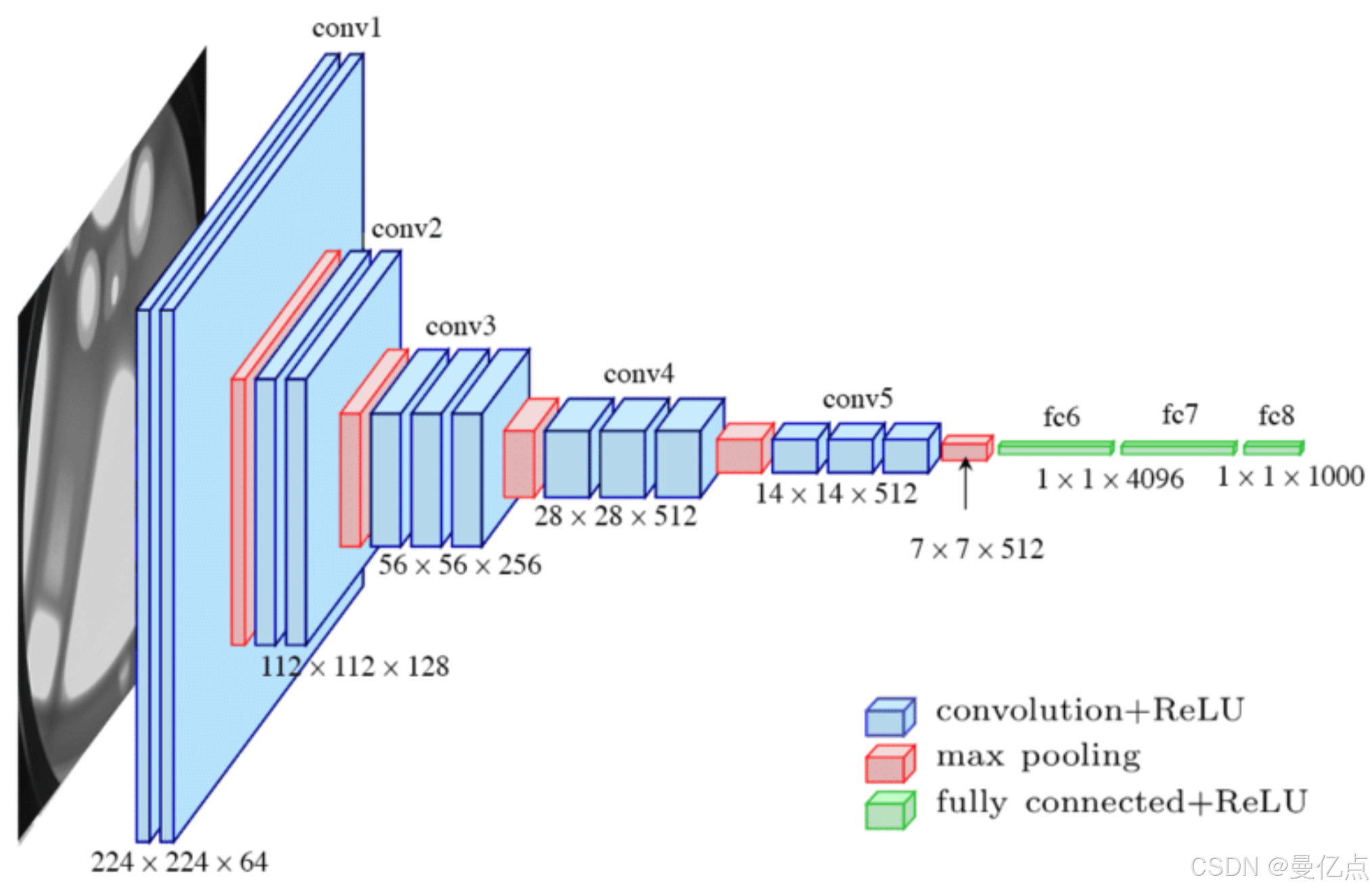
下面通过一张 LCNNLeNet-5 对 CNN 模型的描述图来介绍一下CNN 的型架构、LeNet-5是一个 CNN 模型的开源组织,地址为http://yann,lecun,com/exdb/lenet/。
图表示通过 实现手写字识别的架构,可以看到其中CNN 架构包含卷积(Convolutions)、下采样(Subsampling)和全连接(Full Connection)几个关键元素,下面分别介绍一下这几部分内容。
(1)卷积(Convolutions)。首先介绍卷积核的原理,通过虚线标记出来的这个小方块就是一个卷积核。
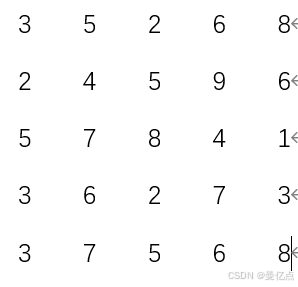
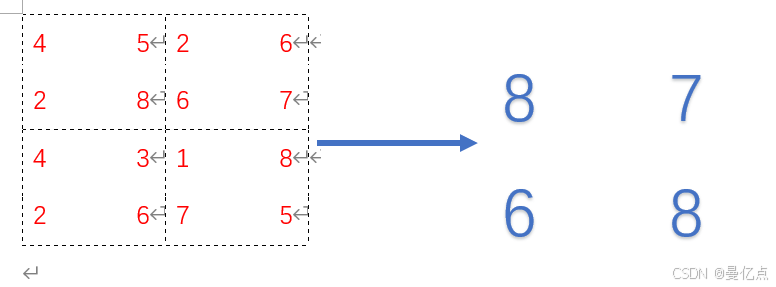
下面通过一个例子介绍卷积核是如何扫描图片的,假设输入图片不考虑 RGB,是一个5x5的矩阵数据,如下所示。
然后我们来看下这组数据经过卷积核的处理会发生什么变化,假设卷积核是3x3的个方块,卷积核矩阵如下。
实际上在执行卷积计算的时候,卷积核需要对输入数据进行一遍扫描,这里选取扫描过程的一部分介绍卷积计算的原理。
把矩阵扫描一遍之后,输入从5x5的矩阵变为了3x3的矩阵,这就做到了参数的压缩,每层都通过一次卷积核处理,那么就可以把图片这种复杂参数的训练流程简化,通过卷积核也能学习出对输入数据的特征描述,整个 CNN学习的过程就是在确定卷积核的具体数值。
(2)下采样(Subsampling)。当我们观察 LeNet-5 的 CNN 架构(见图)时可以发现,除了上面提到的卷积核处理卷积层,还有穿插的下采样层。下采样层的作用就是对图像进行自抽样,减少数据的处理量,使有效的信息得到尽可能的保留。下采样层在深度学习中也被表示为池化层(PoolingLayer)。池化方法有很多,这里介绍一种比较简单的方法————最大池化(Maxpooling),最大池化的原理是在每个小区域中选择最大值作为输出值。
通过一个例子介绍下最大池化,如图所示,输入数为 4x4的结构,可以拆分成4个2x2的小方块,最大池化取每一部分中最大的数值作为输出,这样的好处是保留了数据中的最主要特征而且能小计算复杂度。
(3)全连接(Full connecton)。通过CNN 架构我们了解到,经历了两卷积和采样处理,生成了许多的特征图谱(Feature Map),这些特征图谱(Feature Map)可以看作对于输入图片的位置信息以及表现的描述,不同的特征图谱(Feature Map)会示不同的内容,如某一个点的位置、字母中某一个模块的朝向等。但是我们需要解决的坏景是识别输入图片中的字母:“A”,光有这些特征图谱(Feature Map)是不够的,因为特行图谱(Feature Map)描述的是输入图片的各种细节信息,需要把这些信息进行汇总并且乡合判断、返回我们需要的结果。全连接以及高斯连接会做一个分类结果的判断,判断输入结果是否为“A”。
到这里就完成了对 CNN 的简单介绍,如果想更详细地了解CNN 架构还需要大量查阅资料,目前CNN在图片识别领域的应用非常广泛,主要是针对空间数据的处理,下面绍一下对时间序列数据进行处理的深度学习架构RNN。


(3)循环神经网络
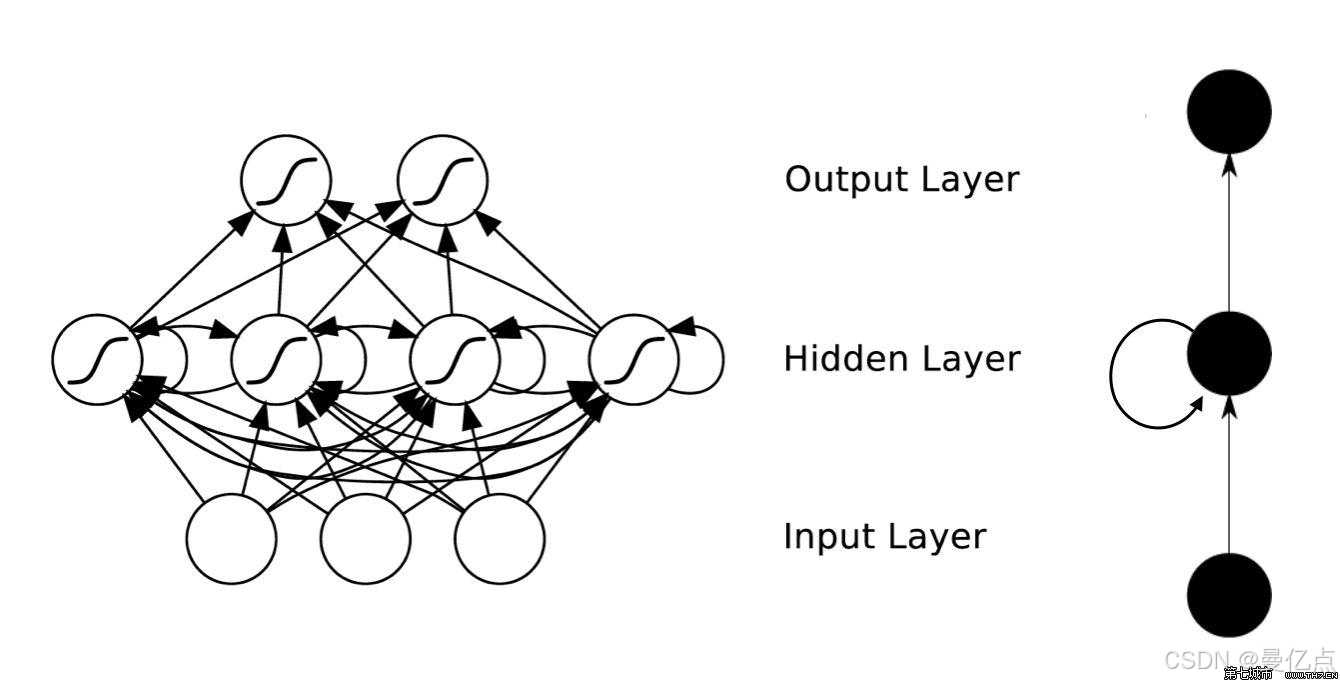
循环神经网络(Recurrent Neural Network,RNN)是一种环状的深度神经网络,常用来解决时序行为的问题。什么是环状网络?下面通过和CNN 比对来介绍这种形态的网络的特点。从参数传导的角度来看,CNN架构的每层参数是直接向下传导的,不会回流而且同层参数间没有传导。而 RNN 在隐藏层的输出可以作为自身的输入,参数可以环状传导。
对业务场景来讲,CNN主要处理的是图片数据,图片数据其实是一种空间上的相互联系,如猫的图像中鼻子边上可能是嘴,CNN 解决的是空间的问题。但是对文本分析和语音识别来讲,下一个时间产生的文本会受到前一时刻文本的影响,也就是说在时间维腹上是彼此关联的,所以 RNN 的环状特点就会更好地解决这种时序空间的联系。而且CNN解决的问题往往是输入数据长短格式固定的场景,如训练了一个32 像素x32 像素的人胎识别模型,那么就只能对这个尺寸的数据进行预测。然而在很多场景中,如机器翻译,每次需要翻译的句子长短是不定的,这对 CNN 这种在输入格式中有固定要求的模型就不适合了,RNN 就没有这方面的限制。
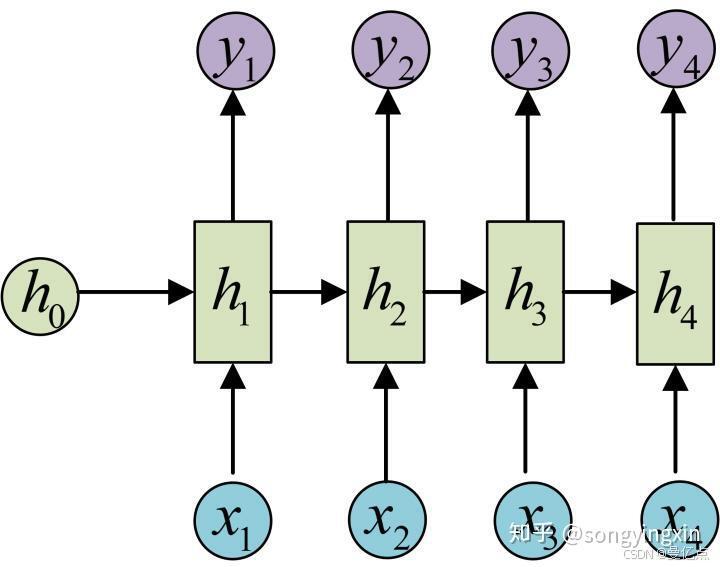
这张图表示 RNN 的隐藏层结构,X作为输入,Y为输出,H表示每个隐藏层的参数下面以图 为例介绍 RNN,例如需要预测文章接下来的3个字是什么,那么这3个字对应到 RNN 中为3个隐藏层。我们看到每一层在做计算的时候都会考虑到前一层的隐层参数以及当前时间序列的输入,如在训练的时候考虑了以及,对应到文章预测场景,就是每预测一个字都会考虑到上下文的联系。相比于 CNN 的隐藏层间参数不传导RNN 的这种架构更适合对时间序列的数据进行预测。
目前 RNN 已经广泛应用于自然语言理解和股票预测等时间相关的场景下,也有很多RNN 的衍生版本产生,比较成功的模型如 LSTM,所以如果想真正了解RNN的原理,还需要对其他模型研究进行相关探索。
结束语🥇
以上就是机器学习
持续更新机器学习教程,欢迎大家订阅系列专栏🔥机器学习
你们的支持就是曼亿点创作的动力💖💖💖
