Importing Essential Libraries
import librosa
import numpy as np
from glob import glob
from tqdm import tqdm
import soundfile as sf
import scipy
from scipy.io import wavfile
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report
import matplotlib.pyplot as plt
from IPython.display import Audio, display
import IPython
import librosa.display
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPooling2D, Flatten, TimeDistributed, Bidirectional, LSTM, GRU, Dense, Dropout, Input, concatenate
from tensorflow import keras
from keras.layers import Reshape
from keras.regularizers import l2
import seaborn as sns
import pickleAudio Preprocessng
def audio_reading_and_resampling(file_directory, target_sr=44000):
audio, sr = librosa.load(file_directory, sr=None)
audio_resampled = librosa.resample(audio, sr, 44000)
return audio_resampled, target_sr
def removing_silence(audio_file, threshold_value=25):
non_silent_indices = librosa.effects.split(audio_file, top_db=threshold_value)
audio_trimming_performed = np.concatenate([audio_file[start:end] for start, end in non_silent_indices])
return audio_trimming_performed
def applying_wiener_filter(audio_file):
audio_denoised_effect = librosa.effects.preemphasis(audio_file)
return audio_denoised_effect
filenames = glob('Audio/*.wav')
file = filenames[0]
for file in tqdm(filenames):
audio_resampled, sr_resampled_rate = audio_reading_and_resampling(file)
audio_trimmed_performed = removing_silence(audio_resampled)
audio_denoisation_performed = applying_wiener_filter(audio_trimmed_performed)
sf.write(file, audio_denoisation_performed, 44000)Mel_Spectrogram Formation
audio, sr = librosa.load('Audio/F_01_OISHI_S_1_ANGRY_1.wav', sr=None)
audio2=audio[0:33411]
print(audio2.shape)
print(audio)
print(audio2)
print(sr)
(33411,)
[-0.00021362 -0.00015259 -0.00021362 ... -0.00341797 -0.00311279
-0.00305176]
[-0.00021362 -0.00015259 -0.00021362 ... 0.09979248 0.09967041
0.09970093]
44100
i=0
audio3=[]
file_names = glob('Audio/*.wav')
for file_name_inst2 in tqdm(file_names):
audio_file_path = file_name_inst2
y, sr = librosa.load(audio_file_path, sr=None)
mel_spectrogram = librosa.feature.melspectrogram(y, sr=sr, n_fft=2048, hop_length=512, n_mels=128)
mel_spectrogram_db = librosa.power_to_db(mel_spectrogram, ref=np.max)
mel_spectrogram_db_resized = librosa.util.fix_length(mel_spectrogram_db, 259, axis=1)
mel_spectrogram_np = np.array(mel_spectrogram_db_resized)
audio3.append(mel_spectrogram_np)
audio3=np.array(audio3)
audio3.shape
(7000, 128, 259)
audio3[0]
array([[-80. , -80. , -80. , ..., -45.458397, -48.79946 ,
-55.715096],
[-80. , -80. , -80. , ..., -50.80785 , -52.968376,
-55.8729 ],
[-80. , -80. , -80. , ..., -58.38736 , -63.51193 ,
-59.595676],
...,
[-80. , -80. , -80. , ..., -80. , -80. ,
-80. ],
[-80. , -80. , -80. , ..., -80. , -80. ,
-80. ],
[-80. , -80. , -80. , ..., -80. , -80. ,
-80. ]], dtype=float32)
audio5=audio3
audio5[6999]
array([[-80. , -80. , -80. , ..., -49.782776, -53.632187,
-50.914474],
[-80. , -80. , -80. , ..., -41.7889 , -41.881985,
-42.34123 ],
[-80. , -80. , -80. , ..., -22.900608, -24.374134,
-25.656837],
...,
[-80. , -80. , -80. , ..., -80. , -80. ,
-80. ],
[-80. , -80. , -80. , ..., -80. , -80. ,
-80. ],
[-80. , -80. , -80. , ..., -80. , -80. ,
-80. ]], dtype=float32)Data Labelling & Spectral Visualization
labels_data = []
for each_file in file_names:
each_file = each_file.split('/')[-1][:-3]
labels_data.append(each_file.split('_')[-2])
file_name = file_names[0]
data_file = []
for file_name in tqdm(file_names):
temp_file = scipy.io.wavfile.read(file_name, mmap=False)
data_file.append(temp_file[1])
indx = []
for each in labels_data:
indx.append(list(np.unique(labels_data)).index('FEAR'))
indx = 5000
print(labels_data[indx])
plt.plot(data_file[indx])
IPython.display.Audio(file_names[indx])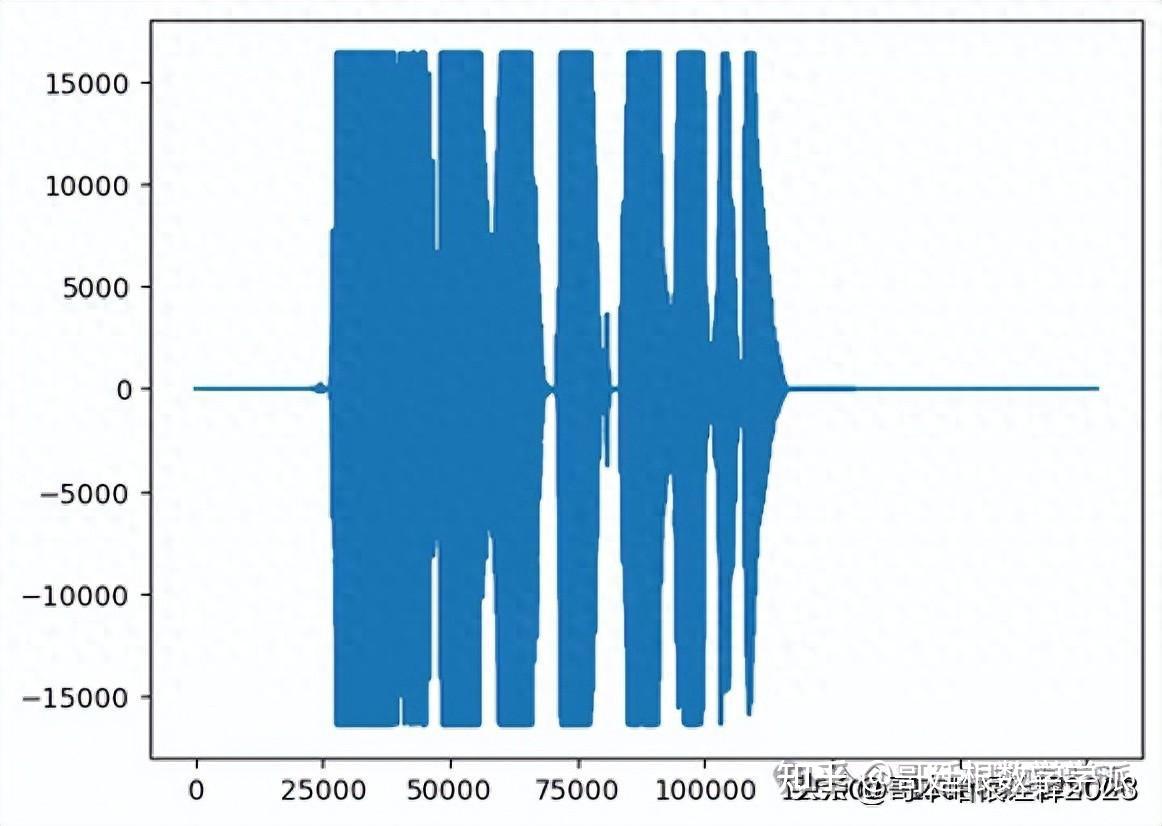
indx = 5909
print(labels_data[indx])
plt.plot(data_file[indx])
IPython.display.Audio(file_names[indx])
SAD
index = 5929
print(labels_data[indx])
plt.plot(data_file[indx])
IPython.display.Audio(file_names[indx])
SAD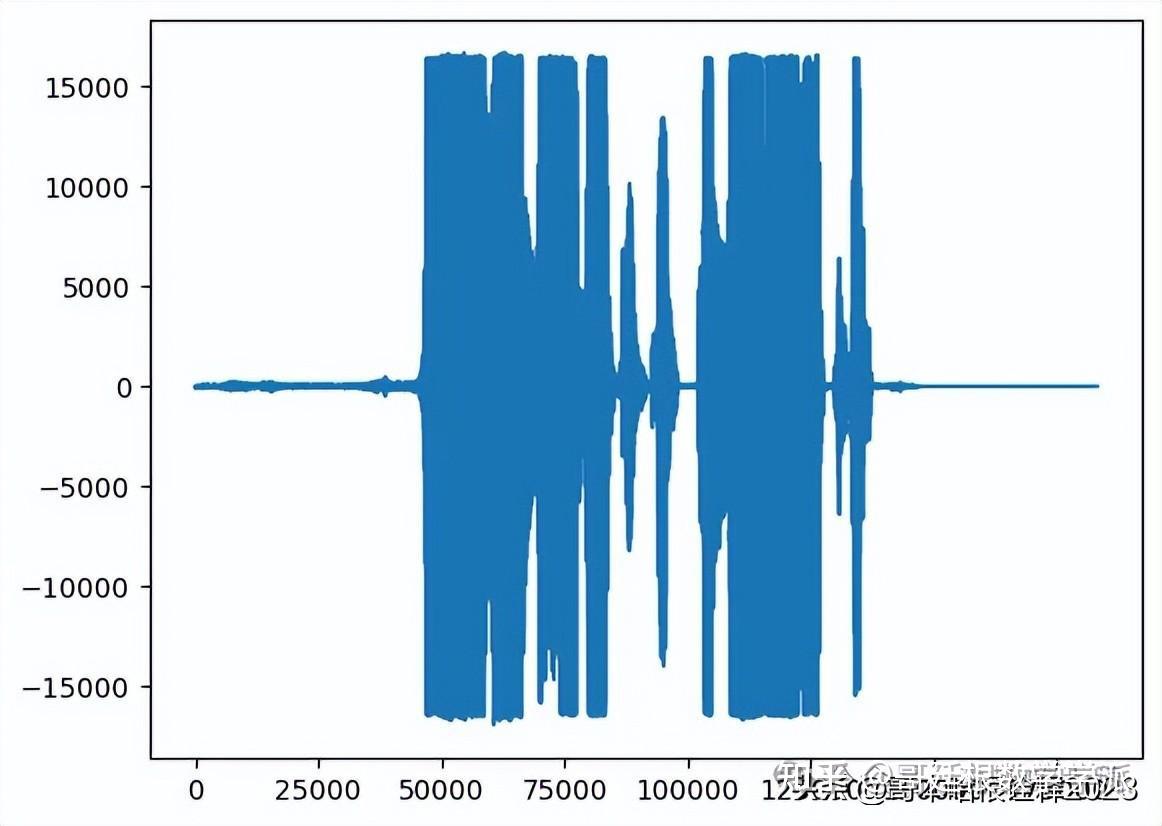
Audio Spectrums
def create_waveplot(data_file, sr_rate, e):
plt.figure(figsize=(10, 3))
plt.title('Waveplot for the audio file with {} sentiment'.format(e), size=15)
librosa.display.waveplot(data_file, sr=sr_rate)
plt.show()
def create_spectrogram(data, sr_rate, e):
X_file = librosa.stft(data)
Xdb_file = librosa.amplitude_to_db(abs(X_file))
plt.figure(figsize=(12, 3))
plt.title('Spectrogram for the audio file with {} sentiment'.format(e), size=15)
librosa.display.specshow(Xdb_file, sr=sr_rate, x_axis='time', y_axis='hz')
plt.colorbar()
spectogram = []
indx = 500
emotion=labels_data[indx]
path = file_names[indx]
data, sampling_rate = librosa.load(path,sr=None)
print(sampling_rate)
a = create_spectrogram(data, 44000, emotion)
spectogram.append(a)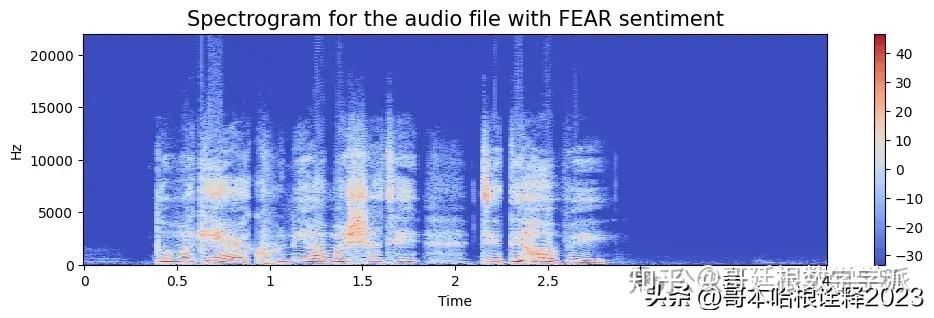
spectogram = []
indx = 800
emotion=labels_data[indx]
path = file_names[indx]
data, sampling_rate = librosa.load(path, sr=None)
a = create_spectrogram(data, 44000, 'AMAZEMENT')
spectogram.append(a)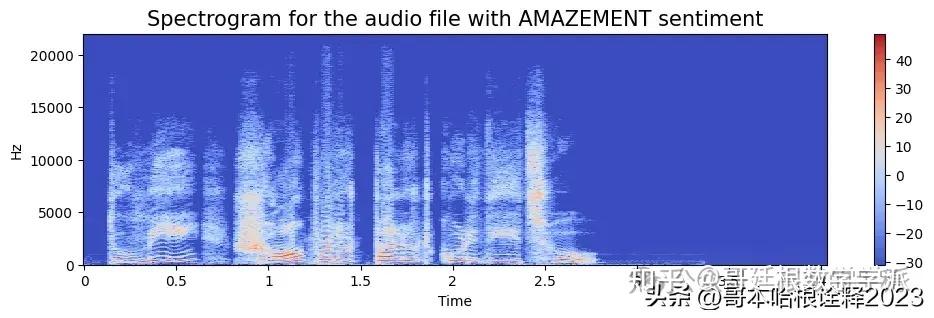
spectogram = []
indx = 2000
emotion=labels_data[indx]
path = file_names[indx]
data, sampling_rate = librosa.load(path, sr=None)
a = create_spectrogram(data, 44000, 'HATE')
spectogram.append(a)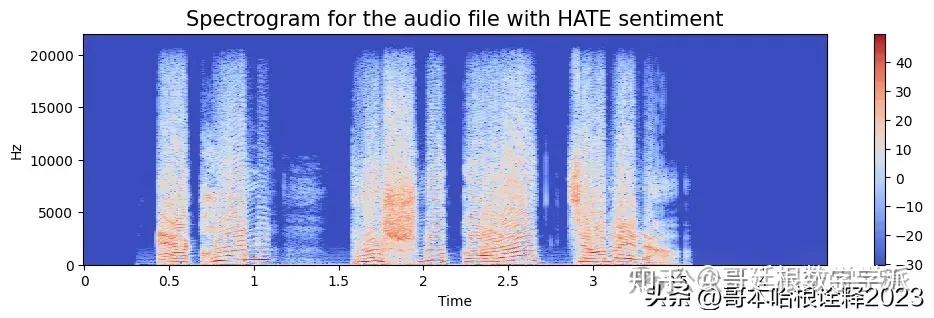
Audio Spectrograms (Mel-Spectrograms)
Audio_file = "Audio/F_01_OISHI_S_2_ANGRY_1.wav"
Audio, sr = librosa.load(Audio_file, sr=None)
print(sr)
mel_spectrogram = librosa.feature.melspectrogram(Audio, sr=sr, n_fft=2048, hop_length=512, n_mels=10)
mel_spectrogram.shape
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram)
log_mel_spectrogram.shape
plt.figure(figsize=(10, 3))
librosa.display.specshow(log_mel_spectrogram,
x_axis="time",
y_axis="mel",
sr=sr)
plt.colorbar(format="%+2.f")
plt.show()
print('Angry')
44100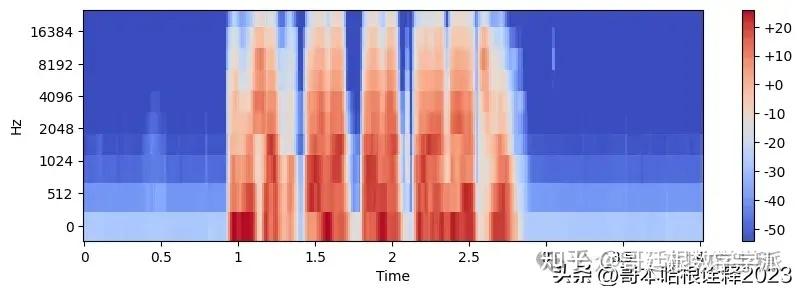
Audio_file = "Audio/F_01_OISHI_S_1_SAD_3.wav"
Audio, sr = librosa.load(Audio_file, sr=None)
mel_spectrogram = librosa.feature.melspectrogram(Audio, sr=sr, n_fft=2048, hop_length=512, n_mels=10)
mel_spectrogram.shape
log_mel_spectrogram = librosa.power_to_db(mel_spectrogram)
log_mel_spectrogram.shape
plt.figure(figsize=(10, 3))
librosa.display.specshow(log_mel_spectrogram,
x_axis="time",
y_axis="mel",
sr=sr)
plt.colorbar(format="%+2.f")
plt.show()
print('Unhapiness')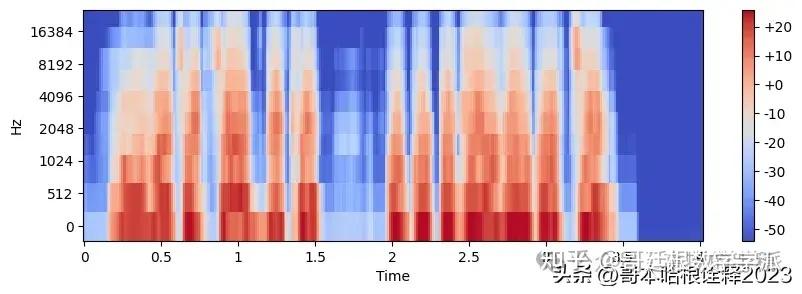
Model Preparation
labels_data=np.array(labels_data)
categories = labels_data.reshape(-1, 1)
encoder = OneHotEncoder(sparse=False)
one_hot_encoded = encoder.fit_transform(categories)
labels_data=one_hot_encoded
labels_data
array([[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
[1., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 1.],
[0., 0., 0., ..., 0., 0., 1.],
[0., 0., 0., ..., 0., 0., 1.]])
audio5=audio5.reshape(7000, 128, 259, 1)
labels_data=labels_data.reshape(7000, 1, 7)
X_train, X_test, y_train, y_test=train_test_split(audio5, labels_data, test_size=0.10, random_state=42)
def Deep_CNN_S_Hb_LSTM_GRU_Model(input_shape):
model_in = Input(shape=input_shape)
model1_in= Input(shape=input_shape)
model=Conv2D(128, (3, 3), strides=(1, 1), padding='same')(model_in)
model=BatchNormalization()(model)
model=Activation('elu')(model)
model=MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(model)
model=Conv2D(128, (3, 3), strides=(1, 1), padding='same')(model)
model=BatchNormalization()(model)
model=Activation('elu')(model)
model=MaxPooling2D(pool_size=(4, 4), strides=(4, 4))(model)
model=Conv2D(64, (3, 3), strides=(1, 1), padding='same')(model)
model=BatchNormalization()(model)
model=Activation('elu')(model)
model=MaxPooling2D(pool_size=(4, 4), strides=(4, 4))(model)
model=Conv2D(64, (3, 3), strides=(1, 1), padding='same')(model)
model=BatchNormalization()(model)
model=Activation('elu')(model)
model=MaxPooling2D(pool_size=(4, 4), strides=(4, 4))(model)
model1=Conv2D(128, (3, 3), strides=(1, 1), padding='same')(model1_in)
model1=BatchNormalization()(model1)
model1=Activation('elu')(model1)
model1=MaxPooling2D(pool_size=(2, 2), strides=(2, 2))(model1)
model1=Conv2D(128, (3, 3), strides=(1, 1), padding='same')(model1)
model1=BatchNormalization()(model1)
model1=Activation('elu')(model1)
model1=MaxPooling2D(pool_size=(4, 4), strides=(4, 4))(model1)
model=TimeDistributed(Flatten())(model)
model1=TimeDistributed(Flatten())(model1)
model=Bidirectional(LSTM(units=375, return_sequences=True))(model)
model=Dropout(0.20)(model)
model1=Bidirectional(GRU(units=156, activation='tanh', return_sequences=True))(model1)
model1=Dropout(0.35)(model1)
model=Dense(30,activation='relu', kernel_regularizer=l2(0.01))(model)
model1=Dense(30,activation='relu', kernel_regularizer=l2(0.01))(model1)
model1=Reshape((1, 480))(model1)
model2=concatenate([model, model1])
model2=Dense(7,activation='softmax')(model2)
model_ul=tf.keras.models.Model(inputs=[model_in, model1_in], outputs=model2)
return model_ul
A_model = Deep_CNN_S_Hb_LSTM_GRU_Model(X_train.shape[-3:])
A_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
A_model.summary()
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_5 (InputLayer) [(None, 128, 259, 1)] 0 []
conv2d_12 (Conv2D) (None, 128, 259, 128) 1280 ['input_5[0][0]']
batch_normalization_12 (Ba (None, 128, 259, 128) 512 ['conv2d_12[0][0]']
tchNormalization)
activation_12 (Activation) (None, 128, 259, 128) 0 ['batch_normalization_12[0][0]
']
max_pooling2d_12 (MaxPooli (None, 64, 129, 128) 0 ['activation_12[0][0]']
ng2D)
conv2d_13 (Conv2D) (None, 64, 129, 128) 147584 ['max_pooling2d_12[0][0]']
batch_normalization_13 (Ba (None, 64, 129, 128) 512 ['conv2d_13[0][0]']
tchNormalization)
activation_13 (Activation) (None, 64, 129, 128) 0 ['batch_normalization_13[0][0]
']
input_6 (InputLayer) [(None, 128, 259, 1)] 0 []
max_pooling2d_13 (MaxPooli (None, 16, 32, 128) 0 ['activation_13[0][0]']
ng2D)
conv2d_16 (Conv2D) (None, 128, 259, 128) 1280 ['input_6[0][0]']
conv2d_14 (Conv2D) (None, 16, 32, 64) 73792 ['max_pooling2d_13[0][0]']
batch_normalization_16 (Ba (None, 128, 259, 128) 512 ['conv2d_16[0][0]']
tchNormalization)
batch_normalization_14 (Ba (None, 16, 32, 64) 256 ['conv2d_14[0][0]']
tchNormalization)
activation_16 (Activation) (None, 128, 259, 128) 0 ['batch_normalization_16[0][0]
']
activation_14 (Activation) (None, 16, 32, 64) 0 ['batch_normalization_14[0][0]
']
max_pooling2d_16 (MaxPooli (None, 64, 129, 128) 0 ['activation_16[0][0]']
ng2D)
max_pooling2d_14 (MaxPooli (None, 4, 8, 64) 0 ['activation_14[0][0]']
ng2D)
conv2d_17 (Conv2D) (None, 64, 129, 128) 147584 ['max_pooling2d_16[0][0]']
conv2d_15 (Conv2D) (None, 4, 8, 64) 36928 ['max_pooling2d_14[0][0]']
batch_normalization_17 (Ba (None, 64, 129, 128) 512 ['conv2d_17[0][0]']
tchNormalization)
batch_normalization_15 (Ba (None, 4, 8, 64) 256 ['conv2d_15[0][0]']
tchNormalization)
activation_17 (Activation) (None, 64, 129, 128) 0 ['batch_normalization_17[0][0]
']
activation_15 (Activation) (None, 4, 8, 64) 0 ['batch_normalization_15[0][0]
']
max_pooling2d_17 (MaxPooli (None, 16, 32, 128) 0 ['activation_17[0][0]']
ng2D)
max_pooling2d_15 (MaxPooli (None, 1, 2, 64) 0 ['activation_15[0][0]']
ng2D)
time_distributed_5 (TimeDi (None, 16, 4096) 0 ['max_pooling2d_17[0][0]']
stributed)
time_distributed_4 (TimeDi (None, 1, 128) 0 ['max_pooling2d_15[0][0]']
stributed)
bidirectional_5 (Bidirecti (None, 16, 312) 3981744 ['time_distributed_5[0][0]']
onal)
bidirectional_4 (Bidirecti (None, 1, 750) 1512000 ['time_distributed_4[0][0]']
onal)
dropout_5 (Dropout) (None, 16, 312) 0 ['bidirectional_5[0][0]']
dropout_4 (Dropout) (None, 1, 750) 0 ['bidirectional_4[0][0]']
dense_7 (Dense) (None, 16, 30) 9390 ['dropout_5[0][0]']
dense_6 (Dense) (None, 1, 30) 22530 ['dropout_4[0][0]']
reshape_2 (Reshape) (None, 1, 480) 0 ['dense_7[0][0]']
concatenate_2 (Concatenate (None, 1, 510) 0 ['dense_6[0][0]',
) 'reshape_2[0][0]']
dense_8 (Dense) (None, 1, 7) 3577 ['concatenate_2[0][0]']
==================================================================================================
Total params: 5940249 (22.66 MB)
Trainable params: 5938969 (22.66 MB)
Non-trainable params: 1280 (5.00 KB)Model Traning and Cross Validation
X_train.shape
(6300, 128, 259, 1)
y_train.shape
(6300, 1, 7)
model_history=A_model.fit([X_train, X_train], y_train, epochs=50, batch_size=64, validation_split=0.22)
plt.plot(model_history.history['accuracy'])
plt.plot(model_history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()
plt.plot(model_history.history['loss'])
plt.plot(model_history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['Train', 'Validation'], loc='upper left')
plt.show()Result Prediction
y_pred=A_model.predict([X_test, X_test])
y_pred2=y_pred.reshape(700,7)
probabilities = y_pred2
indices = np.argmax(probabilities, axis=1)
one_hot_probabilities = np.zeros((probabilities.shape[0], probabilities.shape[1]))
one_hot_probabilities[np.arange(probabilities.shape[0]), indices] = 1
print(one_hot_probabilities)
[[0. 0. 0. ... 0. 1. 0.]
[1. 0. 0. ... 0. 0. 0.]
[0. 0. 0. ... 0. 1. 0.]
...
[0. 0. 0. ... 0. 0. 1.]
[0. 0. 0. ... 0. 1. 0.]
[0. 0. 0. ... 0. 0. 1.]]Confusion Matrix Formation & Result Evaluation
cm = confusion_matrix(y_test2.argmax(axis=1), y_pred2.argmax(axis=1))
plt.figure(figsize=(20,10))
ax= plt.subplot()
sns.heatmap(cm, annot=True, fmt='g', ax=ax);
labels=['Anger', 'Hate', 'Fear', 'Delight', 'Neutral', 'Unhappiness', 'Amazement']
ax.set_xlabel('Predicted labels');ax.set_ylabel('True labels');
ax.set_title('Confusion Matrix');
ax.xaxis.set_ticklabels(labels); ax.yaxis.set_ticklabels(labels)
[Text(0, 0.5, 'Anger'),
Text(0, 1.5, 'Hate'),
Text(0, 2.5, 'Fear'),
Text(0, 3.5, 'Delight'),
Text(0, 4.5, 'Neutral'),
Text(0, 5.5, 'Unhappiness'),
Text(0, 6.5, 'Amazement')]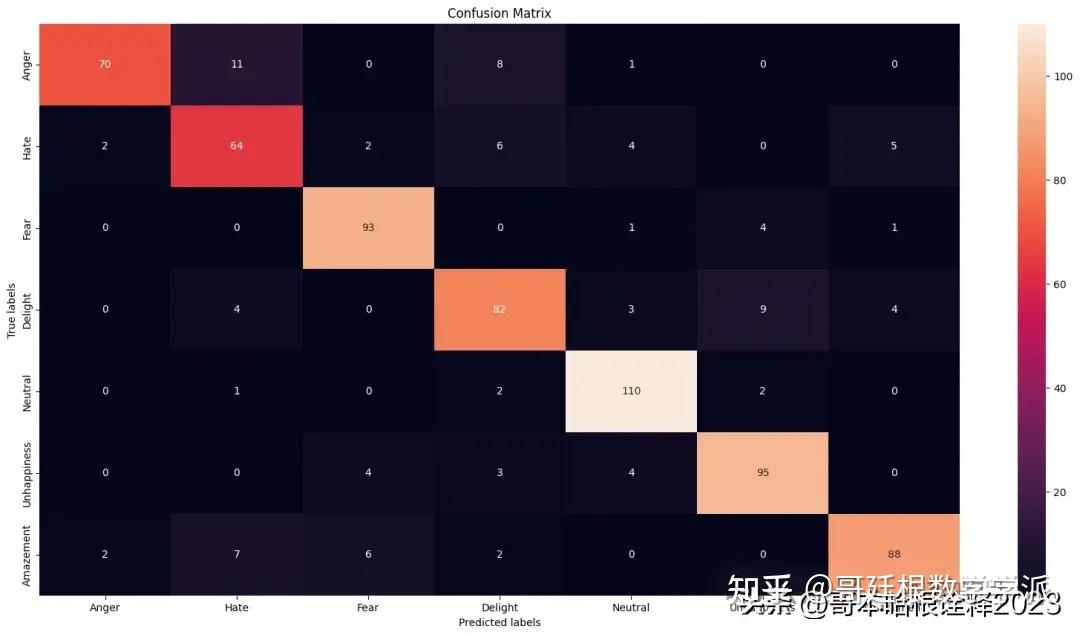
labels=['0: Anger', '1: Hate', '2: Fear', '3: Delight', '4: Neutral', '5: Unhappiness', '6: Amazement']
print(classification_report(y_test2, y_pred2, labels=[0,1,2,3,4,5,6]))
precision recall f1-score support
0 0.95 0.78 0.85 90
1 0.74 0.77 0.75 83
2 0.89 0.94 0.91 99
3 0.80 0.80 0.80 102
4 0.89 0.96 0.92 115
5 0.86 0.90 0.88 106
6 0.90 0.84 0.87 105
micro avg 0.86 0.86 0.86 700
macro avg 0.86 0.85 0.86 700
weighted avg 0.86 0.86 0.86 700
samples avg 0.86 0.86 0.86 700学术咨询:
担任《Mechanical System and Signal Processing》《中国电机工程学报》等期刊审稿专家,擅长领域:信号滤波/降噪,机器学习/深度学习,时间序列预分析/预测,设备故障诊断/缺陷检测/异常检测。
分割线分割线分割线分割线分割线分割线分割线分割线分割线
基于门控卷积单元增强的Transformer编码器NASA涡扇发动机退化仿真数据集剩余使用寿命RUL预测(Python)
python==3.8.8
numpy==1.20.1
pandas==1.2.4
matplotlib==3.3.4
pytorch==1.8.1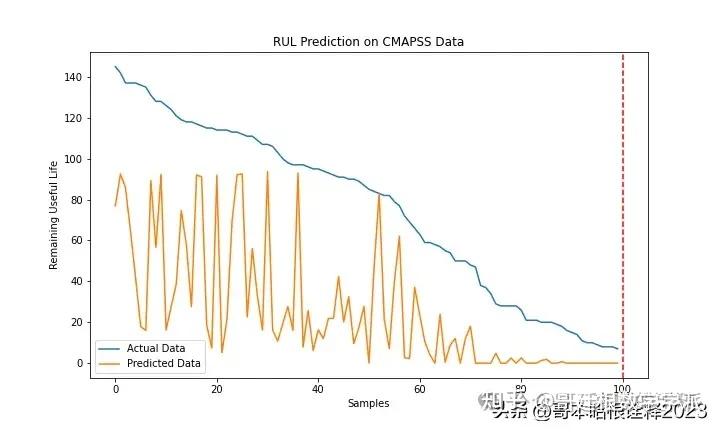
完整代码通过学术咨询获得: