目录
本章代码坐标:redis 缓存策略

缓存简单介绍
用户的数据一般都是存储于数据库,数据库的数据是落在磁盘上的,磁盘的读写速度非常慢。在高并发的情况下,需要对数据库进行庞大的 CRUD,很容易导致数据库崩溃。所以为了避免用户直接访问数据库,一般都会用 Redis 作为缓存层。
Redis 是基于内存的,我们可以将数据库的数据缓存在 Redis 里,相当于数据缓存在内存,内存的读写速度比硬盘快好几个数量级。这样用户在访问数据的情况下,可以直接在缓存中获取,这样大大提高了程序的运行效率,也在一定程度上降低了数据库的访问压力。
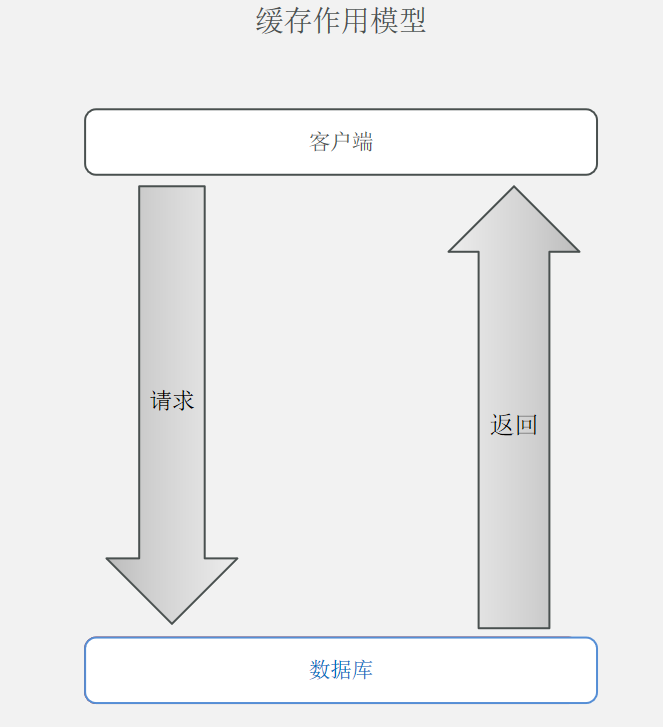
总结:缓存就是数据交换的缓冲区,是存贮数据的临时地方,一般读写性能较高。
缓存的作用:
| 缓存作用 |
|---|
| 降低后端负载 |
| 提高读写效率,降低响应时间 |
缓存虽好,但是需要考虑的东西可不少:
| 缓存的成本 |
|---|
| 数据一致性成本 |
| 代码维护成本 |
| 运维成本 |
这里先简单提一下数据的一致性,数据的一致性主要发生在用户修改数据库的数据后,redis 来不及更新所造成缓存数据与数据库数据不一致的问题。关于怎么解决,请看以下分解。
缓存更新策略
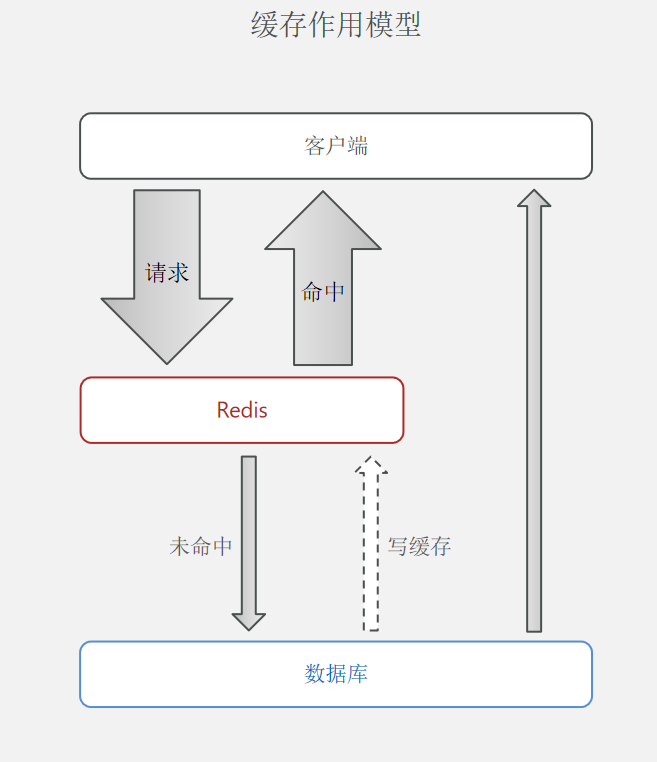
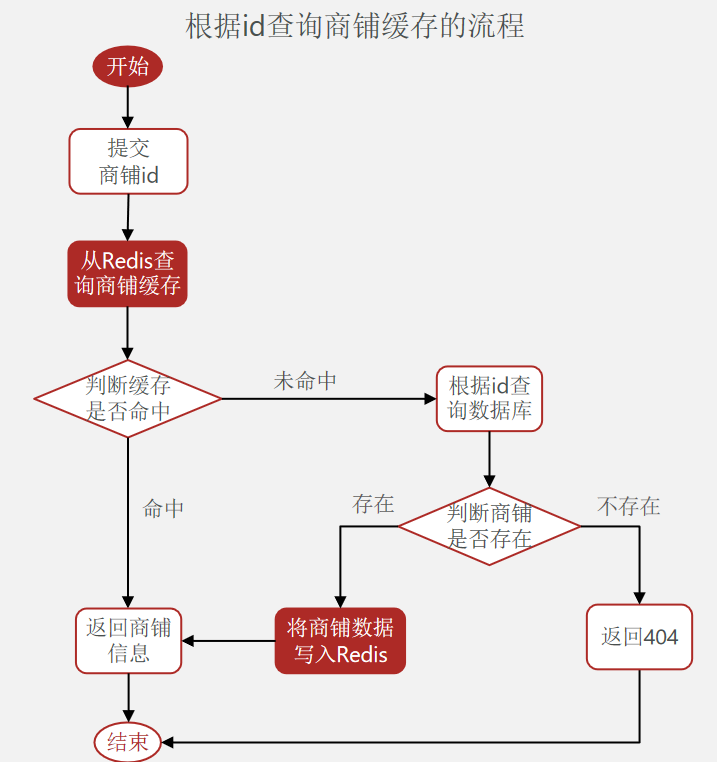
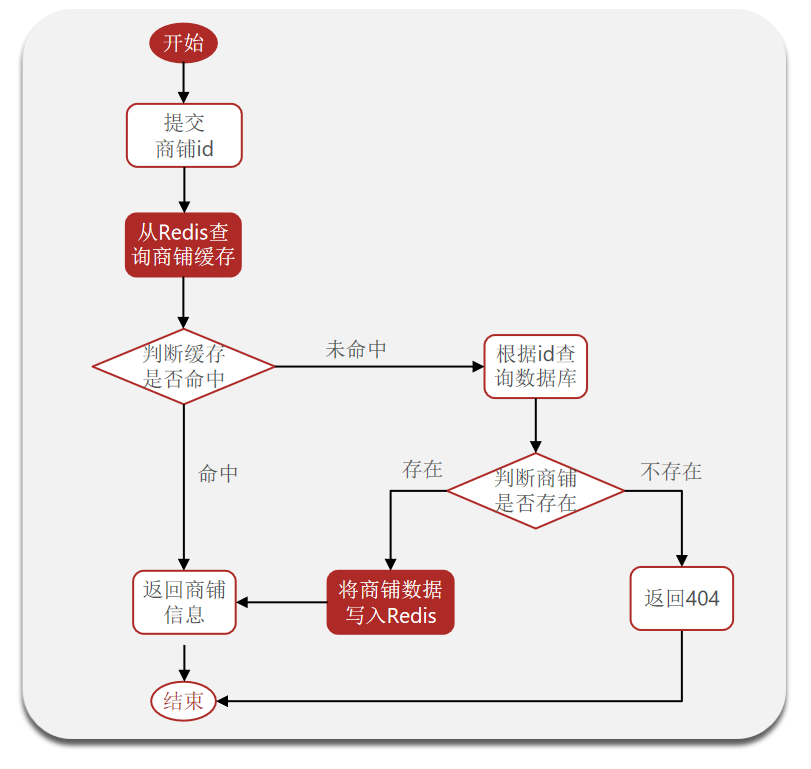
在请求达到后端之后,对需要进行缓存的接口,会先去 Redis 中找有无数据,没有的话会继续走正常的业务流程,会去查询数据库的信息然后将查询到的结果返回给客户端的同时也放在 Redis 中一份,下次相同请求进来后,就可以直接从 Redis中拿到数据。如果数据库中也没有这个请求信息,则说明这是一个 “非法” 请求,需要返回404之类的提示信息。
在进行缓存之后,相同的请求在缓存时间内是不会去读取数据库的,但是此时如果修改了数据库,则接口返回的数据就不能保证和数据库一致,因此在增、删、改时我们需要刷新(更新)缓存。
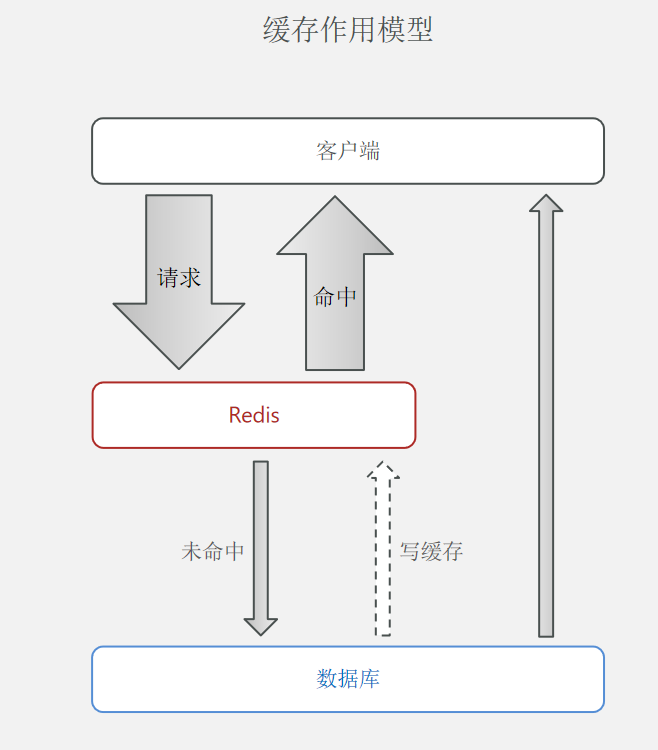
缓存更新需求
缓存更新是 redis 为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向 redis 插入太多数据,此时就可能会导致缓存中的数据过多,所以 redis 会对部分数据进行更新,或者把他叫为淘汰更合适。
缓存更新的策略有很多,这里比较三种情况:
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不用自己维护,利用 Redis 的内存淘汰机制,当内存不足时自动淘汰部分数据。下次查询时更新缓存。 | 给缓存数据添加TTL时间,到期后自动删除缓存。下次查询时更新缓存。 | 编写业务逻辑,在修改数据库的同时,更新缓存。 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
业务场景:
低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存。
高一致性需求:主动更新,并以超时剔除作为兜底方案。例如店铺详情查询的缓存。
数据库缓存不一致解决方案
由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的。因此,如果当数据库中数据发生变化,而缓存却没有同步;此时就会有一致性问题存在。其后果是:用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,从而影响业务,产品口碑等。那么该如何解决呢?
这里有三个问题需要考虑:
先操作缓存还是先操作数据库? |
|---|
| 先删除缓存,再操作数据库 |
| 先操作数据库,再删除缓存 |
先删除缓存,再操作数据库
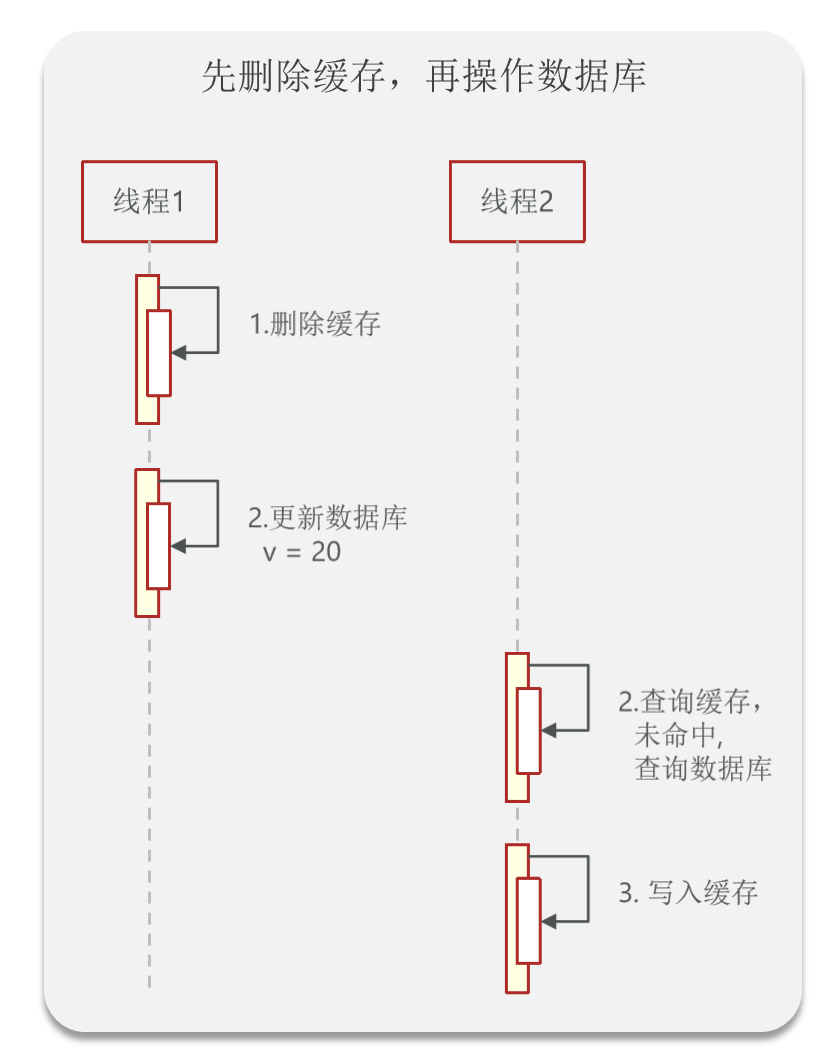
首先以上步骤是正常情况,一个线程先删除缓存,在更新数据库,另一个线程开始查询的时候写入缓存。这是很理想的状态。
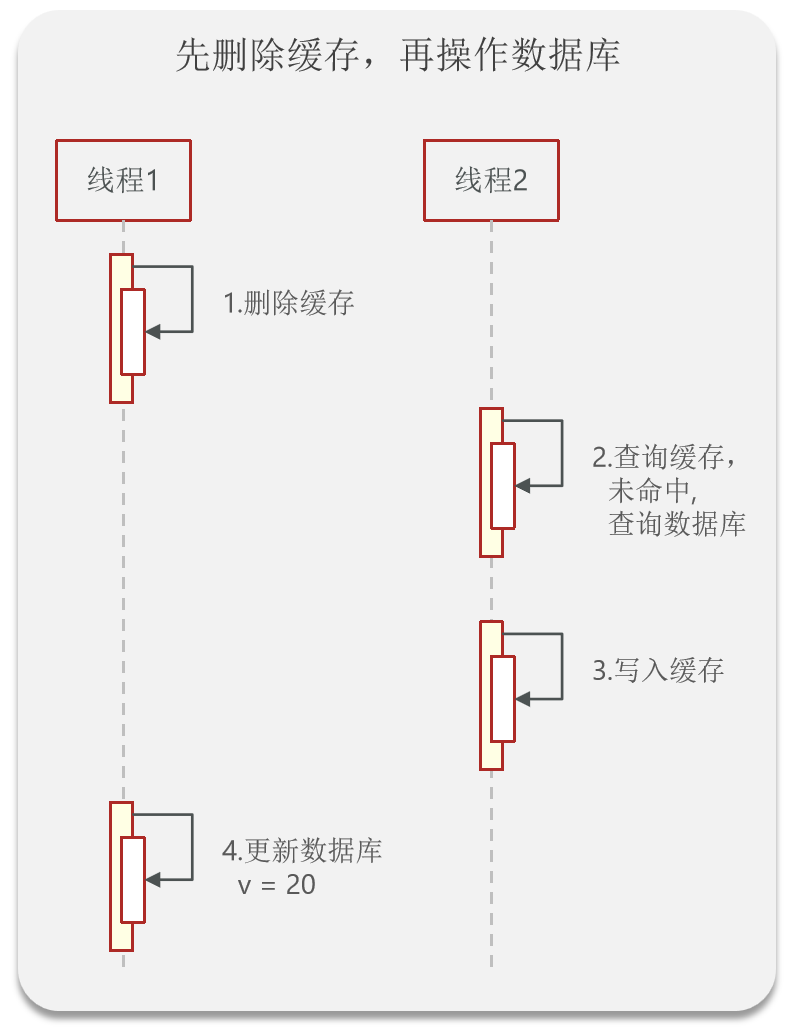
但是注意,因为数据库的操作是基于硬盘的,所以 CRUD 的效率是很慢的,在这个空档期很容易被其他线程趁虚而入。比如还没来得及更新数据库,另一个线程直接去进行查询操作,发现没有缓存,操作数据库后将旧数据写入缓存。虽然数据库后面更新了,但是缓存仍然是旧数据。这就导致数据的不一致。
先操作数据库,再删除缓存
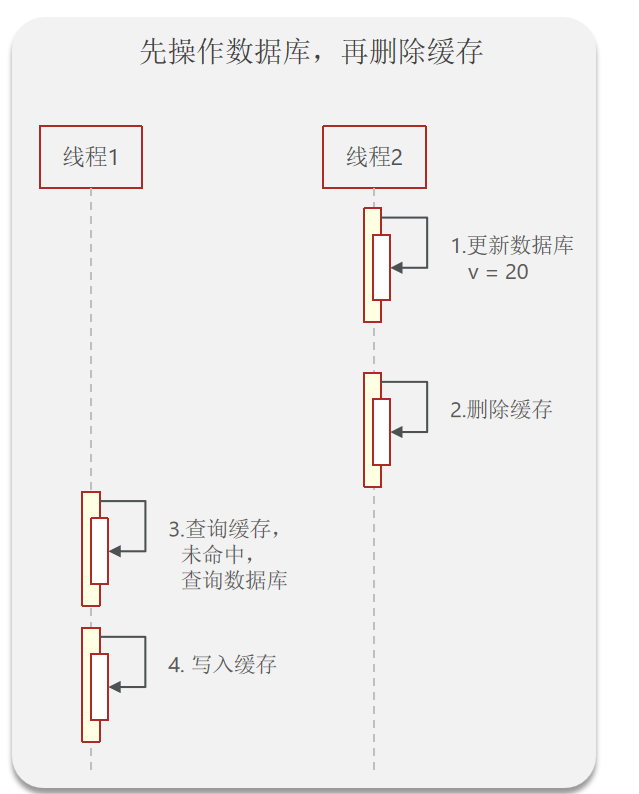
以上的步骤是正常情况,一个先更新数据库,在删除缓存,另一个线程再次访问的时候没有命中缓存就会去查询数据库,并将查询的结果写入缓存(查询结果存在的情况下)。
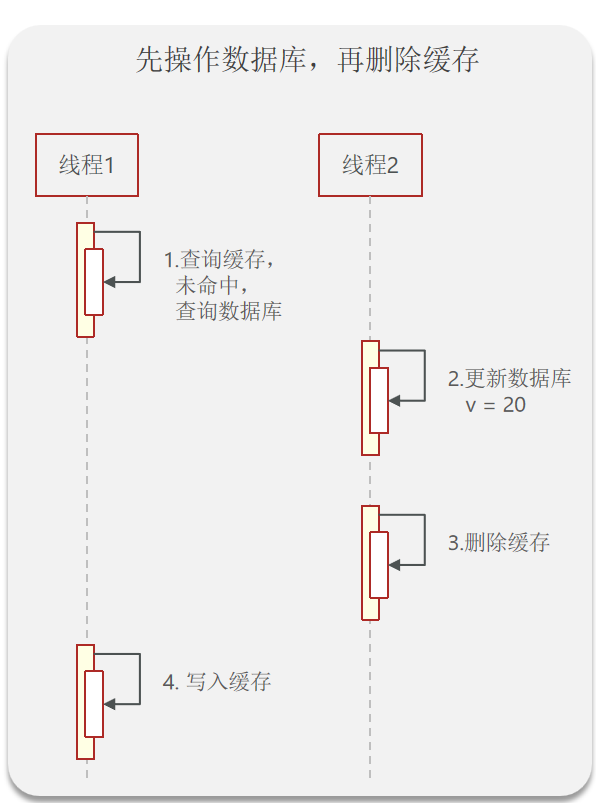
但是这个方法依然有可能会发生线程安全问题:一个线程查询数据的时候,恰好缓存的有效期过了,所以缓存没有命中正准备去操作数据库。偏偏在这个时候另一个线程将数据库中的值给修改了。此时,轮到第一个线程进行操作将旧的数据写入内存。这样就导致了缓存数据与数据库数据不一致。
总结
虽然以上两种方法都存在线程安全的问题,但是想要满足 “先操作数据库,再删除缓存” 发生的条件是不容易的。(1) 需要缓存的有效期突然失效;(2) redis是基于内存的,运行速度快,而操作数据库是基于硬盘的,运行速度是很慢的。所以出现在操作缓存的时间中,成功操作数据库的情况是十分少的。
所以我们一般选着先操作数据库再删除缓存。
删除缓存还是更新缓存? |
|---|
| 更新缓存:每次更新数据库都更新缓存,无效写操作较多 |
| 删除缓存:更新数据库时让缓存失效,查询时再更新缓存 |
这里我们采用删除缓存的方法,原因如下:
| 原因 | 删除缓存 | 更新缓存 |
|---|---|---|
| 数据一致性 | 直接更新缓存可能导致缓存与数据库之间的数据不一致。如果在更新缓存的同时有其他请求正在读取或修改数据库,就可能出现数据不一致的情况。 | 删除缓存后,下一次读取会从数据库中获取最新数据,从而保证数据的一致性。 |
| 简化操作 | 更新缓存需要处理缓存中的数据结构,这可能比简单地删除缓存更复杂。 | 删除缓存后,可以避免复杂的同步逻辑,简化系统的维护。 |
| 避免竞态条件 | 在高并发的系统中,多个进程或线程可能同时操作缓存和数据库。如果直接更新缓存,可能会出现竞态条件,导致数据不一致。 | 删除缓存可以减少这种风险。 |
由于更新缓存的操作比较复杂、维护成本较高、还容易发生高并发问题。我们最好使用删除缓存这种方法。
保证缓存与数据库的操作的同时成功或失败 |
|---|
| 单体系统,将缓存与数据库操作放在一个事务。 |
| 分布式系统,利用TCC等分布式事务方案。 |
在更新数据库和Redis时,我们需要保证操作的原子性,即要么全部成功,要么全部失败。 否则,可能导致部分更新成功,数据不一致。 解决方法如上,在单体系统中采用事务机制,即可在操作失误时,回滚之前的已经做过的操作,保证操作原子性;在分布式系统中也可以采用相应的分布式事务进行操作。
代码实现与调试
【更新店铺缓存流程】
-
更新商铺信息 -> 访问数据库并修改信息
-
删除 redis 缓存
-
根据 id 查询数据库
-
更新商铺缓存
-
这里再提一点:因为 redis 缓存是基于内存的,而内存的空间十分有限,所以我们一般需要给缓存设置一个有效期,让那些不是热点的缓存(基本上没用户访问的)不再占用内存空间。
Controller
// 根据 id 查找商铺
@GetMapping("/{id}")
public Result queryShopById(@PathVariable("id") Long id) {
return Result.ok(shopService.getById(id));
}
// 更新商铺信息
@PutMapping
public Result updateShop(@RequestBody Shop shop) {
// 写入数据库
shopService.update(shop);
return Result.ok();
}
public class RedisConstants {
public static final Long CACHE_SHOP_TTL = 30L;
public static final String CACHE_SHOP_KEY = "cache:shop:";
}Serivce
@Override
public Result getById(Long id){
Shop shop = updateRedis(id);
if (shop == null){
return Result.fail("商铺信息不存在");
}
// 返回
return Result.ok(shop);
}
// 更新缓存代码
public Shop updateRedis(Long id){
// 从 redis 查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY+id);
// 判断 redis 是否存在商铺信息
if(StrUtil.isNotBlank(shopJson)){
// 存在直接返回
log.debug("redis 存在数据缓存,直接返回");
return JSONUtil.toBean(shopJson,Shop.class);
}
// 缓存不存在,根据 id 查询数据库
Shop shop = baseMapper.selectById(id);
if(shop == null){
log.debug("商铺信息不存在");
// 数据库信息不存在,返回null
return null;
}
// 存在将商铺信息写入 redis, 并设置有效期
log.debug("将数据库数据写入 redis 缓存");
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL , TimeUnit.MINUTES);
return shop;
}
// 删除缓存代码
@Override
@Transactional
public Result update(Shop shop) {
// 判断店铺是否存在
Long id = shop.getId();
if(id==null){
return Result.fail("店铺id不能为空");
}
// 更新数据库
updateById(shop);
// 删除缓存
log.debug("删除缓存");
stringRedisTemplate.delete(CACHE_SHOP_KEY+id);
return Result.ok();
}代码调试:
此时 redis 只有一个用户的 token 数据。
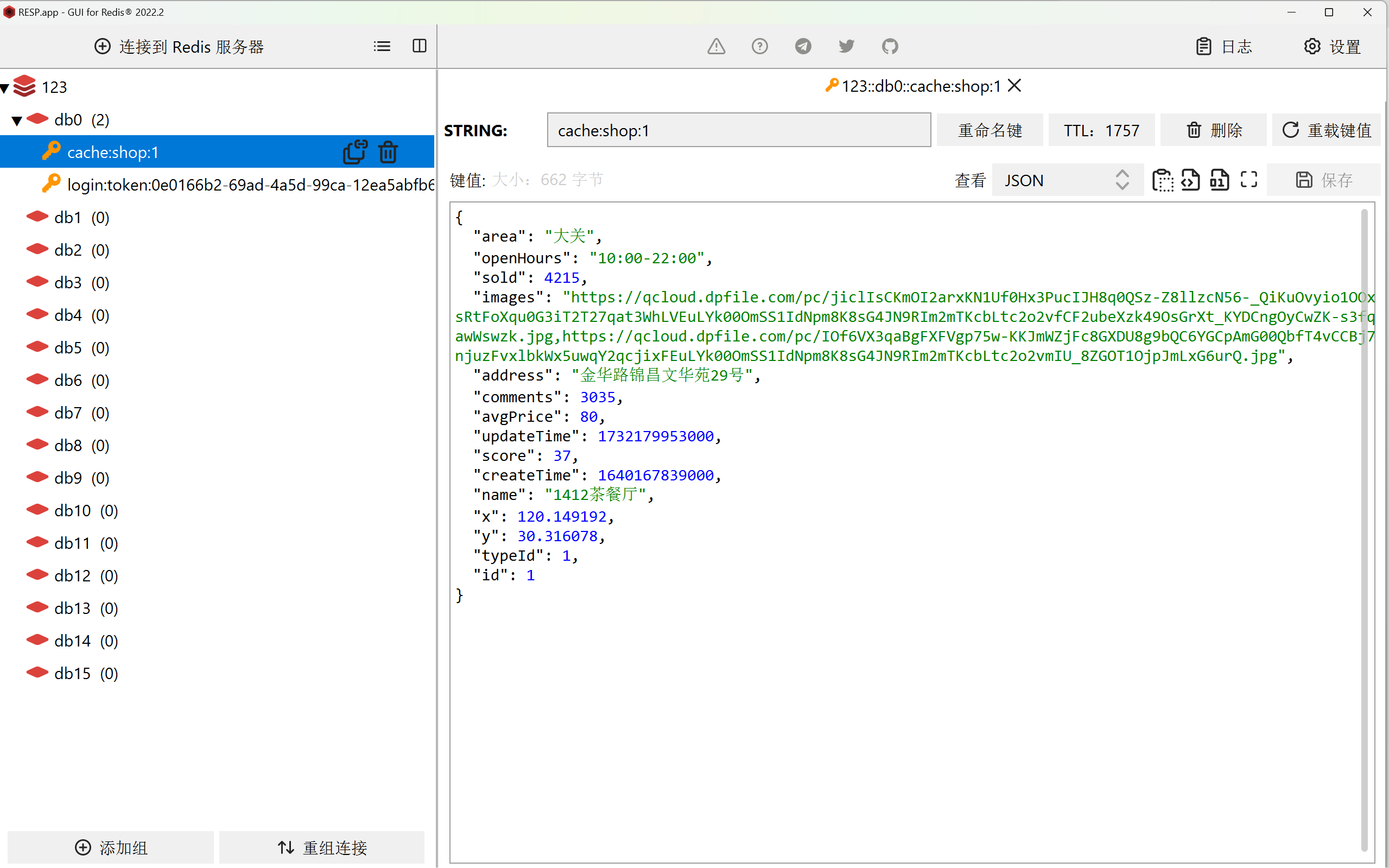
当我们点击1412餐厅时,数据库将数据写入缓存,于是 redis 数据库就可以看见了。
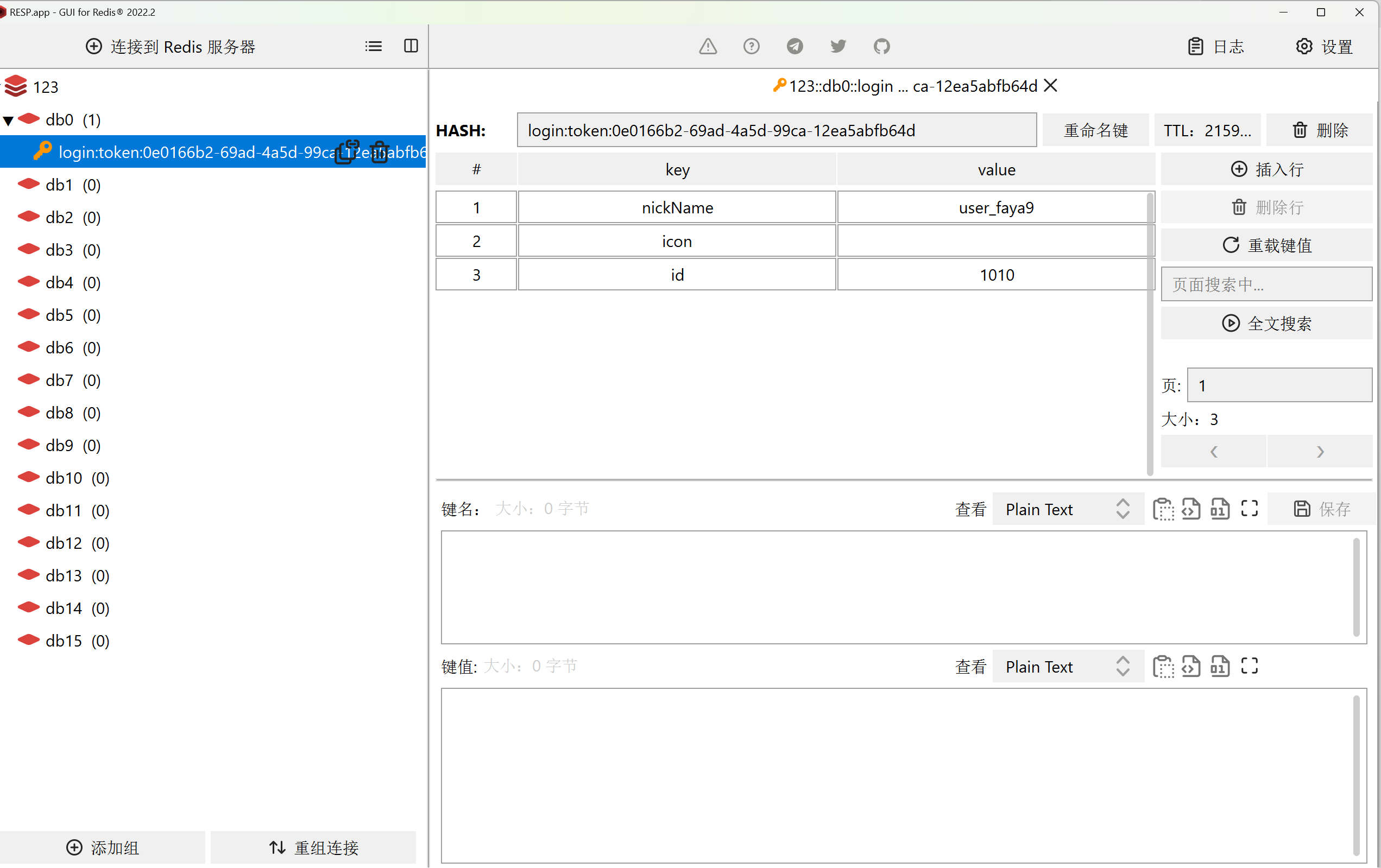
此时我们使用 postman 给后端发送更新请求,将餐厅名字改成520餐厅。
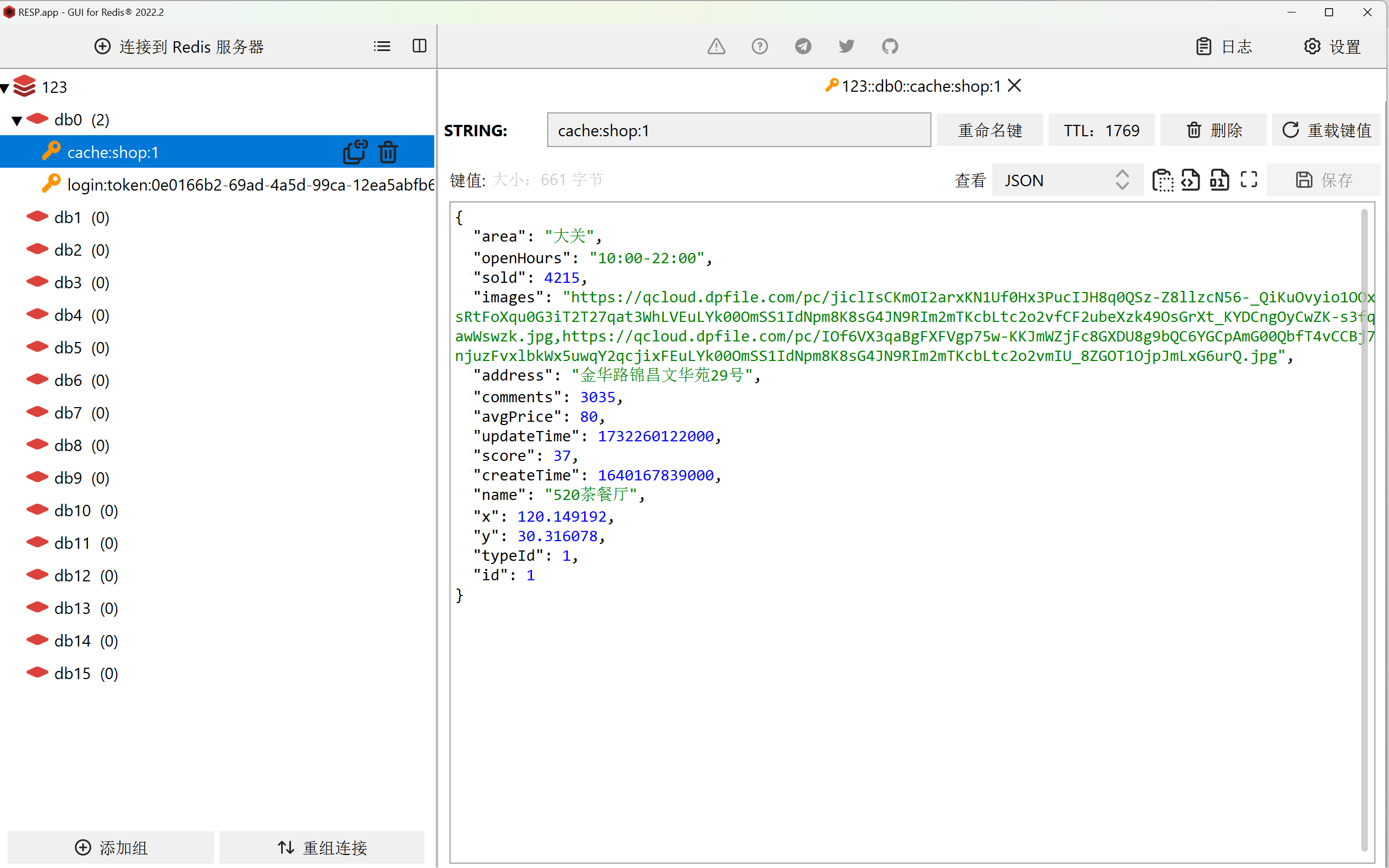
缓存穿透策略
缓存穿透介绍
当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,于是这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,可能会导致数据库的崩溃。
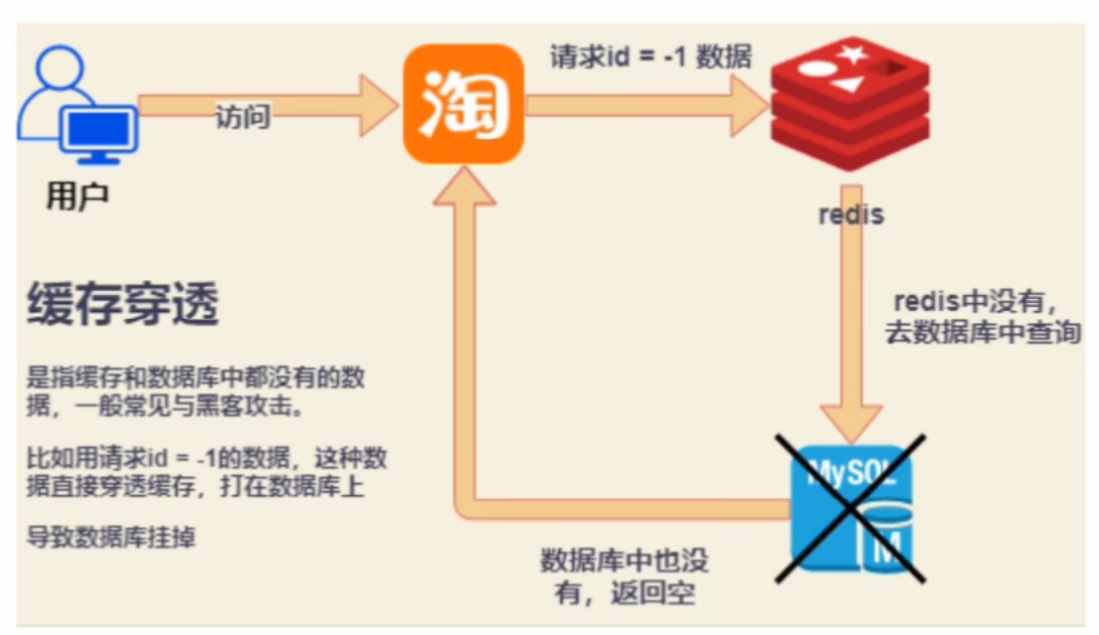
举个例子:
淘宝的一家商铺十分火爆,动了某些人的蛋糕,于是就遭到黑客的攻击,而攻击的方式则可能是缓存穿透。数据库的主键Id都是从0开始自增的,而黑客就利用这一点,不断使用小于0的参数给后端发送请求:而 redis 中并没有Id小于0的数据,则这个请求就会打在(操作)数据库上,而数据库中也肯定是没有的,就会给前端返回 404 相关的报错信息。因为redis不能拦截请求,所以redis给这样的数据给 “穿透” 了,直接穿透到数据库的里面。导致数据库的崩溃。
总结:缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
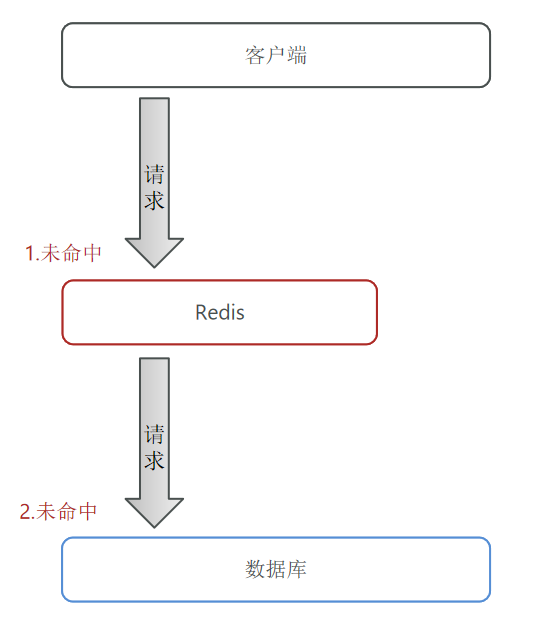
遇到这类情况,我们可以采取很多措施,比如对增强id的复杂度,避免被猜测id规律,对 id 进行校验,做好热点参数的限流,当网站遭到缓存穿透时立刻拉黑该用户的IP等等。虽然这些措施可以有效的防范一定的缓存击穿,但是还不能真正的解决问题。
缓存穿透的解决方式
缓存空对象 |
|---|
| 优点:实现简单,维护方便 |
| 缺点: * 额外的内存消耗 * 可能造成短期的不一致 |
缓存空对象思路分析
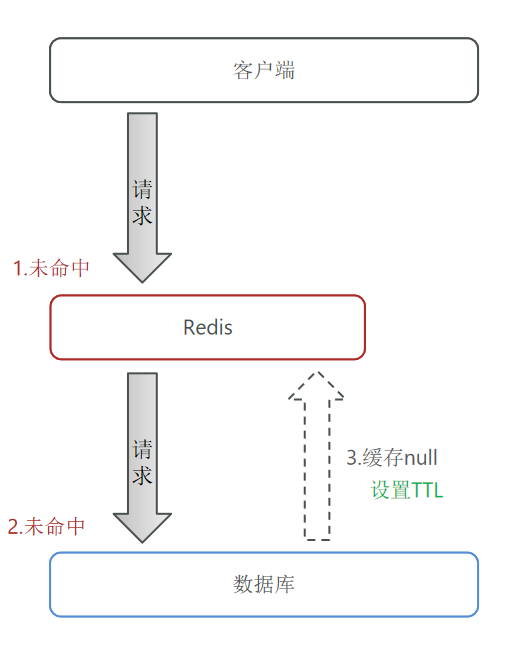
缓存空对象:哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去。这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到数据库了。
实现流程
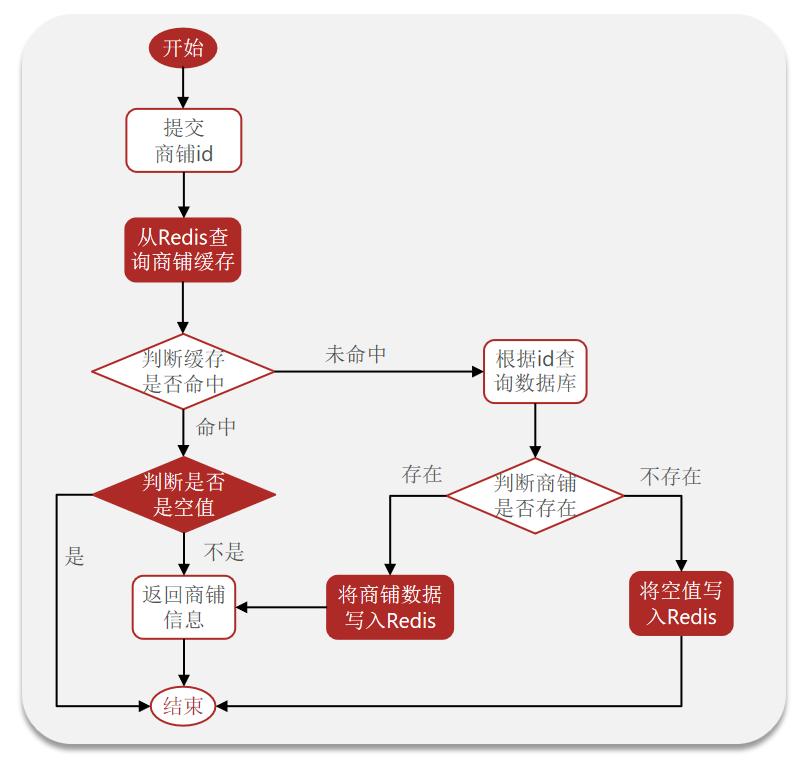
【防止缓存穿透流程】
-
缓存未命中根据id查询数据库
-
如果数据库中存在该信息,就将其写入缓存
-
如果数据库不存在该信息,我们就将此id作为key将空值写入缓存中
-
当下次该使用该id作为参数进行查询时,便可直接返回缓存中的空值
代码实现
// 防范穿透的代码
public Shop queryWithPassThrough(Long id){
// 从 redis 查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY+id);
// 判断 redis 是否存在商铺信息
if(StrUtil.isNotBlank(shopJson)){
// 存在直接返回
log.debug("redis 存在数据缓存,直接返回");
return JSONUtil.toBean(shopJson,Shop.class);
}
// StrUtil.isNotBlank("") == false 过滤不了空值
// 防范 redis 穿透,判断
if(shopJson != null){
// 返回错误信息
log.info("防范穿透的处理");
return null;
}
// 不存在,根据 id 查询数据库
Shop shop = baseMapper.selectById(id);
if(shop == null){
log.debug("商铺信息不存在");
// 防范 redis 穿透,将空值写入数据库
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id,"",CACHE_NULL_TTL,TimeUnit.MINUTES);
return null;
}
// 存在将商铺信息写入 redis
log.debug("将数据库数据写入 redis 缓存");
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY+id, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL , TimeUnit.MINUTES);
return shop;
}以上的方法虽然可以缓解同一个非法key对数据库的连续攻击,但是如果攻击者不断使用多个随机的key进行访问;也还是会存在相同的问题,所以我们可以使用布隆过滤器来实现。
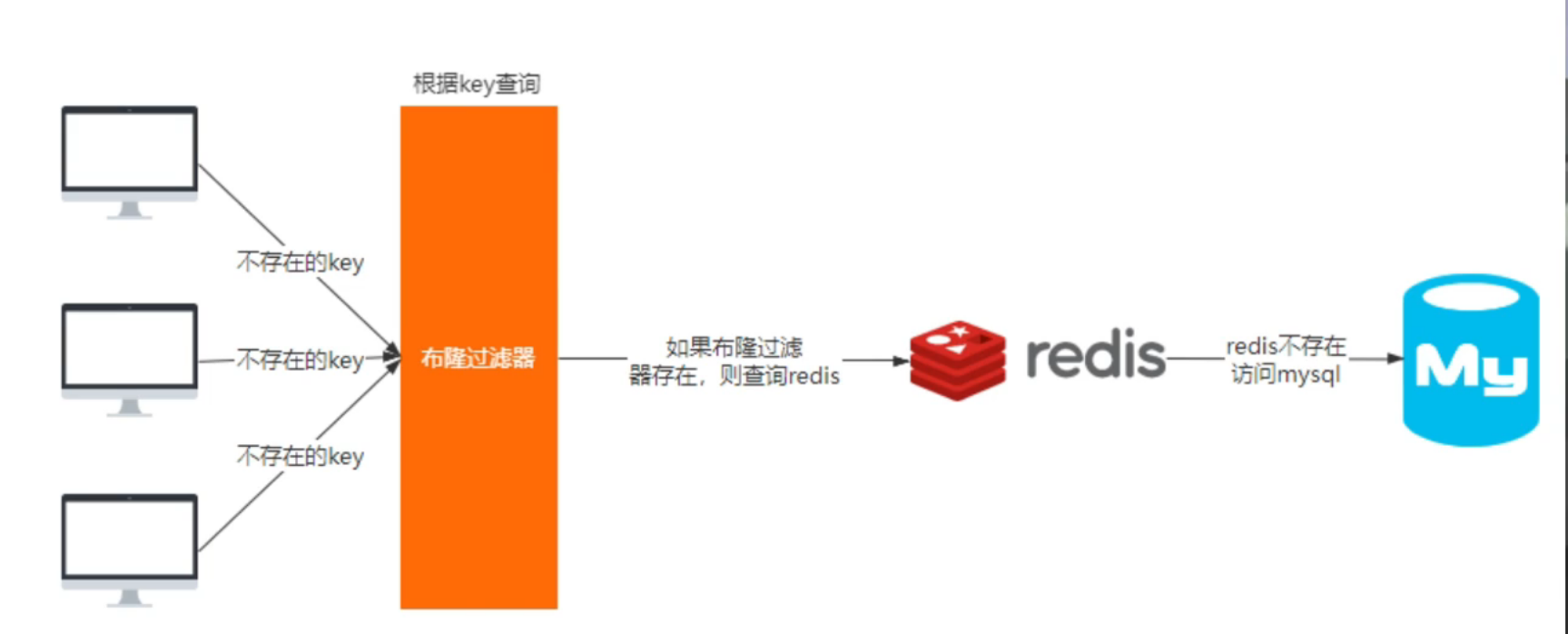
我们把所有的请求key全部缓存到布隆过滤器里面,当攻击者使用不同的key来进行请求的时候;先去布隆过滤器中进行查询,如果不存在,则意味着这个key肯定在数据库中也不存在,所以这个时候就不会去访问数据库。
布隆过滤 |
|---|
| 优点:内存占用较少,没有多余 key |
| 缺点: * 实现复杂 * 存在误判可能 |
布隆过滤器的实现原理
Redis 实现布隆过滤器的底层就是通过 bitmap 这种数据结构:

布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,走哈希思想去判断当前这个要查询的数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中。(这里有误,如果发生误判,该数据可能不存在于数据库)假设布隆过滤器判断这个数据不存在,则直接返回。
这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突。
映射一个值到布隆过滤器
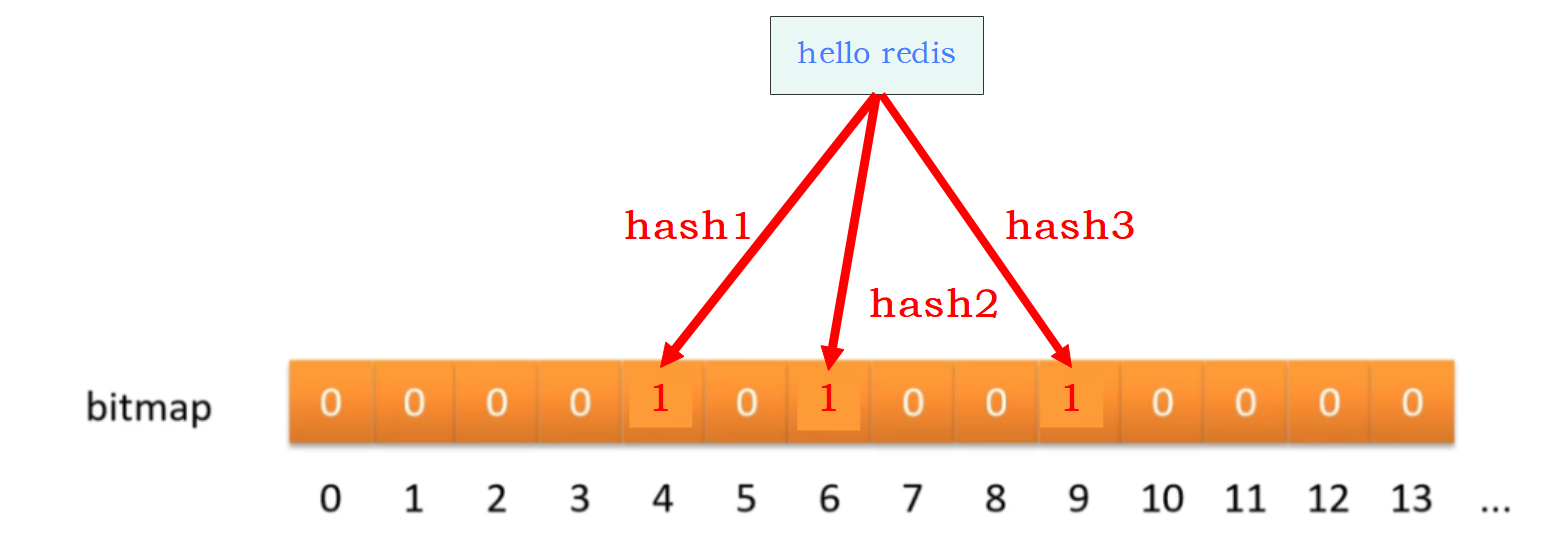
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的位置设置为 1。如下图,针对 "hello redis" 它需要经历三个哈希函数(根据实际情况而定),这三个哈希函数会计算出三个哈希值,他就会把三个哈希值映射到数组里面去。比如说,hash1算出的结果为4,他就会把数组4的位置设置为1,其他同理。这样的话,"hello redis" 这个数据就算存到了布隆过滤器中。
判断值是否存在布隆过滤器
也就是说 "hello redis" 会在下标 4、6、9 这些位置表示 "hello redis" 这个数据。
举个例子:
“hello world” 的哈希函数返回了 4、7、9 三个值,结果我们发现 7 这个位置值是0,说明没有任何一个值映射到这个位置,我们就可以很明确的知道,这个 "hello world" 不存在与数据库中。
如果需要查询 "hello redis" 这个值是否存在,则需要判断返回的 4、6、9 三个值,我们发现这三个值都为 1,那么就能确定这个 "hello redis" 一定存在于数据库吗?答案是否定的,我们只能说可能存在。因为随之存入的数据越来越多,就会发生哈希冲突。
如下图,如果此时有别的值刚好映射到这个位置,就会间接的帮助我们的 “hello world” 逃过检查,此时就会去操作数据库。这个这也是我之前所说的误判。
哈希冲突是避免不了的,我们只能通过扩容等操作来缓解这种冲突,来保证容错率;然而这些操作也是十分消耗性能的。关于设置怎样的容错率还需要根据场景的需求来决定。
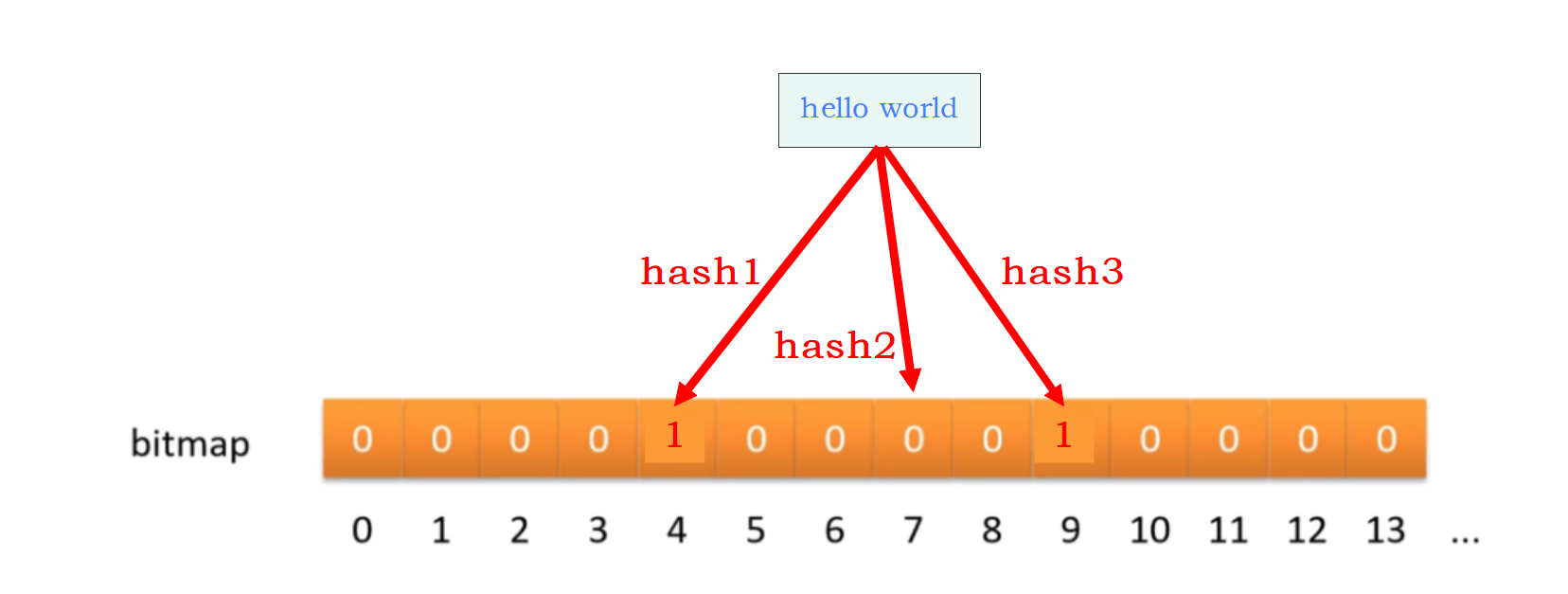
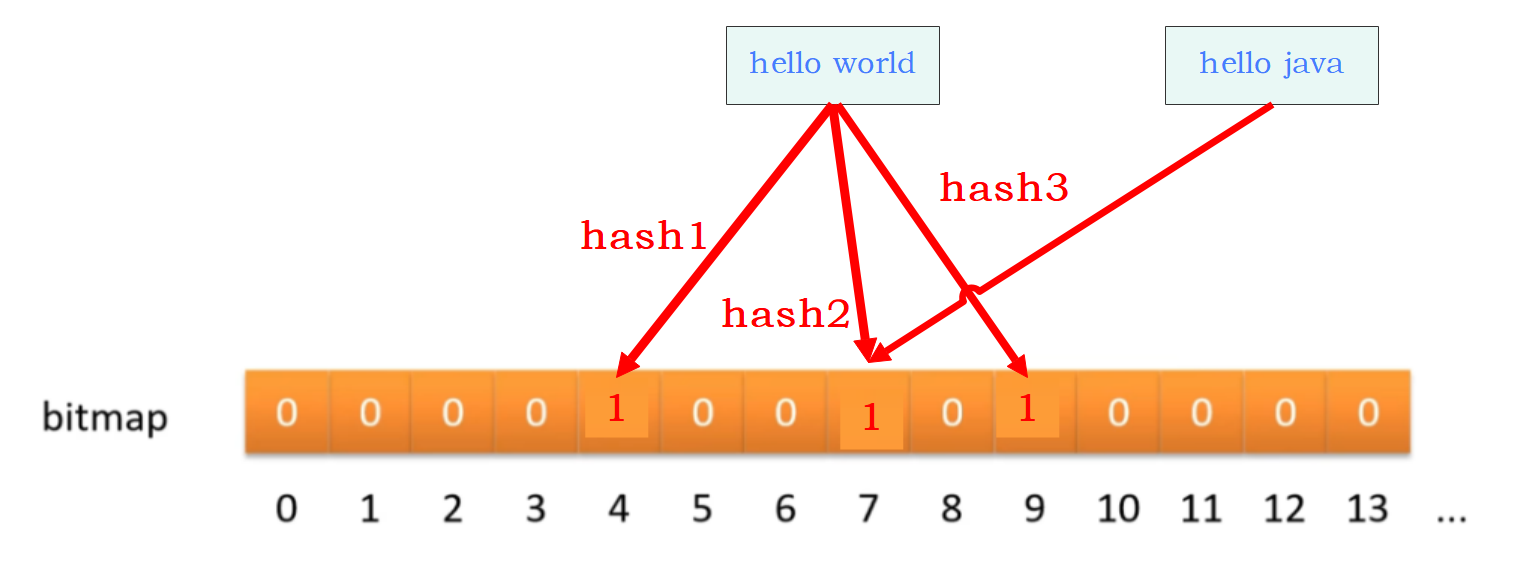
总结:(1)要求所有的映射位置都为1,才能判断这个值可能存在于数据库;如果有一个不为1,那么肯定不存在于数据库。(2)在数据量大的情况下,会产生哈希冲突,从而造成误判。
误判的其他例子:

布隆过滤器的相关代码
package com.ys.rediscluster.bloomfilter.redisson;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("你的redis ip");
config.useSingleServer().setPassword("你的 redis 密码");
// 构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("phoneList");
// 初始化布隆过滤器:预计元素为100000000L,误差率为3%
bloomFilter.tryInit(100000000L,0.03);
// 将号码10086插入到布隆过滤器中
bloomFilter.add("10086");
// 判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("123456"));//false
System.out.println(bloomFilter.contains("10086"));//true
}
}这是单节点的 Redis 实现布隆过滤器的方式,如果数据量比较大,期望的误差率又很低,那单节点所提供的内存是无法满足的,这时候可以使用分布式布隆过滤器。
缓存雪崩策略
缓存雪崩介绍
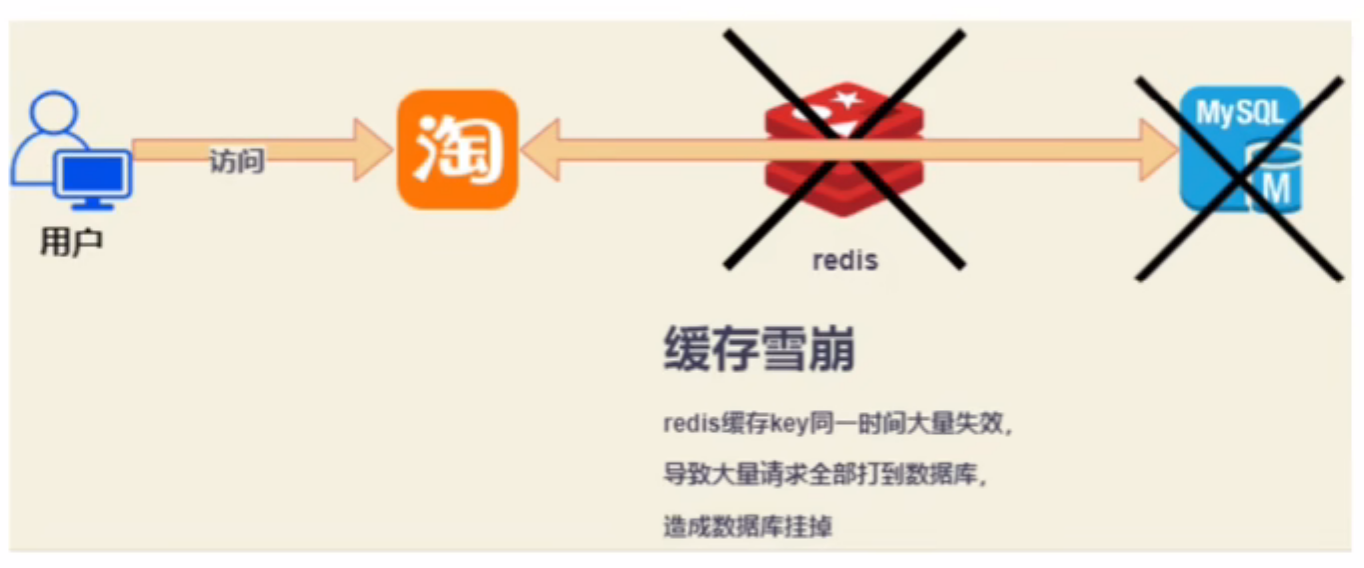
缓存雪崩是指在某一时刻,大量缓存同时失效,导致大量请求直接打到数据库层,造成数据库压力骤增,甚至可能导致数据库崩溃、系统不可用的情况。
造成缓存雪崩的原因:
同一时段大量的缓存 key 同时失效 Redis 服务宕机
解决缓存雪崩的方法
针对同一时段大量的缓存 key 同时失效
(1) 设置缓存失效时间,让它们不要在同一时间失效,在设置缓存的失效时间的时候,我们可以随机初始化失效时间,这样就不会让缓存在同一时间失效,将缓存打在数据库上
(2) 设置定时任务,定时的去刷新缓存
(3) 不设置缓存失效的时间,一般针对热点key
(4) 给一个热点业务添加多级缓存
(5) redis 一般都是集群部署,我们把热点 key 放在不同的节点上去,让这些热点的缓存平均分布在不同的 redis 的节点上
(6) 发现访问的数据不在Redis中,加上互斥锁,保证同一时间内只有一个请求来构建缓存
Redis 服务宕机
(1) 启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误,暂停使用数据库,等Redis恢复正常后,在允许业务应用缓存服务
(2) 启动请求限流机制,只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务
(3) 如果 redis 的一个节点故障宕机,从该节点可以切换成为另一个节点,继续提供缓存服务
缓存击穿策略
缓存击穿介绍

缓存击穿是一个热点的key问题,有大量并发请求集中对一个服务进行访问,突然间这个缓存的key突然失效了,导致大量并发请求全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
缓存击穿的解决方法
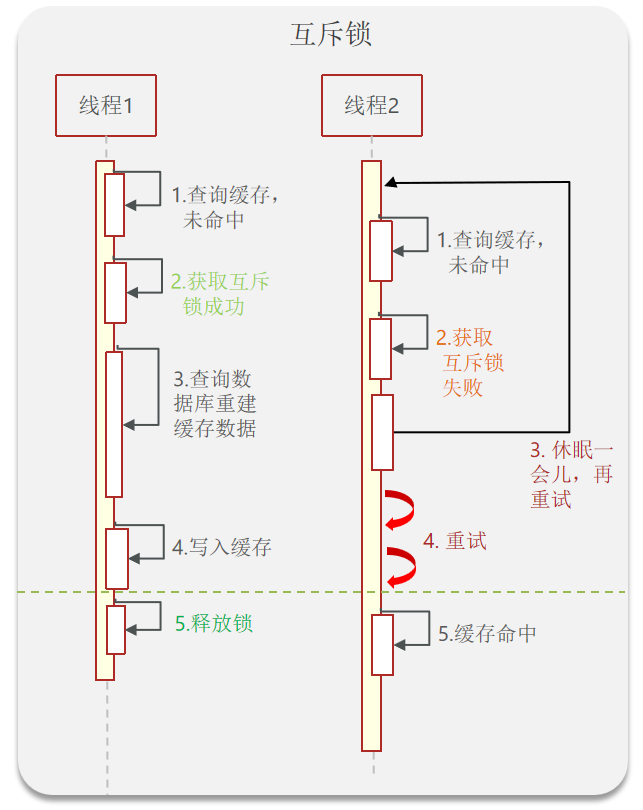
互斥锁 |
|---|
| 假设现在线程1过来访问,他查询缓存没有命中,但是此时他获得到了锁的资源,那么线程1就会一个人去执行逻辑,假设现在线程2过来,线程2在执行过程中,并没有获得到锁,那么线程2就可以进行到休眠,直到线程1把锁释放后,线程2获得到锁,然后再来执行逻辑,此时就能够从缓存中拿到数据了。 |
互斥锁的代码方式
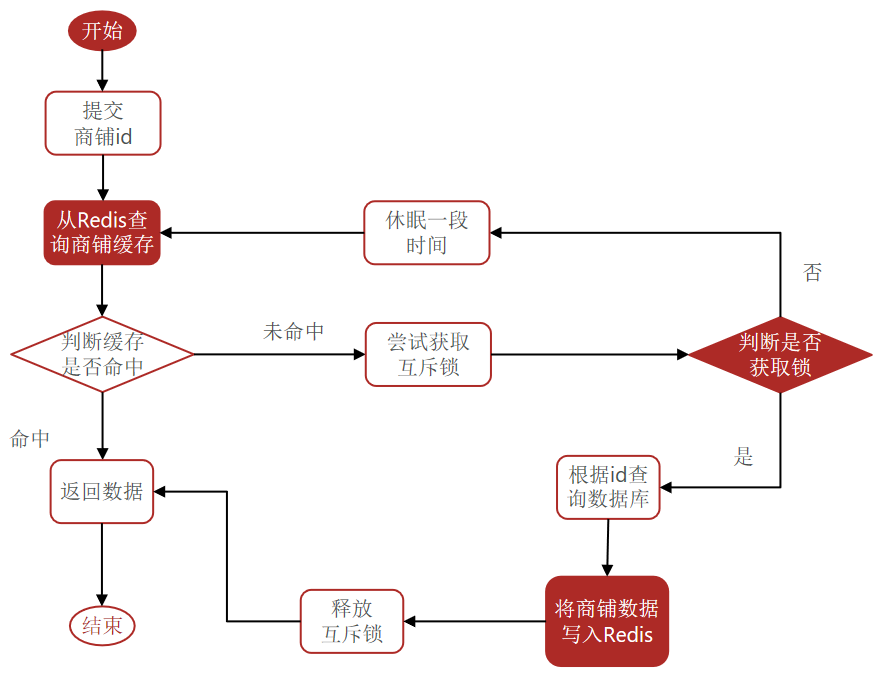
相较于原来从缓存中查询不到数据后直接查询数据库而言,现在的方案是进行查询之后,如果从缓存没有查询到数据,则进行互斥锁的获取,获取互斥锁后,判断是否获得到了锁,如果没有获得到,则休眠,过一会再进行尝试,直到获取到锁为止,才能进行查询。如果获取到了锁的线程,再去进行查询,查询后将数据写入redis,再释放锁,返回数据,利用互斥锁就能保证只有一个线程去执行操作数据库的逻辑,防止缓存击穿。
public class RedisConstants {
public static final Long CACHE_SHOP_TTL = 30L;
public static final String CACHE_SHOP_KEY = "cache:shop:";
public static final String LOCK_SHOP_KEY = "lock:shop:";
public static final Long LOCK_SHOP_TTL = 10L;
} // redis 自定义锁,加锁
private boolean tryLock(String key){
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key,"自定义锁",LOCK_SHOP_TTL , TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
// redis 自定义锁,解锁
private void unLock(String key){
stringRedisTemplate.delete(key);
}
// 防范击穿的代码(互斥锁)
public Shop queryWithMutex(Long id) {
// 从 redis 查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(CACHE_SHOP_KEY + id);
// 判断 redis 是否存在商铺信息
if (StrUtil.isNotBlank(shopJson)) {
// 存在直接返回
log.debug("redis 存在数据缓存,直接返回");
return JSONUtil.toBean(shopJson, Shop.class);
}
// StrUtil.isNotBlank("")// false
// 防范 redis 穿透,判断
if (shopJson != null) {
// 返回错误信息
log.info("防范穿透的处理");
return null;
}
// 1.缓存未命中,实现缓存重建
String LockKey = null;
Shop shop;
try {
// 2.获取互斥锁
LockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(LockKey);
// 3.判断是否获取成功
if (!isLock) {
// 没有获取到锁的线程阻塞等待
Thread.sleep(50);
queryWithMutex(id);
}
// 获取到锁的线程执行以下程序
// 不存在,根据 id 查询数据库
shop = baseMapper.selectById(id);
if (shop == null) {
log.debug("商铺信息不存在");
// 防范 redis 穿透,将空值写入数据库
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
// 存在将商铺信息写入 redis
log.debug("将数据库数据写入 redis 缓存");
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
// 4.释放掉锁
unLock(LockKey);
}
return shop;
}
由于保证了互斥性,所以数据一致,且实现简单,因为仅仅只需要加一把锁而已,也没其他的事情需要操心,所以没有额外的内存消耗,缺点在于有锁就有死锁问题的发生,且只能串行执行性能肯定受到影响。
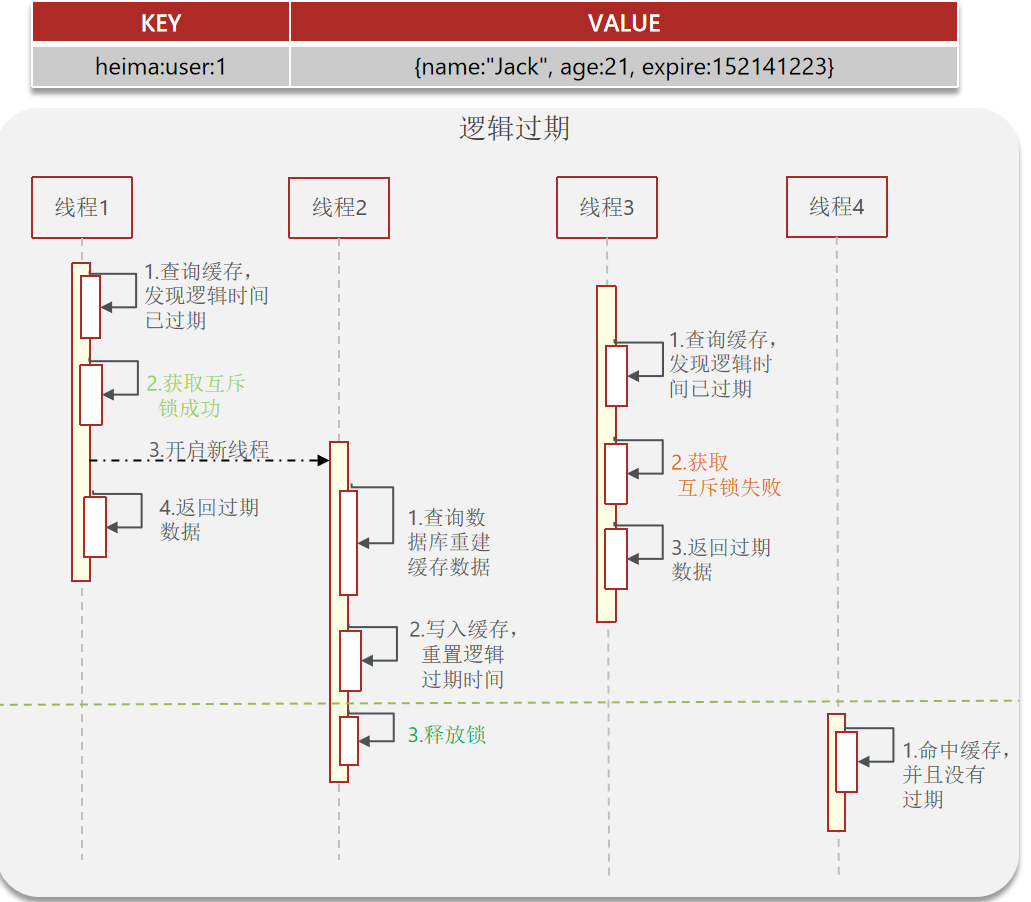
逻辑过期方案 |
|---|
| 我们把过期时间设置在 redis 的 value 中,这个过期时间并不会直接作用于redis,而是我们后续通过逻辑去处理。假设线程1查询缓存,未命中直接返回,命中判断是否过期,没过期直接返回数据;已过期,就会尝试获取锁,然后此刻开启新的线程进行缓存重建,线程1返回旧数据,其他线程获取锁失败都返回旧数据。 |
逻辑过期的代码方式

当用户开始查询 redis 时,判断是否命中,如果没有命中则直接返回空数据,不查询数据库,而一旦命中后,将 value 取出,判断 value 中的过期时间是否满足,如果没有过期,则直接返回 redis 中的数据,如果过期,则在开启独立线程后直接返回之前的数据,独立线程去重构数据,重构完成后释放互斥锁。
设置过期时间与重建缓存
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data;
} public void saveShop2Redis(Long id, Long expireSeconds){
RedisData redisData = new RedisData();
Shop shop = shopMapper.selectById(id);
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
stringRedisTemplate.opsForValue().set(RedisConstants.CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
} // 防范击穿的代码(逻辑过期)
// 用线程池创建10个线程
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
public Shop queryWithLogicalExpire (Long id){
// 查询 redis 的商铺缓存
String key = CACHE_SHOP_KEY + id;
String shopCache = stringRedisTemplate.opsForValue().get(key);
if(StrUtil.isBlank(shopCache)){
// 未命中返回null
return null;
}
// 命中缓存,检查是否过期
// 未过期,直接返回
// 需要先把 json反序列化为对象
RedisData redisData = JSONUtil.toBean(shopCache, RedisData.class);
JSONObject jsonObject = (JSONObject) redisData.getData();
Shop shop = JSONUtil.toBean(jsonObject, Shop.class);
// 取出过期时间
LocalDateTime expireTime = redisData.getExpireTime();
if(expireTime.isAfter(LocalDateTime.now())){
// 未过期,直接返回店铺
return shop;
}
// 过期,获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(lockKey);
if(isLock){
// 再次检查Redis缓存是否逻辑过期
if(expireTime.isAfter(LocalDateTime.now())){
// 没过期
return shop;
}
// 成功,开启独立线程,开启缓存重建
CACHE_REBUILD_EXECUTOR.submit(()->{
try {
// 重建缓存
this.saveShop2Redis(id, 20L);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
unLock(lockKey);
}
});
}
// 返回数据
return shop;
}
// redis 自定义锁,加锁
private boolean tryLock(String key){
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key,"自定义锁",LOCK_SHOP_TTL , TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
// redis 自定义锁,解锁
private void unLock(String key){
stringRedisTemplate.delete(key);
}
线程读取过程中不需要等待,性能好,有个额外的线程持有锁去进行重构数据,但是在重构数据完成前,其他的线程只能返回之前的数据,导致缓存数据与数据库数据不一致;且实现起来比较麻烦。