文章目录
前言
本文仅供学习参考
- 还原sign参数算法_思路
以下是本篇文章正文内容
一、合理猜测sign加密方法
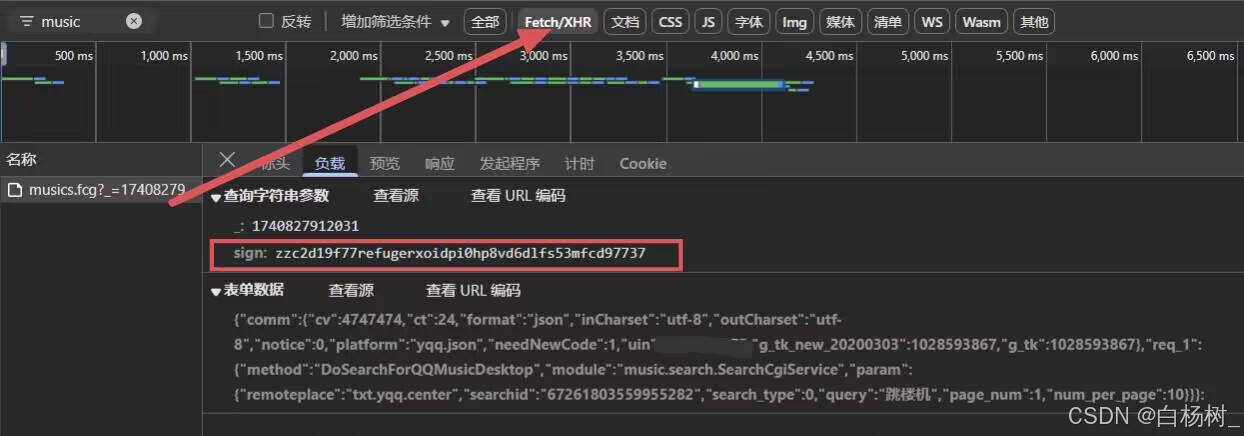
打印sign长度为45位,不是常见加密方法结果的长度。
(md5一般为32位,sha1一般为40位)
并且sign长度不是固定的,但是前三位是固定的zzc
"zzc2d19f77refugerxoidpi0hp8vd6dlfs53mfcd97737".length //45位
"zzc6921aabyavvmtjrmgvf4xninak9wrhy4a0e7b61c".length //43位
二、定位sign加密位置
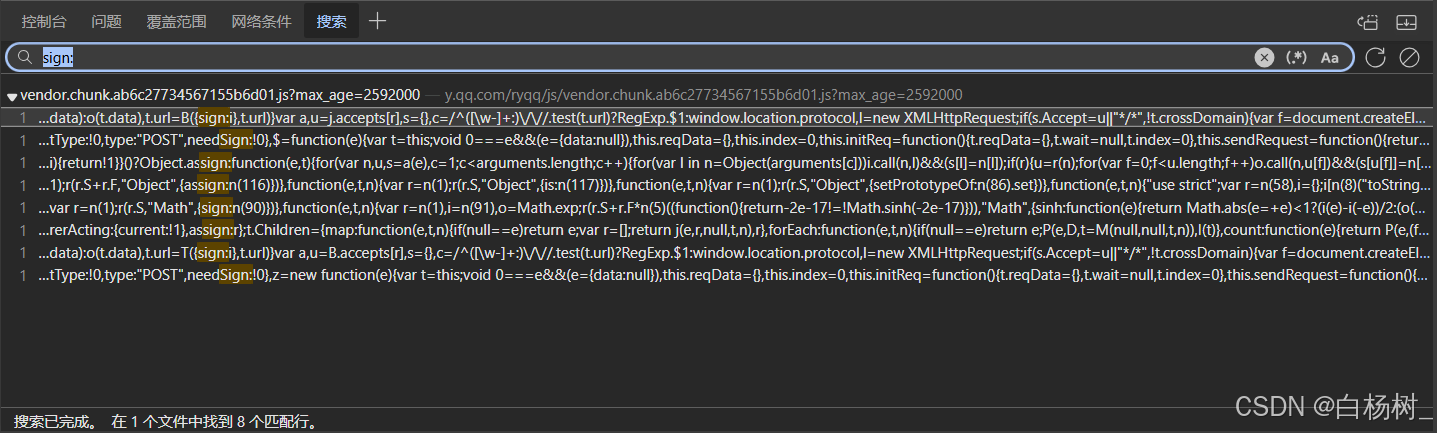
- 全局搜索,以sign:为关键词
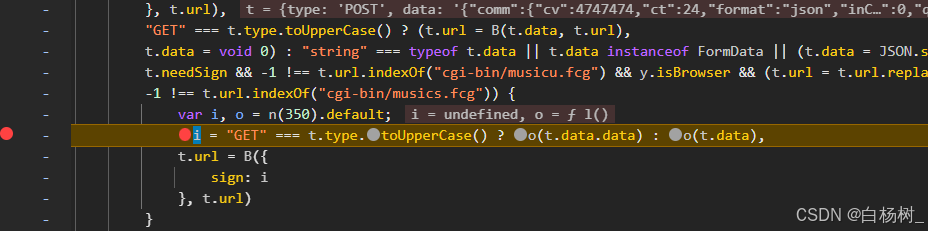
- 给所有可能是加密的地方打上断点
- 重新加载,成功定位到加密入口,二元判断进入o(t.data)函数,t.data就是post请求传入的内容
三、插桩分析
1.扣下加密函数
这个加密函数使用webpack加载器加载使用,我们要在本地浏览器里调试时需要把webpack加载器的代码复制下来,同时在内部新定义一个变量来引用这个加载器函数,由于本文只注重讲解sign算法的还原,所以如何使用webpack的方法在下一篇补环境的文章里我会详细讲解。补环境链接
我是在本地vscode,nodejs环境下和本地浏览器都调试(都用到)
2.在合适位置插桩
进入o()函数,代码如下,是一个case流,大概有82个分支
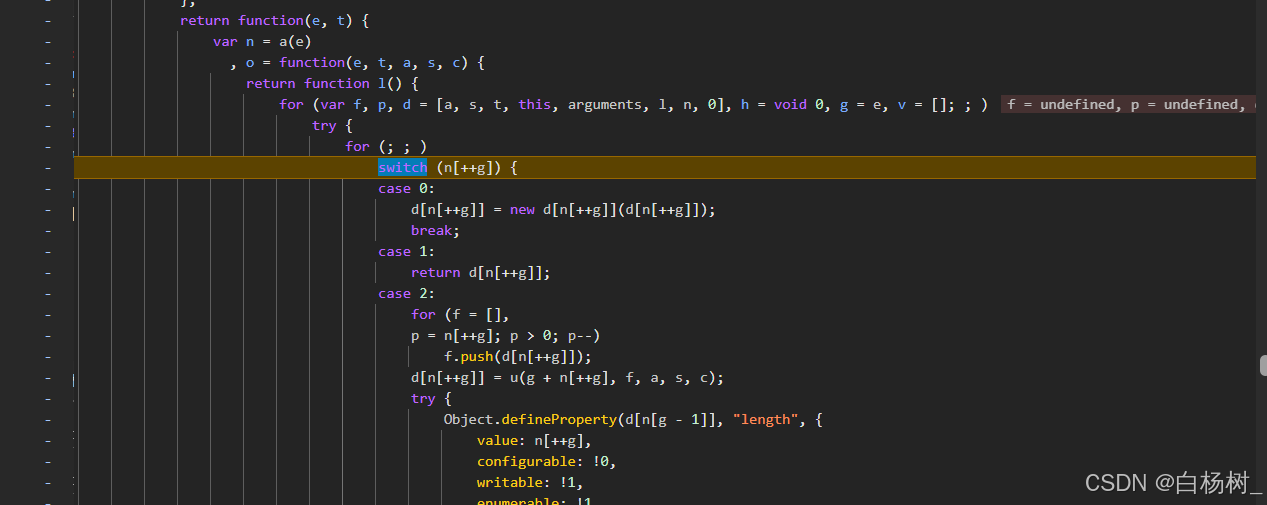
- 显而易见,我们刚好可以在switch 判断这里打上打印信息的断点,打印g和d的值(因为这个分支流就是使用g来取d中的值,并且用d中的值来做一些运算)运行结果如下:
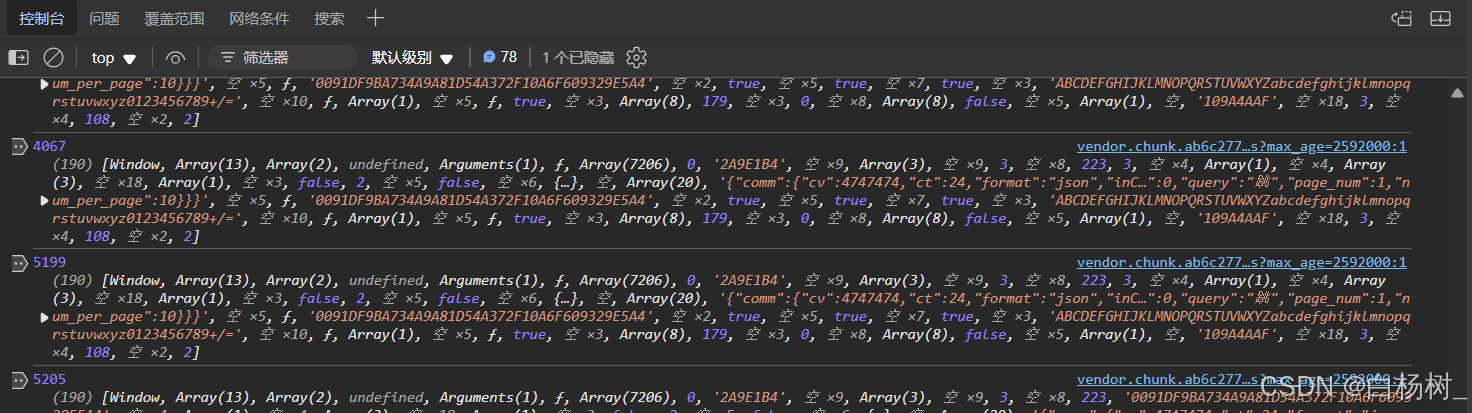
大概有十二万条打印信息,意味着这个分支流经历了上万次。所以我们要通过观察提炼出关键的运算过程,找到哪些case分支是与sign值生成息息相关的!
3.分析sign值的构成
- 通过截图和完整的打印信息我们会清晰的发现有许多值是很特殊或者固定的(通过多次请求),如下(为了清晰引用这些变量,我将他们命名):
arr1="2A9E1B4" //7位
arr2="109A4AAF" //8位
payload_content='{"comm":{"cv":4747474,"ct":24,"format":"json","inC…":0,"query":"跳","page_num":1,"num_per_page":10}}}'
dic_1={0:'0',1:'1',2:'2',3:'3',4:'4',5:'5',6:'6',7:'7',8:'8',9:'9',A:10,B:11,C:12,D:13,E:14,F:15} 固定生成
list_temp=[89,39,179,150,218,82,58,252,177,52,186,123,120,64,242,133,143,161,121,179] //固定生成
sha1_result="0091DF9BA734A9A81D54A372F10A6F609329E5A4" //40位
base64_ma='ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/='
sign="zzc2a9e1b4wbzsdx1mk1ssybkjiuqd5ryinbc109a4aaf"//最终的sign值(都为小写)
sha1_ma=[undefined, 1732584193, 4023233417, 2562383102, 3285377520, false, true, 2147483648, 4294967295, 4294967296, 1518500249, 1859775393, 1894007588] //固定值
sign_list=[89, 182, 108, 13, 125, 102, 147, 84, 172, 96, 25, 9, 137, 74, 157, 229, 28, 136, 156, 23] // 20位
arr2_list=[16, 1, 32, 12, 19, 27, 8, 5] // 8位 固定值
arr1_list=[23, 14, 6, 36, 16, 40, 7, 19] //7位 固定值
我相信看到这些值的时候,你一定也发现了许多很重要的信息。
- sign其实是由四部分组成。
- sign = zzc + 长度为7的字符(arr1) + 长度不确定的字符 + 长度为8的字符(arr2)
- 长度为40位的字符串(sha1_result)很可能是sha1加密的结果(因为长度为40位),而加密内容一般就是我们传入的post请求体(payload_content)
- arr1和arr2的值与arr1_list和arr2_list有关(因为他们长度对应相等)
- sign值可能由sign_list这个列表通过base64编码获得
4.确认sign值构成
- 列表sign_list要经过base64编码前。需要先转为字符格式,如下:

验证成功等于sign值中zzc 2a9e1b4 wbzsdx1mk1ssybkjiuqd5ryinbc 109a4aaf的第三部分的值
- sha1_result也确实由payload_content经过sha1加密而来(具体验证这里不展示)
- arr1和arr2的值来自sha1_result,取切片值,切片就是arr1_list和arr2_list
四、sign第三部分值
现在,我们只需要解决sign的第三部分,也就是长度为20的sign_list是怎么生成的。(这也是最难分析的一部分)
1.寻找第三部分生成的开端
我是通过查看所有打印的d的case流信息,发现在生成完arr1和arr2后,再生成base64_ma=‘ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=’
紧接着就可能是第三部分生成的过程。
或者查看所有流信息,猜想sign_list的运算过程也处于d的第18位,所以我们在switch处可以添加条件断点 d[18].includes(89)

成功在g为5280的时候断住,此时恰好生成sign_list中的第一个值。
显而易见,接下来就是生成sign_list的第二个值。
我们就需要一直单步执行下一步,在每一个经过的case分支上添加打印内容,格式可参考如下(因为我们是在运算前添加打印信息,所以需要使用g+1这种方法):
//打印g和d的内容
console.log(g,d)
//打印这个分支流的运算过程
console.log(g,'#',`d的${n[g+1]}位 -> d的 ${n[g+2]}位 ${d[n[g+2]]} *相乘 d的 ${n[g+3]}位 ${d[n[g+3]]} `)
大概需要添加26处打印信息(也就是26个主要运算步骤,大概20个分支)
做好打印信息的内容后,我们重新运行,查看打印内容
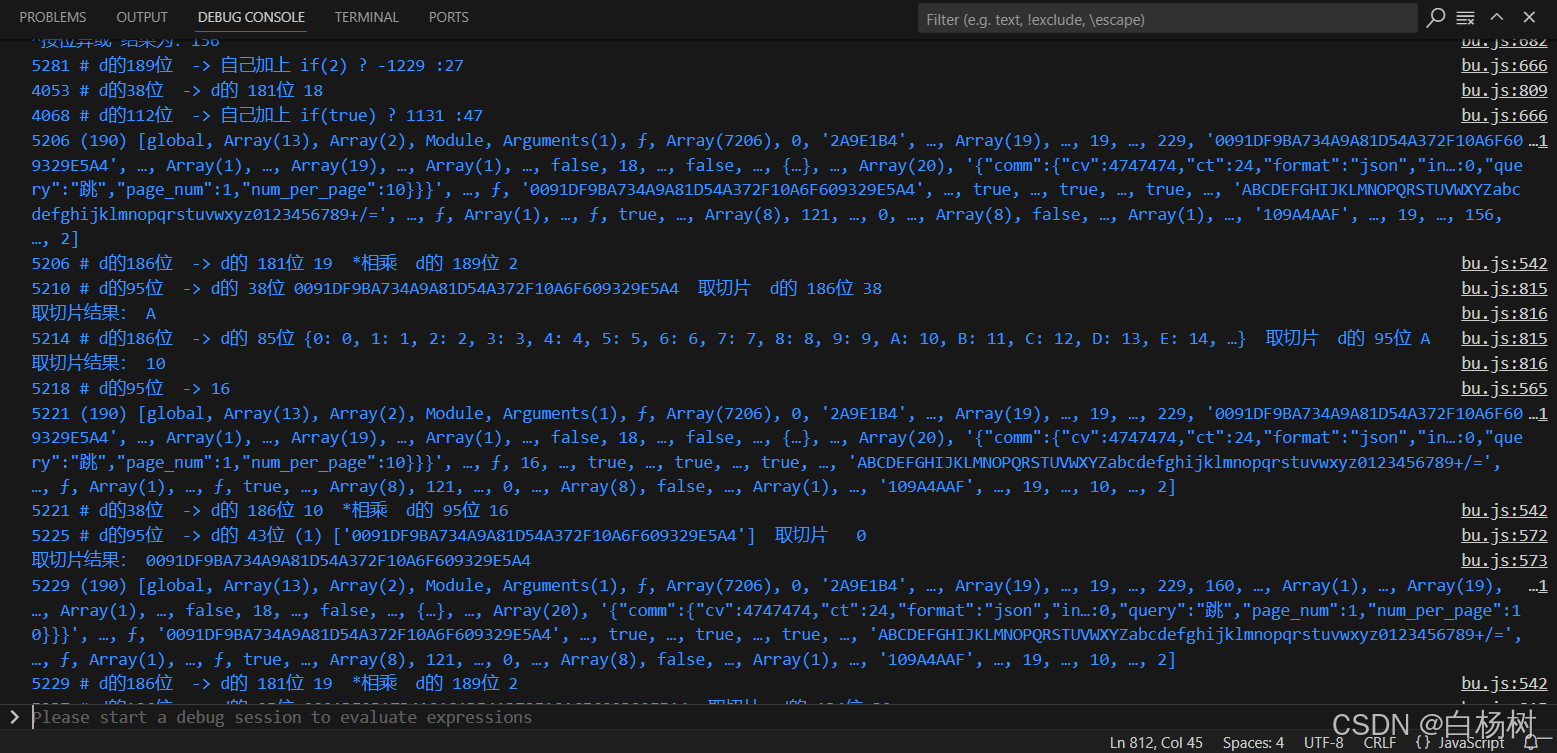
大概打印了一万多条,经过观察,可以清楚的看到,在后面有一个循环往复的过程,在不断生成sign_list里的值。这个循环也就是sign第三部分生成的开端。
2.分析第三部分的运算
- 我们需要注释掉一些不在这个循环里的打印信息,以及不再打印d的内容
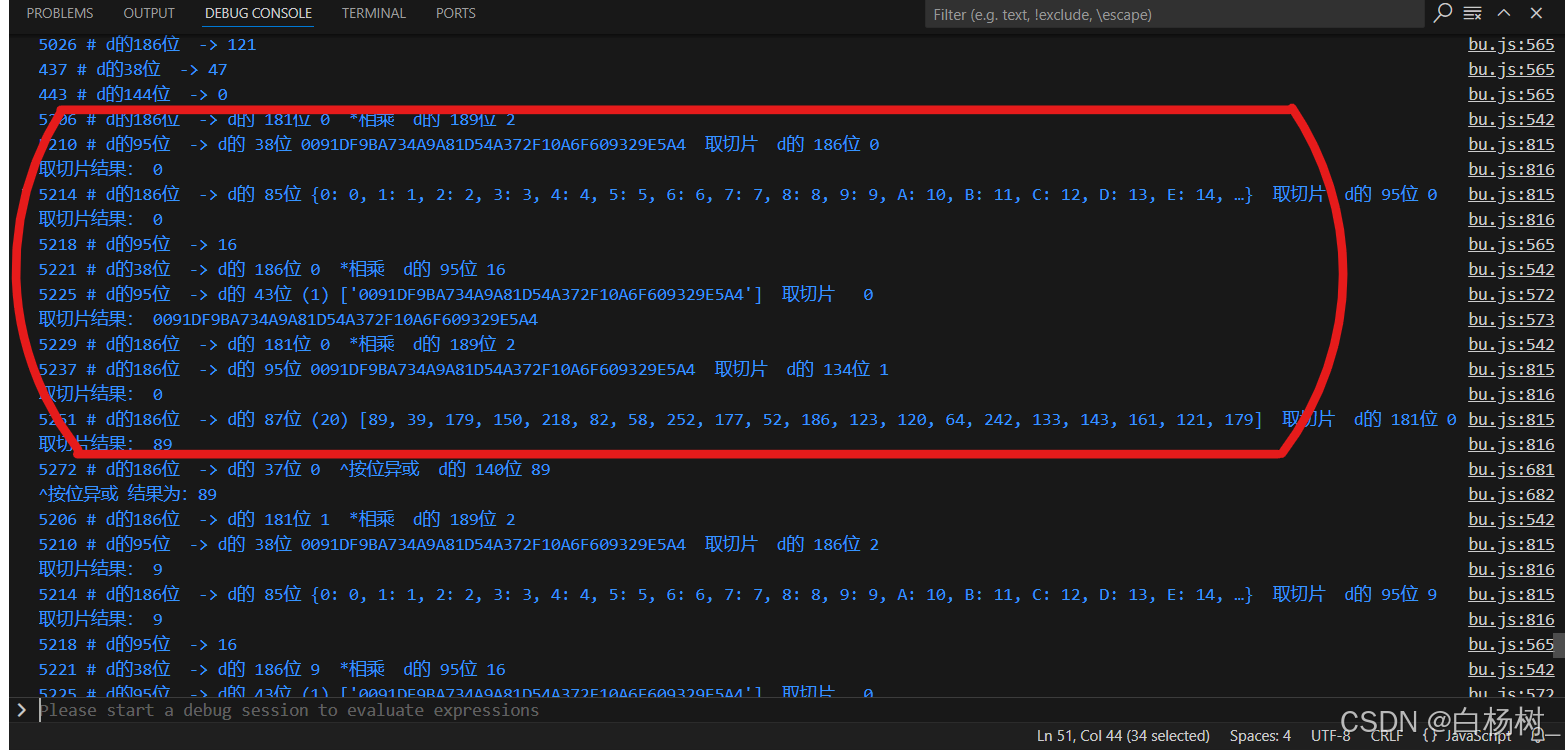
现在,我们可以清晰的发现他使用了以下内容来进行运算生成sign_list的值,并且循环了20次(因为19之后内容不再重复)
dic_1={0:'0',1:'1',2:'2',3:'3',4:'4',5:'5',6:'6',7:'7',8:'8',9:'9',A:10,B:11,C:12,D:13,E:14,F:15} 固定生成
list_temp=[89, 182, 108, 13, 125, 102, 147, 84, 172, 96, 25, 9, 137, 74, 157, 229, 28, 136, 156, 23] //固定生成
sha1_result="0091DF9BA734A9A81D54A372F10A6F609329E5A4" //40位
通过截图可知,大致运算步骤:
- 第一次循环,对应切片0。
- 取sha1_result切片0*2 一> 0 与dic_1映射 得到 一>0
- 0*16 一>0
- 取sha1_result切片0*2+1 一> 0 与dic_1映射 得到 一>0
- 取list_temp切片0 一> 89
- 将步骤3和步骤4的结果相加得到0,与步骤5的结果进行 按位异或 运算得到 一>89
- 将步骤6 按位异或 运算得到的89保存至d[18]中
以上运算步骤循环20次,最终得到长度为20的sign_list。
再对sign_list进行base64编码(编码后如果有=字符,需要去除),得到sign值的第三部分
最终得到 sign = zzc + 长度为7的字符(arr1) + base64编码后的字符 + 长度为8的字符(arr2)
3.快速定位
如果大家需要自己本地调式,找到第三部分的入口,以下case21是可以打印信息和断点的好地方。
相信大家做一遍,才会有深刻的记忆,技术也会有提升
case 21:
console.log(g,d) //打印g和d的内容
console.log(g,'#',`d的${n[g+1]}位 -> d的 ${n[g+2]}位 ${d[n[g+2]]} *相乘 d的 ${n[g+3]}位 ${d[n[g+3]]} `) 打印这个分支流的运算过程
d[n[++g]] = d[n[++g]] * d[n[++g]];
break;
总结
以上就是今天要讲的内容,本文仅仅对sign值的运算进行了还原讲解,而本地调试和真正搞清楚这个运算逻辑,还需要大家自己多动手,多调试。