目录
1. 进程创建
重新认识一下fork以及对应的写实拷贝。
进程调⽤fork,当控制转移到内核中的fork代码后,内核做:•分配新的内存块和内核数据结构给⼦进程(给子进程建立对应的PCB)•将⽗进程部分数据结构内容拷⻉⾄⼦进程 (比如 mm_struct 或者 进程上下文 等,都需要父进程的数据)•添加⼦进程到系统进程列表当中•fork返回,开始调度器调度

(把50和100看成是地址)
子进程也会继承PC指针,知道了父进程走到哪了(PC指针记录了该进程的上下文),
就能继续往下跑。
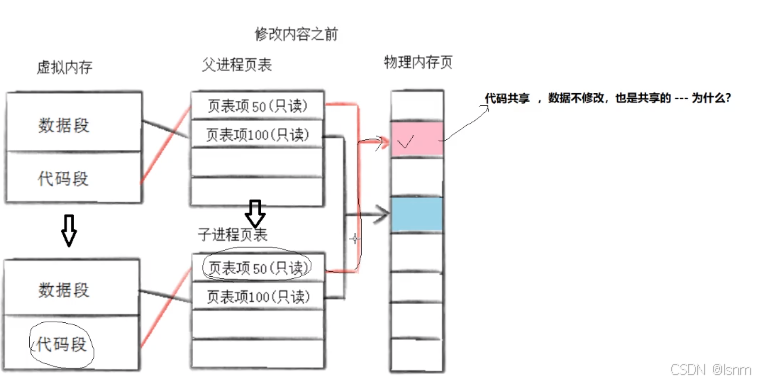
fork之前,父进程继承下去的页表会把所有内容的权限调成只读。代码(存在于常量区)本来就是只读的,无所谓。
但是数据:
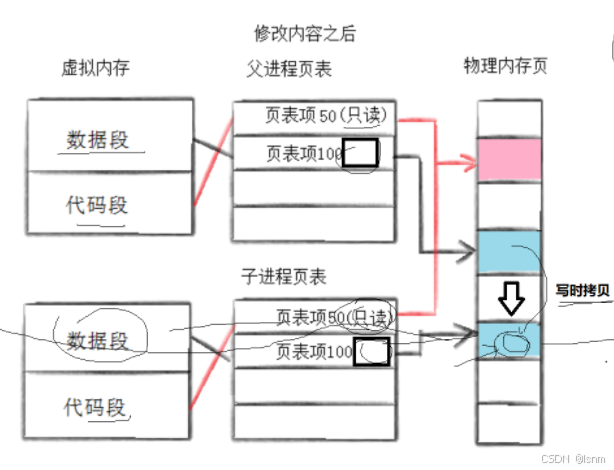
1. 子进程想修改数据时,会触发系统错误。
系统错误导致缺页中断,系统开始检测并判定,是普通的错误还是此时该发生写时拷贝
拷贝之后就申请内存(物理)进行拷贝


2. 如果发生写时拷贝时,要被拷贝的内容不在内存里:也会触发这个系统错误
依然继续判定:要么野指针等错误,要么发生写时拷贝,要么是需要发生页面置换(先将磁盘中对应的程序给置换进内存)
2. 进程终止(区分退出码和退出信号)
之前有提过,函数的返回值是为了返回给父进程或者系统的。
为什么返回给系统,是因为有时候需要系统扮演父进程的位置(比如Bash结束的时候)
我们可以用echo $? 来表现上一个程序的退出码


用不同的数字表明出错的原因,介绍三个函数来理解这些错误码:

strerror是一个标准库函数,用于将错误码转换为人类可读的错误描述字符串。
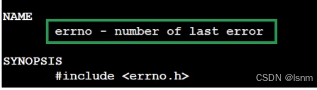
errno是一个全局变量,用于存储最近一次系统调用或库函数失败时的错误码。它是一个整数,定义在<errno.h>中。
//两者常见于一起使用
printf("Error Occured: %s\n",strerror(erron));而perror则更常用于写程序的人用于自行报错。
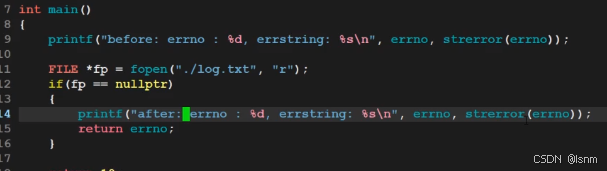
注意,fopen失败时会自动设置一个erron值
errno不是只在一个程序运行崩溃时才记录,而是一个库函数没有运行成功也会记录,比如fopen或者fork都会记录一个数值。
总结:给机器看错误码,给人看字符串描述 (利用strerror来转述)
进程也可以有自己的特殊退出码(由程序员自行设定):
比如一个二分查找,此时出错和系统无关,需要自己设置错误退出码
OJ中也有用,脚本语言的执行也有用,那么就需要自己设置这个退出码。
如何自主的来结束进程呢:
1 main中使用return
2 使用exit函数,在头文件stdlib.h中
exit后面的参数,就是进程的退出码(exit(1)之后,erron的值就会更新成1)。
3 _exit
_exit几乎和exit一致,_exit属于2号手册(即系统调用接口,是比exit更接近内核的接口),
_exit不刷新缓冲区
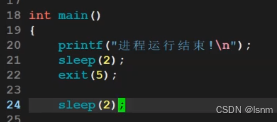
去掉反斜杠n,再将exit换成_exit,会发现_exit不能自动刷新缓存区。
理解:
exit是属于glibc中的接口。库函数本身就是对一些系统调用的封装。
exit的本质是对_exit的封装
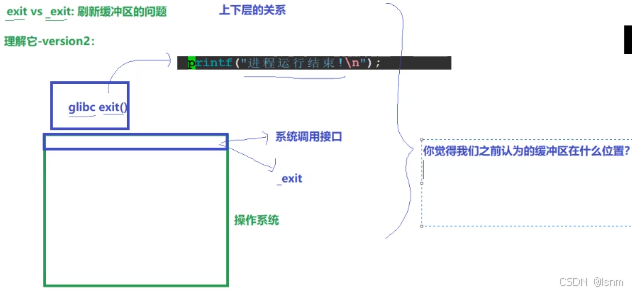
我们以前认为,\n能刷新缓存区,但是此时直接使用系统层的函数却不能去刷新,原因:
这个缓冲区,叫:语言级缓冲区
和系统没有关系。exit在封装的时候可能调用了fflush等函数
总结:退出码表示结果正确与否,退出信号表示是否正常退出。
3. 进程等待
⼦进程退出,⽗进程如果不管不顾,就可能造成‘ 僵⼫进程 ’的问题,进⽽造成内存泄漏。另外,进程⼀旦变成僵⼫状态,那就⼑枪不⼊,“杀⼈不眨眼”的kill -9 也⽆能为⼒,因为谁也没有办法杀死⼀个已经死去的进程。最后,⽗进程派给⼦进程的任务完成的如何,我们需要知道。如,⼦进程运⾏完成,结果对还是不对,或者是否正常退出。⽗进程通过 进程等待 的⽅式,回收⼦进程资源,获取⼦进程退出信息
根据errno对于fork的补充:
RETURN VALUE
On success, the PID of the child process is returned in the parent, and 0 is returned in the child. On failure, -1 is returned in the parent, no child process is created, and errno is set appropriately.也就是说,如果fork了返回值不正确,也会更新对应的errno值。
进程等待对应的接口:wait和waitpid
先实现一个让子进程变僵尸进程的demo,再用两个号来观察
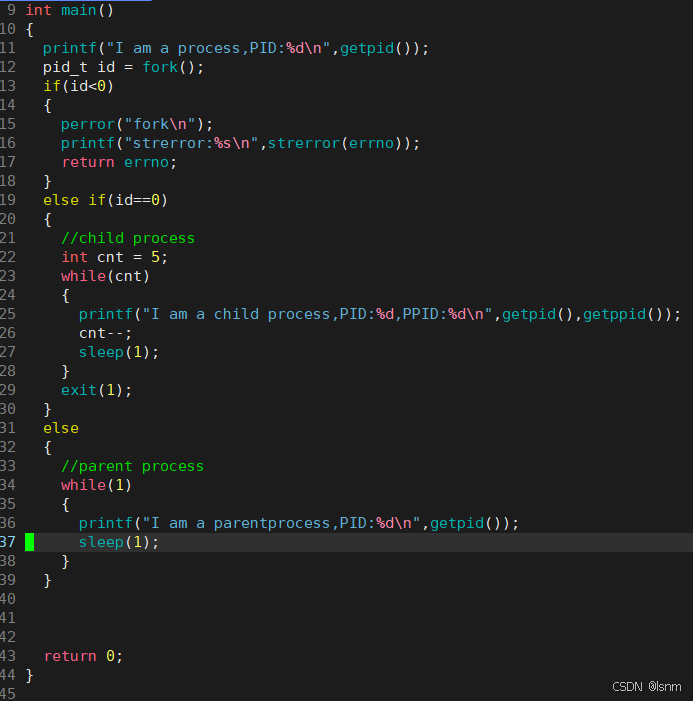

用脚本观察得:子进程已经进入Z状态

为了解决这种问题,我们使用以下两个接口:
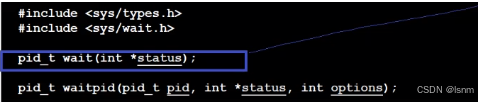
先说wait,wait能回收子进程的僵尸状态,因为如果子进程不退,父进程就会阻塞在wait函数内部。并且wait能等待 任意 一个 子进程
在父进程的分支中加一个wait并且加一个rid接受wait的返回值:
wait以及waitpid的返回值:
成功时返回子进程的 PID。
出错时返回
-1。
子进程退出之后,如果想知道子进程完成的如何,更多使用wait_pid
waitpid可以使用第二个参数去获得子进程的退出码(exit后面跟的那个数字)
参数pid取值:


注意此处的任意等待一个子进程:

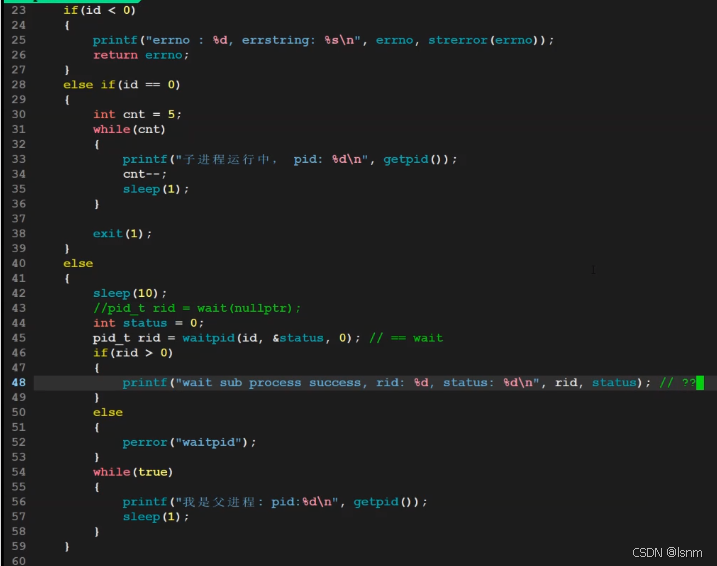
status是一个“输出性参数” ,返回的是子进程的退出码

status既包含正常退出信息,又包括异常退出信息,并且是一个输出型参数,也是为了能让父进程得到子进程的推出信息。(不要和wait以及waitpid的返回值混肴!)
statis本质是一个位图
其中次低八位 是退出状态(8-15),终止信号为0;当进程被信号所杀时(非正常终止),次低八位属于未被使用的状态,终止信号接受各种kill下的信号。

为了获得退出码,让32位的status与00000000 00000000 00000000 11111111(0xFF)按位与
(status>>8)& 0xFF;
那大家就可以规范几种固定的数字,让父进程通过数字知道为什么子进程退了,并且错在哪里
如果我们使用kill下的指令去结束一个进程, 那么此时status的低八位就会获得一个数据。
比如野指针的错误:
11号信号对应的就是这类野指针的错误(segment fault段错误)
或者8号信号对应的浮点数错误
因此:进程崩掉这种现象,是OS发出这样的信号导致的结果

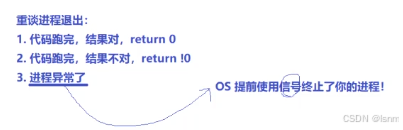
这样的信号,叫做退出信号
区分退出信号和退出码!!!
先观察退出信号,再观察退出码。
没有退出信号时,再去研究退出码。
kill下没有0号指令也是这个原因,零号表示信号正常。

如果要从位图中解出这个数值,就直接按位与 0111 1111即可。

能否用环境变量获得退出信息?

退出信息不一定要获得,但是回收僵尸进程是很有必要的。
rid>0(wait与waitpid的返回值)只表示waitpid正常运行了,并不代表子进程成功退出了,子进程此时可能是异常退出的,不过僵尸进程已经被父进程给回收了。至于子进程具体的退出信息,还是要看status的值。
WIFEXITED AND WEXUTSTATUS
每次按位与来解析status这个位图非常不雅观,于是有两个宏


所以整体的大逻辑如下图:先判断wait是否成功进行。(rid是否大于0)
再判断WIFEXITED,若为真,表示进程不是被退出信号所杀掉的,可以查看退出码;
若为假,表示进程是被kill信号所杀掉的(也就是位图的最低八位中不是0)

子进程的作用(waitpid的练习代码):
每秒中往一个vector中添加数据,每十秒执行一次备份,要求用子进程进行备份。
父进程要回收子进程资源并且打印对应的退出信息。具体的备份函数要求以时间戳+.backup命名。
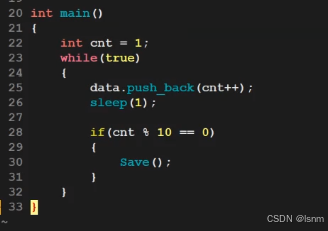
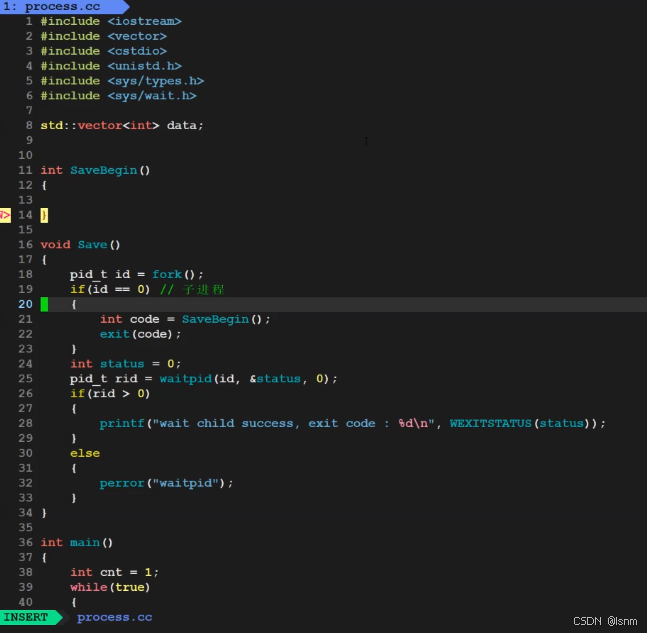
尽管在不停的增加东西到data里去,但是子进程不关心vector里的数据如何变化(写时拷贝中父进程数据变化),相当于是做一个快照。父进程怎么改数据,一点都不影响。
做成子进程,能避免备份失败带来的影响,因为进程具有独立性,并且代码更具有可扩展性
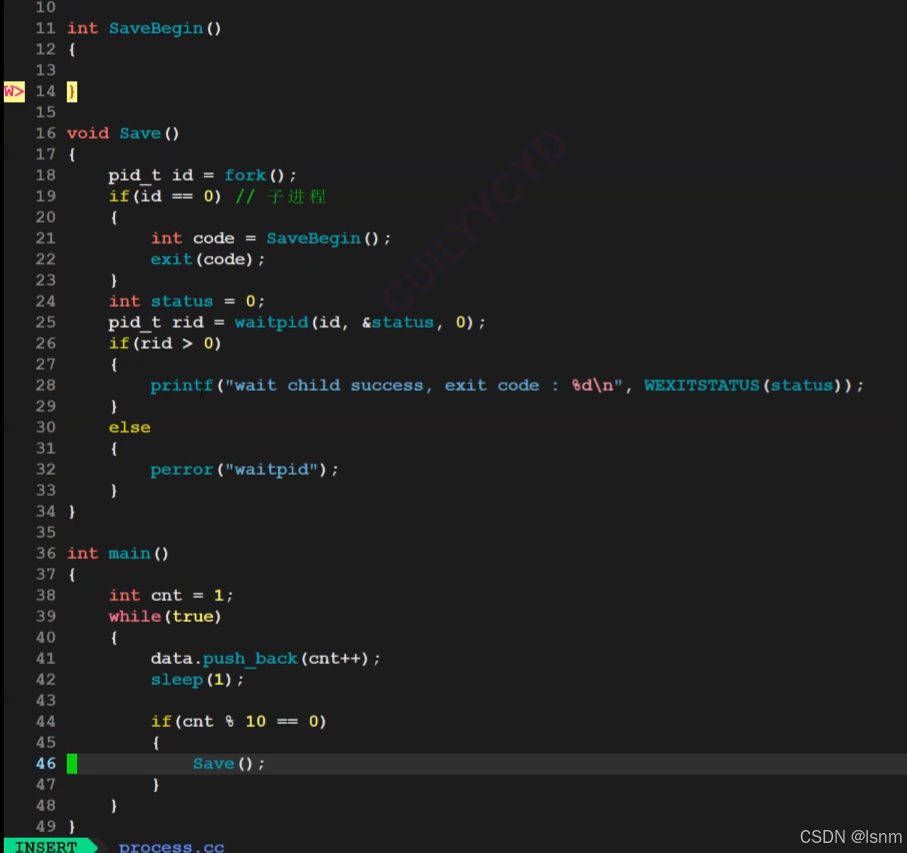
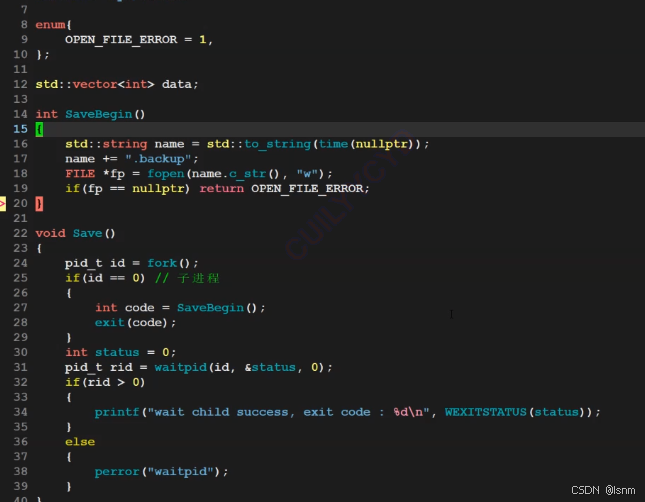

最终代码:
#include <iostream>
#include <cstdio>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <vector>
#include <string>
#include <cstdlib>
std::vector<int> data;
std::string g_sep = " ";
enum state
{
OK = 0,
OPPEN_FILE_ERROR,
};
int SaveBegin()
{
std::string name =std:: to_string(time(nullptr));
name += ".backup";
FILE* fp = fopen(name.c_str(),"w");
if(fp == nullptr)
{
perror("fopen");
return OPPEN_FILE_ERROR;
}
std::string datastr ;
for(auto d:data)
{
datastr += std::to_string(d);
datastr += g_sep;
}
fputs(datastr.c_str(),fp);
fclose(fp);
return OK;
}
void save()
{
pid_t id = fork();
if(id==0)
{
//child process
int code = SaveBegin();
exit(code);
}
//child process never come to here
int status = 0;
pid_t rid = waitpid(id,&status,0);
if(rid<0)
{
perror("waitpid");
}
else
{
if(WIFEXITED(status))
{
if(WEXITSTATUS(status)==0) printf("SUCCESS!\n");
else
printf("wait success,EXIT code:%d\n",WEXITSTATUS(status));
}
else
{
printf("exit unsuccess,exit signal:%d\n",status & 0x7F);
}
}
}
int main()
{
int cnt = 1;
while(true)
{
data.push_back(cnt++);
sleep(1);
if(cnt%5==0)
{
save();//keep a backup
}
}
return 0;
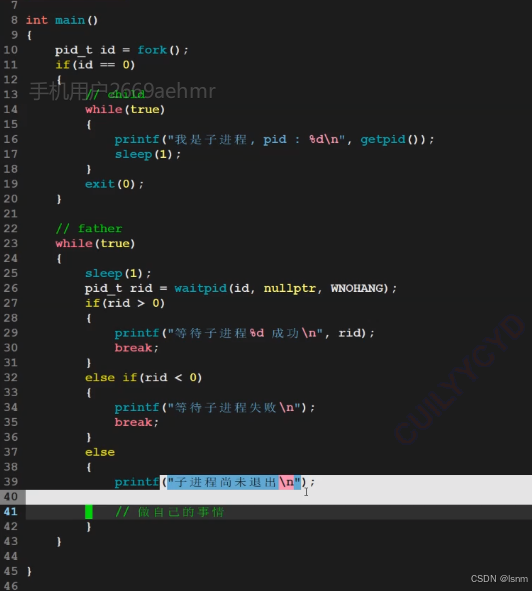
}阻塞与非阻塞问题(WNOHANG)
之前都是父进程在waitpid函数中阻塞下来等待子进程回收
非阻塞等待操作:将参数0换成宏WNOHANG(wait no hang)
目的是让父进程可以做更多自己的事,不过代码成本更高,需要自己进行循环检测

其实wait的返回值还有等于0的情况,表示此时子进程没有退出。
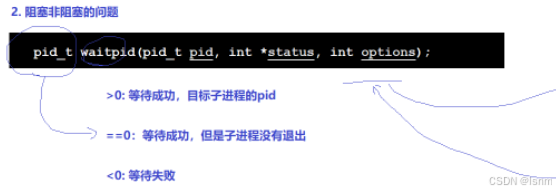
挂上WNOHANG之后可以如下操作:
4. 进程程序替换
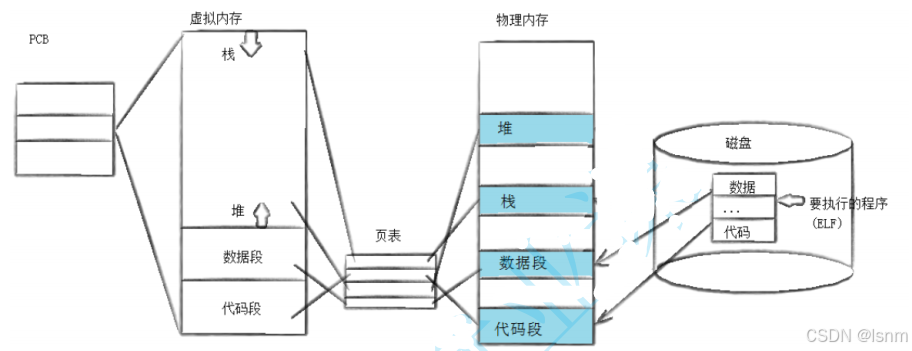
4.1 替换原理
⽤fork创建⼦进程后执⾏的是和⽗进程相同的程序(但有可能执⾏不同的代码分⽀),⼦进程往往要调⽤⼀种exec函数以执⾏另⼀个程序。当进程调⽤⼀种exec函数时,该进程的⽤⼾空间代码和数据完全被新程序替换,从新程序的启动例程开始执⾏。调⽤exec并不创建新进程,所以调⽤exec前后该进程的id并未改变。
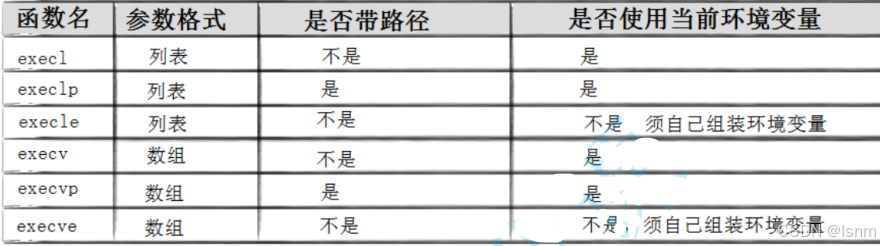
4.2 替换方法
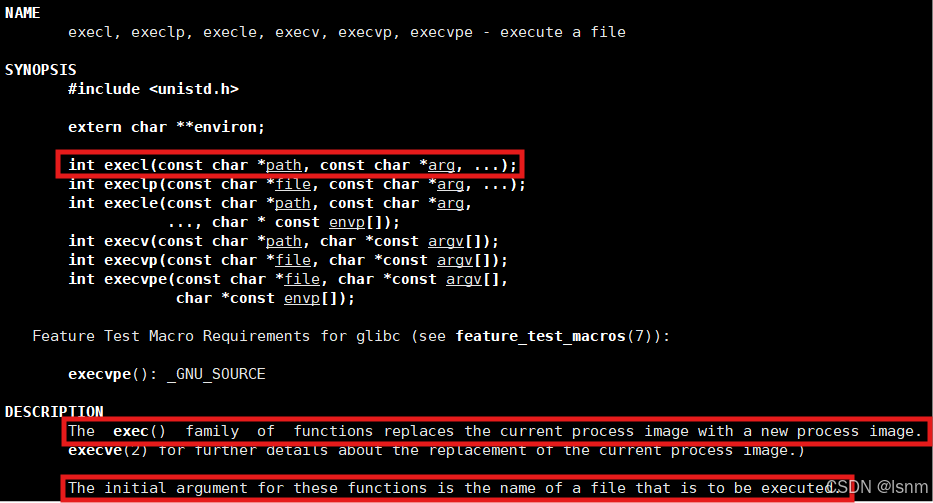
有六种exec开头的函数,简称execl函数
#include <unistd.h> int execl(const char *path, const char *arg, ...); int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg, ...,char *const envp[]); int execv(const char *path, char *const argv[]); int execvp(const char *file, char *const argv[]); int execve(const char *path, char *const argv[], char *const envp[]);
以execl为例先进行学习。第一个path是希望变成的程序的路径,第二个是给参数列表传参。基于之前对参数列表的学习(初识Linux(8) :环境变量-CSDN博客),我们建议第一个参数就传这个ELF文件本身的名字。
也就是:
参数列表的末尾必须要有nullptr作为标志。


关于返回值:
这些函数如果调⽤成功则加载新的程序从启动代码开始执⾏,不再返回。•如果调⽤出错则返回-1•所以exec函数只有出错的返回值⽽没有成功的返回值。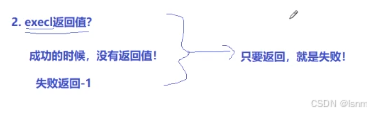 没有太多必要去关注exec函数的返回值!!
没有太多必要去关注exec函数的返回值!!
不过不要通过execl去执行诸如“ll”这种命令所对应的程序,因为ll本身是一个别名,不是具体的指令。
可以通过--color来让指令变的有色彩等。
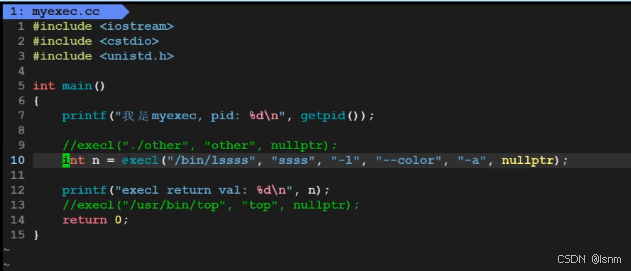
4.3 具体使用
exec就是一种加载。将磁盘中的程序加载到新创建的PCB和代码空间中去。
一旦
execl调用成功,当前进程的代码和数据将被新程序的代码和数据完全替换,并且新程序会从其入口点开始直接执行。
#include <iostream> 2 #include <cstdio> 3 #include <cstdlib> 4 #include <unistd.h> 5 #include <sys/types.h> 6 #include <sys/wait.h> 7 8 int main() 9 { 10 pid_t id = fork(); 11 if(id==0) 12 { 13 //child process 14 sleep(3); 15 execl("/bin/ls","ls","-l","-a",nullptr); 16 exit(0); 17 } 18 // father process 19 pid_t rid = waitpid(id,nullptr,0);//不关心子进程的返回,并且采用阻塞等待 20 if(rid>0) 21 { 22 printf("wait child success!!\n"); 23 } 24 25 return 0; 26 }
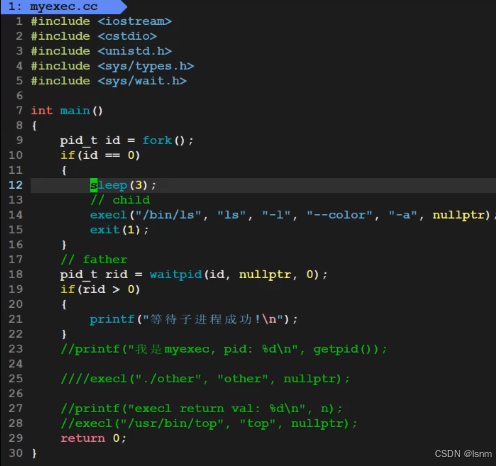
理解一下fork+execl:
可以说,几乎所有在shell上跑的程序或者脚本,都是
fork+execl调用起来的
操作系统中几乎所有的进程都满足这么做
fork先创建内核数据结构(从父进程处拷贝需要用的内容,然后execl加载我们希望的程序)
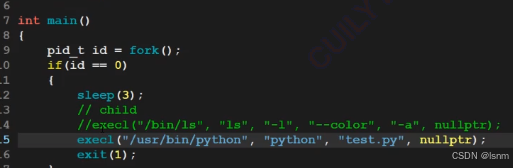
并且此时一定会发生写时拷贝:

代码区照样会发生写时拷贝(通过触发系统错误完成)
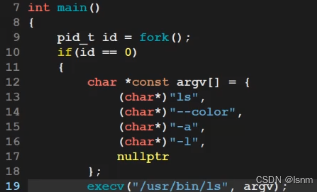
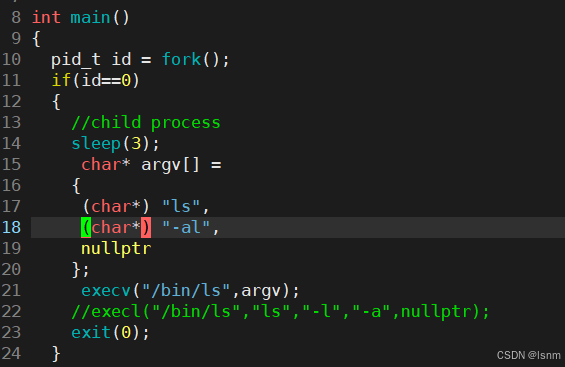
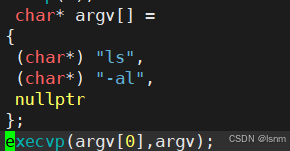
execv:
execl中的l是list的意思,此处的v是vector的意思。
所以这个函数需要我们自己构建指针数组,然后以数组的形式传进execv的第二个参数
注意,一定要传最后的nullptr。

execlp 和 execvp
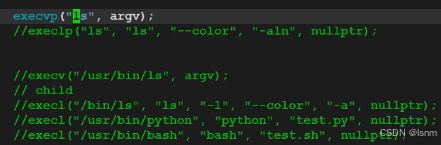
其他可以说是一模一样,不过这次只需要传一个文件名,不需要文件路径。
操作系统会自动通过环境变量PATH去找到这个程序。
当然,如果PATH如果有重复的,是从左向右搜并使用查到的第一个。
使用例子:

execvpe和execlpe,最后的e就是enviroement
除了argv,还需要主动去传environ。用户将参数传给exec函数,被命令行解析之后传给调用的main函数
一个程序是从main开始执行的,这个程序是被 命令行 给fork再exec 的,那这个argv[]参数和argc参数也是被传递进来的。不过一般都需要自己去主动完成一个argc数组
但是之前的execvp和execlp没有传envp,是如何获得envp的呢?
execvpe这种接口很好理解,能主动传环境变量。
按理来说,环境变量在栈的上面,是不会被替换的。因为环境变量是具有全局性的,由父进程继承给子进程。所以使用execvpe的目的是,你希望传一个新的环境变量

但这是覆盖性的写法。
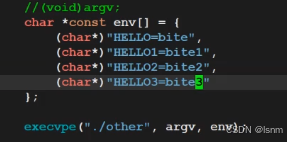
为了让子进程获得原来的父进程的许多环境变量,我们采用putenv。
putenv:
父进程中可以直接导环境变量,父进程中导的环境变量是能直接被子进程继承的。父进程的父进程(shell)是不会知道的你重新导进了环境变量的
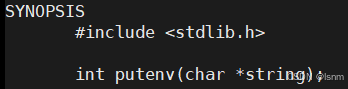
注意:环境变量必须写成xxx=xxx的形式,如果没有这个等号,是有可能不能添加进去的。
Hello不是一个环境变量名称,AAAAAAA才是环境变量的名字。
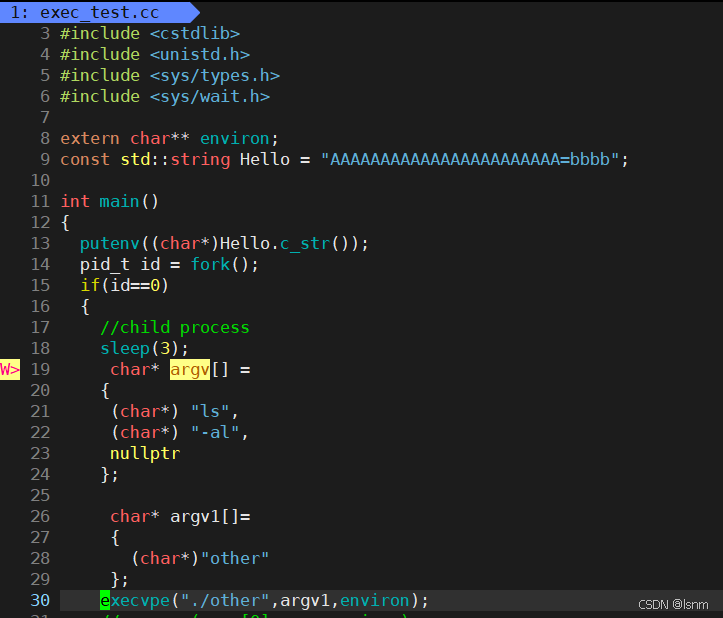
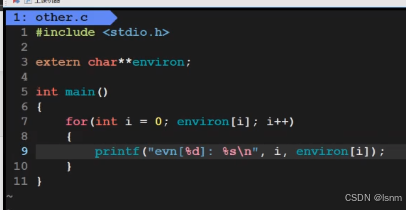
other代码: