目录
前言
排序是一个相对复杂的过程,进一步思考排序这个问题,我们可以借助分治的思想来解决这个问题,
什么叫分治呢?就是把大问题化成小问题,进而缩小问题的规模,并且大问题和小问题只有规模不同,显然,大问题的问题规模大,小问题的问题规模小。例如,我们上面的起泡排序,经过一趟排序后,得到的序列是{23,22,38,23,45,31,15,41,67},其中67已经排好,剩下的元素也是排序,只是需要排序的元素
少了一个(问题规模变小)。当然,起泡排序的这种分割太低效,每次只能切除一个元素,太费时费力了。
那么有没有更有效的方法呢?答案是有,快速排序就是其中一种经典算法。
一、快排思想过程
(1)排序思想。
快速排序是我们最常用的算法,它的基本思想是通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,再分别对这两部分记录进行下一趟排序, 从而达到整个序列有序。也就是说,每次都选一个基准元素,通过这个基准元素将待排序的元素分成两个部分。
(2)排序过程。
每次都选一个基准元素,通过这个基准元素将待排序的元素分成两个部分。那么怎么选这个基准元素呢?在考研中,一般选择每段的第一个元素作为基准元素。具体来说,设待排序的记录序列是L[s .. t],在记录序列中取L[s]作为参照(又称为基准或枢轴),以L[s]为基准重新排列其余的所有记录,将所有比基准小的关键字放L[s]之前,将所有比基准大的关键字放L[s]之后。以L[s]最后所在位置i作为分界,将序列L[s .. t]分割成两个子序列L[s .. i-1]和L[i+1 .. t],再分别对这两部分元素进行下一趟排序(L[s .. i-1]以L[s]为基准元素,L[i+1 .. t]以L[i+1]为基准元素)。如此重复,直到整个序列有序。
(3)一趟快速排序方法。
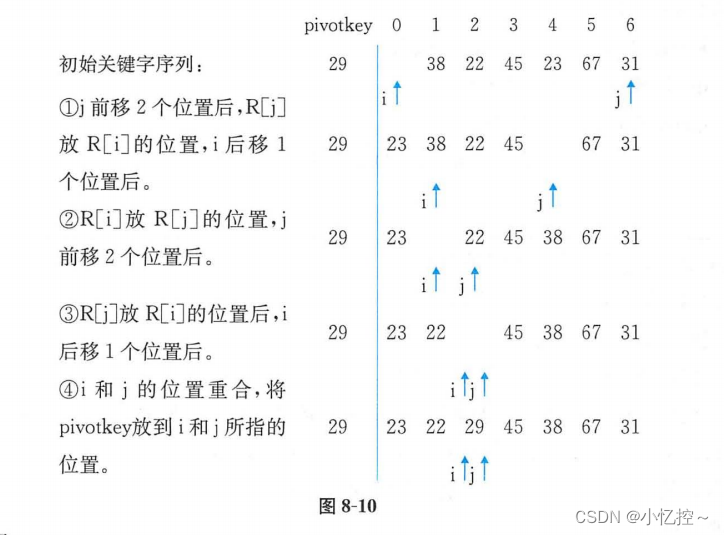
在快速排序中,选取基准元素L[s],将所有比基准小的关键字放L[s]之前,将所有比基准大的关键字放L[s]之后。实现上述过程的操作称为一趟排序。从序列的两端交替扫描各个记录,将关键字小于基准,关键字的记录依次放置到序列的前边; 将关键字大于基准关键字的记录从序列的最后端起,依次放置到序列的后边,直到扫描完所有的记录。这个文字描述比较难理解,我们通过一个例子来说明,结合一趟实现快速排序的代码来讲解实现过程。设有7个待排序的记录,关键字分别为29、38、22、45、23、67、31,一趟快速排序的过程如下,待排元素的数组是L。



二、算法思路
当执行快速排序时,可以根据以下算法思路进行步骤实现:
1. 定义一个快速排序函数,接收数组、起始索引和结束索引作为参数。
2. 如果起始索引小于结束索引,则进行以下步骤:
a. 选择数组的第一个元素作为基准元素 pivot。
b. 初始化两个指针 i 和 j 分别指向起始索引和结束索引。
c. 开始循环,直到 i 不小于 j:
- 从右向左找到第一个小于 pivot 的元素,将其索引赋给 j。
- 从左向右找到第一个大于 pivot 的元素,将其索引赋给 i。
- 若 i 小于 j,则交换数组中索引为 i 和 j 的元素。
d. 当 i 大于等于 j 时,将基准元素 pivot 与索引为 j 的元素交换。
e. 以 j 为界将数组分为两部分,递归调用快速排序函数对左右两部分进行排序。
3. 在主函数中调用快速排序函数,将数组和起始、结束索引传入。
4. 最终,数组会被分隔成许多小的部分,每个部分都是有序的,最终整个数组会被排序。
这就是快速排序算法的基本思路,通过不断地分割和交换元素,最终实现对整个数组的排序。
三、代码实现
C语言实现:
#include <stdio.h>
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
int partition(int arr[], int low, int high) {
int pivot = arr[low];
int i = low, j = high;
while (i < j) {
while (i < j && arr[j] >= pivot) {
j--;
}
if (i < j) {
swap(&arr[i], &arr[j]);
}
while (i < j && arr[i] <= pivot) {
i++;
}
if (i < j) {
swap(&arr[i], &arr[j]);
}
}
arr[i] = pivot;
return i;
}
void quickSort(int arr[], int low, int high) {
if (low < high) {
int pivotIndex = partition(arr, low, high);
quickSort(arr, low, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, high);
}
}
int main() {
int arr[] = {29, 38, 22, 45, 23, 67, 31};
int n = sizeof(arr) / sizeof(arr[0]);
quickSort(arr, 0, n - 1);
printf("Sorted array: ");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}C语言分析:
这段代码实现了快速排序算法的逻辑,首先使用
swap函数交换两个元素的值,然后定义partition函数来进行分区操作,最后实现了quickSort函数来递归进行快速排序。在main函数中初始化一个示例数组并调用quickSort函数进行排序,然后输出排序后的数组。
C++实现:
#include <iostream>
#include <vector>
void quickSort(std::vector<int>& arr, int low, int high) {
if (low < high) {
int pivot = arr[low]; // 选择第一个元素作为基准元素
int i = low, j = high;
while (i < j) {
while (i < j && arr[j] >= pivot) {
j--;
}
if (i < j) {
std::swap(arr[i], arr[j]);
}
while (i < j && arr[i] <= pivot) {
i++;
}
if (i < j) {
std::swap(arr[i], arr[j]);
}
}
arr[i] = pivot; // 将基准元素放置到正确的位置
quickSort(arr, low, i - 1); // 对基准元素左边的子数组进行快速排序
quickSort(arr, i + 1, high); // 对基准元素右边的子数组进行快速排序
}
}
int main() {
std::vector<int> arr = {29, 38, 22, 45, 23, 67, 31};
quickSort(arr, 0, arr.size() - 1);
std::cout << "Sorted array: ";
for (int num : arr) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}这段C++代码实现了快速排序算法的完整逻辑。让我们逐步分析这段代码:
1. 在代码开头`#include <iostream>`和`#include <vector>`语句用来引入所需的头文件。
2. `void quickSort(std::vector<int>& arr, int low, int high)`定义了一个名为`quickSort`的函数,接受一个整数向量`arr`以及表示排序范围的`low`和`high`参数。
3. 在`quickSort`函数中,首先检查`low`和`high`是否指向有效的排序范围,如果`low < high`,进入排序逻辑。
4. 在排序逻辑中,选择数组第一个元素作为基准元素`pivot`,然后定义两个指针`i`和`j`分别指向排序范围的两端。
5. 通过双指针的移动,将数组中的元素不断与基准元素比较和交换,直到双指针相遇。
6. 将基准元素放置到正确的位置,使得基准元素左侧的元素都小于基准元素,右侧的元素都大于基准元素。
7. 对基准元素左右两侧的子数组分别递归调用`quickSort`函数进行排序。
8. 在`main`函数中,初始化一个整数向量`arr`作为示例数组,调用`quickSort`函数对该数组进行排序。
9. 最后使用`for`循环遍历排序后的数组,并输出排序结果。
10. 程序执行结束后返回`0`表示运行成功。
这段C++代码实现了快速排序算法的逻辑,通过递归的方式对数组进行分治排序,最终实现了对数组的快速排序功能。
总结
-
优点:
- 平均时间复杂度为O(nlogn),效率较高。
- 原地排序,不需要额外的空间。
- 相对容易实现。
-
缺点:
- 对于小规模数据或近乎有序的数据,性能可能不如插入排序等简单排序算法。
- 快速排序的最坏时间复杂度为O(n^2),发生在数组已经有序的情况下。
-
稳定性:快速排序是不稳定的排序算法,因为在交换过程中相同元素的相对位置可能发生变化。