目录
Main Dispatch Queue/Global Dispatch Queue
dispatch_suspend/dispatch_resume
GCD概要
什么是GCD
GCD是异步执行任务的技术之一。它可以将程序中记述的线程管理用的代码在系统级中实现。GCD的线程管理是作为系统的一部分来实现的,因此可统一管理,也可执行任务,比以前的线程更有效率。
比如:
dispatch_async(queue, ^{
//长时间处理
//例如AR用画像识别
//例如数据库访问
//长时间处理结束,主线程使用该处理结果。
dispatch_async(dispatch_get_main_queue(), ^{
//只在主线程可以执行的处理
//例如用户界面更新
})
});可以发现,GCD使用了Blocks,进一步简化了应用程序代码。
相比performSelector系方法,GCD更为简洁,如果使用GCD,不仅不必使用NSThread类或performSelector系方法这些过时的API,更可以通过GCD提供的系统级线程管理提高执行效率。
多线程管理
由于一个CPU一次只能执行一个命令,不能执行某处分开的并列的两个命令,因此通过CPU执行的CPU命令列就好比一条无分叉的大道,其执行不会出现分歧。
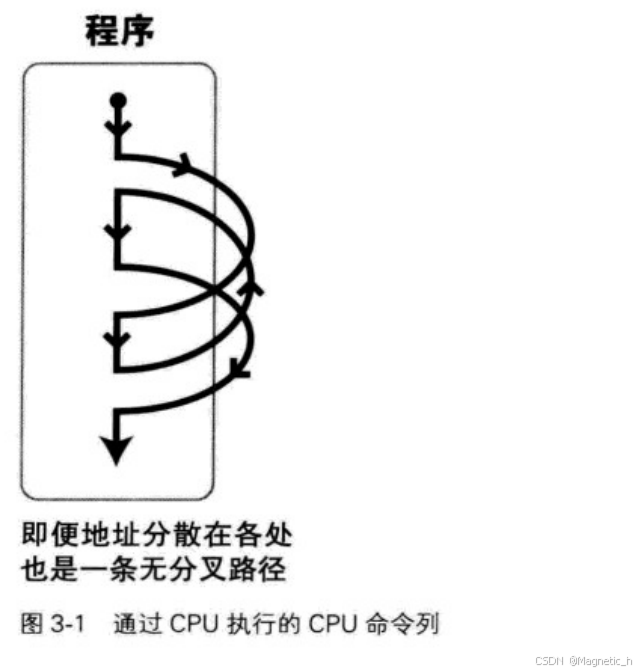
这里说的“1个CPU执行的CPU命令列为一条无分叉路经”,即“线程”。
当这种路经存在多条时,就是所谓的“多线程”。

iOS的核心XUN内核在发生操作系统事件时,会切换执行路径。执行中路径的状态,例如CPU的寄存器等信息保存到各自路经专用的内存块中,从切换目标路径专用的内存块中,复原CPU寄存器等信息,继续执行切换路径的CPU命令列。这被称为“上下文切换”。
通过上下文切换,一个CPU就可以达到看上去像并列执行多个线程一样,当具有多个CPU时,就可以实现真正的多线程。这种利用多线程编程的技术被称为“多线程编程”。
但是多线程容易产生多种问题:比如多个线程更新相同的资源会导致数据的不一致(数据竞争)、停止等待事件的线程会导致多个线程相互持续等待(死锁)、使用太多线程会消耗大量内存等。

但还是应当使用多线程编程,因为可以保证程序的响应性能。
GCD的API
Dispatch Queue
对这个API,官方的说明是:
开发者要做的只是定义想执行的任务并追加到适当的Dispatch Queue中。
这句话用源代码表示如下:
dispatch_async(queue, ^{
//想执行的任务
});该代码使用Block语法“定义想执行的任务”,通过dispatch_async函数“追加”赋值在变量queue的"Dispatch Queue中"。这样就可以使指定的Block在另一线程中执行。
Dispatch Queue是执行处理的等待队列,它按照追加的顺序执行Block语法中的任务。

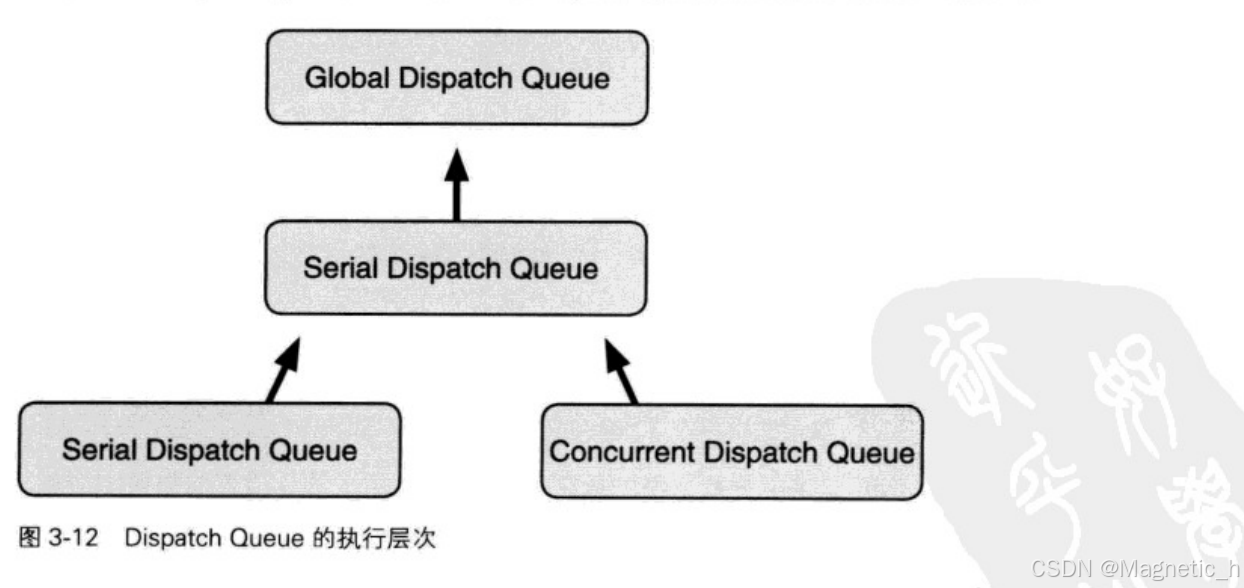
有两种Diapatch Queue,一种是等待现在执行中处理的Serial Dispatch Queue,另一种是不等待现在执行中处理的Concurrent Dispatch Queue。

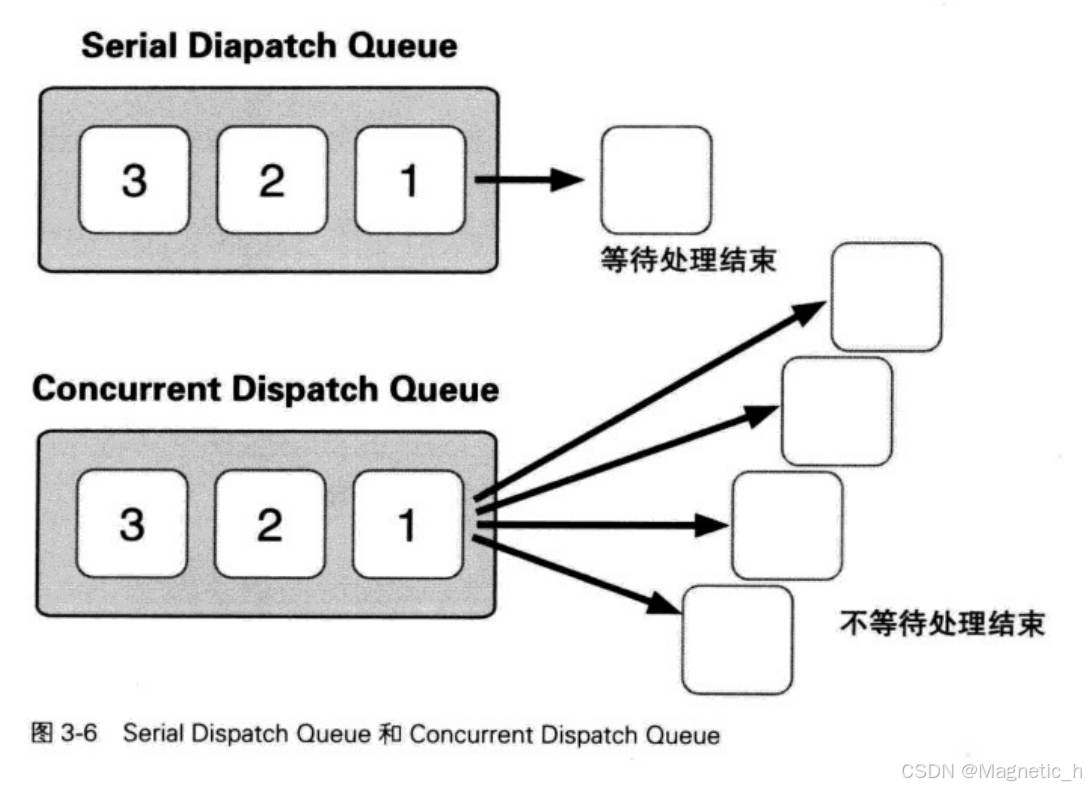
并发队列可以并行执行多个处理,但并行执行的处理数量取决于当前系统的状态。

有两种方法得到Dispatch Queue
dispatch_queue_create
第一种方法是通过GCD的API的生成Dispatch Queue
通过dispatch_queue_create函数可生成Dispatch Queue。
dispatch_queue_t mySerialDispatchQueue = dispatch_queue_create("com.example.gcd.MySerialDispatchQueue", NULL);这样就可以生成串行队列。使用这个函数可以生成多个Dispatch Queue。当生成多个Serial Dispacth Queue时,各个Serial Dispatch Queue将并行执行。

生成一个Serial Dispatch Queue,就会生成并使用一个线程,如果过多使用多线程,就会消耗大量内存。
只在为了避免数据竞争时使用串行队列:
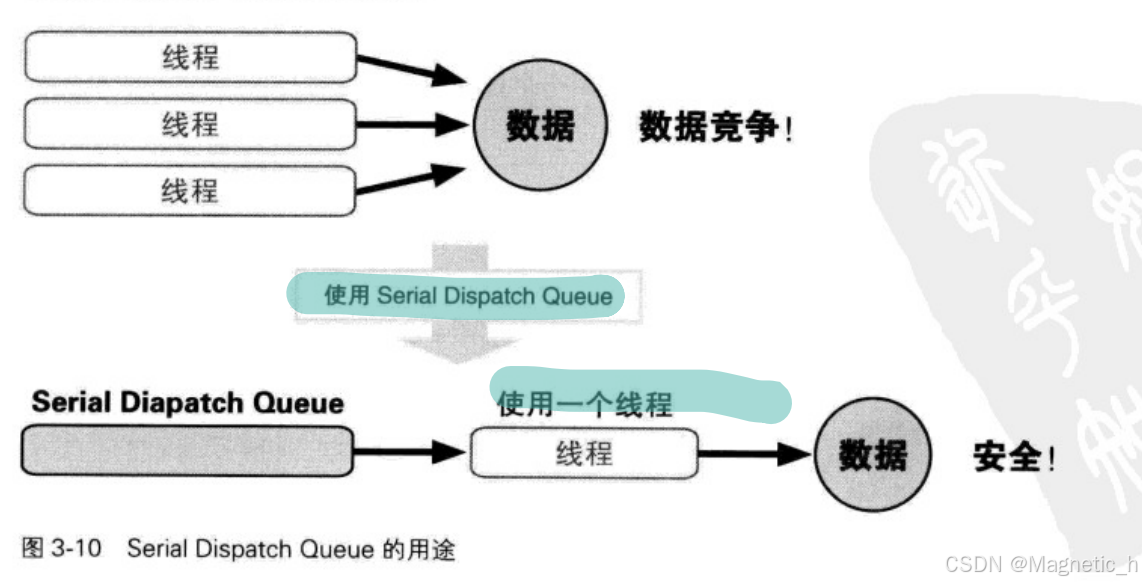
当想并行执行不发生数据竞争等问题的处理时,使用Concurrent Dispatch Queue(并发队列)。
生成并发队列,只需要改变函数的一个参数即可
dispatch_queue_t myConcurrentDispatchQueue = dispatch_queue_create("com.example.gcd.MyConcurrentDispatchQueue", DISPATCH_QUEUE_CONCURRNET);生成Serial Dispatch Queue时,将第二个参数指定为NULL,生成Concurrent Dispatch Queue时,将参数指定为DISPATCH_QUEUE_CONCURRENT。
尽管有ARC这一通过编译器自动管理内存的技术,但生成的Dispatch Queue必须由程序员负责释放,因为Dispatch Queue没有像Block那样具有作为OC对象处理的技术。
生成的Dispatch Queue在使用结束后通过dispatch_release函数释放。
dispatch_release(mySerialDispatchQueue);也有相应的retain函数:
dispatch_retain(myConcurrentDispatchQueue);可见Dispatch Queue也像OC的引用计数式内存管理一样,需要通过dispatch_retain函数和dispatch_release函数的引用计数来管理内存。
使用dispatch_retain函数和dispatch_release函数不仅是在Dispatch Queue中,在通过函数或方法获取Dispatch Queue以及其他名称中含有create的API生成的对象时,有必要通过dispatch_retain函数持有,并在不需要时通过dispatch_release函数释放。
Main Dispatch Queue/Global Dispatch Queue
第二种方法是获取系统标准的Dispatch Queue。
系统会给我们提供几个队列,Main Dispatch Queue和Global Dispatch Queue。
Main Dispatch Queue是在主线程中执行的Dispatch Queue,因为主线程只有1个,所以Main Dispatch Queue自然就是Serial Dispatch Queue。
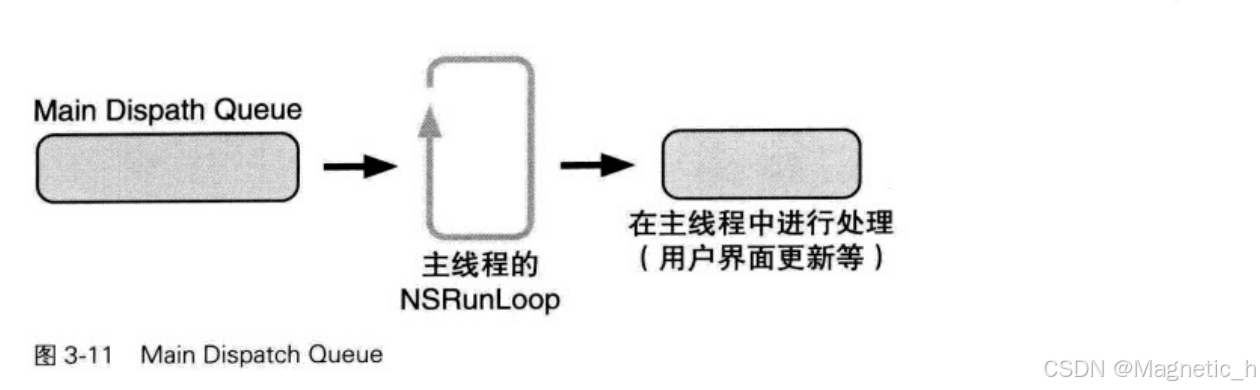
另一个Global Dispatch Queue是所有程序都能够使用的Concurrent Dispatch Queue,没必要逐个生成并发队列,只要获取Global Dispatch Queue使用即可。
Global Dispatch有4个执行优先级:

获取方法如下:
dispatch_queue_t mainDispatchQueue = dispatch_get_main_queue();//并发队列
dispatch queue_t globalDispatchQueueHigh = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0);//高优先级
dispatch queue_t globalDispatchQueueDefault = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);//默认优先级
dispatch queue_t globalDispatchQueueLow = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0);//低优先级
dispatch queue_t globalDispatchQueueBackground = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_BACKGROUND, 0);//后台优先级对于这两个队列,不必执行retain和release并且使用也不会有问题,不会有变化。
dispatch_set_target_queue
变更队列的执行优先级要使用dispatch_set_targer_queue函数。在后台执行动作处理的串行队列的生成方法如下:

将Dispatch Queue指定为参数,不仅可以改变执行优先级,还可以作为执行阶层。如果将多个串行队列指定目标为某一个串行队列,那么原本应并行执行的多个串行队列,在目标队列上只能同时执行一个处理。
dispatch_after
这个API可以在指定时间后执行处理。

需要注意,这个函数只是在指定时间后,将block追加到Dispatch Queue中。
因为Main Dispatch Queue在主线程的RunLoop中执行,所以会有一些延迟。
Dispatch_time_t值使用dispatch_time函数或dispatch_walltime函数做成。

数值和NSEC_PRE_SEC的乘积得到单位为毫微秒的数值。”ull“是C语言的数值字面量,时表明类型时使用的字符串(unsigned long long)。以下源代码获取表示从现在开始150毫秒后时间的值:

Dispatch_walltime函数用于计算绝对时间,比如可以指定XXXX年XX月XX日XX时XX分XX秒。
Dispatch Group
这个API可以在多个并发队列执行完成后进行结束处理:
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
didpatch_group_t group = dispatch_group_create();
dispatch_group_async(group, queue, ^{NSLog(@"blk0");});
dispatch_group_async(group, queue, ^{NSLog(@"blk1");});
dispatch_group_async(group, queue, ^{NSLog(@"blk2");});
dispatch_group_notify(group, dispatch_get_main_queue(), ^{NSLog(@"done");});
dispatch_release(group);也可以使用dispatch_group_wait函数等待全部处理结束:
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
didpatch_group_t group = dispatch_group_create();
dispatch_group_async(group, queue, ^{NSLog(@"blk0");});
dispatch_group_async(group, queue, ^{NSLog(@"blk1");});
dispatch_group_async(group, queue, ^{NSLog(@"blk2");});
dispatch_group_wait(group, DISPATCH_TIME_FOREVER);
dispatch_release(group);dispatch_barrier_async
这个函数可以等待追加到并发队列上的并行执行的处理结束后,再将指定的处理追加到Concurrent Dispatch Queue中。然后在处理完毕后,并发队列恢复一般的动作。

dispatch_sync
dispatch_async函数的“async”意味着“非同步”,就是将指定的Bloc k“非同步”地追加到指定的Dispatch Queue中。dispatch_async函数不做任何等待
dispatch_sync函数,意味着“同步”,在追加Block结束之前,dispatch_sync函数会一直等待。
这个函数很容易造成死锁:
dispatch_queue_t queue = dispatch_get_main_queue();
dispatch_sync(queue, ^{@"NSLog(@"Hello?")";});该代码就会造成死锁,主线程中执行Block,并等待执行结束,但主线程中正执行这些代码,所以无法执行追击到主线程队列的Block。
dispatch_apply
Dispatch_apply函数是dispatch_sync和Dispatch Group的关联API,该函数按指定的次数将指定的Block追加到指定队列中,并等待全部处理执行结束。
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_apply(10, queue, ^(size_t index) {
NSLog(@"%zu", index);
});
NSLog(@"done");dispatch_apply函数会等待全部处理执行结束。
执行结果:

现在对NSArray类所有元素执行处理,不必再编写for循环:
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
dispatch_apply([array count], queue, ^(size_t index) {
NSLog(@"%zu: %@", index, [array objectAtIndex:index]);
})这样就可以对所有元素执行Block。
dispatch_suspend/dispatch_resume
当追加大量处理到Dispatch Queue时,有时不希望执行已追加的处理,这时可以挂起该队列
dispatch_suspend(queue);//挂起
dispatch_resume(queue);//恢复Dispatch Semaphore
并行更新数据时,会产生数据不一致的情况,有一种比串行队列和栅栏更细粒度的排他控制,就是Dispatch Semaphore。
Dispatch Semaphore 是持有计数的信号,该计数是多线程编程中的计数类型信号。类似过马路手旗,可通过时举起手旗,不可通过时放下手旗。Dispatch Semaphore使用计数来实现该功能,计数为0时等待,计数为1或大于1时,减去1而不等待。
使用方法如下:
dispatch_semaphore_t semaphore = dispatch_semaphore_create(1);本例将计数值初始化为1,并且该类可以有dispatch_retain和dispatch_release管理引用计数。
可以通过dispatch_semaphore_signal函数将Dispatch Semaphore 的计数值加1。
dispatch_once
dispatch_once函数是保证在程序中只执行一次的API,使用该API可以简化单例的初始化:
static dispatch_once_t pred;
dispatch_once (&pred, ^{
//初始化
});Dispatch I/O
读取较大文件时,可以将文件分成合适大小使用多个线程并列读取,实现该功能的是Dispatch I/O和Dispatch Data
苹果官方使用的例子:
