目录
特殊符号
1.@(取消显化)
@的作用:执行指令,但指令本身不会显化;
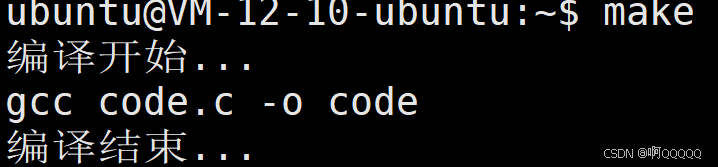
举个例子:我在编译code文件的同时打印一些注释;
code:code.c
echo "编译开始..."
gcc code.c -o code
echo "编译结束..."
.PHONY:clean
clean:
rm -f code
echo "清理文件完毕..." 但是实际上执行make后的结果并和我们想的不一样:因为默认下,makefile文件会执行指令语句,并且把指令显化;

对于这种问题,我们只需要在不需要显化的雨具前面加上@,就可以告诉makefile,只执行指令,不显化;
2.%(通配符)和$<(将文件挨个传递)和$^(将全部文件一块执行指令)
在Linux的makefile中
%被视作为通配符,比如%.c就是代表所有的.c任意以点.c结尾的文件;
$<:将文件中的一个一个的分别都指令依次该指令;注意:1.$<和$^是相对依赖文件而言的并不能对目标文件使用;
2,在编译时,目标文件只能有一个,如果有多个,就需要指定新的规则;现在我们默认为多个木匾文件是不允许的;
这么说比较抽象,我们来看个例子:
1.使用文件变量将多个文件编译同时编译
这里我以new.c和new.h为例,将他们同时编译生成可执行文件new;
dest=new
src=new.c new.h
$(dest):$(src)
gcc $^ -o $@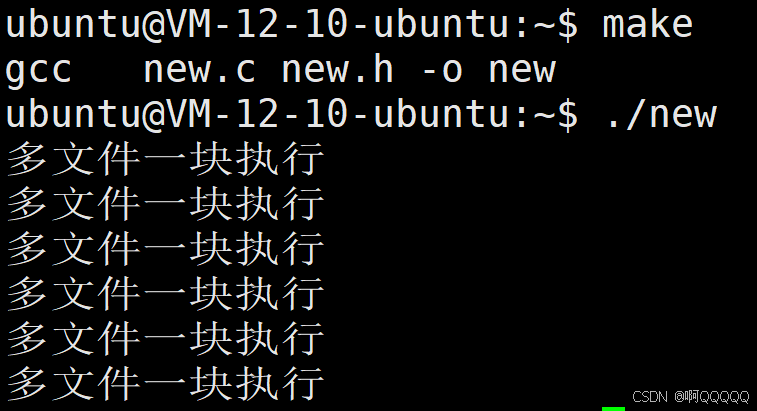
dest和src是两个文件变量,用于储存文件地址,$(文件变量)就相当于是对文件解引用了;$^此时就是new.c 和new.h两个组成的整体;$@就是目标文件new;
这里的$@是可以替换成$(dest)的;
2.如何同时编译两个可执行程序
这里我们需要使用伪目标all;
.PHONY:all
all:code proc
code:code.c
gcc code.c -o code
proc:proc.c
gcc proc.c -o proc
.PHONY:clean
clean:
rm -rf code proc这里的all的依赖关系其实是一个幌子,因为查找是从上往下的,all需要依赖可执行程序code和proc,那么makefile就会向下继续执行指令,直到将code和proc生成,生成后而我们并没有使用code和proc对all进行什么操作;然后就结束了;在此过程中all其实就是一个引子, 通过依赖关系引出code和proc;实际上并非是all依赖于code和proc;
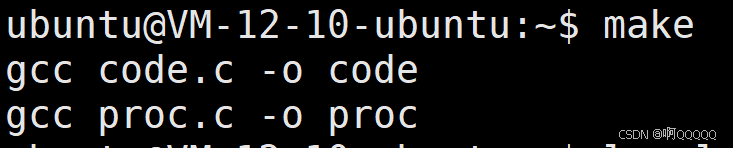
此时我们make一下,两个文件就会同时编译生成可执行文件了;
Linux小程序---进度条
1.\n和\r的理解
回车和换行其实是两个概念,顾名思义,回车就是回到行的开头,换行就仅仅只是到了下一行而已,列的位置并没有发生改变;
我们所使用的\n其实是别人优化好的回车和换行的组合;真要区分\n是换行,\r是回车;
2.缓冲区
接下来要用到sleep函数,我们现在看一下他的介绍;
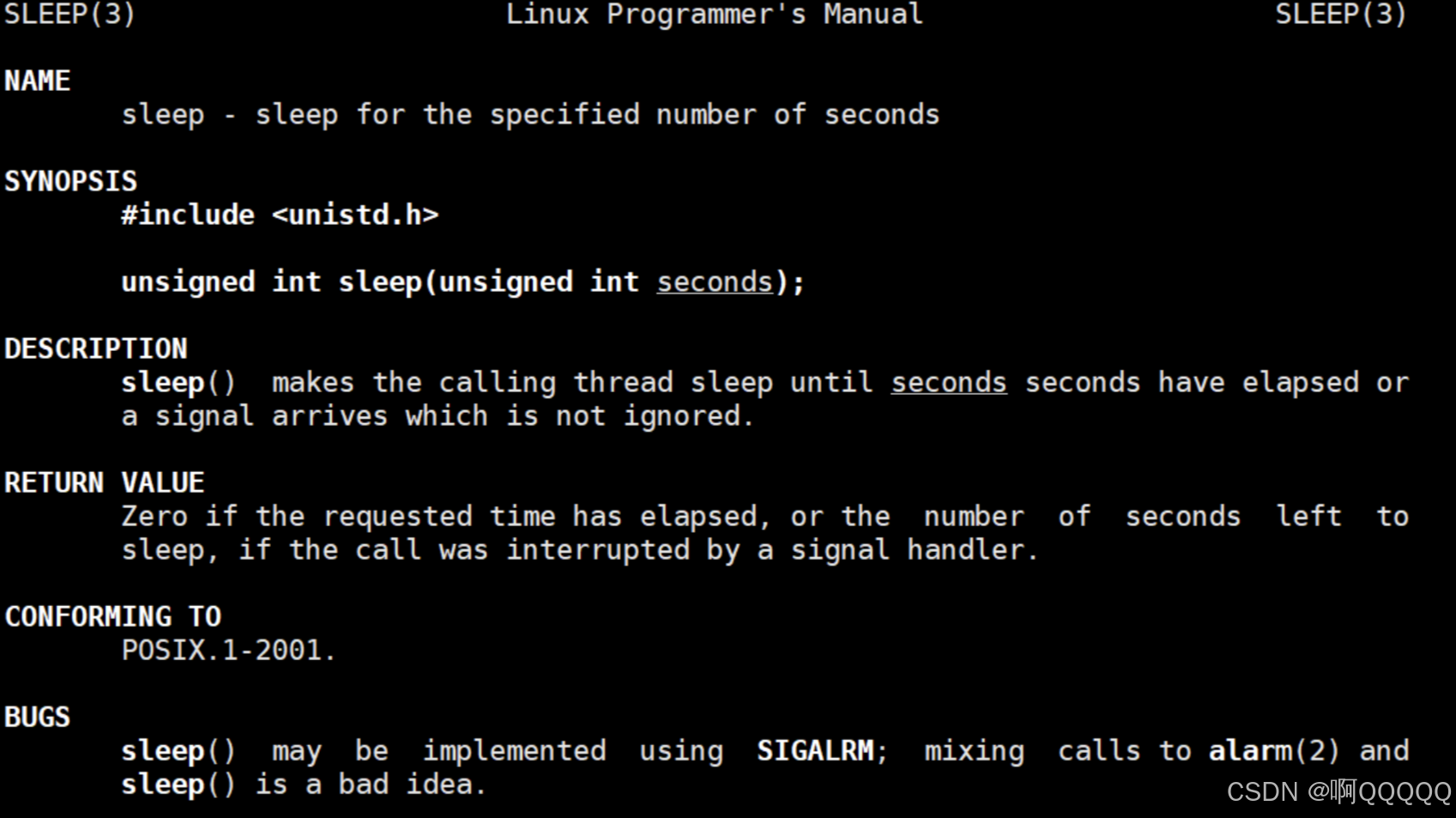
sleep为休眠函数,单位是秒;头文件是unistd.h;
接下来我们用sleep来区分一下\n和\r
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("hello linux\n");
sleep(2);
}这里的运行结果是先打印"hello Linux,并且换行,2秒之后才出现了指令行;这都没什么问题;
但是如果我把\n删除了呢,这时会是什么结果?
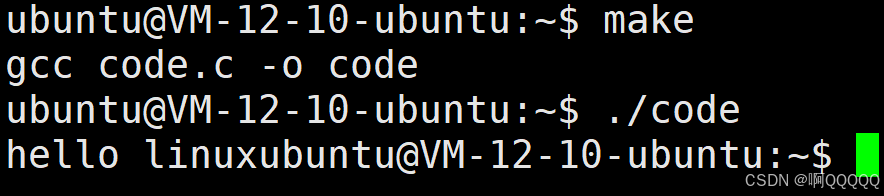
运行结果并没有先打印"hello linux"而是2秒之后,hello linux和指令行一块打印出来了;
思考:为什么没有先打印hello linux呢?
printf("hello linux");没有换行,执行完这条语句其实是储存在缓冲区中的,缓冲区没有满或者没有被刷新在程序结束之前是不会输出的,这就是为什么没有先打印hello linux的原因;
这段程序中,缓冲区没有在sleep之前刷新,而是睡眠后,等到了程序结束,自动刷新了缓冲区;这时才打印了字符串;
如果我们想要不换行就可以解决缓冲区不刷新的问题,那就需要fflush(stdout)对缓冲区进行强制刷新;
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("hello linux");
fflush(stdout);
sleep(2);
}
这个时候执行完printf后就会在睡眠之前打印字符串;
3.设计简单的倒计时
我们需要三个文件processbar.c processbar.h main.c
接下来我们实现一个倒计时为10的计时器;
我们需要考虑几个问题::
1.倒计时其实就是一个数字然后递减打印;
2.每次打印之间需要有时间间隔;
3.打印之前需要覆盖之前的数字;
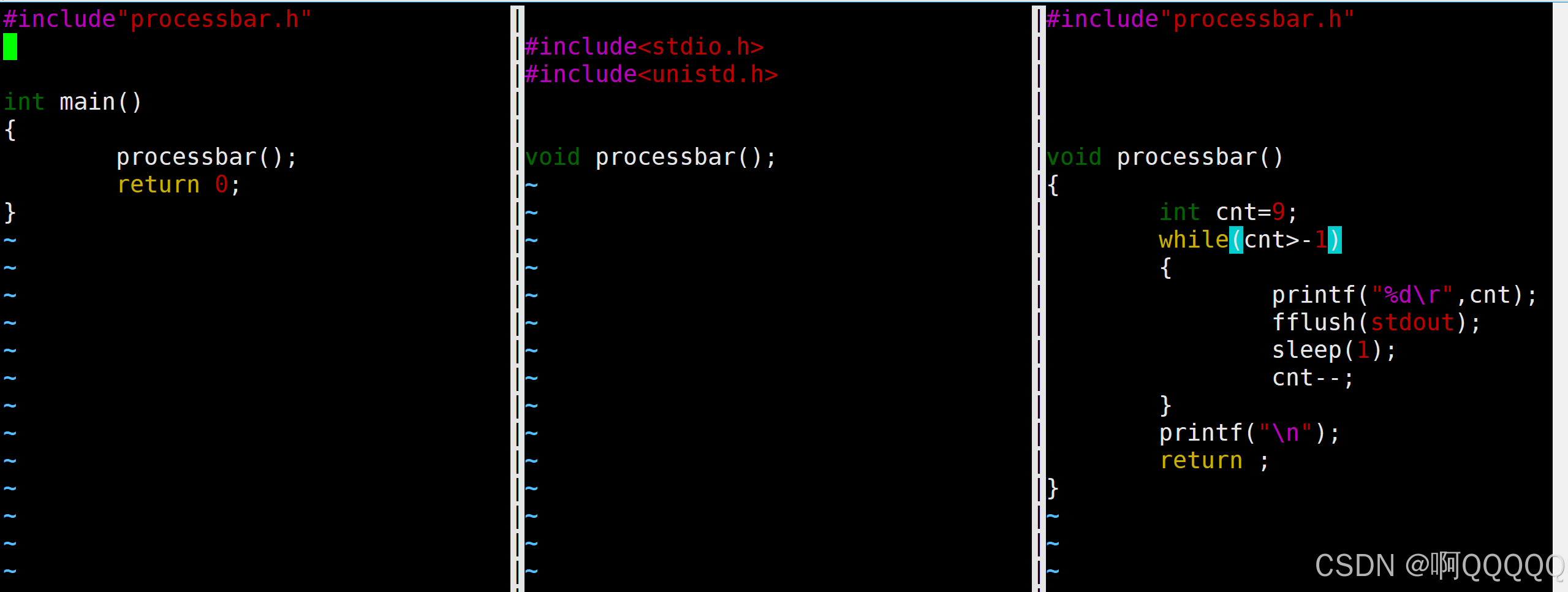

但是如果我们打印从10开始的倒计时,一开始是两位数,后面变成了一位数,那这是第二位数是没有被覆盖的;因此我们需要调整下格式为2个宽度,左对齐;
4.设计简单的进度条
1.'#'持续推进,
2,每一部分需要使用[]括起来;
3.还需要有进度百分数,类似于旋转加载的符号
这里我们使用laebl="/|-\\"来模拟加载的符号;
void processbar()
{
const char* label="/|-\\";
char bar[NUM];
memset(bar,'\0',sizeof bar);
int cnt=0;
int len=strlen(label);
while(cnt<=100)
{
printf("[%-100s][%d%%][%c]\r",bar,cnt,label[cnt%len]);
fflush(stdout);
bar[cnt++]=STYLE;
usleep(10000);
}
printf("\n");
return ;
}

设计进度条外部调用版本
#include"processbar.h"
const char* label="/|-\\";
char bar[NUM];
void processbar(int rate)
{
if(rate<0||rate>100)return ; int len=strlen(label); printf("[%-100s][%d%%][%c]\r",bar,rate,label[rate%len]);
fflush(stdout);
bar[rate++]=STYLE;
}
#include "processbar.h"
int main()
{
int total=1000;
int cur=0;
while(cur<=total)
{
processbar(cur*100/total);
cur+=10;
usleep(50000);
}
printf("\n");
return 0;
}
git-版本控制器
安装git指令
root用户:
yum install gitubuntu用户:
sudo apt install -y git1.理解什么是版本控制器?
讲一个故事:
比方说老师要求我们交一份实验报告,而你的室友张三是一个非常勤奋的人,所以他很早就写好了第一版交给老师,但老师的要求很高,他觉得第一版不行,给了他一些修改意见,然后他在第一版的基础上写完第二版后,老师还是不满意,他又在第二版的基础上写出了第三版……就这样一直下去,当张三写到第八版的时候,老师发现他越改越差,还不如第二版,于是让张三交第二版就行,但此时张三就慌了,因为他一直在原来版本上修改,所以早就忘了第二版是什么样子的了。而你吸取了张三的教训,你也开始做实验报告,但是跟张三不同的是,每次老师给你打回来的时候,你都会将原先版本给保存一份然后再去修改,最后当老师想要第二版的时候,你就可以直接可以把第二版拿出来。(我在有意识地在保留前面的版本,因为可能未来会用到)
除此之外还有其他同学也要交实验报告,于是你想到了一个办法,你在老师办公室门口贴了一个告示“这个老师可能改到最后会需要之前的版本,你们可以加我微信,我给你们提供保存之前版本的服务”,于是乎很多同学开始加你的微信,然后你就开始给李四、王五、赵六……分别建了目录,他们会将旧的版本发给你保存,然后当他们需要的时候,找到你就可以找到之前的版本了。(说明许多人会存在这样的需求,可以提供相关的服务)
但是你的业务做得越来越大,你不断在复制和粘贴,不断有人找你索要之前的版本,你有点忙不过来了,于是你在思考:其实版本管理本质上不就是对文件进行重命名、拷贝等工作吗??那我能不能写一些软件来自动化这些无聊繁琐的工作??于是乎你写出了两个软件,一个是服务端负责版本管理,另一个是客户端负责给用户查看。然后你把两个软件合成了一个既可以做服务端也可以做客户端的软件(版本控制器的雏形开始出现了)
你给自己放置版本的地方起名叫做仓库,而当别人下载了你的软件之后,他如果在自己的电脑上做版本控制,那就是本地仓库,但是他可能会担心本地仓库的东西丢失,于是他又使用了你提供的云服务器,那就是远端仓库,然后推送到远端仓库。(所以git其实就是一款服务端和客户端为一体且具有网络功能的版本控制器,作用其实就是一种将客户的本地仓库和由你提供的云服务器上的远端仓库建立一个联系,帮助我们更好的版本管理和控制,远端仓库一般是大公司提供的云服务器,一般不会出问题,可以有效防止文件丢失)
其实实验报告都是有模版的,所以我们并不是非要每个人都写一份,可以是共同维护一份,这个操作就可以在远端进行(所以git还有一个作用就是方便多人协作)
总结:
1、git是一款服务端和客户端为一体的具有网络功能的版本控制器
2、方便多人协作
当然在现实中,其实例子中的老师就相当于是我们的产品经理,而学生就相当于程序员,一个团队里面产品经理需要去分析用户的需求,然后再分工给程序员去完成项目,但是客户的需求可能是会不断发生变化的,所以这也就意味着我们需要对每一个版本都进行有效的管理和保持。
2.git的使用
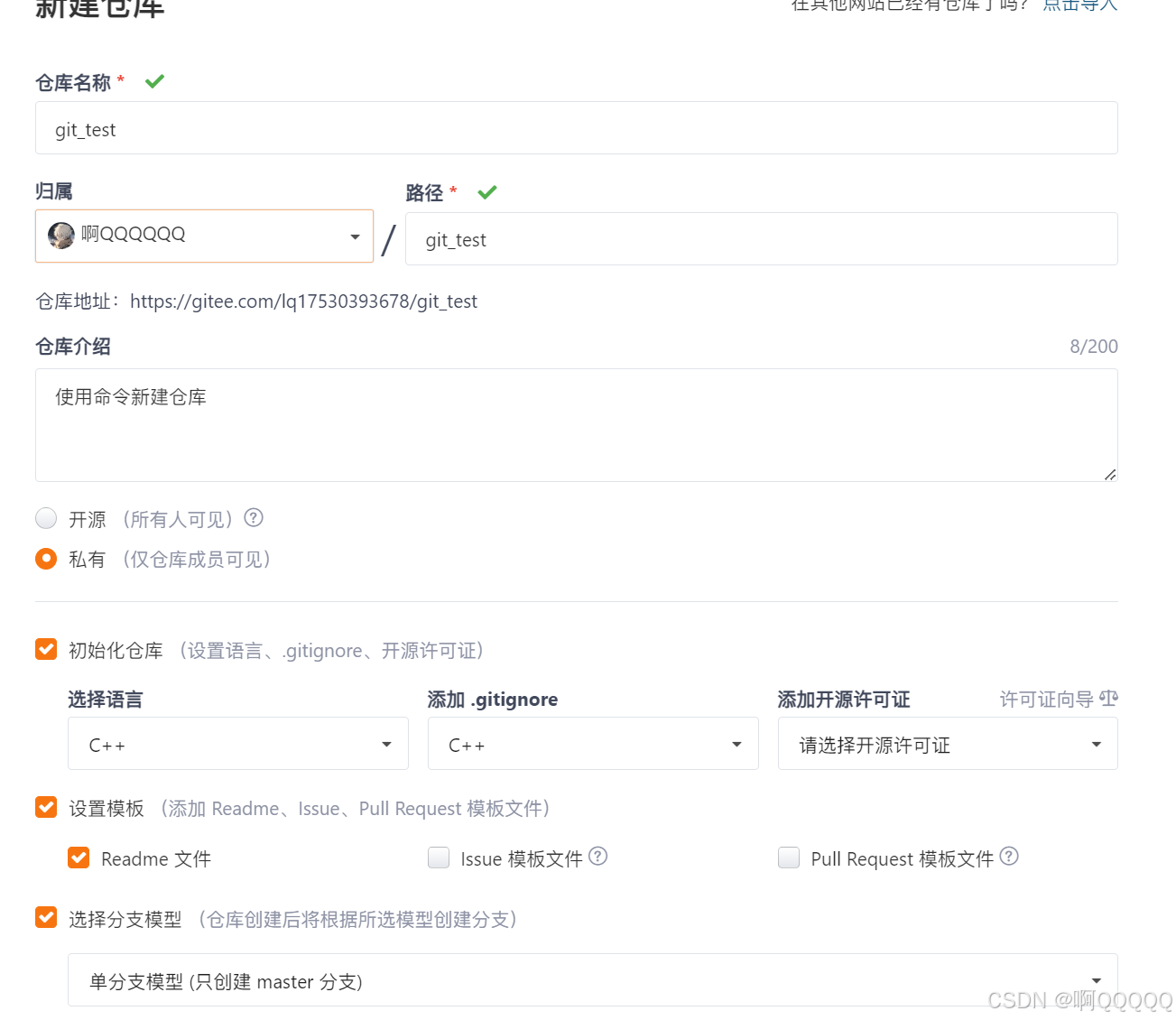
创建之后点击克隆;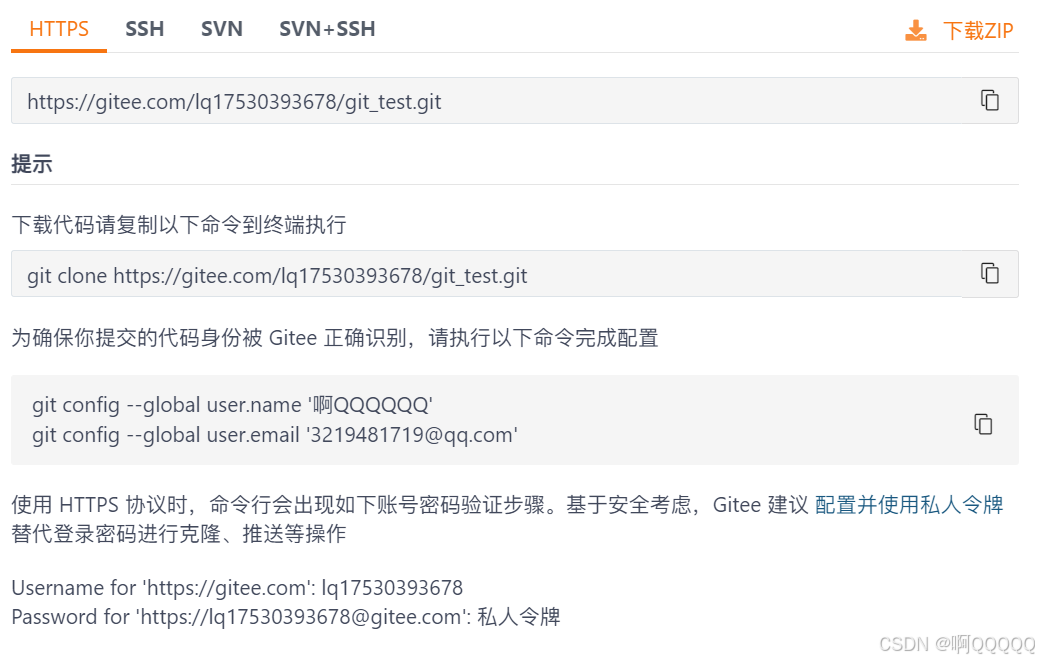
使用指令(注意这里的仓库地址,是你自己的仓库地址)
git clone https://gitee.com/lq17530393678/git_test.git这里输入完指令后,会确认你的身份;你需要按照指示复制就可以了;私人令牌你自己创建一个就可以了;
注意:私人令牌之后就无法查看了,一定要保存好,截图或者把字符串拷贝下来;

创建成功后赋值令牌到命令行就确认身份成功了;
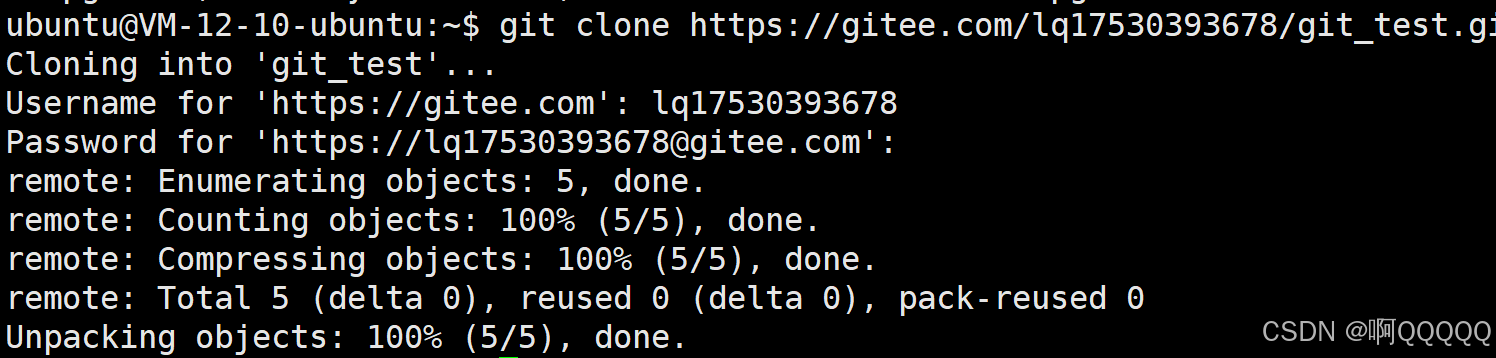
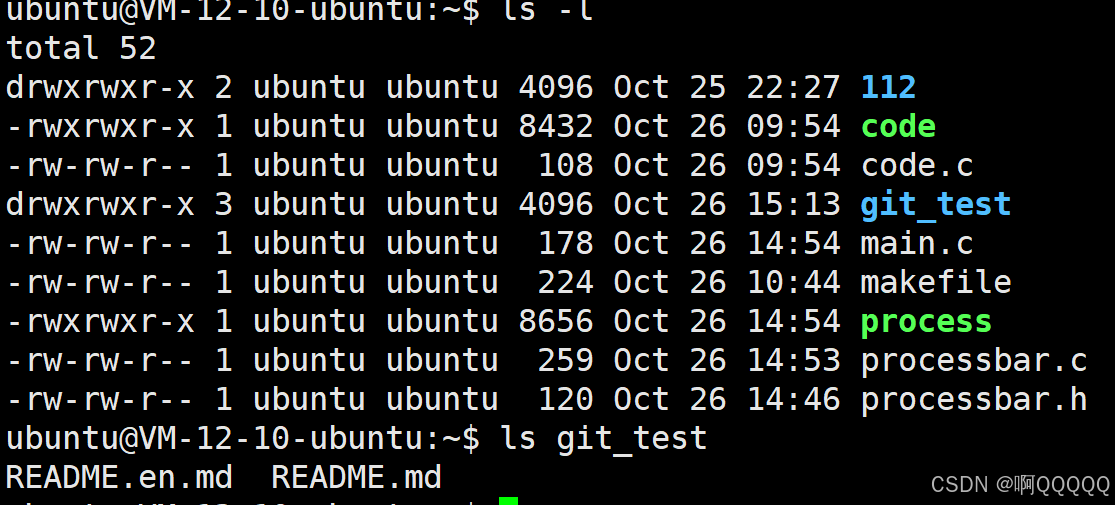
然后发现 在当前目录下出现了你的新建仓库文件(git_test);这个文件就是你仓库;以后我们只需要把文件放在git_test仓库中就可以了;
现在我将code.c拷贝一份放在了gittest中,试着将gittest传到仓库git_test中;
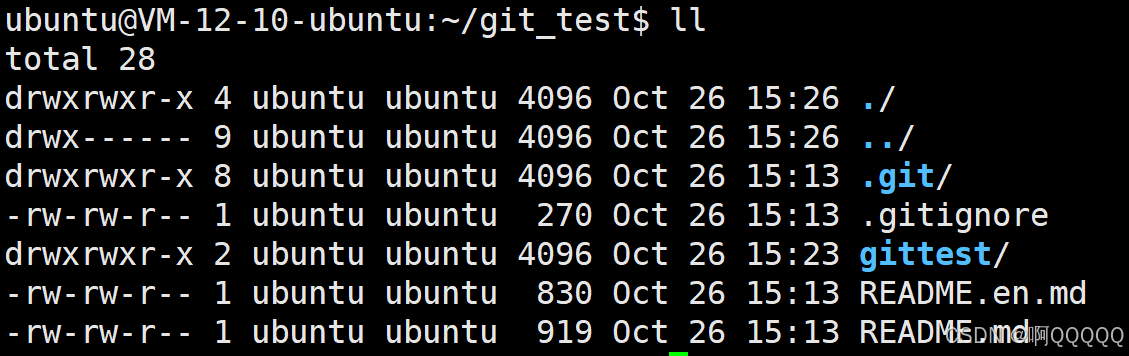
在此目录下使用指令:
git add . #add和.不能挨着
git commit -m "hello linux" #这里的备注一定要好好写

git push
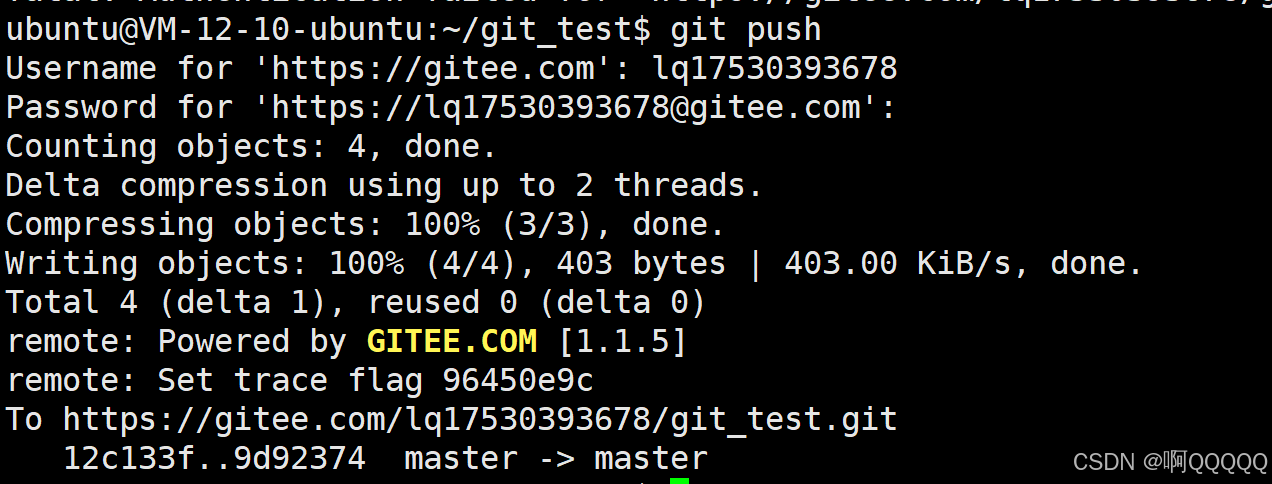
到这里,我们发现仓库中出现了刚才的测试文件;
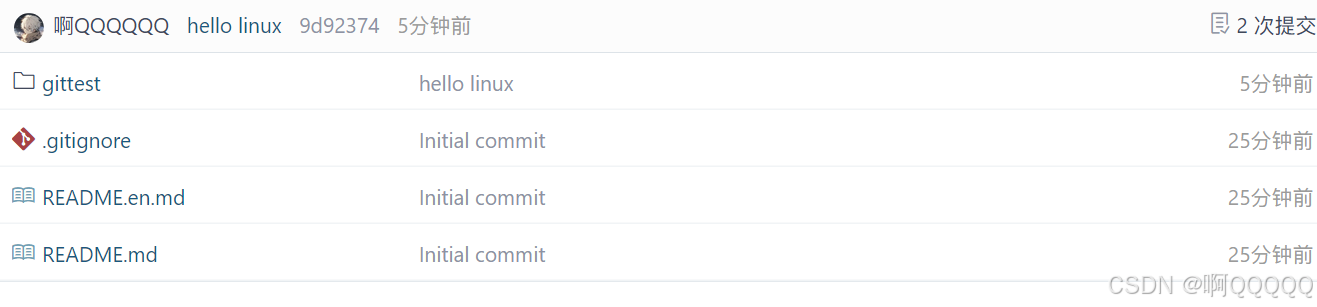
其实这也对应了再windows中的我们上传代码的方式;
在windows中,我们就是先把目标文件放到仓库中,然后将文件add ->commit->push;步骤是一样的;
3.git的其他说明
1.我们还可以查看git仓库的提交记录,(到这里我们就可以发现,在git仓库下执行的命令都是git +指令)
git log
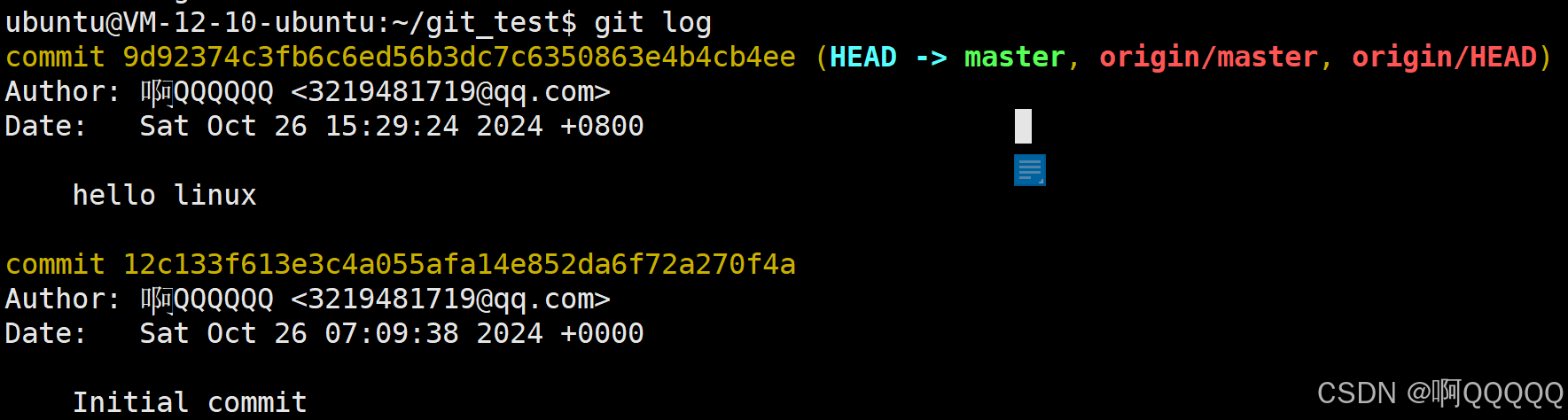
2. 还可以查看当前目录的状态
git status
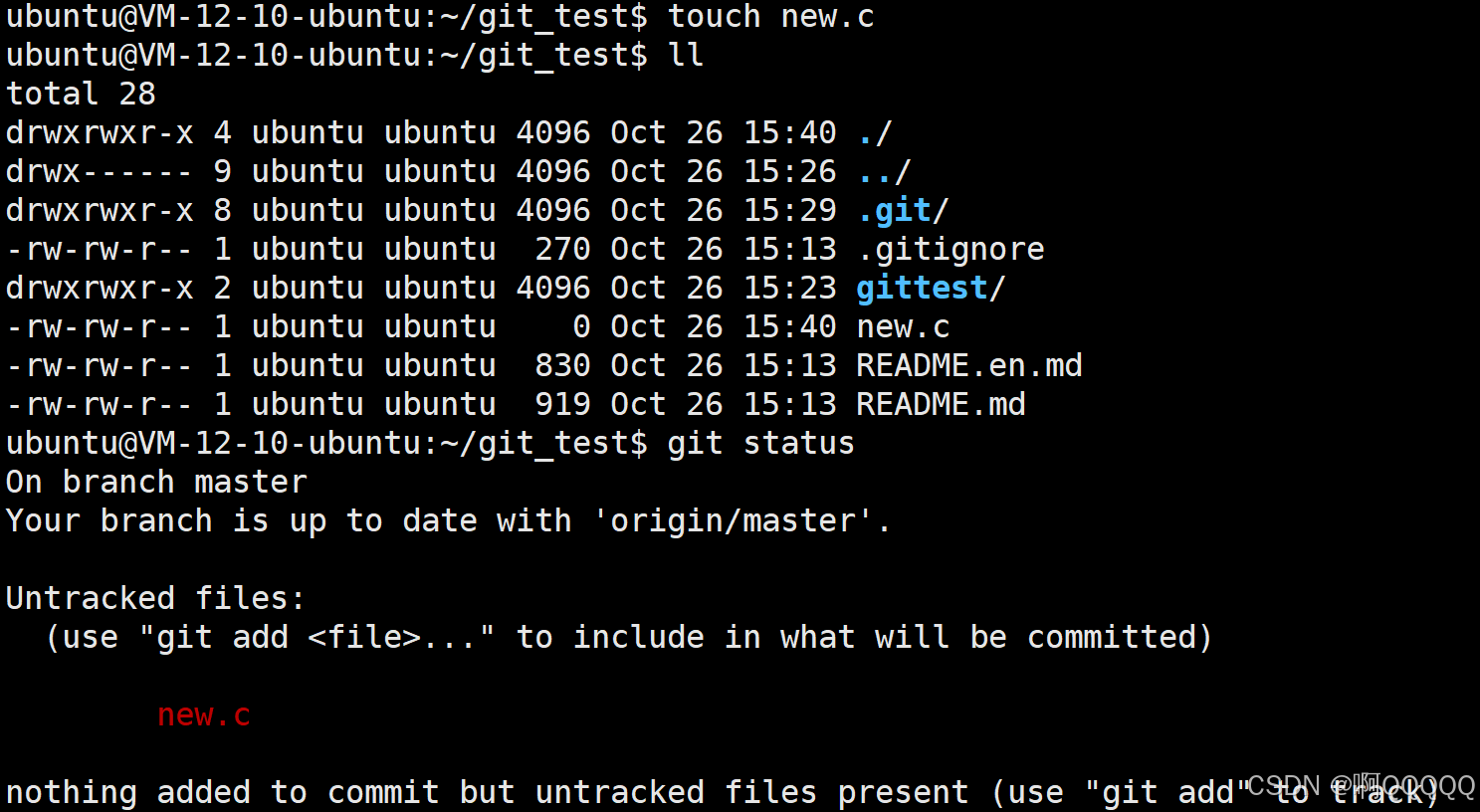
我在仓库里创建了一个新文件,但是这时候并不能说明,他就在远程仓库里,因为我还没上传,这时候他与远程仓库没有任何关系;正如提示所说,"use ""git add ....."下一步应该添加该文件;
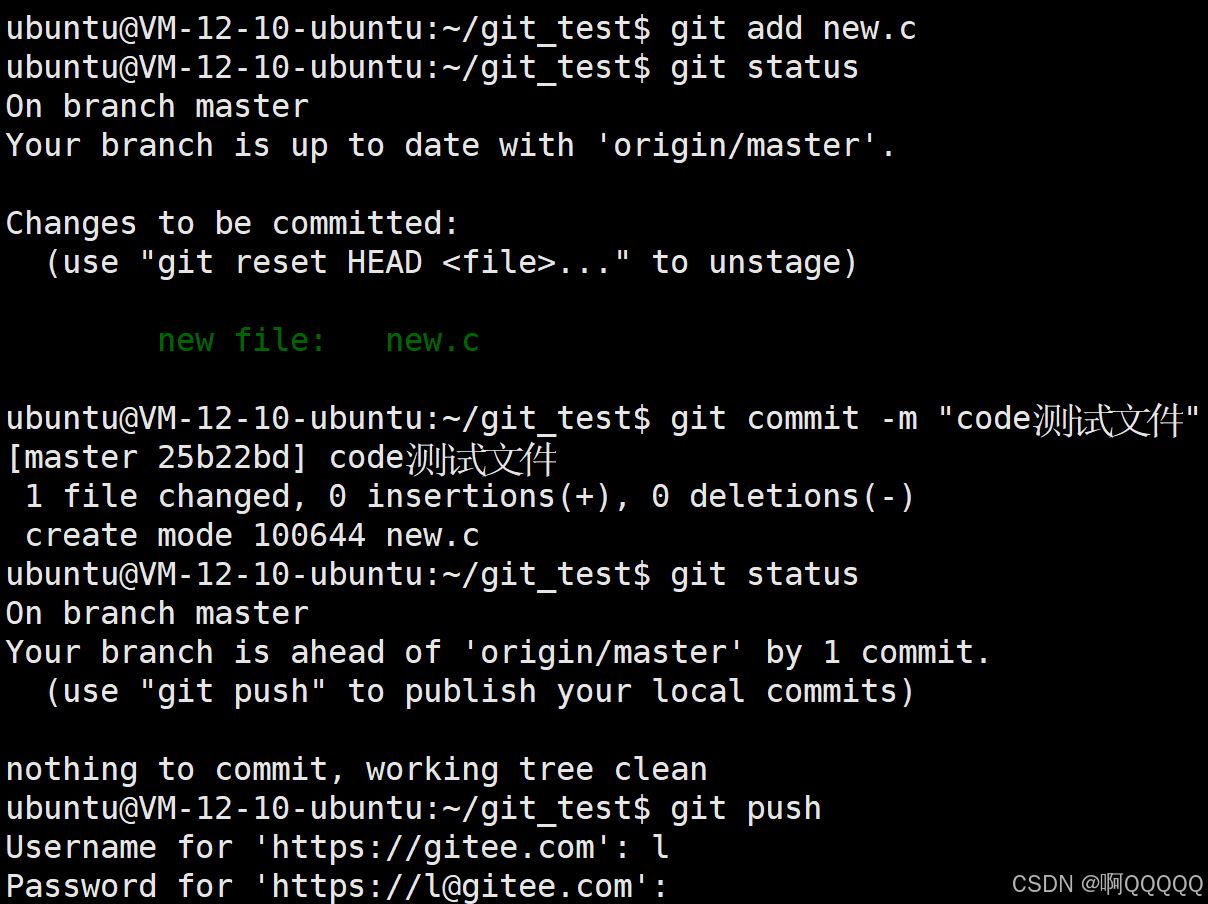
在push之前在gitee网页上是看不到的;我们push之后才可以看到 ;
总结上传过程
我们如果要把文件上传到git仓库中骂我们需要先把文件上传到本地仓库,本地仓库就是我们通过gitee上仓库地址克隆的;而git就是远程仓库,gitee是git的可视化软件网页;
1.add:add的作用就是将当前仓库下的(未add)的文件提交到工作区(这个了解即可);
2.commit(提交):commit的作用是将工作区的文件提交到本地仓库,没错,就是本地仓库,这里有一个易错点;
仅仅将文件拉到git仓库文件里并不算是添加进了仓库;就好像你是110班的你要转班,进到了112班级里,虽然你跟别人在同一个屋子里,但是你的身份并不是112的;你需要经过一定的流程才能成功转班;
现在,你平白无故坐在了112班里,而这个班的老师看你不是本班的学生,就问你,你说你想要来112班上课,这时候就相当于是给仓库的管理员传达了指令我要add进你们班,然后老师(工作区)给了你一个申请表,你会去写完后,交给了老师这就是commit操作,将工作区的文件提交到本地仓库,然后老师把你的申请表push给了领导,成功后,领导把教务系统(远程仓库)的数据修改,你才能正式变成112班的学生;
3.push:将本地仓库的文件同步到远程仓库;这个本地仓库上传是否成功是有图标显示的;而查看是否成功传到远端仓库需要我们打开gitee网页,查看是否有目标文件即可;所以综合下来共有下面几种情况:
1.没有add:在git本地仓库的目录下,但是并未添加到工作区,也就是并没有准备上传;
2.add了没有commit:add之后文件添加到了工作区,但是没有提交到本地仓库;
3.commit了没有push:提交到了本地仓库,没有同步到远程仓库,这是并不能起到安全的保存代码,仅仅是原代码的拷贝文件而已;
4.三个操作都做了:本地仓库有文件的拷贝,远程仓库也有文件的拷贝,本地仓库不小心搞丢了或搞坏了,都无伤大雅,远程仓库人家公司帮你把门呢;在gitee就能使用;
4..gitignore可以忽视我们不想上传的文件
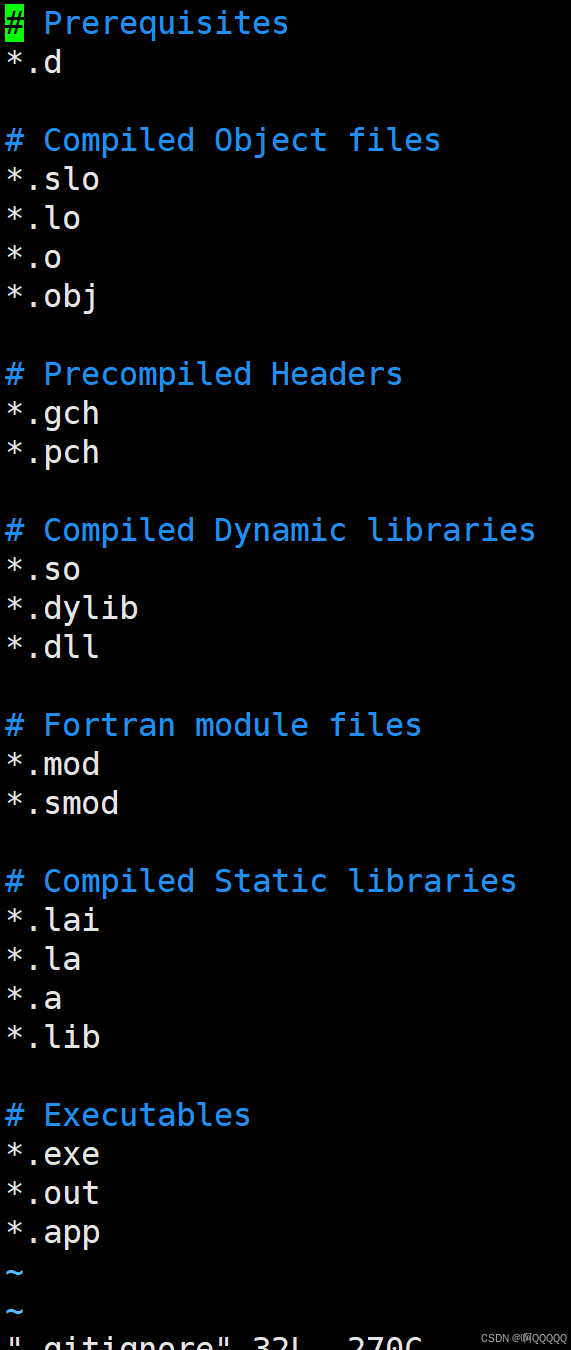
1.这是一个配置的文件,以文件中出现的后缀的文件,是不允许被添加进git仓库中的;
2.*是一个通配符,我们在前面因为学过通配符%,*的范围更大,%是当前目录下的通配符,*是系统的通配符;
3.文件是可以自行配置的,可以自己另行添加不行上传的以某种后缀结尾的文件;
如何解决免密码问题
1.进入你的git本地仓库目录;
2.输入指令git config --global credential.helper store
3.在输入一次你的用户名和私人令牌码
之后再次push就不需要每次身份认证了;