在回归分析浅析中篇的文章中,
有人问了一个问题:
案例里的calls数据貌似离散,更符合泊松模型,为啥不采用泊松而采用高斯呢?
确实,在中篇中写道:
在这个例子中我们为了更好地解释变量,使用高斯模型代替更适合的泊松模型。
这句话该怎么理解呢?
一般情况下,拿到研究数据之后,如果我们计划使用GLR工具,首先需要判断使用哪个模型,使用哪个模型是由数据来确定的,当数据都是整数时,究竟是用高斯还是泊松呢?
我们知道,高斯模型需要满足数据正态分布。在Pro中如何看数据是否正态分布呢?
打开Pro,在内容列表中选择包含因变量的原始图层,选择创建图表,点击直方图就可以查看数据的分布形态了。
在图表属性中选择数值变量为Calls
存在变换三种形式,无变换、对数变换以及平方根变换。默认情况下选择无变换。
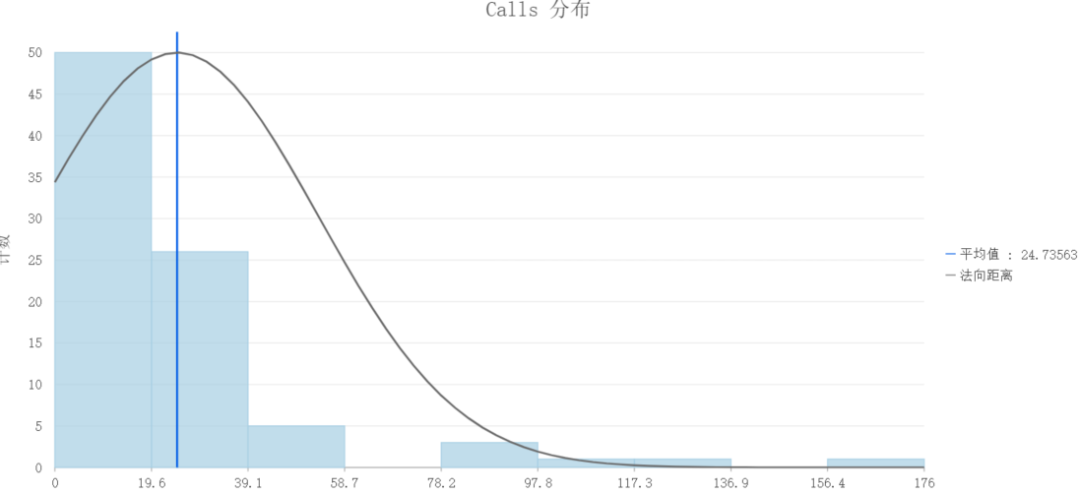
其中横轴是Calls值,纵轴为Calls的数量。
很显然,当前数据是偏斜的,并不是正态分布的。这种情况下是不建议选择高斯模型,更推荐使用泊松的。
但是很多情况下,高斯的性能或者说拟合度都要好于泊松。(大家可以尝试使用本例中的数据,再结合GLR工具中的泊松模型得出该模型的拟合度)
所以为了向高斯模型靠拢,提高模型精度,会尝试将数据进行变换。
你可以理解为在某种程度上,变换可以认为并非在调整数据,而是换个角度看数据,比如说圆柱体完全水平的看截面是正方形,而从顶上垂直俯视是圆形。怎么看(变换),都不会改变数据的最终表现,只是让我们从某个角度更容易的理解它而已。
god xia,公众号:虾神说D[虾答]莫兰指数计算时只能用原始数据还是也能用取对数后的数据?
以上内容引自虾神卢(下一篇会附上他的公众号)关于变换内容的说明
将数据进行变换,也就是尝试使用对数变换以及平方根变换,再来确定数据是不是正态分布的。如果变换后数据是正态分布的,我们仍然可以选择高斯模型来对变量之间的线性关系进行建模。
在这里我们尝试使用平方根变换。
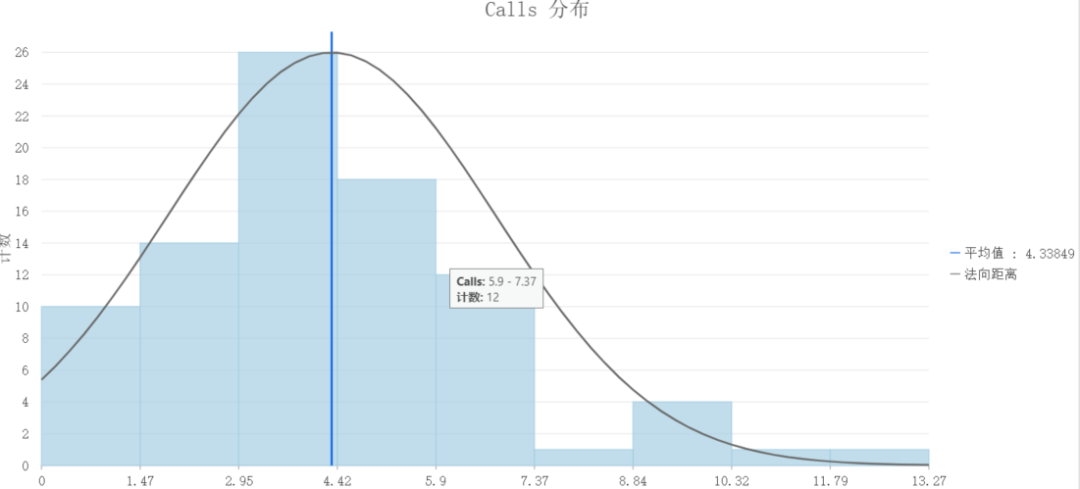
很不幸。仍然不是正态分布。
但是上述这种,数据变换之后呈现正态分布的情况确实存在。例如这里我们使用了房价数据进行比较。
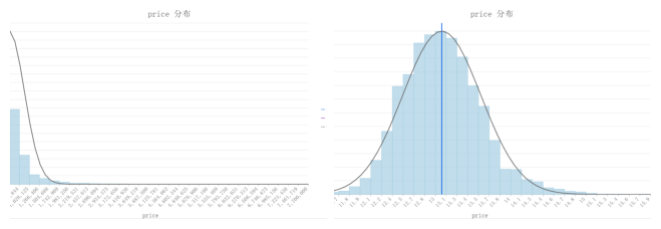
房价无变换 房价对数变换
非正态分布 呈正态分布
所以,严格来说,本例中使用高斯模型来进行数据的分析和预测是存在问题的。(同学们千万注意)
本例中,我们的本意是想讲清楚高斯模型中的众多的结果指标,并得出GLR工具在本例中并不平稳的结论。大家可以理解其方法和思路。
同一数据泊松分布的结果如下
:
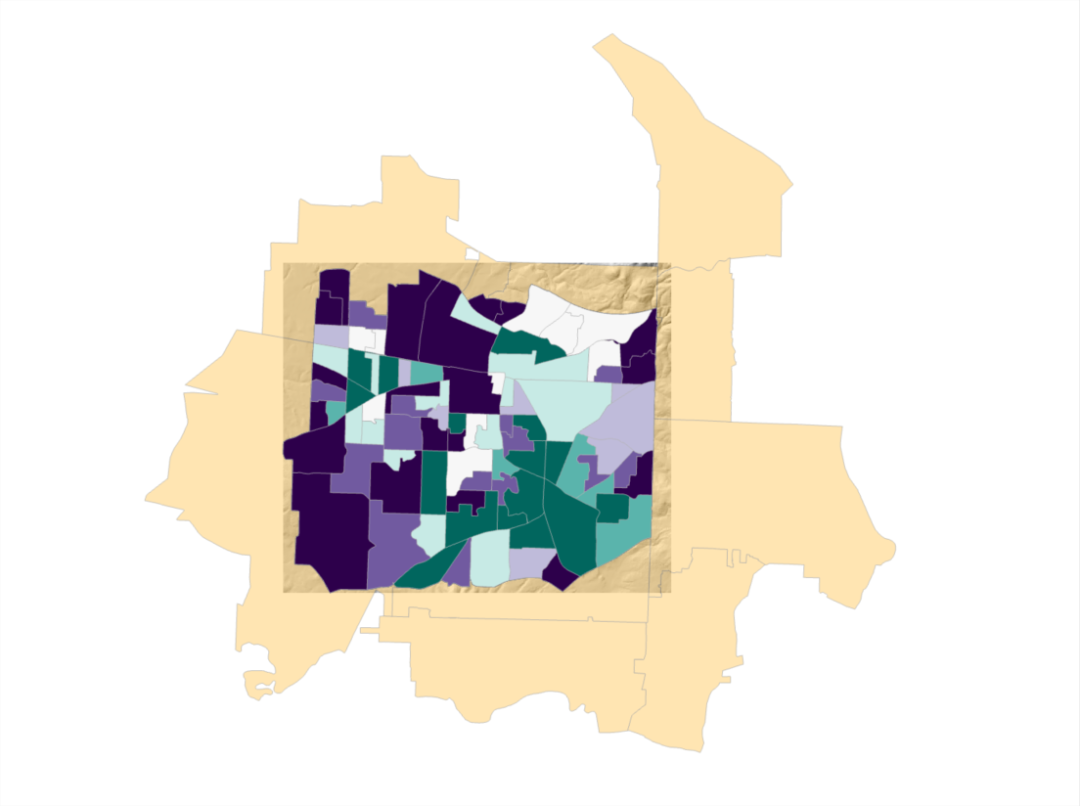
地图视图结果展示
地图视图中增加了GLRPossionData911Calls图层。并使用偏差残差(非标准化残差)来进行渲染。

内容列表中的GLRData911Calls图层
同时增加了3个图表。图表与结果是相互印证的,因此在这里我们主要分析GLRPossionData911Calls图层的内容以及结果运行出来之后的详细信息。
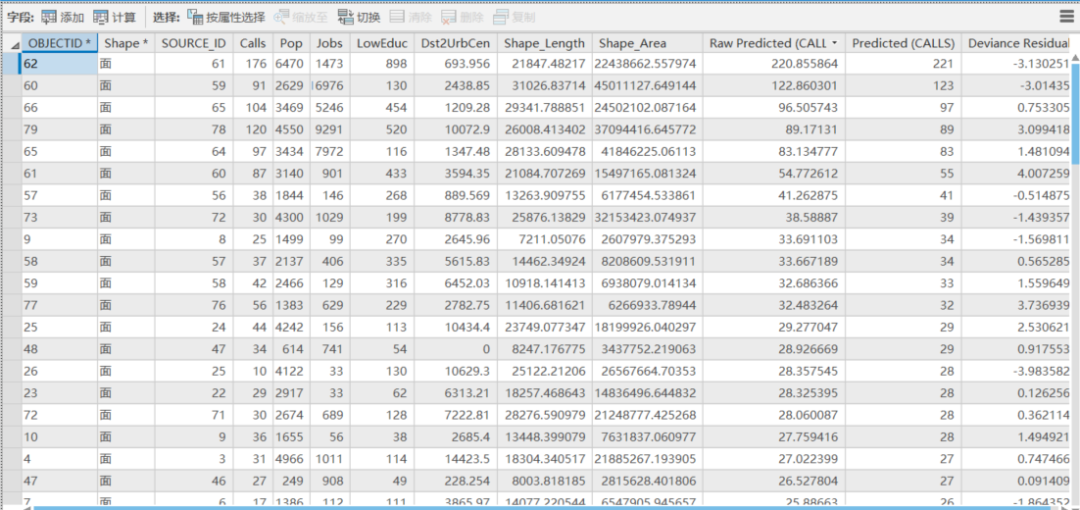
与原始的ObsData911Calls相比较,保留了全部要素的Calls、Pop, Jobs, LowEduc, Dst2UrbCen也就是因变量和解释变量属性,增加了Raw Predicted(CALLS)、Predicted(CALLS)字段也就是因变量的预测值,以及Deviance Residual(偏差残差)这三个字段。
其中偏差残差也反应了预测值与实际值之间的差异,这个与标准残差不同,没有大于2.5或者小于-2.5的限制。
再来看泊松模型的GLR结果

可以发现结果与高斯模型的结果类似,都包含了系数、概率和VIF。这些要求比如概率带星号,VIF不能大于7.5的要求都是相同的。
GLR的诊断中已解释偏差表明因变量中有多少变化可以由模型解释,也叫作模型拟合优度,类似高斯模型中的R方。
从这里我们也能看出,本例中,泊松的拟合结果比高斯的要低。
本例中,我们提供的数据不是特别理想,导致模型的选择容易混淆。在云盘连接中,我们还补充了房产数据,符合高斯模型,大家可以尝试一下。链接:
链接:https://pan.baidu.com/s/17KFw8l5PeBQMAgtAjKU80Q?pwd=1vsl
提取码:1vsl