听说这里是目录哦
通过Web UI查看Hadoop运行状态🐇
一、关闭防火墙
在集群中每个虚拟机内执行
systemctl stop firewalld 【关闭防火墙】
systemctl disable firewalld 【禁止防火墙开机启动】
二、在物理计算机添加集群的IP映射
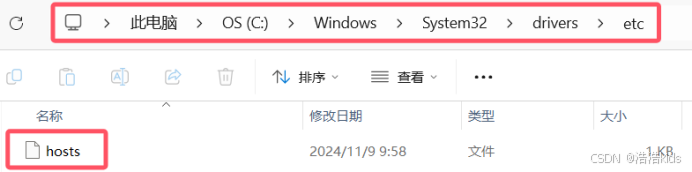
在hosts文件末尾添加【解决HDFS网页无法查看文件】
这是我的,格式就是IP 虚拟机名
刷新DNS缓存:以管理员身份运行命令提示符,在命令提示符中输入ipconfig /flushdns

三、启动集群
看Hadoop•搭建完全分布式集群目录中的启动Hadoop。
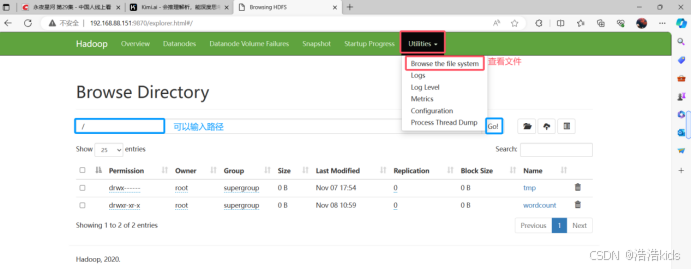
四、进入HDFS的Web UI
在浏览器输入IP:9870,如192.168.88.151:9870【192.168.88.151是我的主机IP,HDFS的Web UI端口一般都是9870】
词频统计🦩
1、准备文本数据
在哪个目录下创建,路径就在哪。切到需要的目录下哦~【记住路径!!!】
命令用touch word.txt或者vi word.txt都行(创建一个名为word的.txt文件)。
文件内要编写的内容如下图:

2、在HDFS创建目录
用命令hdfs dfs -mkdir -p /wordcount/input在HDFS创建/wordcount/input用于存放文件word.txt
3、上传文件
用命令hdfs dfs -put /export/data/word.txt /wordcount/input把位于/export/data/的word.txt上传到HDFS的/wordcount/input
4、查看文件是否上传成功
进入HDFS的Web UI输入路径/wordcount/input,如果看到该目录下有word.txt,那word.txt就上传成功了
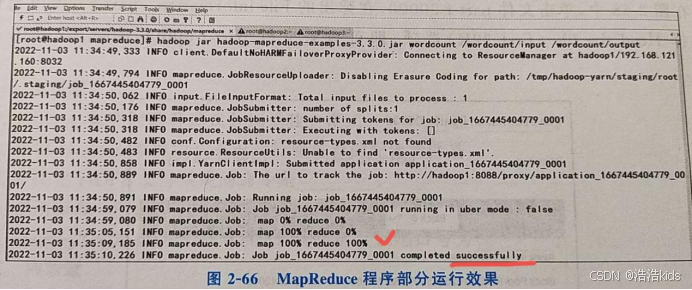
5、运行MapReduce程序
在主机node1进入/export/servers/hadoop-3.1.4/share/hadoop/mapreduce目录下执行ll命令查看Hadoop提供的MapReduce程序hadoop-mapreduce-examples-3.1.4.jar。在该程序所在目录下执行命令hadoop jar hadoop-mapreduce-examples-3.1.4.jar wordcount /wordcount/input wordcount/output运行该程序即可实现词频统计,该命令中hadoop jar指定运行的MapReduce程序,第一个wordcount是程序名称【执行操作要用的】,/wordcount/input是要计算的文件word.txt所在的目录,wordcount/output是统计结果输出的目录【该目录会自动创建,所以不能提前创建】。注意,这里使用的都是HDFS文件系统的目录。
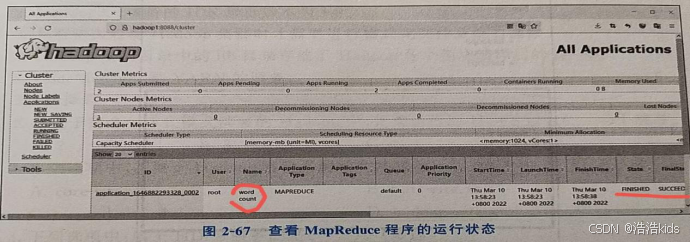
6、查看MapReduce程序运行状态
使用浏览器访问YARN在浏览器输入IP:8088,如192.168.88.151:8088【192.168.88.151是我的主机IP,YARN的Web UI端口一般都是8088】
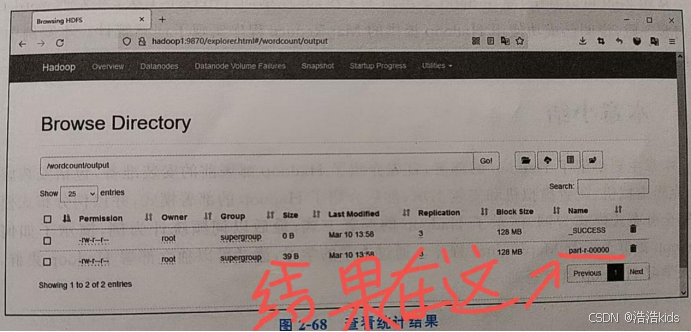
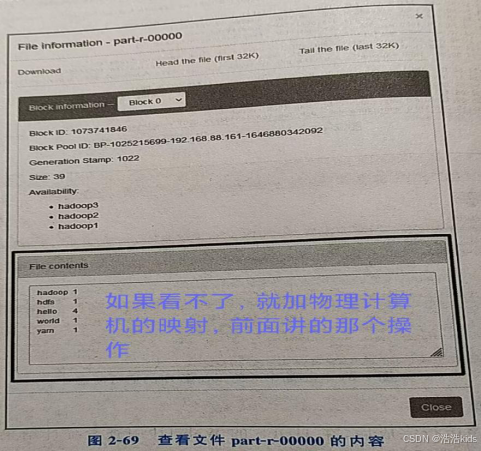
7、查看统计结果
进入HDFS的Web UI,结果存放在wordcount/output目录,输入路径,然后Go!就行了。
🐇🐇🐇我是分割线
就是在物理计算机添加集群的IP映射。
能量站😚
祝有爱者有爱,无爱者自由。

❤️谢谢你为自己努力❤️