RDD默认带有分区的,那么创建完毕rdd以后他的分区数量是多少?
从hdfs读取文件的方式是最正规的方式,我们通过计算原理可以推出blk的个数和分区数量是一致的,本地化计算。
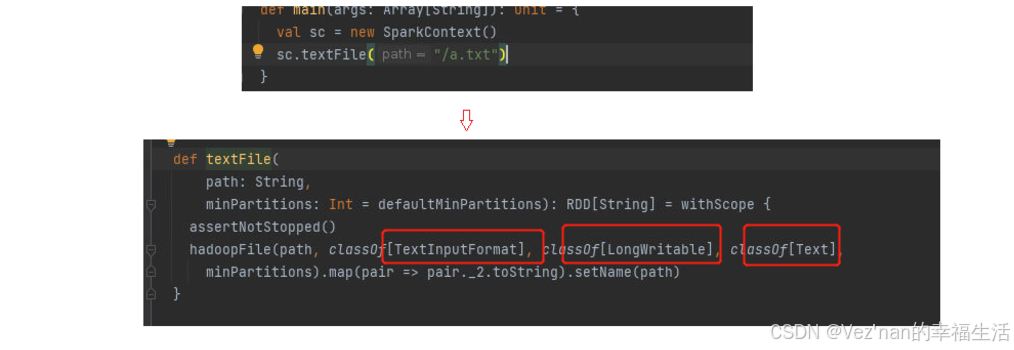
我们可以发现数据的读取使用的是textInputFormat,读取的数据内容是文本。
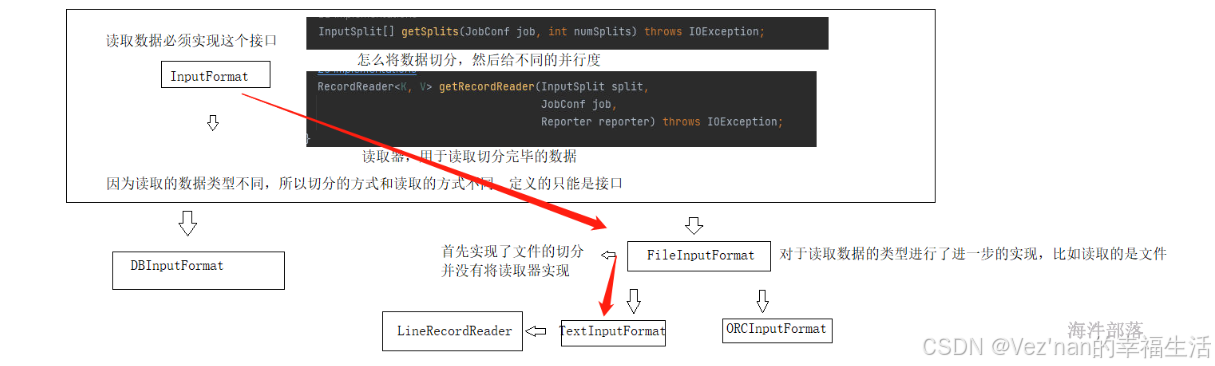
实现InputFormat接口必须实现getSplits和getRecordReader两个方法。FireInputFormat接口继承了InputFormat接口,实现了文件的切分(getSplits方法),而TextInputFormat类与ORCInputFormat继承并实现了FireInputFormat接口。TextInputFormat类实现了getRecordReader方法,即读取器为LineRecordReader,即对文本数据一行一行读取。
数据结构的实现由上图进行规划
FileInputFormat中对于文件的切分进行了分割,切分几个部分就可以实现分区的个数。
文件在hdfs存储的文件在spark中的使用是不同的。
存储的时候单位是block块 128M。
读取的时候是以spark为主,spark的读取大小叫做split切片。默认情况下,split-size = block-size。
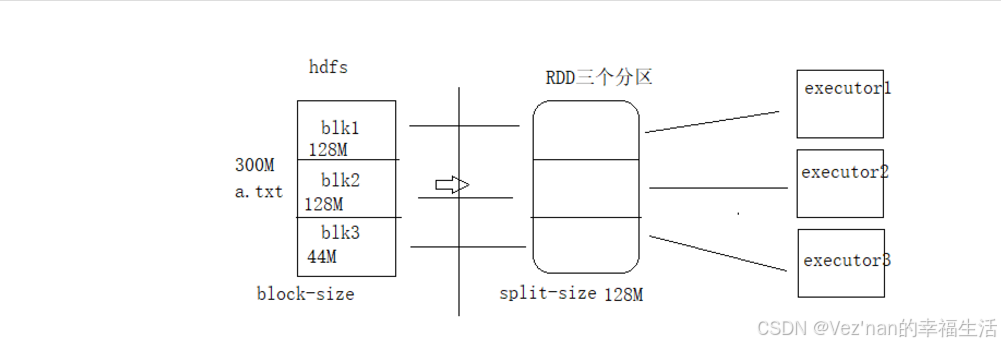
千万要将存储和计算区分开。
分区的多少完全看切片是多少,和hdfs的存储无关,但是如果切片大小和block的大小一致的话那么就可以实现本地化计算,即不需要从其他机器通过网络传输或拉取一些数据到本地的executor进行计算。
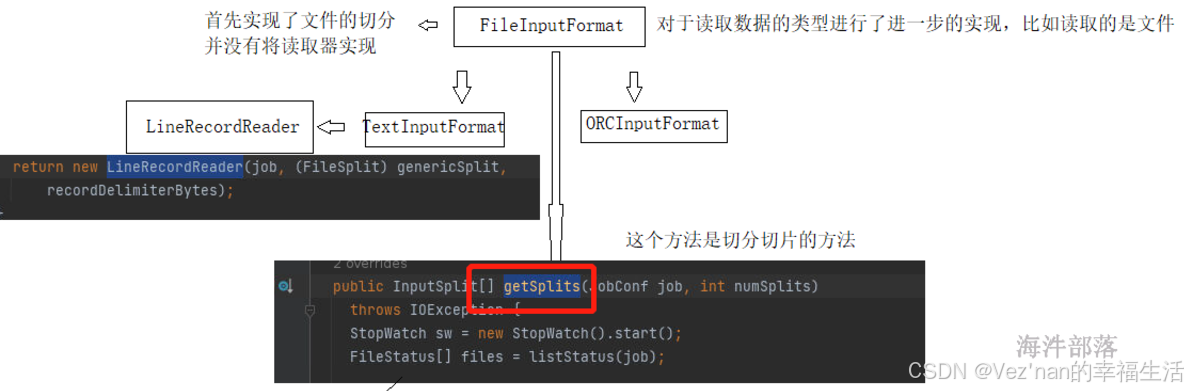
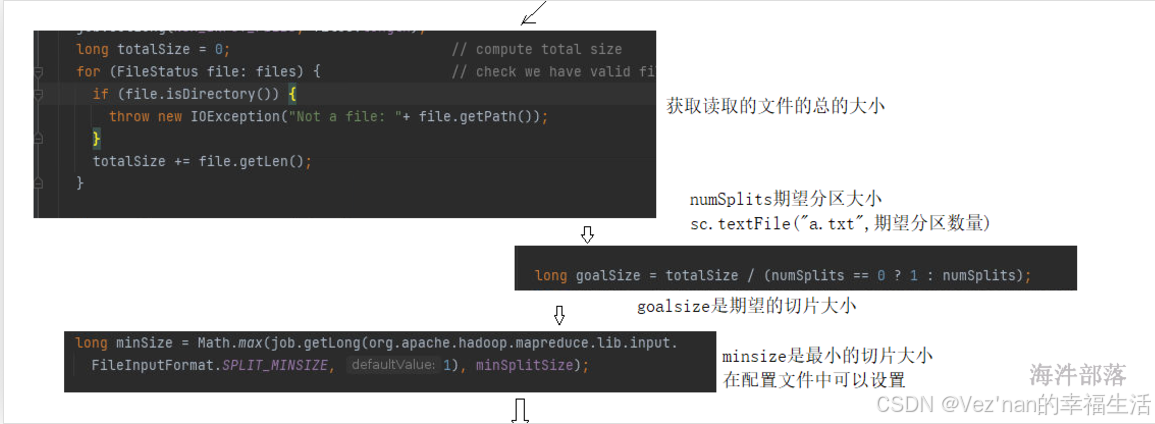
numSplits的个数可以由参数传入。

由读取的总的数据量totalSize / 期望分区的个数goalSize可以得到期望切片的大小。
计算规则:块的大小与期望切片的大小取最小值,但二者最小值不能小于配置的minSize。否则按照minSize大小进行切片划分分区。
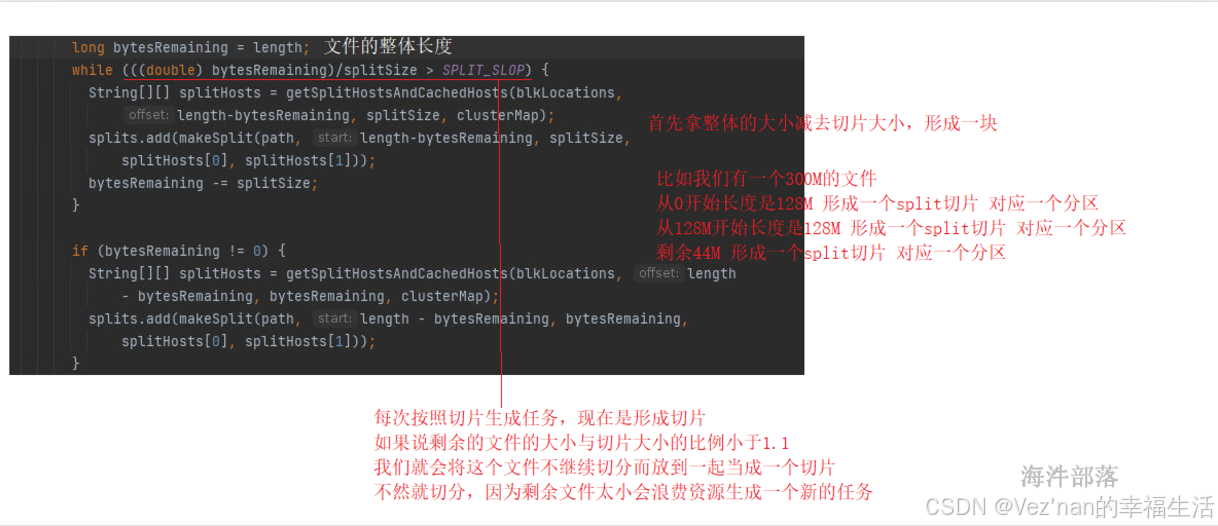
以上是源码逻辑分析
计算规则演示如下:

代码演示如下:
#追加形式增大文件的大小
cat word.txt >> word1.txt
cat word.txt >> word2.txt 
最终形成结果为上图

分区数量为4
然后继续增加文件
cat word.txt >> word3.txt 
结果如上图:

最终分区数量为5
在读取hdfs的文件的时候,一般文件都比较大,所以期望分区在不设定的时候默认值是2,切片大小肯定大于128M,那么以128M为主肯定切片和block的数量是一致的。
集合并行化。
根据集群中的核数进行适配,启动的时候有几个核,产生分区数量就是几个。
因为在计算的过程中,我们是为了做测试,为了达到最大的性能,所以分区数量会自己适配。