只有shuffle类的算子能够修改分区数量,这些算子不仅仅存在自己的功能,比如分组算子groupBy,它的功能是分组但是却可以修改分区。
而这里我们要讲的distinct算子也是一个shuffle类的算子。即可以修改分区。
scala> val arr = Array(1,1,2,2,3,3,4,4,5,5,6,6)
arr: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6)
scala> val rdd = sc.makeRDD(arr)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at makeRDD at <console>:26
scala> rdd.distinct
res29: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[22] at distinct at <console>:26
scala> res29.collect
res30: Array[Int] = Array(1, 2, 3, 4, 5, 6) 去重使用方式很简单。
但是原理却不简单。
思考一下怎么进行数据去重的?
这个同sql和mr是一样,都是分组完毕取出key的值。(即先groupBy,再map)
scala> arr
res31: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6)
scala> sc.makeRDD(arr)
res32: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at makeRDD at <console>:27
scala> res32.groupBy(t=> t)
res33: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[25] at groupBy at <console>:26
scala> res33.map(_._1).collect
res34: Array[Int] = Array(1, 2, 3, 4, 5, 6)distinct的底层实现是通过分组实现,分组存在shuffle,所以可以修改分区数量,所以切分阶段
能够修改分区数量的算子必须存在shuffle。但是如果人为不去设定分区数量,下游的分区数量和上游相同。
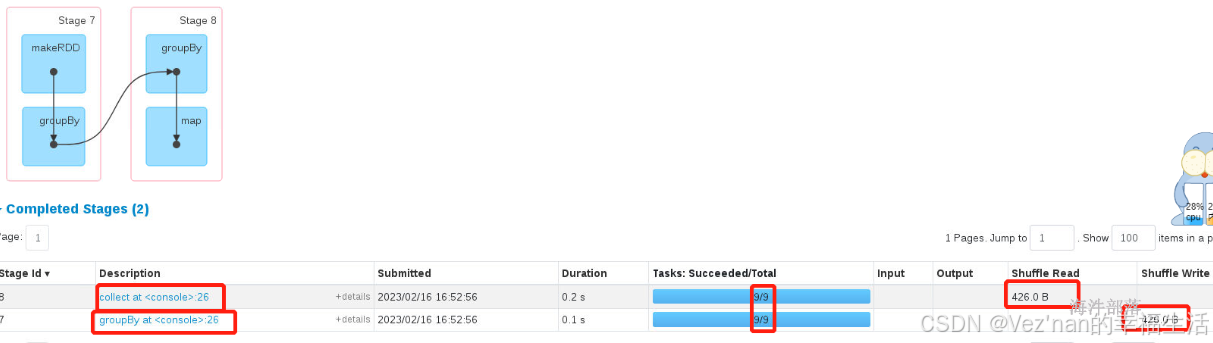
可以修改分区数量
scala> arr
res35: Array[Int] = Array(1, 1, 2, 2, 3, 3, 4, 4, 5, 5, 6, 6)
scala> sc.makeRDD(arr,3)
res36: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at makeRDD at <console>:27
scala> res36.distinct(6)
res37: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[30] at distinct at <console>:26
scala> res37.partitions.size
res38: Int = 6
scala> res36.distinct(2)
res39: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[33] at distinct at <console>:26
scala> res39.partitions.size
res40: Int = 2distinct 可以增加也可以减少分区数量