1. 共享变量
Spark两种共享变量:广播变量(broadcast variable)与累加器(accumulator)。
累加器用来对信息进行聚合,相当于mapreduce中的counter;而广播变量用来高效分发较大的对象,相当于semijoin中的DistributedCache 。
共享变量出现的原因:
我们传递给Spark的函数,如map(),或者filter()的判断条件函数,能够利用定义在函数之外的变量,但是集群中的每一个task都会得到变量的一个副本,并且task在对变量进行的更新不会被返回给driver。
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object TestAcc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test acc")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val rdd = sc.makeRDD(Array(1, 2, 3, 4, 5, 6, 7, 8, 9),3)
val count = rdd.map(t=> 1).reduce(_+_)
println(count)
// val acc = sc.longAccumulator("count")
//
// rdd.foreach(t=>{
// acc.add(1)
// })
//
// println(acc.value)
// println(rdd.count())
}
}原因总结:
对于executor端,driver端的变量是外部变量。
excutor端修改了变量count,根本不会让driver端跟着修改。如果想在driver端得到executor端修改的变量,需要用累加器实现。
当在Executor端用到了Driver变量,不使用广播变量,在每个Executor中有多少个task就有多少个Driver端变量副本。如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低,也可能会造成内存溢出。使用广播变量以后,在每个Executor中只有一个Driver端变量副本,在一个executor中的并行执行的task任务会引用该一个变量副本即可,需要广播变量提高运行效率。
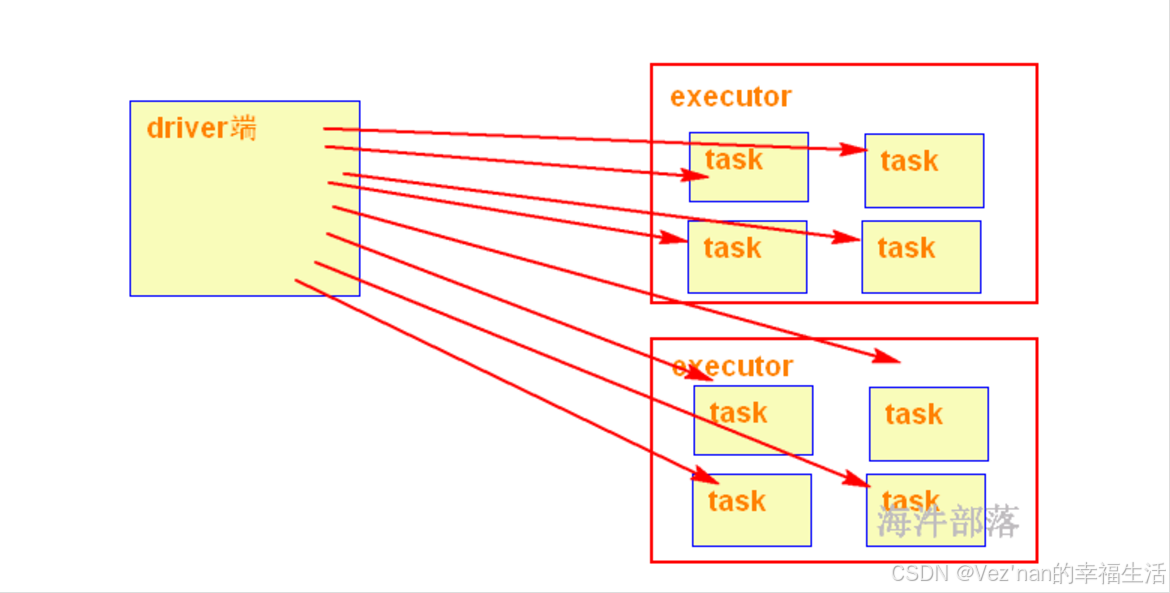
2. 累加器
累加器的执行流程:
通过SparkContext创建一个累加器并初始化。当driver端将任务分发给executor时,每个executor会接收一个任务和一个引用到该累加器的副本。每个executor上的任务可以调用累加器的add方法来增加累加器的值,这些操作是线程安全的,因为每个任务都会在自己的executor线程中执行。当每个任务完成,executor将累加器的更新值发送到driver端进行聚合过程,得到最终的聚合结果。
累加器可以很简便地对各个worker返回给driver的值进行聚合。累加器最常见的用途之一就是对一个job执行期间发生的事件进行计数。
用法:
var acc: LongAccumulator = sc.longAccumulator // 创建累加器
acc.add(1) // 累加器累加
acc.value // 获取累加器的值累加器的简单使用
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object WordCountWithAcc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("test acc")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val acc = sc.longAccumulator("bad word")
sc.textFile("data/a.txt")
.flatMap(_.split(" "))
.filter(t=>{
if(t.equals("shit")){
acc.add(1)
false
}else
true
}).map((_,1))
.reduceByKey(_+_)
.foreach(println)
println("invalid words:"+acc.value)
}
}3. 广播变量
ip转换工具
public class IpUtils {
public static Long ip2Long(String ip) {
String fragments[] = ip.split("[.]");
Long ipNum = 0L;
for(int i=0;i<fragments.length;i++) {
ipNum = Long.parseLong(fragments[i]) | ipNum << 8L;
}
return ipNum;
}
}ip案例代码
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object IpTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ip")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val accessRDD = sc.textFile("data/access.log")
.map(t=>{
val strs = t.split("\\|")
IpUtils.ip2Long(strs(1))
})
val ipArr:Array[(Long,Long,String)] = sc.textFile("data/ip.txt").map(t=>{
val strs = t.split("\\|")
(strs(2).toLong,strs(3).toLong,strs(6)+strs(7))
}).collect()
// accessRDD.map(ip=>{
// ipRDD.filter(t=>{
// ip>= t._1 && ip<= t._2
// })
// }).foreach(println)
accessRDD.map(ip=>{
ipArr.find(t=>{
t._1<= ip && t._2>=ip
}) match {
case Some(v) => (v._3,1)
case None => ("unknow",1)
}
//option
}).reduceByKey(_+_)
.foreach(println)
}
}使用广播变量可以使程序高效地将一个很大的只读数据发送到executor节点,会将广播变量放到executor的BlockManager中,而且对每个executor节点只需要传输一次,该executor节点的多个task可以共用这一个。
用法:
val broad: Broadcast[List[Int]] = sc.broadcast(list) // 把driver端的变量用广播变量包装
broad.value // 从广播变量获取包装的数据,用于计算
我们可能遇到这样的问题:如果我们需要广播的数据为100M,如果需要driver端亲自向每个executor端发送100M的数据,在工作中executor节点的个数可能是很多的,比如是200个,这意味着driver端要发送20G的数据,这对于driver端的压力太大了。所以要用到比特洪流技术。
就是说driver端不必向每个executor发送一份完整的广播变量的数据,而是将一份广播变量切分成200份,发送给两百个executor,然后200个executor间通过BlockManager中的组件transferService与其他executor通信,进行完整的数据。
这样driver端只需要发送一份广播变量的数据,压力就会小很多,而且其他executor也都拿到了这一份广播变量的数据 。
package com.hainiu.spark
import org.apache.spark.{SparkConf, SparkContext}
object IpTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ip")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val accessRDD = sc.textFile("data/access.log")
.map(t=>{
val strs = t.split("\\|")
IpUtils.ip2Long(strs(1))
})
val ipArr:Array[(Long,Long,String)] = sc.textFile("data/ip.txt").map(t=>{
val strs = t.split("\\|")
(strs(2).toLong,strs(3).toLong,strs(6)+strs(7))
}).collect()
val bs = sc.broadcast(ipArr)
// accessRDD.map(ip=>{
// ipRDD.filter(t=>{
// ip>= t._1 && ip<= t._2
// })
// }).foreach(println)
accessRDD.map(ip=>{
bs.value.find(t=>{
t._1<= ip && t._2>=ip
}) match {
case Some(v) => (v._3,1)
case None => ("unknow",1)
}
//option
}).reduceByKey(_+_)
.foreach(println)
}
}为了提高查找的效率,可以使用二分法查找代码。将时间复杂度由O(n)优化到了O(logn)。
val start = System.currentTimeMillis()
val res = (binarySearch(ip,bs.value),1)
// val res = bs.value.find(t=>{
// t._1<= ip && t._2>=ip
// }) match {
// case Some(v) => (v._3,1)
// case None => ("unknow",1)
// }
val end = System.currentTimeMillis()
acc.add(end-start)累加器实现运行时间的统计