项目简介
在上篇博客,我们完成了主引导扇区的编写,在主引导扇区我们初始化了寄存器,加载了二级引导程序到内存地址 0x8000处,并跳转至0x8000处执行,在本文我们将继续编写二级引导程序。
在二级引导程序将完成以下任务
检测内存容量
打开A20地址线
设置全局段描述符表
进入保护模式
加载并跳转至内核执行
目前项目流程如下:
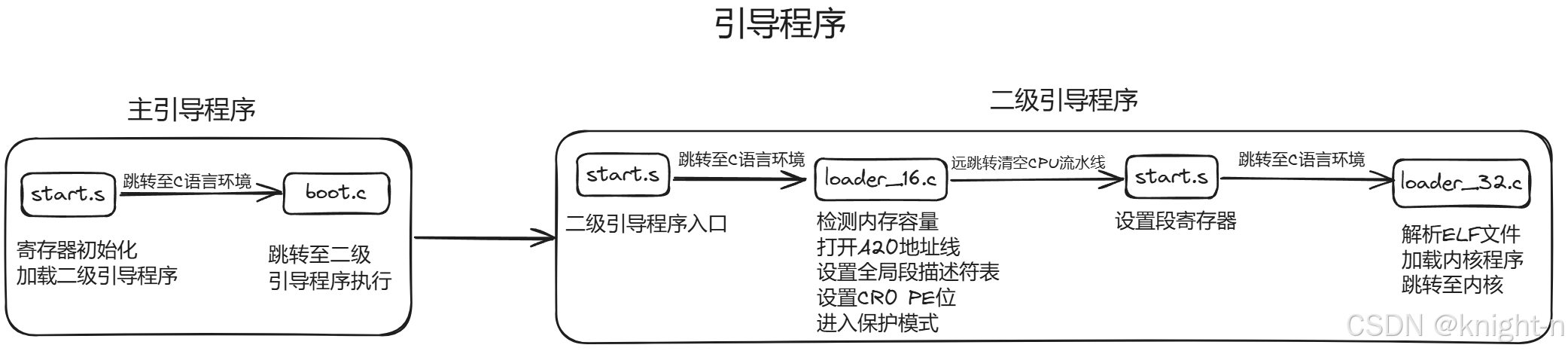
在工程下我们新建一个loader文件夹,存储二级引导程序的代码,文件夹下有五个文件,分别为start.S ,loader_16.c ,loader_32.c ,loader.h 与 CMakeLists.txt。start.S是二级引导程序的入口,loader_16.c存储16位操作尺寸即实模式下的代码,loader_32.c 存储32位操作尺寸保护模式下的代码。
这里简单介绍一下编译二进制文件,与写入虚拟硬盘。项目使用CMake构建编译生成二进制文件通过 vscode 配置文件在启动调试后,自动执行脚本将生成的二进制文件写入虚拟硬盘,同时打开 qemu 虚拟机进行调试。
显示字符
在start.S里我们跳转到C语言环境
//二级引导程序loader
//16位代码
.code16
.text
.global _start
.extern loader_entry
.extern loader_kernel
.global protect
_start:
//跳转至C语言环境
jmp loader_entry我们使用jmp指令跳转至C语言环境,loader_entry是一个C函数,链接器会将 loader_entry 替换为loader_entry函数的其实地址,执行命令后变回跳转至此处执行。这个函数我们在 loader_16.c 定义。
在loader_16.c中我们先完成一个简单的功能——在屏幕上显示字符。在计算机启动时显卡默认处于文本模式,在文本模式下,显卡将每个字符表示为一个图形符号,在屏幕上显示为一个8x8或8x16像素的块,在文本模式下显示器可以显示 80x25 个字符。在文本模式下我们可以通过访问内存中的显示缓冲区显示字符。
在标准的80x25文本模式下,B800:0000 地址开始的内存区域包含了2000个字节,正好对应于80列乘以25行的字符网格。 每个字符占用两个字节:第一个字节是字符本身的ASCII码,第二个字节是属性字节,定义了字符的颜色和亮度等。所以我们可以直接使用mov指令操作内存显示字符。
这一段代码就是一个主引导扇区程序,它会在屏幕打印 "hello word" 。
//这里使用的是x86汇编,项目中使用的汇编语法和伪指令是特定于GAS的
start:
mov ax , 0xb800
mov ds , ax ;设置数据段基址
mov byte [0x00] , 'h'
mov byte [0x01] , 0x07
mov byte [0x02] , 'e'
mov byte [0x03] , 0x07
mov byte [0x04] , 'l'
mov byte [0x05] , 0x07
mov byte [0x06] , 'l'
mov byte [0x07] , 0x07
mov byte [0x08] , 'o'
mov byte [0x09] , 0x07
mov byte [0x0C] , 'w'
mov byte [0x0D] , 0x07
mov byte [0x0E] , 'o'
mov byte [0x0F] , 0x07
mov byte [0x10] , 'r'
mov byte [0x11] , 0x07
mov byte [0x12] , 'l'
mov byte [0x13] , 0x07
mov byte [0x14] , 'd'
mov byte [0x15] , 0x07
jump:
jmp jump
cur:
times 510-(cur-start) db 0
db 0x55 , 0xAA 不难看出这种方法十分繁琐,我们可以使用一种更简单的方法使用软件中断输出字符。cpu会根据我们提供的中断号,在中断向量表中找到中断处理程序的地址跳转至该地址执行。
实模式下的中断向量表(IVT)是计算机在实模式下用于处理中断和异常的一张表。中断向量表通常位于物理内存的最开始部分,从地址0x00000开始。每个中断向量表条目占用4个字节,其中前两个字节是段地址,后两个字节是偏移地址)。中断号范围从0到255,每个中断号对应IVT中的一个条目。系统中断和异常都有固定的中断号,并且通常由BIOS或操作系统设置它们的处理程序。我们也可以设置自定义的中断处理程序,通过修改IVT中的相应条目来实现。当中断发生时,CPU会自动从IVT中找到对应的条目,并跳转到指定的段地址和偏移地址执行中断服务例程。
当系统从实模式切换到保护模式时,IVT会被中断描述符表(IDT)替代,提供更高级的中断和异常处理功能,在进入保护模式后我们需要手动设置 IDT 表。
这里我们使用 16(0x10) 号中断在屏幕光标处输出字符。通过在 AH 寄存器中设置功能号,可以指定 int 10h 要执行的具体操作。以下是一些常用的功能号:
AH = 0x00:设置光标位置。
AH = 0x01:读取当前光标位置。
AH = 0x02:在当前光标位置显示字符。
AH = 0x03:读取光标状态(包括光标位置和光标可见性)。
AH = 0x06:定义字符的属性。
AH = 0x09:写入字符串到屏幕。
当 AH 寄存器设置为 0xE 时,这个中断用于在当前光标位置显示一个字符,并更新光标位置。此时 AL 寄存器需要设置为想要显示的字符的ASCII码。
通过这个中断我们就可以实现显示字符的功能,代码如下:
//使用内联汇编显示文字
static void print_msg(const char* msg)
{
char c;
while((c=*msg++) != '\0')
{
//内联汇编
__asm__ __volatile__( //__asm__ __volatile__ 避免编译器优化
"mov $0xe, %%ah\n\t"
"mov %[ch] ,%%al\n\t"
"int $0x10" ::[ch]"r"(c) //r 表示随机寄存器
);
}
}
在代码中我们使用内联汇编显示字符,关于内联汇编,可以参考这篇博客—— 内联汇编-CSDN博客
检测可用内存
在计算机中并不是所有内存都可以被我们自由使用,系统会保留一部分内存用于特定的硬件操作和系统功能。例如,BIOS和其他固件可能会占用一部分内存,某些内存地址可能被映射到硬件设备,如图形卡、网络卡等,这些地址不可用于常规的内存访问。为了在后续中合理地分配内存给运行中的进程,我们需要检测可用的内存空间。
这一部分工作我们仍然使用中断完成,在检测前我们首先在头文件定义一个结构体,用于存储可用内存。
#pragma once
#include"types.h"
//在types.h中我们定义了uint8_t ~ uint32_t
#define RAM_REGION_MAX 10
#define SYS_KERNEL_LOAD_ADDR (1024*1024)
typedef struct ram_region_struct
{
uint32_t start; //起始地址
uint32_t size; //内存地址
}ram_region_struct;
typedef struct boot_info_t
{
ram_region_struct ram_region[RAM_REGION_MAX]; //可用内存
int ram_region_count; //可用内存数量
}boot_info_t;然后我们在函数中调用 0x15 号中断来检测内存,关于 0x15中断检测内存可以参考这篇博客——操作系统内核管理模块的实现1-检测可用内存_系统管理模块系统监测存储空间-CSDN博客
我们这里不再赘述,代码如下:
/*
内存检测信息结构
typedef struct SMAP_entry
{
uint32_t BaseL; // base address uint64_t
uint32_t BaseH;
uint32_t LengthL; // length uint64_t
uint32_t LengthH;
uint32_t Type; // entry Type
uint32_t ACPI; // extended
}__attribute__((packed)) SMAP_entry_t;
/*
//检测内存容量
static void detect_memory(void)
{
uint32_t contID = 0;
SMAP_entry_t smap_entry;
int signature, bytes;
print_msg("detect memory......\n\r");
// 初次:EDX=0x534D4150,EAX=0xE820,ECX=24,INT 0x15, EBX=0(初次)
// 后续:EAX=0xE820,ECX=24,
// 结束判断:EBX=0
boot_info.ram_region_count = 0;
for (int i = 0; i < RAM_REGION_MAX; i++)
{
SMAP_entry_t * entry = &smap_entry;
//内联汇编
__asm__ __volatile__(
"int $0x15"
: "=a"(signature), "=c"(bytes), "=b"(contID)
: "a"(0xE820), "b"(contID), "c"(24), "d"(0x534D4150), "D"(entry));
//"=a"(signature):EAX->signature。"=c"(bytes):ECX->bytes。"=b"(contID):EBX->contID。
//"a"(0xE820):0xE820->EAX。调用E820内存映射函数 "b"(contID):contID->EBX。"c"(24):24->ECX。"d"(0x534D4150):0x534D4150->EDX "D"(entry) :entry_>EDI
if (signature != 0x534D4150)
{
print_msg("failed.\r\n");
return;
}
// todo: 20字节
if (bytes > 20 && (entry->ACPI & 0x0001) == 0)
{
continue;
}
// 保存RAM信息,只取32位
if (entry->Type == 1)
{
boot_info.ram_region[boot_info.ram_region_count].start = entry->BaseL;
boot_info.ram_region[boot_info.ram_region_count].size = entry->LengthL;
boot_info.ram_region_count++;
}
if (contID == 0)
{
break;
}
}
//打印可用内存
print_msg("usable memory:\r\n");
for(int i=0;i<boot_info.ram_region_count;i++)
{
char str[8]={0};
uintToHex(boot_info.ram_region[i].start,str,8);
print_msg("start: 0x");
print_msg(str);
print_msg(" ");
uintToHex(boot_info.ram_region[i].size,str,8);
print_msg("size: 0x");
print_msg(str);
print_msg("\r\n");
}
print_msg("detection completed.\r\n");
}打开A20地址线
我们知道在早期的英特尔处理器中,CPU有20根地址线可以访问 1MB 的内存。在32位环境下CPU有32位地址线,在实模式下为了兼容早期程序,第21根地址线是默认关闭的,如果想要访问完整的4GB内存我们需要手动打开A20地址线(地址线从零开始计算,A20即第21根地址线)。
打开A20地址线有许多方法:
- 通过快速辅助寄存器: 在某些系统上,可以通过写入端口0x92来快速启用A20地址线。这种方法比较快,因为它直接操作硬件。
outb(0x92, 0x02); // outb是汇编指令,用于输出一个字节到指定的端口- 通过BIOS中断: 使用BIOS中断0x15,子功能0x84,可以请求BIOS来启用A20地址线。
mov ax, 0x2401 ; 设置AH为0x24,AL为0x01,表示启用A20地址线
int 0x15 ; 调用BIOS中断- 通过键盘控制器: 另一个启用A20地址线的常见方法是通过键盘控制器的控制寄存器。这种方法较慢,因为它需要对键盘控制器进行多次操作。
mov al, 0xAD ; 控制寄存器的命令字
out 0x64, al ; 发送命令到键盘控制器的控制寄存器
mov al, 0xD0 ; 读取状态寄存器
in 0x60, al ; 从键盘控制器的状态寄存器读取数据
or al, 0x02 ; 将A20位设置为1
out 0x60, al ; 写回状态寄存器这里我们使用了第一种方法打开地址线。为了方便我们访问端口,我们在comm文件夹定义一个头文件,cpu_instr .h在头文件中,我们会定义内联函数,在内联函数中我们又使用内联汇编,模拟汇编指令。如outb指令:
//向端口写入一个字节
static inline void outb(uint16_t port,uint8_t data)
{
//outb al, dx
__asm__ __volatile("outb %[val] ,%[p]" :: [p] "d"(port), [val]"a"(data));
}
打开A20地址线
//打开A20地址线以访问4GB内存
uint8_t port_92 = inb(0x92); //读取92号端口
outb(0x92,port_92 | 0x2); //第二位置一设置全局段描述符表
在进入保护模式之前,还有一项重要的工作——设置全局段描述符表(GDT)。
在32位系统上大多数的寄存器都从16位拓展为32位,但段寄存器仍为16位,那么16位的段寄存器如何访问32位的内存地址呢?
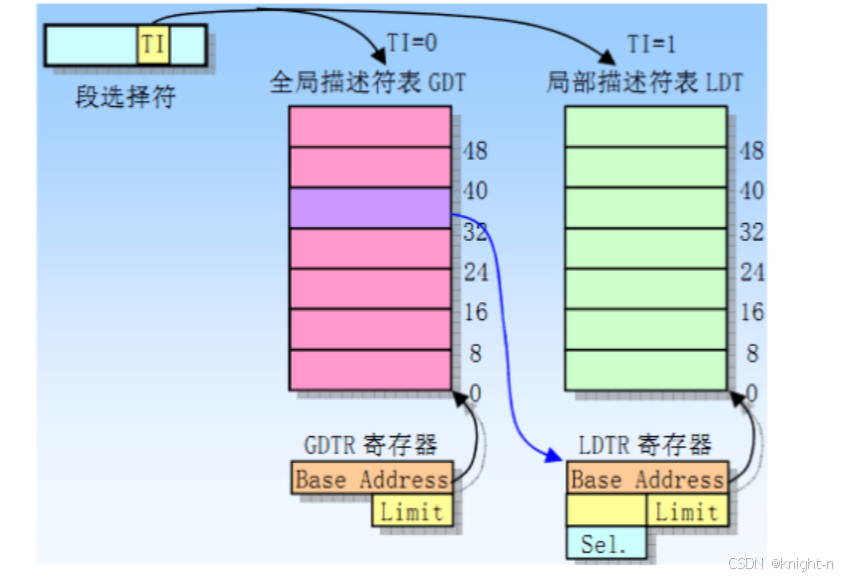
在32位的保护模式中,段寄存器用于选择段描述符,而不是直接参与地址的计算。段寄存器中存储的不再是内存地址,而是16位的段选择子,选择子用于索引GDT或LDT,以获取相应的段描述符。

Index一共13位,正好可以索引到GDT或者LDT的最大限长。由于描述符表都是8字节对齐的,所以index放在高13位,这样把低3位屏蔽后就可以得到表内偏移地址。
TI(Table Indicator)位是引用描述符表指示位,TI=0指示从全局描述符表GDT中读取描述符;TI=1指示从局部描述符表LDT中读取描述符。
选择子的最低两位是请求特权级RPL(Requested Privilege Level),用于特权检查。CS和SS寄存器中的RPL就是CPL(当前特权级)在Linux下只使用两个特权级0、3分别是内核态、用户态。
用段寄存器选择段的基本流程:
加载段寄存器:首先,需要将一个段选择器加载到段寄存器中。段选择器是一个16位的值,它包含了一个索引(用于在全局描述符表GDT或局部描述符表LDT中查找段描述符)和一个请求特权级(RPL)。
索引查找:段寄存器中的段选择器的索引部分用于在GDT或LDT中查找对应的段描述符。如果索引超出了描述符表的大小,或者描述符表中相应位置的描述符不存在,将会导致一个通用保护故障(#GP)。
检查类型和权限:一旦找到段描述符,CPU会检查描述符的类型和权限。段描述符中的类型字段定义了段的类型(如代码段、数据段等),而DPL(描述符特权级)字段定义了可以访问该段的最低特权级别。同时为了快速访问,CPU会将段的基地址,偏移量等保存在影子寄存器中。
检查RPL和CPL:段选择器中的RPL与当前进程的CPL(当前特权级)一起,确定是否可以访问该段。如果RPL大于CPL,或者段描述符中的DPL大于CPL,访问将被拒绝。
获取段基地址:如果权限检查通过,CPU将从段描述符中获取段的基地址。这个基地址与段内偏移量组合,形成完整的物理地址或线性地址。
计算物理/线性地址:在实模式下,段基地址直接与段内偏移量相加得到物理地址。在保护模式下,段基地址和偏移量组合形成线性地址,然后可能需要通过分页机制转换为物理地址。
访问内存:使用计算得到的地址,CPU可以访问内存中的段。如果访问类型(如读、写或执行)与段描述符中的类型不匹配,或者访问违反了其他权限设置,将会导致一个保护故障。
异常和中断处理:在访问内存时,如果发生任何异常或中断,CPU将保存当前的上下文,包括段寄存器的值,到一个安全的地方(如堆栈或任务状态段TSS),以便之后可以恢复执行。
任务切换:在任务切换时,操作系统会更新所有相关的段寄存器,以确保新任务使用正确的段描述符和内存段。
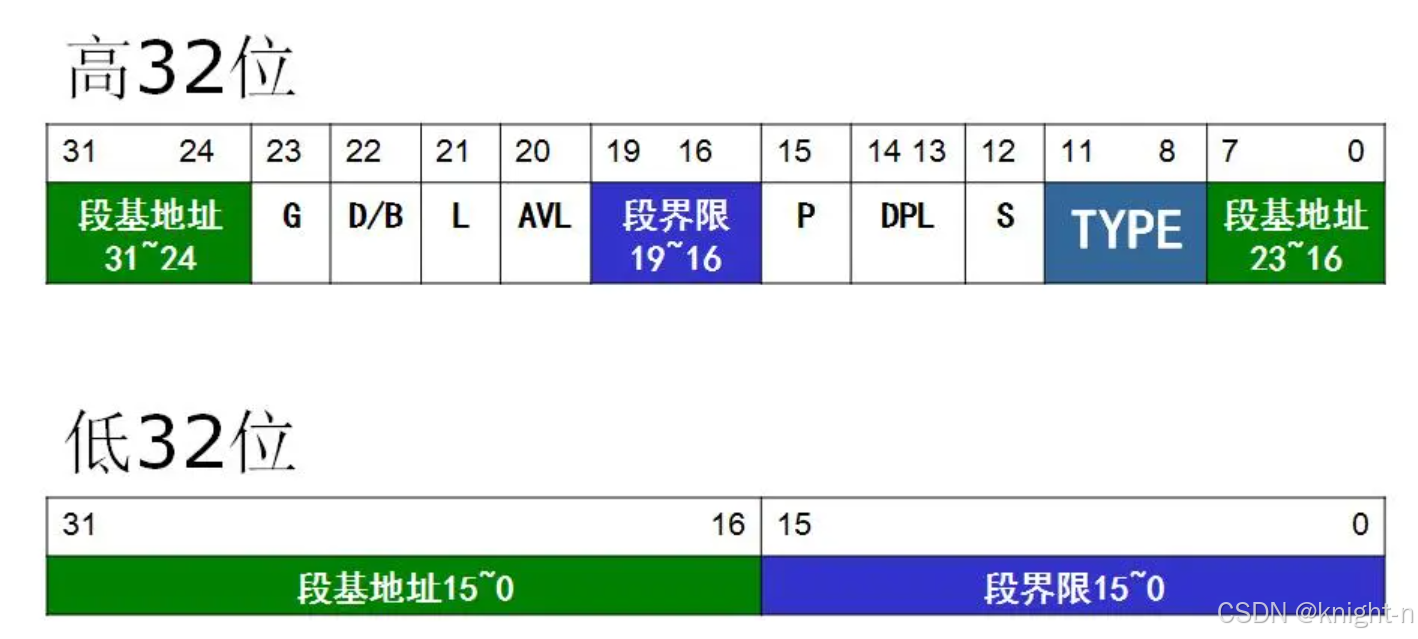
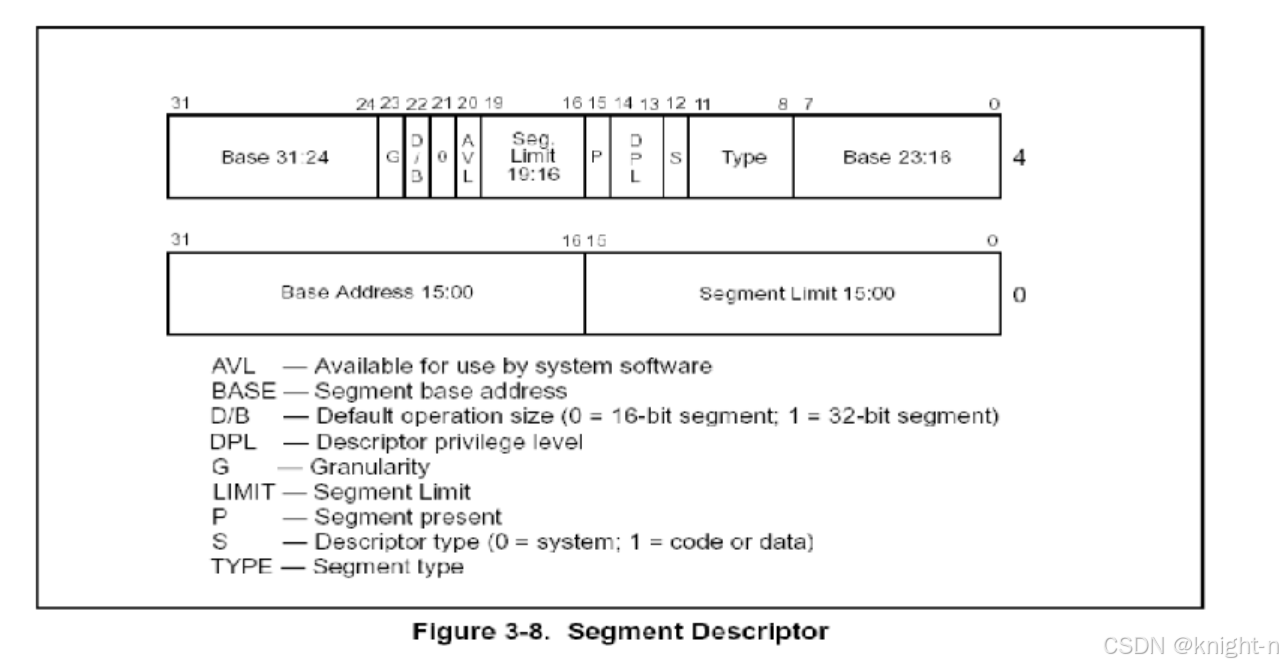
段描述符存储在GDT或者LDT,段描述符(Segment Descriptor)是全局描述符表(GDT)或局部描述符表( LDT)中的一个数据结构,用于定义段的属性和行为。GDT 和LDT 段描述符表实际上是段描述符的一个长度不定的数据阵列。描述符表在长度上是可变的,最多容纳213 个描述符,最少包含一个描述符。每个项有8 个字节长,称为一个段描述符。段描述符设定了使用该段时的内存访问权限、段的界限和基地址。 段描述符为8个字节64位结构如下:
我们通过设置GDTR寄存器指向GDT表,GDT、LDT、GDTR、LDTR与段寄存器关系如下:
在项目中我们采用的是平坦模式访问内存,所以我们这里将数据段与代码段基地址都设为0x00000000,段界限设为4GB。
//设置全局段描述符表
uint16_t gdt_table[][4] = {
{0, 0, 0, 0}, //空描述符
{0xFFFF, 0x0000, 0x9A00, 0x00CF},
{0xFFFF, 0x0000, 0x9200, 0x00CF},
};
x86架构中,全局描述符表的第一个段描述符需要被设置为全零。第二个描述符表是代码段,特权级为0,可读写,在从内存中存在,基地址为0x00000000,段界限为4GB。第三个描述符表是数据段,特权级为0,可读写,在从内存中存在,基地址为0x00000000,段界限为4GB。
这只是一个简单的实现,在进入内核后,我们会重新设置GDT。定义了GDT表后,我们需要设定gdtr寄存器。我们可以使用lgdt指令设置GDTR寄存器。我们仍然使用内联函数完成lgdt功能。
//设置全局段描述符表
lgdt((uint32_t)gdt_table,sizeof(gdt_table));
//设置GDTR
static inline void lgdt(uint32_t start,uint16_t size)
{
struct
{
uint16_t limit; //描述符表大小-1
uint16_t startl; //低16位
uint16_t starth; //高16位
}gdt;
gdt.limit=size-1;
gdt.starth= start >> 16;
gdt.startl= start & 0xFFFF;
__asm__ __volatile("lgdt %[g]" ::[g]"m"(gdt));
}
进入保护模式
进入保护模式的基本流程:
初始化全局描述符表(GDT):
创建一个GDT结构,其中包含必要的段描述符,例如代码段、数据段等。
设置GDT的界限和基地址:
计算GDT的大小,并创建一个GDTR(全局描述符表寄存器)结构,包含GDT的界限和基地址。
加载GDTR:
使用
lgdt指令将GDTR结构加载到CPU的GDTR寄存器中。设置段寄存器:
将CS(代码段寄存器)、DS(数据段寄存器)、ES、FS、GS和SS(堆栈段寄存器)等设置为合适的值,通常指向GDT中的有效段描述符。
开启A20地址线:
如果系统需要访问超过1MB的内存,需要确保A20地址线被启用,允许访问高端内存。
修改CR0寄存器:
将CR0寄存器的PE位(保护使能位)设置为1,启用保护模式。
远跳转至新的代码段:
执行一个远跳转指令,跳转到一个新的代码段,这个跳转操作会刷新内部的段寄存器,并开始在保护模式下执行代码。
我们已经完成大部分工作,现在只要将CR
初始化全局描述符表(GDT):
创建一个GDT结构,其中包含必要的段描述符,例如代码段、数据段等。
设置GDT的界限和基地址:
计算GDT的大小,并创建一个GDTR(全局描述符表寄存器)结构,包含GDT的界限和基地址。
加载GDTR:
使用
lgdt指令将GDTR结构加载到CPU的GDTR寄存器中。设置段寄存器:
将CS(代码段寄存器)、DS(数据段寄存器)、ES、FS、GS和SS(堆栈段寄存器)等设置为合适的值,通常指向GDT中的有效段描述符。
开启A20地址线:
如果系统需要访问超过1MB的内存,需要确保A20地址线被启用,允许访问高端内存。
修改CR0寄存器:
将CR0寄存器的PE位(保护使能位)设置为1,启用保护模式。
远跳转至新的代码段:
执行一个远跳转指令,跳转到一个新的代码段,这个跳转操作会刷新内部的段寄存器,并开始在保护模式下执行代码。
我们已经完成了大部分工作,现在只需设置CR0寄存器即可进入保护模式,我们使用内联汇编完成这个功能:
//设置CR0,PE位
static inline void CR0_PE()
{
uint32_t cr0;
//读取CR0
__asm__("mov %%cr0, %0" :"=r"(cr0));
//修改CR0
cr0 |= 1;
//写回
__asm__("mov %0, %%cr0" :: "r"(cr0));
}完成这部分工作我们就进入了保护模式,也从16位环境跳转至32位环境了,接下来我们需要远跳转清空CPU流水线更新CS段寄存器(CS段寄存器无法手动更改),我们跳转到start.s中执行:
//远跳转
static inline void far_jump(uint32_t selector , uint32_t offset)
{
uint32_t addr[]={offset,selector}; //offset->偏移量,selector->段选择子
__asm__("ljmpl *(%[a])"::[a]"r"(addr));
}
//进入保护模式
static void protect_entry()
{
cli(); //关闭中断
//打开A20地址线以访问4GB内存
uint8_t port_92 = inb(0x92); //读取92号端口
outb(0x92,port_92 | 0x2); //第二位置一
//设置全局段描述符表
lgdt((uint32_t)gdt_table,sizeof(gdt_table));
print_msg("GDT settings\n\r");
//设置CR0 PE位
print_msg("protect mode enter\n\r");
CR0_PE();
//清空cpu流水线
far_jump(8,(uint32_t)protect);
}在start.s中我们更新其他段寄存器执行数据段然后跳转到C语言环境中
//二级引导程序loader
//16位代码
.code16
.text
.global _start
.extern loader_entry
.extern loader_kernel
.global protect
_start:
//跳转至C语言环境
jmp loader_entry
//32位代码
.code32
.text
protect:
//将段寄存器设置为32位
mov $16, %ax //16为段选择子
mov %ax, %ds
mov %ax, %ss
mov %ax, %es
mov %ax, %fs
mov %ax, %gs
jmp $8 , $loader_kernelloader_kernel在loader_32.c中定义,在这里我们会加载操作系统内核到内存然后跳转至内核执行。
加载内核
在进入保护模式后,我们未设置中断描述符表不能使用软件中断,所以我们通过读写端口使用LBA模式读写磁盘,我们将内核加载至内存地址0x10000处。
//使用LBA48位模式读取磁盘
static void read_disk(int sector, int sector_count, uint8_t * buf)
{
outb(0x1F6, (uint8_t) (0xE0));
outb(0x1F2, (uint8_t) (sector_count >> 8));
outb(0x1F3, (uint8_t) (sector >> 24)); // LBA参数的24~31位
outb(0x1F4, (uint8_t) (0)); // LBA参数的32~39位
outb(0x1F5, (uint8_t) (0)); // LBA参数的40~47位
outb(0x1F2, (uint8_t) (sector_count));
outb(0x1F3, (uint8_t) (sector)); // LBA参数的0~7位
outb(0x1F4, (uint8_t) (sector >> 8)); // LBA参数的8~15位
outb(0x1F5, (uint8_t) (sector >> 16)); // LBA参数的16~23位
outb(0x1F7, (uint8_t) 0x24);
// 读取数据
uint16_t *data_buf = (uint16_t*) buf;
while (sector_count-- > 0)
{
// 每次扇区读之前都要检查,等待数据就绪
while ((inb(0x1F7) & 0x88) != 0x8)
{}
// 读取并将数据写入到缓存中
for (int i = 0; i < SECTOR_SIZE / 2; i++)
{
*data_buf++ = inw(0x1F0);
}
}
}
outb(0x1F6, (uint8_t) (0xE0)); - 向硬盘的备用寄存器(Alternate Status Register)端口0x1F6写入0xE0,这是LBA模式的特定命令。
outb(0x1F2, (uint8_t) (sector_count >> 8)); - 发送要读取的扇区数量的高8位到端口0x1F2。
outb(0x1F3, (uint8_t) (sector >> 24)); - 发送LBA地址的高8位到端口0x1F3。 接下来的几条outb指令发送剩余的LBA地址和扇区数量到相应的端口。
outb(0x1F7, (uint8_t) 0x24); - 向命令寄存器(Command Register)端口0x1F7写入0x24,这是读取扇区的命令。
然后,代码进入一个循环,读取每个扇区的数据。 在读取每个扇区之前,代码使用一个循环来检查硬盘状态,等待数据就绪。
inb(0x1F7) - 读取硬盘的状态寄存器,检查数据是否就绪。
一旦数据就绪,代码使用inw(0x1F0)指令从数据端口0x1F0读取数据。这里假设每次读取是16位宽,因此使用uint16_t *data_buf作为缓冲区的指针。 SECTOR_SIZE是定义好的一个宏,表示每个扇区的大小,为512字节。循环读取每个扇区的数据到提供的缓冲区buf。
在读取完内核文件后我们需要跳转至内核执行,在以前我们会直接跳转,但在内核编译时,我们编译生成的是elf文件,而不是之前的bin文件,我们需要解析elf文件,得到程序入口地址,然后跳转至入口执行。
ELF 头部位于文件的开始位置,提供了整个文件的总体信息。它包括程序入口点地址、程序头表和节区头表的位置等信息,我们需要读取ELF 头部中的elf_entry 成员,它存储了程序的入口点地址。这是程序加载到内存后,CPU 开始执行的起始点。
// ELF Header
#define EI_NIDENT 16
#define ELF_MAGIC 0x7F
typedef struct {
char e_ident[EI_NIDENT];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
}Elf32_Ehdr;
#define PT_LOAD 1
typedef struct {
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
Elf32_Word p_filesz;
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
} Elf32_Phdr;
//解析ELF文件格式
static uint32_t load_elf(uint8_t* file)
{
Elf32_Ehdr* elf_hdr= (Elf32_Ehdr*)file;
if ((elf_hdr->e_ident[0] != ELF_MAGIC) || (elf_hdr->e_ident[1] != 'E')
|| (elf_hdr->e_ident[2] != 'L') || (elf_hdr->e_ident[3] != 'F'))
{
return 0;
}
for(int i=0;i<elf_hdr->e_phnum;i++)
{
Elf32_Phdr* phdr=(Elf32_Phdr*)(file+ elf_hdr->e_phoff) + i; //e_phoff为偏移量
//检查是否可加载
if(phdr->p_type != PT_LOAD)
{
continue;
}
//使用物理地址,此时分页机制还未打开
uint8_t * src = file + phdr->p_offset; //源文件地址
uint8_t * dest = (uint8_t *)phdr->p_paddr; //目的地址
for (int j = 0; j < phdr->p_filesz; j++)
{
*dest++ = *src++; //按地址复制
}
//bss区域全0
//memsz和filesz不同时,后续要填0
dest= (uint8_t *)phdr->p_paddr + phdr->p_filesz;
for (int j = 0; j < phdr->p_memsz - phdr->p_filesz; j++)
{
*dest++ = 0;
}
}
return elf_hdr->e_entry; //返回程序入口地址
}
获得入口地址后我们强转为函数指针后调用即可,代码如下:
void loader_kernel()
{
//加载内核程序
read_disk(100,500,(uint8_t *)SYS_KERNEL_LOAD_ADDR);
//跳转至内核程序
uint32_t kernel_entry = load_elf((uint8_t *)SYS_KERNEL_LOAD_ADDR);
if(kernel_entry==0)
{
die(1);
}
((void (*)(boot_info_t*))kernel_entry)(&boot_info);
}到此二级引导程序就完成了,在下一节我们会开始编写内核程序。因为篇幅问题,很多代码,细节 ,目录结构等没有解释,有兴趣的读者可以在gitee上查看完整代码。