今日诗词:
折花逢驿使,寄与陇头人。
江南无所有,聊赠一枝春。
——《赠范晔诗》【南北朝】陆凯
引言:
上一期我们说到了ASCII码表,这是一种现如今不是那么通用的机制,随着计算机的普及,越来越多的人开始学习计算机,深入研究它,所以我们需要一种可以映射所有语言的码表,这就是Unicode编码。
正文:
小知识:
在开始今天的Unicode编码前,我先来说一个知识点,有助于后面地理解,看懂机制中代表的意思。
字节序:
一个字(32位机器采用32bits字长4bytes)在内存中存放的字节序是怎样的呢?
两个方法:
大端法:(big endition):大多数IBM机器,Internet传输
| 0x100 | 0x101 | 0x102 | 0x103 | ||||
| 01 | 23 | 45 | 67 |
小端法:(little endition):Intel兼容机
| 0x100 | 0x101 | 0x102 | 0x103 | ||||
| 67 | 45 | 23 | 01 |
这就是字节序的表示方法:大端法,小端法。
Unicode编码
Unicode编码,也被称为统一码、万国码或单一码,是一种在计算机上广泛使用的字符编码方案。它旨在解决传统字符编码方案的局限,为每种语言中的每个字符设定了统一且唯一的二进制编码,以满足跨语言、跨平台进行文本转换和处理的需求。
一、起源与发展
Unicode编码的历史可以追溯到20世纪60年代,当时计算机科学家们意识到不同计算机系统使用不同的字符编码方式,导致文本和数据在不同系统间传输时出现混乱和错误。为解决这一问题,国际组织开始致力于制定统一的字符编码标准。1987年,Unicode联盟成立,开始制定Unicode编码标准。该标准于1990年开始研发,1994年正式公布,并随着计算机和互联网的发展逐渐成为全球通用的字符编码标准。
二、特点与优势
1.统一性:Unicode为世界上几乎所有的字符集和符号提供了唯一的数字标识符,确保了字符在不同计算机系统和编程环境中的一致性和互操作性。
2.扩展性:Unicode编码体系庞大,能够容纳超过110万个码位,涵盖了全球范围内的绝大多数语言字符,为未来的字符扩展提供了充足的空间。
3.兼容性:Unicode与多种传统字符编码方案(如ISO 8859、GB2312等)保持兼容,使得旧有编码方式可以平滑过渡到Unicode编码。
三、实现方式
虽然Unicode为每个字符分配了唯一的码位,但其具体实现方式(如UTF-8、UTF-16、UTF-32等)在编码长度上有所不同:
1.UTF-8:一种可变长度的编码方式,能够根据字符的不同使用不同数量的字节进行编码。它对于ASCII字符非常高效且兼容,是互联网上最流行的字符编码方式之一。特点是存储效率高(不方便内部随机访问);无字节序问题(可作为外部编码);与ASCII码表完全互通。一个byte表示一个字符。
2.UTF-16:固定长度的编码方式,使用16位(即2个字节)来表示一个字符。在处理基本平面的字符时非常高效,但对于扩展平面的字符需要使用代理对(surrogate pair)来表示。特点是定长(方便内部随机访问);有字节序问题(不可作为外部编码)。两个byte表示一个字符。
3.UTF-32:也是固定长度的编码方式,使用32位(即4个字节)来表示一个字符。它简化了字符的编码和解码过程,但可能会占用更多的存储空间。特点是定长(方便内部随机访问);有字节序问题(不可作为外部编码)。两个byte表示一个字符。
四、应用领域
Unicode编码在多个领域发挥着重要作用,包括:
- 跨语言文本处理:使得不同语言的文本可以在同一平台上进行处理和交换。
- 国际化软件开发:确保软件支持多种语言,满足全球化市场的需求。
- 网络通信:确保各种语言的字符能够正确传输和显示,提高通信的效率和准确性。
- 数据库存储:为数据分析和挖掘提供更广泛的数据来源。
- 文本编辑器:在文档或文本文件中插入Unicode字符时,可以直接使用文本编辑器进行输入或粘贴。
- HTML和网页:在HTML中,可以使用实体编码或直接插入Unicode字符来表示特殊字符。
综上所述,Unicode编码作为一种重要的字符编码标准,为全球范围内的信息交流和处理提供了统一的基础。随着技术的不断发展和全球化的推进,Unicode编码将在更多领域发挥重要作用。
实例演示:
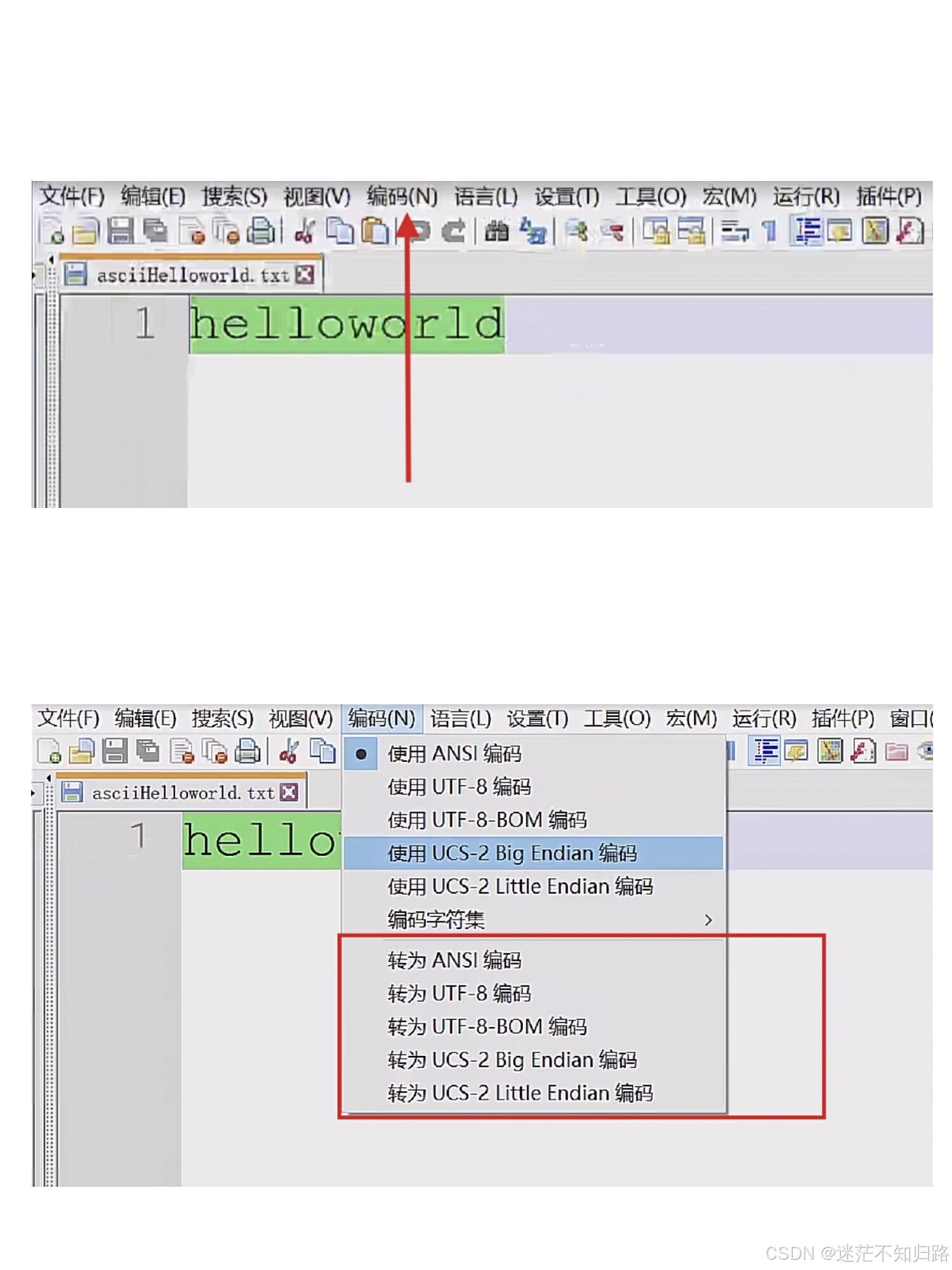
首先我们在Notepad++中写一段字符串常量(helloworld),然后在编码中转换成不同的编码(这里有五种编码:ASCII码表,UTF-8编码,UTF-8-BOM编码,UTF-16 Big Endition编码,UTF-16 Little Endition编码),转化后的文件(五个)保存在一起方便使用。
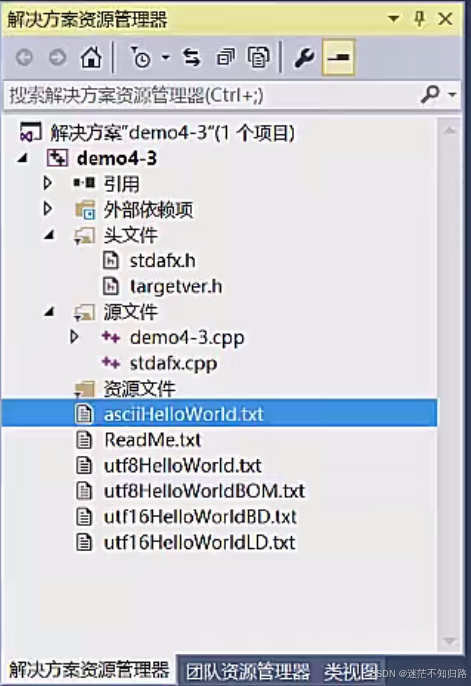
然后在资源管理器中打开这五个文件。然后选中其中一个文件点击右键就会出现打开方式的方框,找到二进制编辑器然后单击,就会出现着五种形式各自的二进制表示。
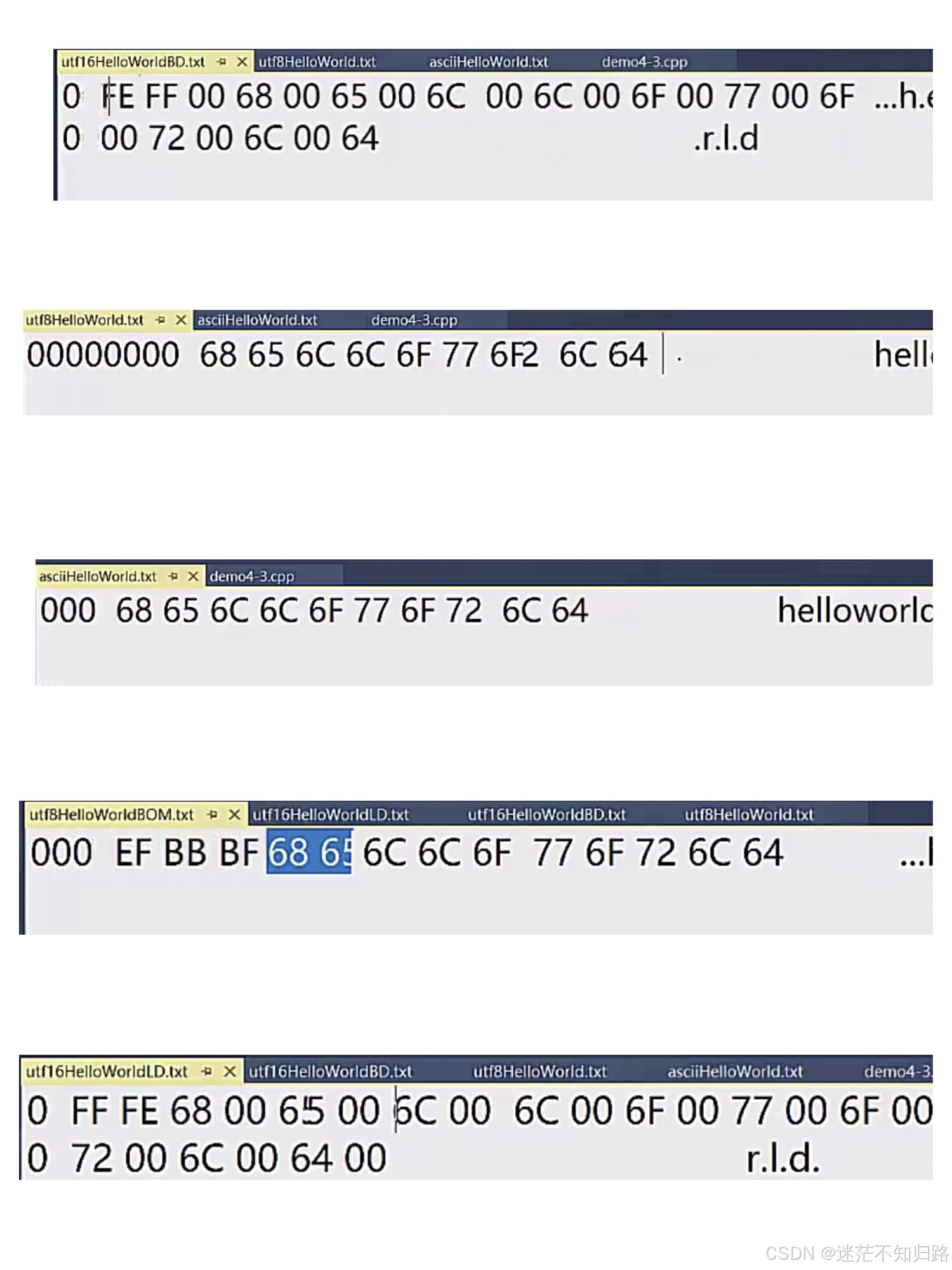
我们看上图,其中3和4就是ASCII码表和UTF-8编码,这两个的二进制表示一摸一样,因为二者都是以8位来定义的,所以是通用的。然后是1和5,分别是UTF-16 Big Endition编码和UTF-16 Little Endition编码,它们之间的不同之处就是字节序的不同,其他都是相同的;相比于UTF-8编码,这两个在每一个数字都加了00。最后是UTF-8-BOM编码,这个可以忽略,因为八位的没有字节序,而BOM又是定义字节序的符号,所以在这就是多此一举。
最后说一句:编码错误的根本原因在于编码方式和解码方式的不统一(就是解铃还须系铃人)。所以当文件出现乱码情况,80%都是这个原因。这一章我讲解的比较简单,不够严谨规范,感兴趣的同学可以深入研究一下
🆗到这里,这篇关于:C++码表之Unicode就说完了,求一个免费的赞,感谢阅读。