" 喜欢了你十年,却用整个四月,编织了一个不爱你的谎言。 "

目录
Hello,大家好,前面我们已经学习了红黑树的底层结构,并且也已经知道了map和set的底层结构其实就是封装了一棵红黑树,但是如果大家了解过map和set的实参个数的话,会发现map需要我们传递2个参数,而set只需要我们传递1个参数,说到这里就有同学好奇了,set的实际传递参数的个数和红黑树所需要的参数个数明显不一致,这个要怎么封装呢?接下来,我就来为大家展示一下map和set如何封装红黑树。
1 源码及其框架分析
我们前面的一篇博客(下面有相应的链接1)讲解了关于红黑树的一些基本功能的实现及其具体得到一个内部结构,并且我们通过前面所学的知识可以得知,在前面还有一篇博客中所讲解的map和set这两个容器的底层(下面有相应的链接2)它其实就是封装了一棵红黑树,说到这里,就会有同学结合红黑树的内部结构以及map和set的内部结构,就会认为map和set的底层分别各自封装了一棵红黑树,在set中的节点存放的是key,而在map中的节点存放的是pair类类型的变量,但事实上并不是这样的,它们的底层共用的是同一颗红黑树,但是,是如何做到的呢?在这里,那接下来,我们就来结合截取出来的map和set的部分核心代码来看一下到底是如何做到的呢?
链接1:数据结构——红黑树的实现:
 https://blog.csdn.net/2301_81390458/article/details/145192209?spm=1001.2014.3001.5502
https://blog.csdn.net/2301_81390458/article/details/145192209?spm=1001.2014.3001.5502链接2:map和set的使用,相信我,超简单的!:
在真正开始展示源代码之前,我们先来说一下我们前一篇博客中实现的那个红黑树的节点结构,我们所实现的节点中的元素是一个pair类类型的变量,这只是我们自主实现的,实际上红黑树的节点中存放的有可能不是pair类类型的变量,我们这里通过下列代码来分析:

为了方便大家使用代码观看,我将代码放在了下面:
template<class key, class Compare=Less<key>, class Alloc=alloc>//Compare为仿函数,后面会讲到它的作用;Alloc暂时先不讲,后面会讲到。
class set//set是key搜索场景,因此只需传1个模板参数。
{
public:
typedef key key_type;
typedef key value_type;//set是key场景,因此关键字就是要存储的数据,key_type和value_type表示的都是同一个类型。
private:
typedef rb_tree<key_type, value_type, identity<value_type>, key_compare, Alloc> rep_type;key_type是关键字类型,
//value_type是存储数据类型,它们是一样的,identity<value_type>、 key_compare、Alloc这几个类型具体是什么,我们先不管,对我们这里不会造成影响。
rep_type t;//定义一棵红黑树。
};
template<class key, class T,class Compare=Less<key>, class Alloc=alloc>//解释和set中的解释相同。
class map
{
public:
typedef key key_type;
typedef T mapped_type;//map是key_value搜索场景,关键字是用来构建红黑树的,且用于查找和删除的,T是此节点中真正存放的东西。
typedef pair<const key, T> value_type;//map中的各个节点中存放的是一个pair类类型的变量,而这个变量中有关键字和存储内容。
private:
typedef rb_tree<key_type, value_type, select1st<value_type>, key_campare, Alloc> rep_type;//和set中的解释相同。
rep_type t;//定义一棵红黑树。
};
template<class key,class value,class keyofvalue,class Compare=Less<key>, class Alloc=alloc>//这些具体是什么类型暂时先不做任何解释。
class re_tree
{
protected:
typedef _rb_tree_node<value> re_tree_node;
//...还有一些成员,由于我们这里所讲解的知识点没有多大的关系,因此就不用写了。
};
template<class value>
struct _rb_tree_node:public _rb_tree_node_base//_rb_tree_node_base这个类中包含了一些基本变量,比如说左指针,右指针等等。
{
typedef _rb_tree_node<value>* link_type;//为了方便表示指针。
value value_field;
};上述的代码只是源码的一部分,其实并不全(完整),我们在set中传给红黑树的第二个模板参数是key类型的,通过我们上述代码中_rb_tree_node这个类模板可知,源码中是将红黑树的节点构成了一个模板,是根据传过来的类型来确定这个节点中应该存放哪种类型的元素变量,set中传给红黑树的第二个参数是key类型的,那么实例化出来的红黑树的节点中存放的就是key类型的元素,因而可以实现出key的搜索场景;在map中传给红黑树的第二个参数是pair类类型的变量,那么实例化出来的红黑树的节点中所存放的就是pair类类型的变量,因而可以实现出key/value的搜索场景。
说到了这里,那么我们就已经讲明白了map和set中是如何对同一棵红黑树进行封装的,map和set的内部它们封装的其实都是同一棵红黑树,但是节点中所存放的数据类型是不同的,这样的话就又会产生一个问题,就是我们在插入节点时,要依靠关键字去找最适合的插入位置,如果是set,就直接使用节点中存储的数据去找,反之,我们还得到pair类类型的对象中去找first,也就是一个需要进行解引用操作才可以找到的关键字,一个不需要就可以直接找到,两种方式不能直接融合在一起,为此,这里就需要我们去通过仿函数去单独实现map和set各自的实现方式。(其实pair也支持比较,只不过它的比较使用first和second一起参与比较的,我们这里则是只想让first进行比较,second是不能参与比较的,因此不能用pair中自己实现的)
//找关键字(与上述代码相呼应)
//set
struct SetKeyOfT
{
const key& operator()(const key& k)
{
return k;
}
};
//map
struct MapKeyOfT
{
const key& operator()(conct pair<key, T>& kv)
{
return kv.first;
}
};1>.通过上图对框架的分析可知,我们可以看到源码中rb_tree用了一个巧妙的泛型思想去实现,re_tree是实现key的搜索场景,还是key/value的搜索场景并不是直接写死的,而是由第二个模板参数value去决定_rb_tree_node中存储的数据类型的。
2>.要注意一下,源码里面的模板参数是用T代表的value,而内部写的value_type并不是我们日常的key/value场景中所说的value,源码中的value_type反而是红黑树节点中存储的真实的数据的类型。
3>.re_tree第二个模板参数value就已经控制了红黑树的节点中存储的数据类型,那么为什么还要传第一个模板参数key呢?尤其是set,两个参数都是一模一样的,这是很多同学的一个疑问。要注意的是对于map和set而言,find/erase时的函数参数都是key,所以第一个模板参数其实是传给find/erase等函数做形参的参数类型的。对于set而言两个参数都是一样的,但是对于map而言就完全不一样了,map中insert的对象是pair类类型的对象,但是find和erase的参数是key对象。
2 模拟实现map和set
2.1 实现出复用红黑树的框架
template<class K, class V>
class map
{
struct MapKeyOfT
{
const K& operator()(conct pair<const K, V>& kv)
{
return kv.first;
}
};
public:
//实现map的各个操作及其功能。
private:
RBTree<K, pair<K, V>, MapKeyOfT> _t;//K前面加了一个const修饰,是因为K是关键字类型,而关键字是不允许随便更改的,因此,加上const修饰,防止有人恶意更改。
};
template<class K>
class set
{
struct SetKeyOfT
{
const key& operator()(const key& k)
{
return k;
}
};
public:
//实现set的各个操作及其功能。
private:
RBTree<K, K, SetKeyOfT> _t;
};
enum colour
{
RED,
BLACK
};
template<class T>
struct RBTreeNode
{
T _data;
RBTreeNode<T>* _left;
RBTreeNode<T>* _right;
RBTreeNode<T>* _parent;
colour _col;
RBTreeNode(const T& data)
:_data(data)
,_left(nullptr)
,_right(nullptr)
_parent(nullptr)
{ }
};
template<class K, class V, class KeyOfT>
class RBTree
{
typedef RBTreeNode<V> node;
node* _root = nullptr;
public:
//实现红黑树中的各种操作及其一些功能。
};1>.以上的框架相较于源码来说,这里是进行了一下调整,key参数就使用K,value参数就使用V,红黑树中的数据类型,我们这里使用的是T。
2>.因为RBTree实现了泛式不知道T参数到底是K,还是pair<K,V>,那么insert的内部进行插入的逻辑比较时,就没有办法去比较,因为pair默认支持的是key和value一起比较,我们需要的是不管任何时候比较的都是key,这与我们需要的明显不符合,所以我们在map和set中分别实现了一个MapKeyOfT和SetKeyOfT的仿函数传给RBTree中的KeyOfT,然后RBTree中通过KeyOfT仿函数取出T类型的对象中的key,再去进行比较,就会达到我们想要的效果了。
2.2 支持iterator迭代器的实现
1>.iterator实现的大框架跟list中的迭代器的思路是一样的,用一个类去封装节点的指针,再通过重载运算符实现,迭代器就可以像指针一样去访问了。
2>.这里的难点是operator++和operator--的实现。之前使用部分,我们分析了map和set的迭代器走的是中序遍历,左子树->根节点->右子树,那么这样的话begin( )返回的就是中序的第一个节点的iterator,也就是指向10这个节点的迭代器。
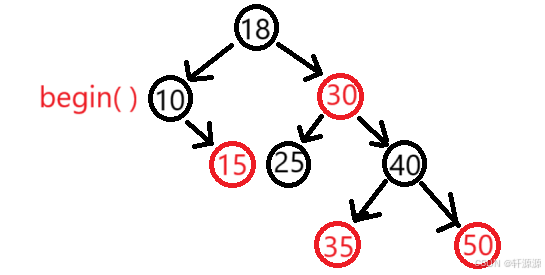
3>.迭代器++的核心逻辑就是不看全局,只考虑当前中序局部要访问的下一个节点。
4>.迭代器++时,如果it指向的节点的右子树不为空的话,那么就说明当前的这个节点我们已经访问完了,要访问的下一个节点就是右子树的最左节点,所以我们这里直接去找右子树中的最左节点就可以了。
5>.如果当前的这个节点是父亲的左,那么根据中序左子树->根节点->右子树,那么下一个访问的节点就是当前节点的父亲;如上图所示,假如it此时指向25这个节点,在++之后,就指向30那个节点了。
6>.如果当前的这个节点是父亲的右,根据中序左子树->根节点->右子树的访问顺序,就当前节点所在的父亲的子树就访问完了,那么下一个要访问的需要往根的祖先中去找,直到找到孩子是父亲左的那个祖先就是中序遍历下一个要访问的节点。

7>.end( )该如何表示呢?如上图所示,当it指向50时,++it,50为40的右,40为30的右,30为18的右,18是根,它的父亲是空指针,到这里时,就说明我们没有找到那个孩子是父亲左的那个祖先,这时父亲就为空了,那么我们就把it中的节点指针置为空,用nullptr去充当end( ),需要注意的是STL源码中,红黑树是增加了一个哨兵位头节点作为end( ),这哨兵位头节点和根互为父亲,左指针指向的是最左节点,右指针指向的是最右节点。相比于我们用nullptr来作为end( ),差别其实并不大,他能顺序的,我们也能实现,而STL源码中之所以要在红黑树上外加上一个头节点,主要还是因为更加便利,在求begin( )和end( )时就不需要我们去遍历红黑树了,还有一个原因是end()没有为空的这一个情况,更安全。

8>.我们这里地迭代器--地实现跟++的思路是类似的,逻辑正好可以反过来,因为它访问的顺序是右子树->根节点->左子树。
9>.set的iterator不支持修改,因为set节点中存储的数据内容就是关键字,而通过我们前面的学习可知,关键字是不允许被改变的,为了防止用户在使用时随意修改,我们把set的第二个模板参数改成const K即可,即RETree<K,const K,SetKeyOf>;(上述代码段中的第29行代码)。
10>.map的iterator也不支持修改,准确的说,不允许修改key,允许修改value,我们把map的第二个模板参数pair中的第一个参数改成const K即可,即 RBTree<K, pair<const K, V> MapKeyOfT> _t;(上述代码段中第14行代码)。
2.2.1 代码实现++和--这两个运算符
我们这里的代码实现选择用我们所讲的这个逻辑来实现,也就是不加哨兵位的那个,之所以不使用库中实现的那样(加上哨兵位)主要是因为太麻烦了,比方说当我们插入一个节点时,要判断它是否是最左节点,是否是最右节点,这使得我们无时不刻都得去维护哨兵位的三个指针,如果真的使用这个方法的话,那么我们就要去修改一下前面所写的那个红黑树的插入部分的代码了,为了相适应,我们这里选择不用哨兵位去实现++和--操作符。
template<class T,class Ref,class Ptr>
struct RBTreeIterator
{
typedef RBTreeNode<T> Node;
typedef RBTreeIterator<T, Ref, Ptr> Self;
node* _node;//通过我们前面的讲解可知,我们不难得知迭代器的内部其实就是封装了一个节点类型的指针。
node* _root;//指向整棵红黑树的那个根节点,这里不方便讲解它为什么要存在的意义和作用,因此我们放到后面再讲。
RBTreeIterator(Node*node,Node*root)
:_node(node)
,_root(root)
{ }
Self& operator++()
{
if (_node->_right)//如果当前节点的右子树不为空的话,那么下一个要访问的节点就是当前节点的右子树中的最左节点。
{
Node* leftMost = _node->_right;
while (leftMost->_left)//如果leftMost所指向的节点的左子树为空的话,则此时leftMost所指向的那个节点就是我们要找的那个最左节点,反之,就继续去左子树中寻找。
{
leftMost = leftMost->_left;
}
_node = leftMost;
}
else//否则,就说明我们下一个要访问的节点就是当前这个节点的祖宗中的其中一个,如果当前这个节点是父亲的左,那么,按照逻辑来说的话,下一个访问的节点是该节点的父亲节点,反之,说明当前节点的父亲节点所在的那棵子树我们因为已经全部访问完了,则要继续往祖宗节点中去找合适的节点,直到遇到这个节点是父亲的左或是parent为空时,就可以结束了,如果parent为空的话,就说明整棵红黑树全部都访问完了,直接返回空就可以了。
{
Node* cur = _node;//让cur去找下一个一个访问的节点。
Node* parent = cur->_parent;
while (parent&& cur = parent->_right)//如果parent不为空且当前节点不为parent的左,就说明我们还没有找到合适的节点,需要继续到上面去找。
{
cur = parent;
parent = cur->_parent;
}//出了循环之后,就说明找到了符合条件的节点了,就是parent指向的那个节点,我们这里可以不用判断parent为空的情况,因为如果出循环后parent为空的话,我们最后还是要让_node指向空,可以直接让其指向parent即可。
_node = parent;
}
return *this;//返回的是迭代器。
}
Self& operator--()
{
//我们这里在写--操作符时,相较于++操作符来说,除了逻辑在这里是相反的以外,还要防止它是否为空,因为可能有人会从end()开始--,end()返回的是指向空的迭代器,--会导致编译器报错的。
if (_node == nullptr)//如果_node为空,则说明当前的这个迭代器是指向红黑树遍历一次的最后一个位置的下一个位置,此时进行--操作的话,下一个访问的位置应该是整棵红黑树的最有节点。
{
Node* rightMost = _root;//现在就可以体现出_root这个变量的作用了,我们大家先想想,就是我们这个迭代器是作为一个单独的类域存在的,而我们前面所实现的set,也是作为一个单独的类域存在的,集体的一棵红黑树是在set类中搭建好的,而迭代器这个类是没有的,若想在迭代器类中也访问set类中的这棵红黑树,就只能传过来,因此我们才要在前面多加上一个_root成员变量,目的就是为了接收传过来的根节点。
while (rightMost && rightMost->_right)//之所以要再加上一步判断rightMost为真,是为了防止空树的存在。
{
rightMost = rightMost->_right;
}
_node = rightMost;
}//接下来,我们来顺着++操作符的逻辑逆一下就好了。
else if (_node->_left)//根据右子树->根节点->左子树的访问顺序我们可知如果当前节点的左子树存在的话,那么下一个被访问的节点就是当前节点的左子树中的最右节点。
{
Node* rightMost = _node->_left;
while (rightMost->_right)
{
rightMost = rightMost->_left;
}
}
else//就说明下一个要访问的节点是当前节点的祖宗中的某一个节点。
{
Node* cur = _node;
Node* parent = _node->_parent;
while (parent && cur == parent->_right)
{
cur = parent;
parent = cur->_parent;
}
_node = parent;
}
return *this;
}
Ref operator*()
{
reutrn _node->_data;
}
//...
};2.3 map支持[ ]
map要支持[ ]主要需要修改insert返回值支持,修改RBTree中的insert的返回值为pair<iterator,bool> Insert(const T& data)
代码实现如下所示:
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert({ key,V() });
return ret.first->second;//这里省略了一个"->"。
}OK,今天我们就先讲到这里了,那么,我们下一篇再见,谢谢大家的支持!
