面对训练好的通用的大语言模型,例如Llama3-8B,虽然在认知理解,知识问答,逻辑推理,数学,代码方面都表现很好。但是其在特定领域的知识是比较缺乏的,而且对中文问答表现也不是很好,经常出现中英文混答的问题。
所以打造一个属于自己的大模型,非常有必要!
由于原生的Llama3模型训练的中文语料占比非常低,因此在中文的表现方面略微欠佳!本教程就以Llama3-8B-Instruct开源模型为模型基座,通过开源程序LLaMA-Factory来进行中文的微调,提高Llama3的中文能力!
认识LLaMA-Factory

LLaMA-Factory是一个易用且高效的LLM微调工具箱。
-
支持多种模型
-
支持多种训练方法,例如增量预训练,指令跟随微调,PPO训练,DPO训练等
-
支持多种高效微调方法,例如全参数微调,冻结微调,LoRA微调等
这里我们选择指令跟随微调。更多的微调训练范式可以参考之前的文章XTuner微调LLM实践。
指令跟随微调,一般是采用SFT有监督的数据集进行微调,SFT数据集,表现形式一般是一问一答,一条数据一个标签的格式。
安装LLaMA-Factory
从Github上面下载最新的代码,并安装
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git cd LLaMA-Factory pip install -e ".[torch,metrics]"
官方提供了一键运行方式,可以分别实现对 Llama3-8B-Instruct 模型进行 LoRA 微调、推理和合并。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml llamafactory-cli chat examples/inference/llama3_lora_sft.yaml llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
但是我们选择,通过LLaMA Board实现可视化微调(由Gradio驱动),启动命令如下:
llamafactory-cli webui
访问链接地址 http://127.0.0.1:7860/
可以看到有Train(训练),Evaluate&Predict(评估和预测),Chat(对话),Export(导出)四个模块。
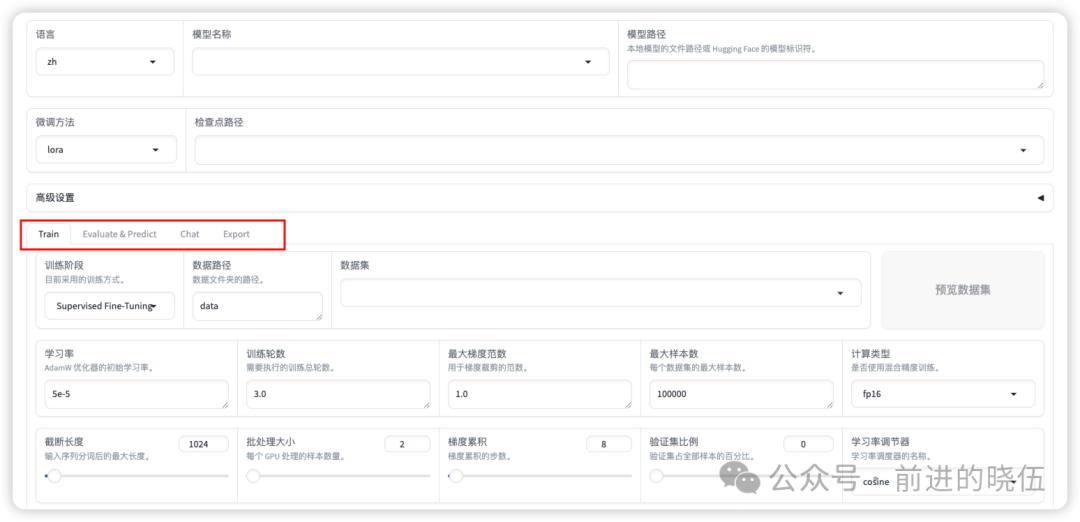
准备模型
我们可以选择从 OpenXLab 上下载 Meta-Llama-3-8B-Instruct 的权重。
git lfs install git clone https://code.openxlab.org.cn/MrCat/Llama-3-8B-Instruct.git Meta-Llama-3-8B-Instruct
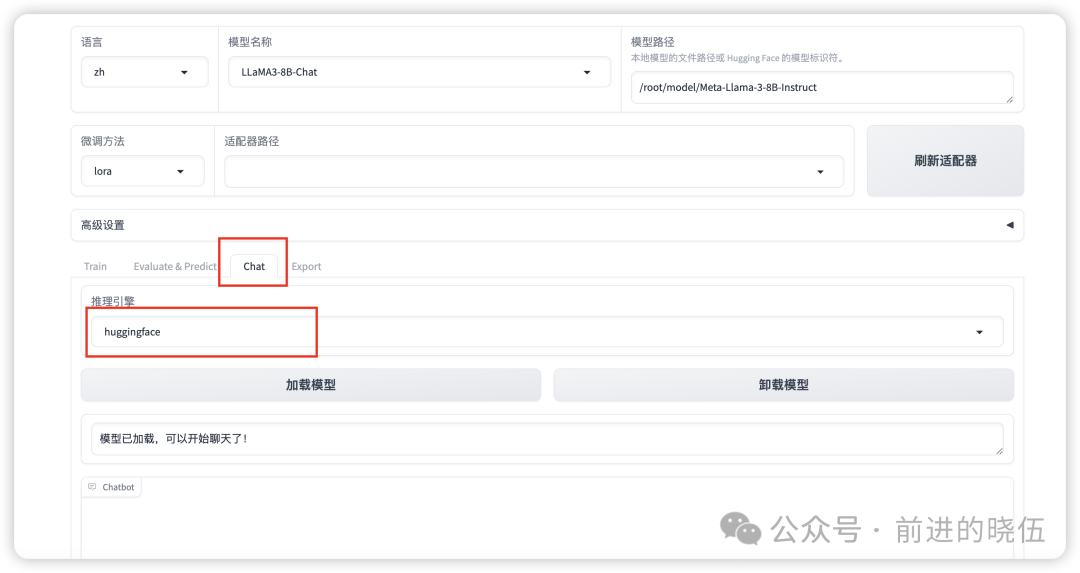
点击Chat,选择好我们的模型名称LLaMA3-8B-Chat,模型位置path需要更改成,我们自己下载的离线模型位置。
可以看到,推理引擎可选:huggingface,vllm。我们选择huggingface,然后点击加载模型。
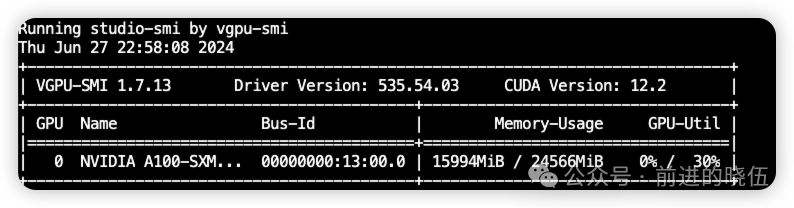
加载占用的显存大小约16GB:
准备数据集
准备数据集,需要庞大且细致的工程。
数据工程概述:
-
数据收集(可以从网络收集,或者利用现有的大模型,例如GPT-4来生成)
-
数据清洗
-
数据格式转换,转换成特定的格式,一般是json
-
得到准备好的数据集Dataset,一般我们准备好的数据集,还需要分成训练数据集和测试数据集
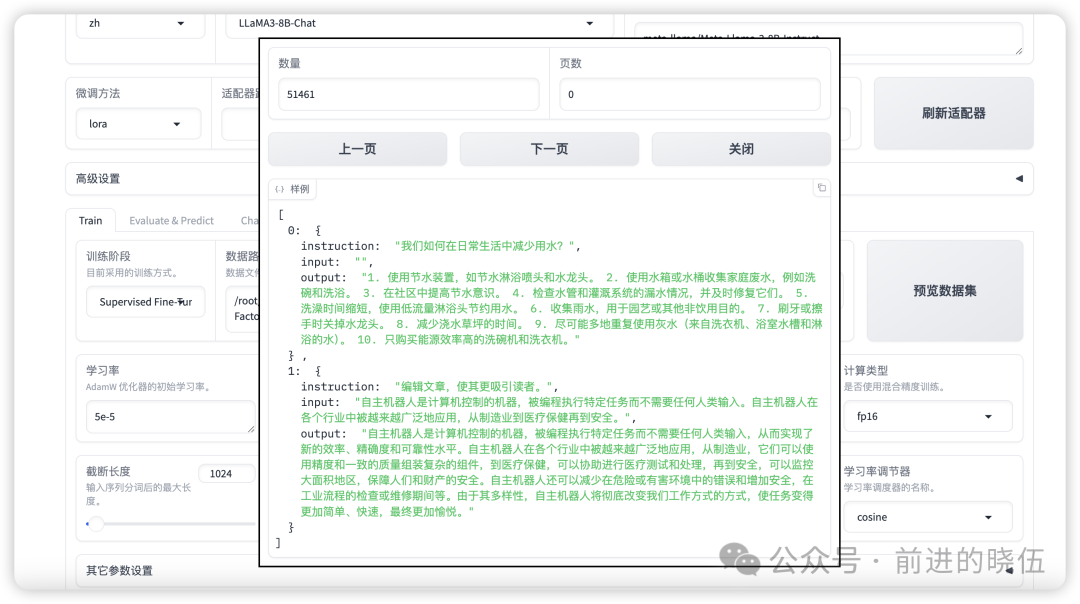
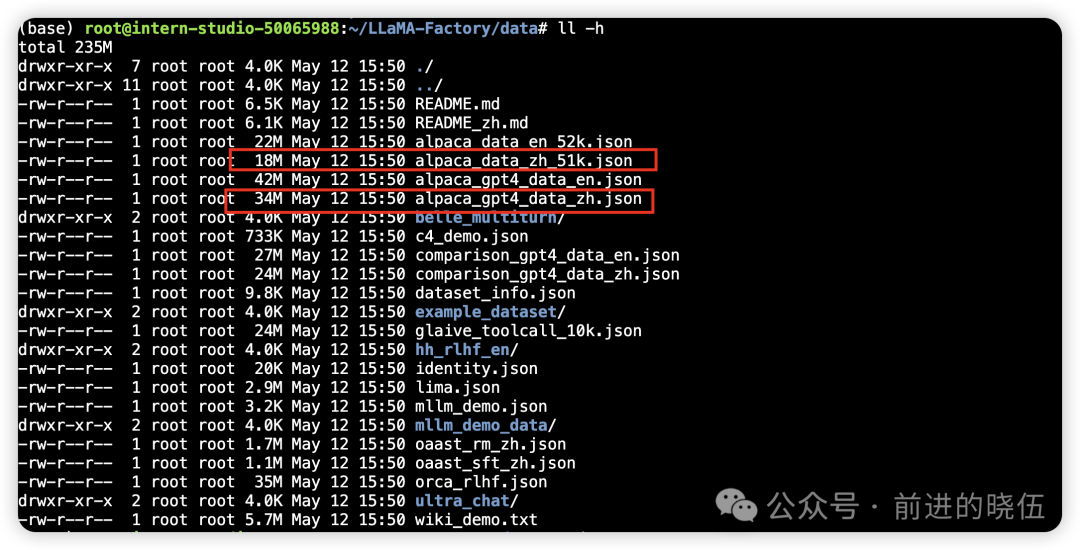
本教程我们选择LLaMA-Factory自带的数据集进行微调,位置在 /root/LLaMA-Factory/data/。
选择alpaca_gpt4_zh数据集,文件大小约为 34MB,选择预览数据集。
开始训练
包含微调方法有:full,freeze,lora。
训练方式包括:Supervised Fine-Tuning,Reword Modeling,PPO,DPO等。
为了节省算力和运行时间,我们选择LoRA微调方法,采用指令监督微调。在原有的大模型之前添加一个Adapter层。
让LLM套上LoRA之后,有了新的灵魂。关于LoRA的细节,可以参考文章XTuner微调LLM实践。
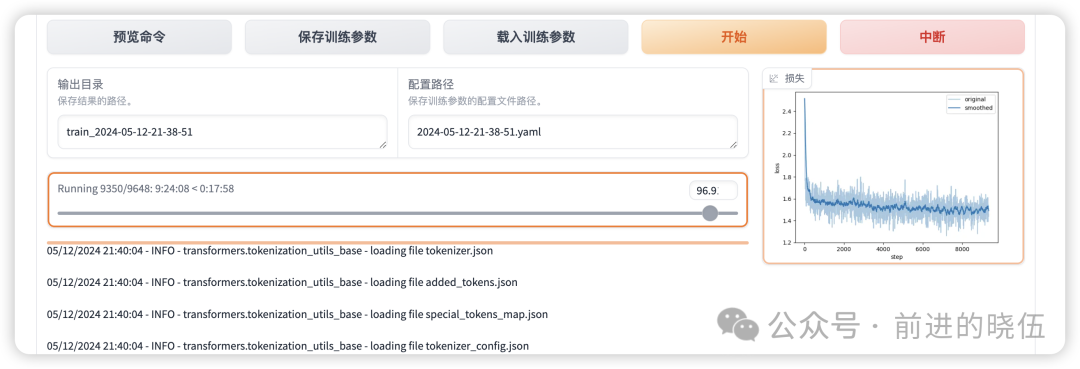
Web UI上面展示的训练指令:
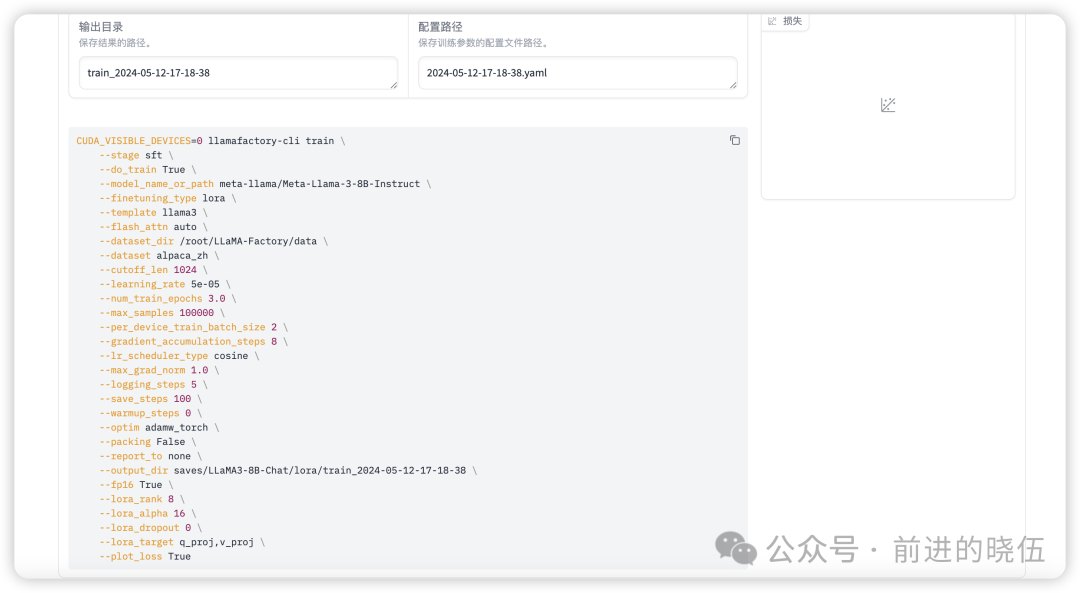
展示的就是我们微调大模型常见的超参数配置,有关于超参数的分析,会在之后的文章给大家分享。
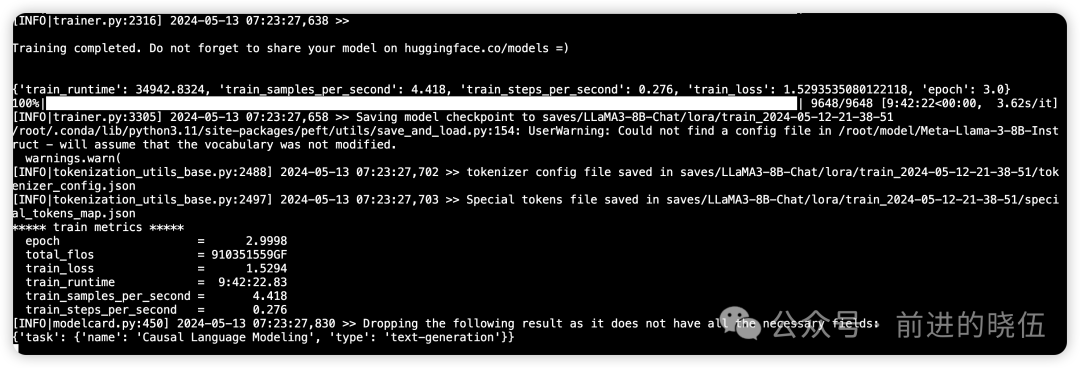
训练日志展示:

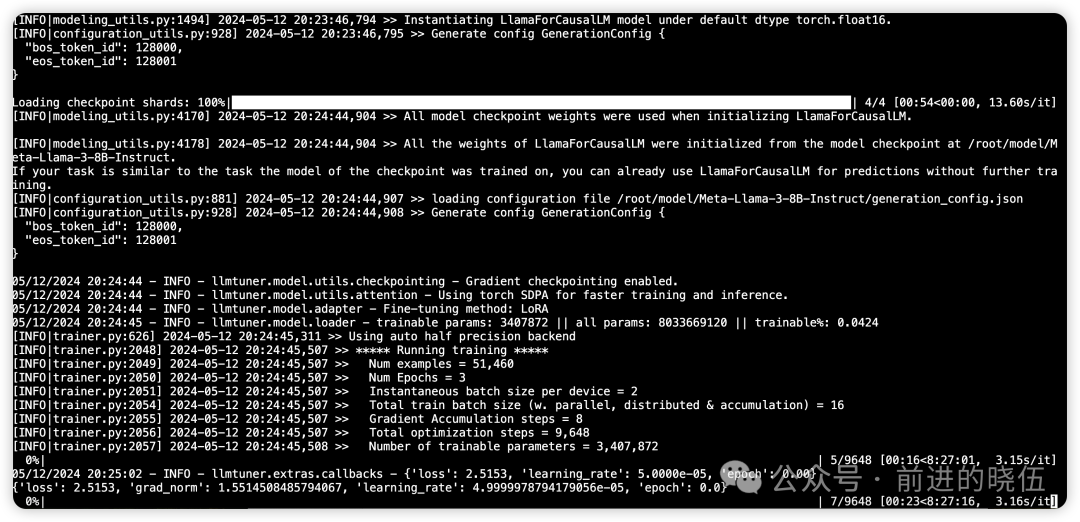
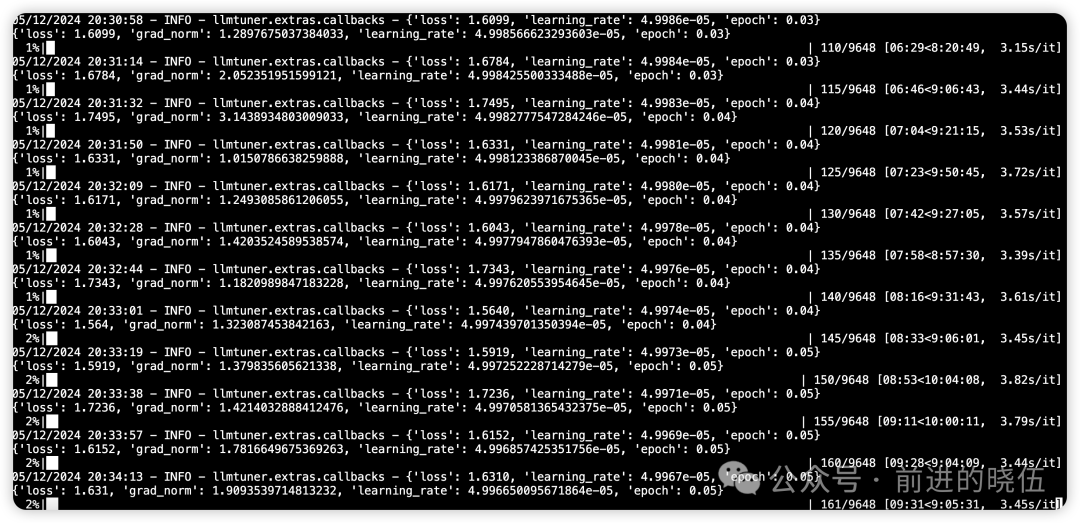
训练所需要的资源
我们的微调机器配置,是24GB显存的A100单卡机。
此时占用显存空间约为22GB,。
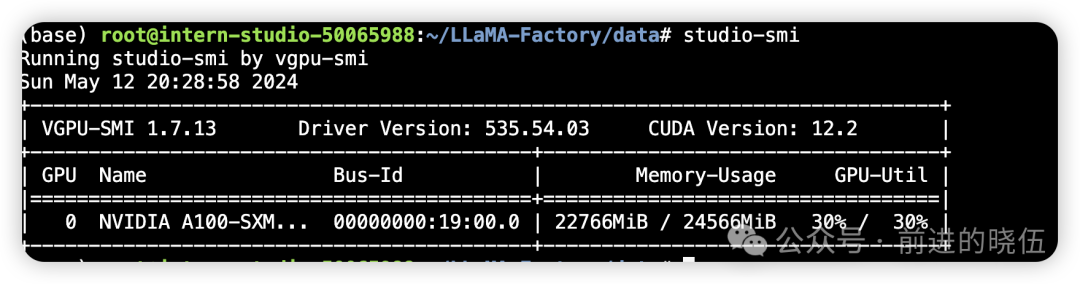
完成LoRA微调,花费了9.5小时: