接下来进行逻辑回归的建模实验,首先需要导入相关库和自定义的模块。
# 随机模块
import random
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# numpy
import numpy as np
# pytorch
import torch
from torch import nn,optim
import torch.nn.functional as F
from torch.utils.data import Dataset,TensorDataset,DataLoader
from torch.utils.tensorboard import SummaryWriter
# 自定义模块
from torchLearning import *
# 导入以下包从而使得可以在jupyter中的一个cell输出多个结果
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
当然,我们可以通过查看我们自定义的函数帮助文档来验证是否导入成功
tensorGenCla?
# output :
Signature:
tensorGenCla(
num_examples=500,
num_inputs=2,
num_class=3,
deg_dispersion=[4, 2],
bias=False,
)
Docstring:
分类数据集创建函数。
:param num_examples: 每个类别的数据数量
:param num_inputs: 数据集特征数量
:param num_class:数据集标签类别总数
:param deg_dispersion:数据分布离散程度参数,需要输入一个列表,其中第一个参数表示每个类别数组均值的参考、第二个参数表示随机数组标准差。
:param bias:建立模型逻辑回归模型时是否带入截距
:return: 生成的特征张量和标签张量,其中特征张量是浮点型二维数组,标签张量是长正型二维数组。
File: c:\users\desktop\study\【2024】深度学习课件\lesson 12\【pdf配套代码】code\torchlearning.py
Type: function
54 逻辑回归手动实现
接下来,尝试手动实现二分类逻辑回归,还是根据此前介绍的深度学习建模流程进行手动实现。

54.1 生成数据集
利用此前创建的tensorGenCla进行二分类数据集的创建
# 设置随机数种子
torch.manual_seed(420)
# 创建数据集
features, labels = tensorGenCla(num_class=2, bias=True)
# 可视化展示
plt.scatter(features[:, 0], features[:, 1], c = labels)
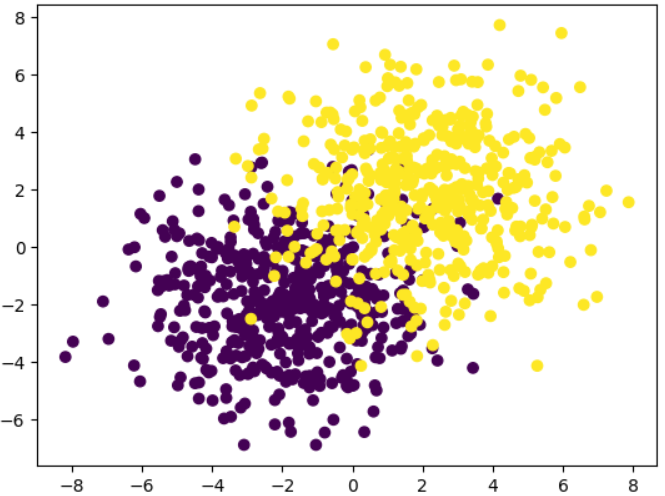
features
# output :
tensor([[-2.0141, -0.9911, 1.0000],
[-0.6593, -2.7657, 1.0000],
[-1.9395, -1.2347, 1.0000],
...,
[ 2.9623, 2.0861, 1.0000],
[ 0.4535, -0.2140, 1.0000],
[-2.6681, 3.3935, 1.0000]])
54.2 建模过程
Stage 1 模型选择
针对二分类问题(0-1问题),我们可以简单的输出一个结果,作为标签取值为1的概率,因此模型结构如下
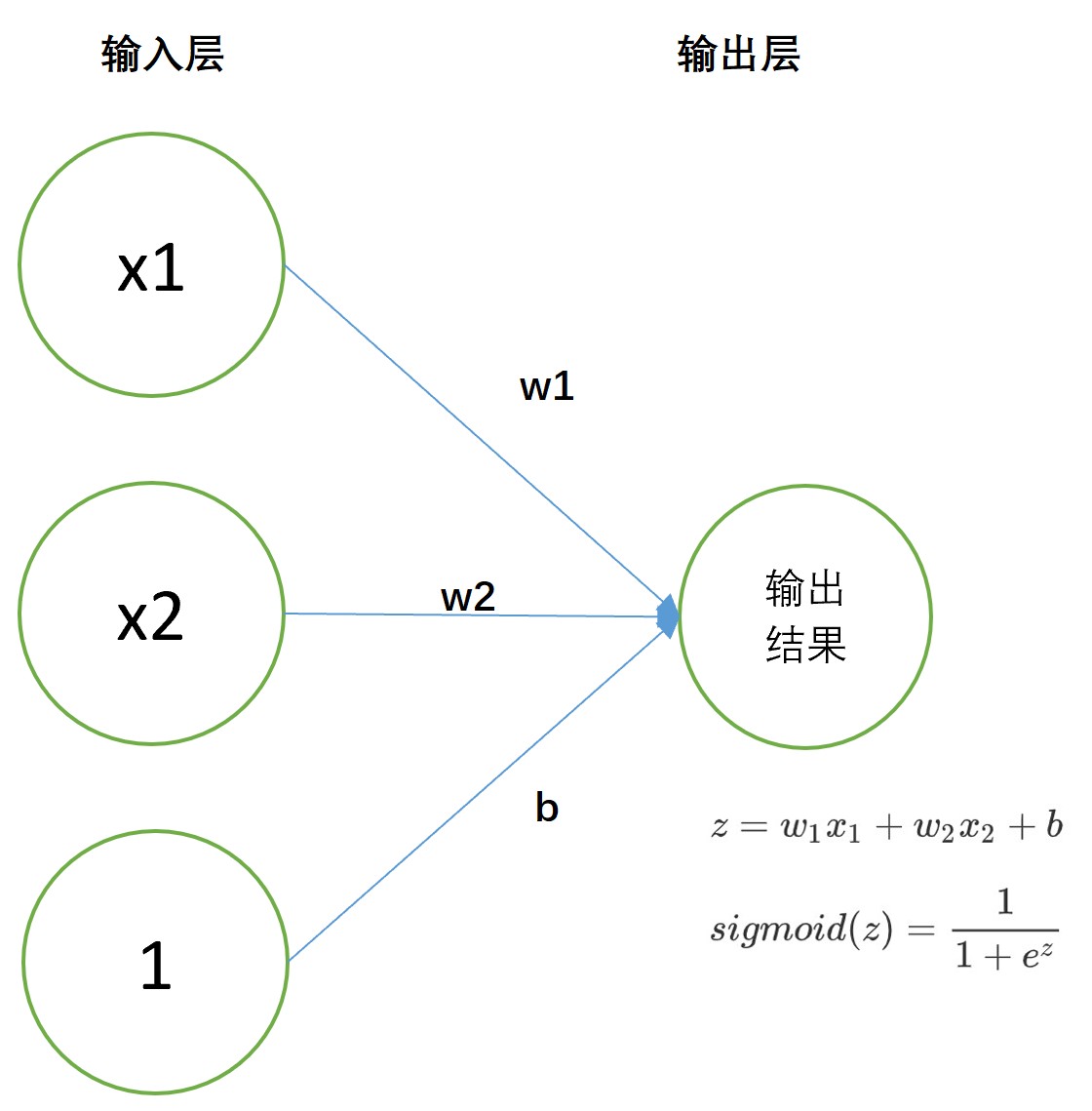
对应的可定义如下模型
-
激活函数
def sigmoid(z): return 1 / (1 + torch.exp(-z)) -
逻辑回归函数
def logistic(X, w): return sigmoid(torch.mm(X, w)) -
辅助函数
由于
sigmoid输出结果是连续值,而用于二分类判别时,我们需要将连续数值转化为所判定的类别,可定义对应分类函数如下:def cal(sigma, p = 0.5): return ((sigma>=0.5).float())a = torch.randint(10, (5, )) a # output : tensor([8, 0, 4, 4, 2]) a >= 5 # output : tensor([ True, False, False, False, False]) (a >= 5).float() # output : tensor([1., 0., 0., 0., 0.])
另外,对分类模型,我们往往会通过准确率 判别模型效果 ,因此还需要定义准确率函数
-
准确率函数
def accuracy(sigma, y): acc_bool = cal(sigma).flatten() == y.flatten() acc = torch.mean(acc_bool.float()) return (acc)p = torch.tensor([1, 1, 2]) == torch.tensor([1, 2, 2]) p # output : tensor([ True, False, True]) p.float() # output : tensor([1., 0., 1.]) torch.mean(p.float()) # output : tensor(0.6667)
Stage 2 定义损失函数
def cross_entropy(sigma, y):
return (-(1/y.numel())*torch.sum((1-y)*torch.log(1-sigma)+y*torch.log(sigma)))
Stage 3 定义优化方法
def sgd(params,lr):
params.data -= lr * params.grad
params.grad.zero_()
Stage 4 训练模型
# 设置随机数种子
torch.manual_seed(420)
# 初始化核心参数
batch_size = 10 # 每一个小批的数量
lr = 0.03 # 学习率
num_epochs = 3 # 训练过程遍历几次数据
w = torch.ones(3, 1, requires_grad = True) # 随机设置初始权重
# 参与训练的模型方程
net = logistic # 使用逻辑回归方程
loss = cross_entropy # 交叉熵损失函数
# 训练过程
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w), y)
l.backward()
sgd(w, lr)
train_acc = accuracy(net(features, w), labels)
print('epoch %d, accuracy %f' % (epoch + 1, train_acc))
# output :
epoch 1, accuracy 0.904000
epoch 2, accuracy 0.907000
epoch 3, accuracy 0.914000
w
# output :
tensor([[1.0069],
[0.9753],
[0.5765]], requires_grad=True)
54.3 模型调试
根据上述迭代三轮返回的准确率,能够看出整体还在增加,让我们再多迭代几轮查看结果
# 设置随机数种子
torch.manual_seed(420)
# 迭代轮数
num_epochs = 20
# 设置初始权重
w = torch.ones(3, 1, requires_grad = True)
# 设置列表容器
train_acc = []
# 执行迭代
for i in range(num_epochs):
for epoch in range(i):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w), y)
l.backward()
sgd(w, lr)
train_acc.append(accuracy(net(features, w), labels))
# 绘制图像查看准确率变化情况
plt.plot(list(range(num_epochs)), train_acc)
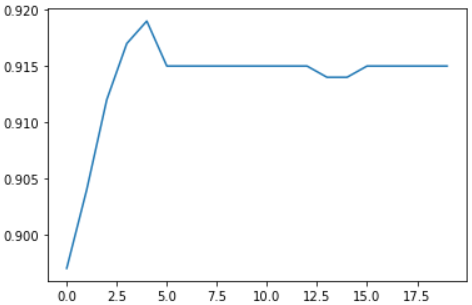
train_acc
# output :
[tensor(0.8970),
tensor(0.9040),
tensor(0.9120),
tensor(0.9170),
tensor(0.9190),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9140),
tensor(0.9140),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150)]
能够看出,增加迭代次数之后,损失函数逼近最小值点,每次迭代梯度取值较小,整体准确率趋于平稳
当然,如果我们将数据难度增加,也就是增加数据的离散程度,是否会对模型结果造成影响
tensorGenCla?
# output :
Signature:
tensorGenCla(
num_examples=500,
num_inputs=2,
num_class=3,
deg_dispersion=[4, 2],
bias=False,
)
Docstring:
分类数据集创建函数。
:param num_examples: 每个类别的数据数量
:param num_inputs: 数据集特征数量
:param num_class:数据集标签类别总数
:param deg_dispersion:数据分布离散程度参数,需要输入一个列表,其中第一个参数表示每个类别数组均值的参考、第二个参数表示随机数组标准差。
:param bias:建立模型逻辑回归模型时是否带入截距
:return: 生成的特征张量和标签张量,其中特征张量是浮点型二维数组,标签张量是长正型二维数组。
File: c:\users\desktop\study\【2024】深度学习课件\lesson 12\【pdf配套代码】code\torchlearning.py
Type: function
torch.manual_seed(420)
features, labels = tensorGenCla(num_class=2, bias=True, deg_dispersion=[4, 4])
# 可视化展示
plt.scatter(features[:, 0], features[:, 1], c = labels)
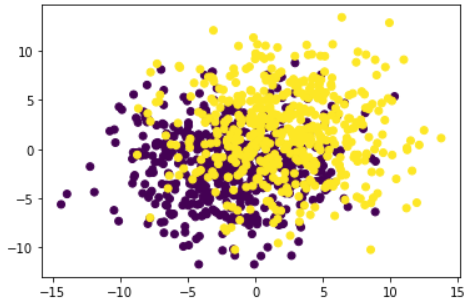
# 设置随机数种子
torch.manual_seed(420)
# 迭代轮数
num_epochs = 20
# 设置初始权重
w = torch.zeros(3, 1, requires_grad = True)
# 设置列表容器
train_acc = []
# 执行迭代
for i in range(num_epochs):
for epoch in range(i):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w), y)
l.backward()
sgd(w, lr)
train_acc.append(accuracy(net(features, w), labels))
# 绘制图像查看准确率变化情况
plt.plot(list(range(num_epochs)), train_acc)
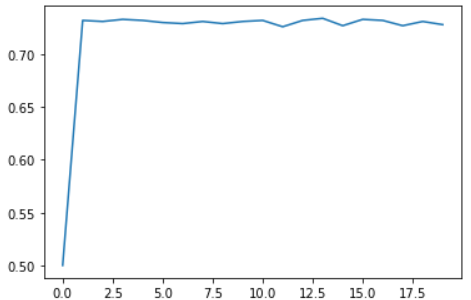
能够发现,随着数据情况变复杂,相同模型的准确率发生了很大的变化。
train_acc
# output :
[tensor(0.5000),
tensor(0.7320),
tensor(0.7310),
tensor(0.7330),
tensor(0.7320),
tensor(0.7300),
tensor(0.7290),
tensor(0.7310),
tensor(0.7290),
tensor(0.7310),
tensor(0.7320),
tensor(0.7260),
tensor(0.7320),
tensor(0.7340),
tensor(0.7270),
tensor(0.7330),
tensor(0.7320),
tensor(0.7270),
tensor(0.7310),
tensor(0.7280)]
55 逻辑回归的快速实现
55.1 构建模型
接下来,我们练习使用PyTorch中的函数和类,进行逻辑回归的快速构建。
定义核心参数
batch_size = 10 # 每一个小批的数量
lr = 0.03 # 学习率
num_epochs = 3 # 训练过程遍历几次数据
数据准备
# 设置随机数种子
torch.manual_seed(420)
# 创建数据集
features, labels = tensorGenCla(num_class=2)
labels = labels.float() # 损失函数要求标签也必须是浮点型
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
Stage 1 定义模型
class logisticR(nn.Module):
def __init__(self, in_features=2, out_features=1): # 定义模型的点线结构
super(logisticR, self).__init__()
self.linear = nn.Linear(in_features, out_features)
def forward(self, x): # 定义模型的正向传播规则
out = self.linear(x)
return out
# 实例化模型和
logic_model = logisticR()
Stage 2 定义损失函数
criterion = nn.BCEWithLogitsLoss()
Stage 3 定义优化方法
optimizer = optim.SGD(logic_model.parameters(), lr = lr)
Stage 4 模型训练
def fit(net, criterion, optimizer, batchdata, epochs):
for epoch in range(epochs):
for X, y in batchdata:
zhat = net.forward(X)
loss = criterion(zhat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
接下来,即可执行模型训练
# 设置随机数种子
torch.manual_seed(420)
fit(net = logic_model,
criterion = criterion,
optimizer = optimizer,
batchdata = batchData,
epochs = num_epochs)
查看模型训练结果
logic_model
# output :
logisticR(
(linear): Linear(in_features=2, out_features=1, bias=True)
)
# 查看模型参数
list(logic_model.parameters())
# output :
[Parameter containing:
tensor([[0.8394, 0.8016]], requires_grad=True),
Parameter containing:
tensor([-0.2617], requires_grad=True)]
# 计算交叉熵损失
criterion(logic_model(features), labels)
# output :
tensor(0.2293, grad_fn=<BinaryCrossEntropyWithLogitsBackward>)
def acc_zhat(zhat, y):
"""
输入为线性方程计算结果,输出为逻辑回归准确率的函数
:param zhat:线性方程输出结果
:param y: 数据集标签张量
:return:准确率
"""
sigma = sigmoid(zhat)
return accuracy(sigma, y)
acc_zhat(logic_model(features), labels)
# output :
tensor(0.9130)
55.2 模型调试
同样,我们首先尝试多迭代几次,看下准确率如何发生变化
#创建数据
torch.manual_seed(420)
features, labels = tensorGenCla(num_class=2)
labels = labels.float()
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
# 设置随机数种子
torch.manual_seed(420)
# 初始化核心参数
num_epochs = 20
LR1 = logisticR()
cr1 = nn.BCEWithLogitsLoss()
op1 = optim.SGD(LR1.parameters(), lr = lr)
# 创建列表容器
train_acc = []
# 执行建模
for epochs in range(num_epochs):
fit(net = LR1,
criterion = cr1,
optimizer = op1,
batchdata = batchData,
epochs = epochs)
epoch_acc = acc_zhat(LR1(features), labels)
train_acc.append(epoch_acc)
# 绘制图像查看准确率变化情况
plt.plot(list(range(num_epochs)), train_acc)
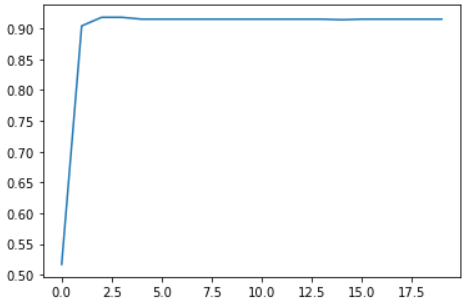
train_acc
# output :
[tensor(0.5170),
tensor(0.9040),
tensor(0.9180),
tensor(0.9180),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9140),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150),
tensor(0.9150)]
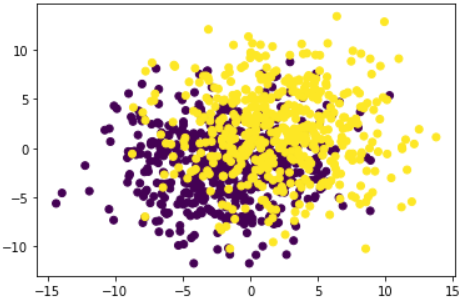
接下来,和此前一样,接下来尝试增加数据难度来测试模型分类性能
#创建数据
torch.manual_seed(420)
features, labels = tensorGenCla(num_class=2, deg_dispersion=[4, 4])
labels = labels.float()
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
plt.scatter(features[:, 0], features[:, 1], c = labels)
#创建数据
torch.manual_seed(420)
# 数据封装与加载
data = TensorDataset(features, labels)
batchData = DataLoader(data, batch_size = batch_size, shuffle = True)
# 初始化核心参数
num_epochs = 20
LR1 = logisticR()
cr1 = nn.BCEWithLogitsLoss()
op1 = optim.SGD(LR1.parameters(), lr = lr)
# 创建列表容器
train_acc = []
# 执行建模
for epochs in range(num_epochs):
fit(net = LR1,
criterion = cr1,
optimizer = op1,
batchdata = batchData,
epochs = epochs)
epoch_acc = acc_zhat(LR1(features), labels)
train_acc.append(epoch_acc)
# 绘制图像查看准确率变化情况
plt.plot(list(range(num_epochs)), train_acc)
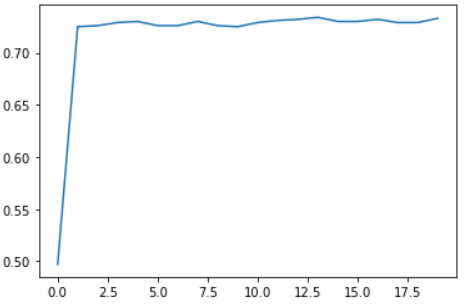
train_acc
# output :
[tensor(0.4970),
tensor(0.7250),
tensor(0.7260),
tensor(0.7290),
tensor(0.7300),
tensor(0.7260),
tensor(0.7260),
tensor(0.7300),
tensor(0.7260),
tensor(0.7250),
tensor(0.7290),
tensor(0.7310),
tensor(0.7320),
tensor(0.7340),
tensor(0.7300),
tensor(0.7300),
tensor(0.7320),
tensor(0.7290),
tensor(0.7290),
tensor(0.7330)]
和此前一样,准确率在0.7-0.75之间徘徊。