在AI的世界里,我们经常会听到 “知识增强生成”(Knowledge Augmented Generation,简称KAG)。它不仅是个概念,更是一套强大的工具,用来解决专业领域中逻辑推理和问答的难题。今天,我们就来聊聊 KAG 框架是怎么帮助开发者提升工作效率的,顺便看看它是如何优于传统的 RAG 模型。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
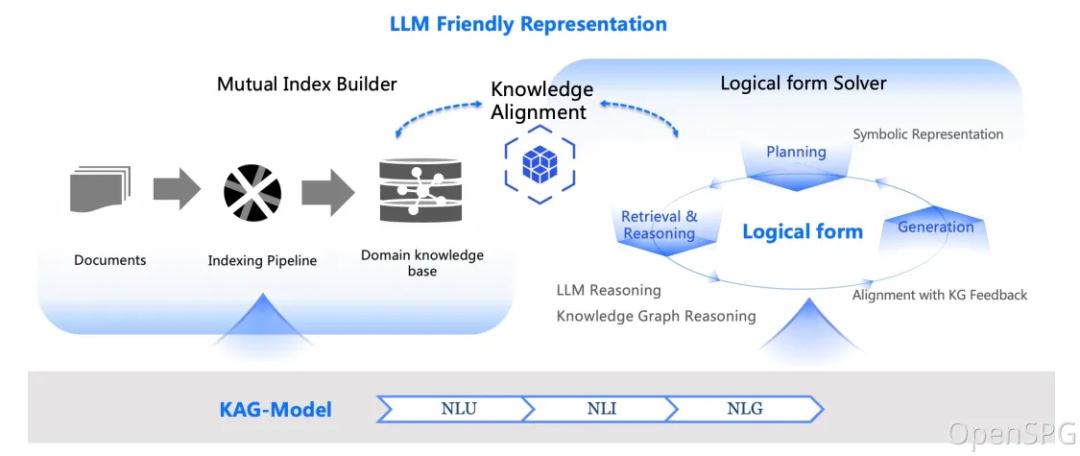
KAG是什么?它解决了什么问题?
KAG[1] 是一个基于 OpenSPG 引擎 和 大语言模型(LLM) 的推理框架,主要应用于专业领域的知识库构建和问答解决方案。简单来说,它帮我们搞定以下几个问题:
-
- 克服模糊性:传统的 RAG(Retrieve-then-Generate)模型靠向量相似度来匹配答案,但相似度往往不够精准,容易跑偏。而 KAG 能用逻辑推理让结果更可信。
-
- 减少噪声:通过一种叫“知识对齐”的方法,KAG 优化了由 OpenIE 生成的噪声问题。
-
- 支持多跳推理:你可以通过多步推理,获得更复杂问题的答案。
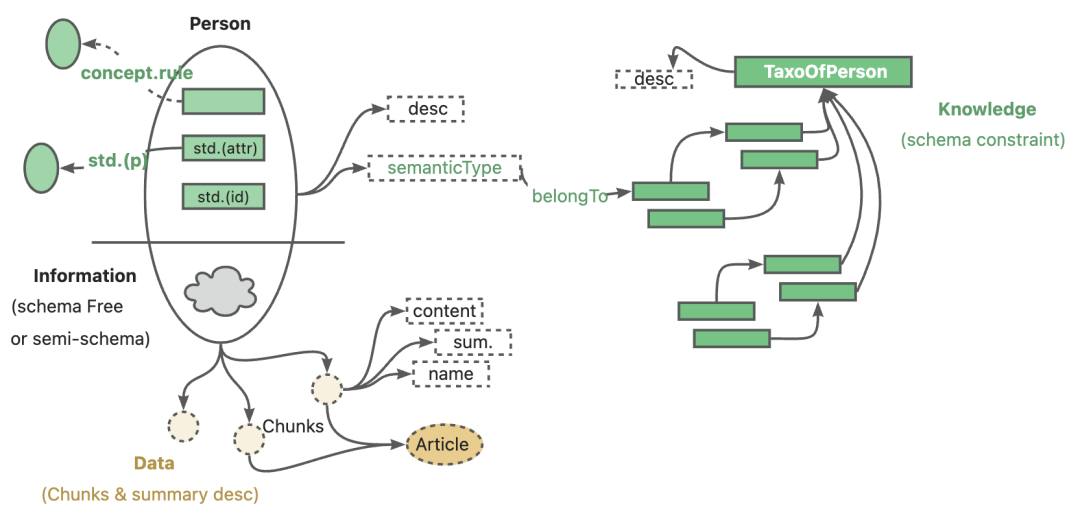
用一句话总结:KAG 是让 AI 在知识库场景下更智能、更靠谱的解决方案。
核心功能解析
接下来我们分点聊聊 KAG 的核心能力,这些也是它比传统方法更强的关键所在。
1. 知识表示:让数据变得有序
在现实场景中,我们的数据类型五花八门:
-
• 非结构化数据:比如新闻、日志、书籍等。
-
• 结构化数据:交易记录、统计表格等。
-
• 领域经验:专家规则、业务逻辑。
KAG 引入了 DIKW(数据-信息-知识-智慧)模型,通过以下几步,把杂乱的数据转化为 统一的知识图谱:
-
• 布局分析:识别数据内容的结构。
-
• 知识抽取:提取关键信息。
-
• 语义对齐:让不同来源的数据互通有无。

构建完图谱后,KAG 会用 双向索引机制 将知识图谱和原始文本关联起来。这样,既可以支持基于图谱的推理,也能回溯到具体的文本片段,逻辑清晰且上下文连贯。
2. 逻辑引导的混合推理
KAG 的推理过程可以看成一个“多工具协作”的过程,包含以下三种操作符:
-
- 规划:将问题分解成多步任务。
-
- 推理:通过逻辑推导得到中间或最终结论。
-
- 检索:找到相关的文档或数据。
例如,一个复杂的问题可能需要先检索相关知识,再进行数字计算,最后结合语义推理。KAG 的设计支持这些操作串联起来,像流水线一样高效完成任务。
这里用一个简单的流程图说明:
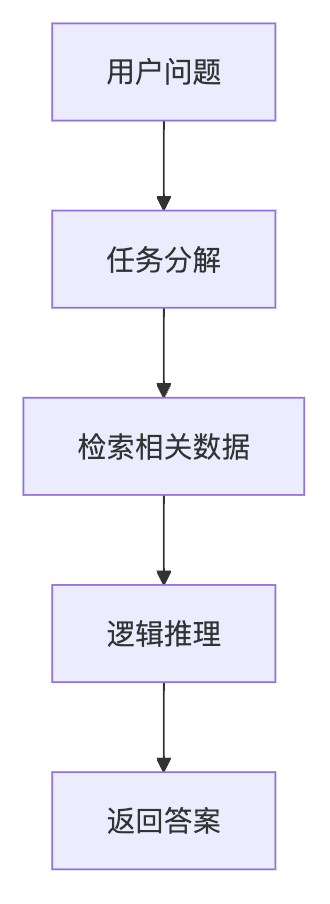
实操:如何快速上手 KAG?
KAG 提供了两种使用方式:
-
- 产品模式:适合普通用户,通过浏览器直接体验。
-
- 工具模式:面向开发者,可以深度定制。
1. 产品模式
先安装 KAG 的依赖环境(以 Docker 为例):
curl -sSL https://raw.githubusercontent.com/OpenSPG/openspg/refs/heads/master/dev/release/docker-compose-west.yml -o docker-compose-west.yml docker compose -f docker-compose-west.yml up -d
然后,访问 http://127.0.0.1:8887 即可。
2. 工具模式
如果你是一名开发者,可以用下面的命令把 KAG 拉到本地,并搭建开发环境:
Mac/Linux 开发者
# 创建虚拟环境并激活 conda create -n kag-demo python=3.10 && conda activate kag-demo # 克隆代码库 git clone https://github.com/OpenSPG/KAG.git # 安装 KAG cd KAG && pip install -e .
Windows 开发者
# 安装 Python 3.8.10 或更高版本,并安装 Git py -m venv kag-demo && kag-demo\Scripts\activate git clone https://github.com/OpenSPG/KAG.git cd KAG && pip install -e .
安装完成后,你可以通过内置组件测试性能,或者直接将框架应用到你的业务场景中。
KAG 和其他工具的对比
为了更直观地理解 KAG 的优势,我们用一张表格来对比它与传统 RAG 和 GraphRAG 模型的区别:
| 功能点 | KAG | 传统 RAG | GraphRAG |
|---|---|---|---|
| 检索方式 |
|
知识对齐 + 逻辑推理
|
向量相似度
|
图结构检索
|
|
推理能力
|
支持多跳推理
|
不支持
|
支持,但噪声大
|
|
数据兼容性
|
结构化 + 非结构化数据
|
主要是非结构化数据
|
结构化数据为主
|
|
噪声控制
|
噪声低
|
噪声高
|
中等
|
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;

第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓