1.导入文件
注意:要把excel放到跟你的python文件在同一个地方
import pandas as pd
import numpy as np
df=pd.read_excel("鸢尾花训练数据.xlsx",engine="openpyxl")import pandas 先引入 (若没有下载 需要在终端下载 pip install pandas)
这里要把excel的名字加后缀xlsx作为参数,以及一个引擎openpyxl,需要在终端输入pip install openpyxl 就可以下载了
2.显示数据信息
import pandas as pd
import numpy as np
df=pd.read_excel("鸢尾花训练数据.xlsx",engine="openpyxl")
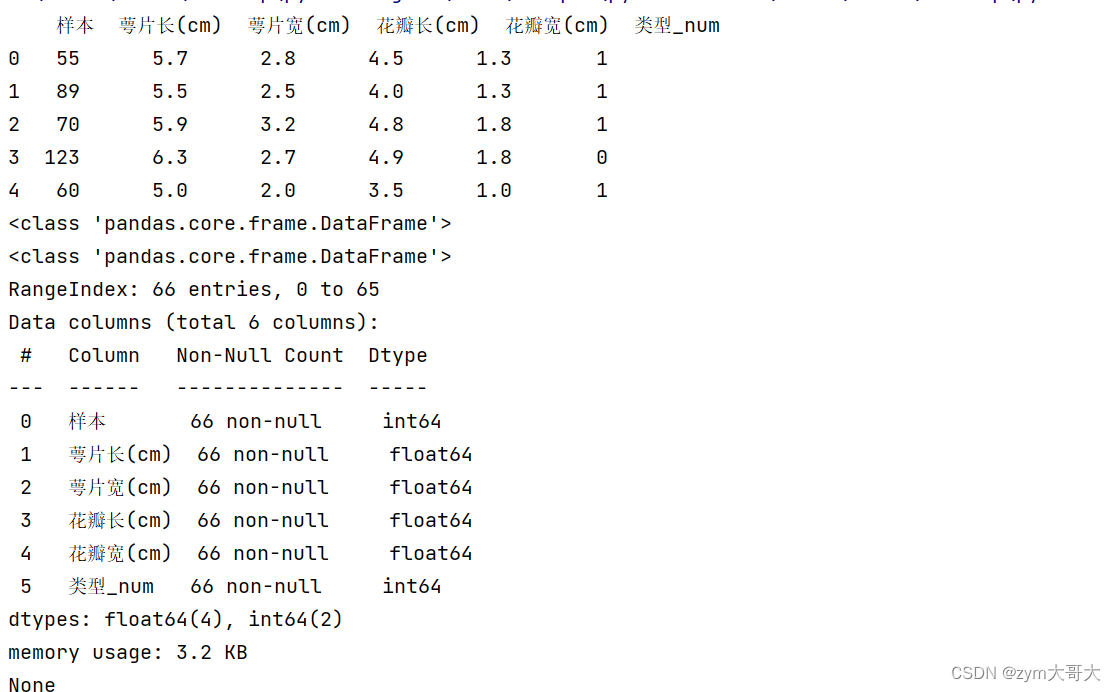
print(df.head())#打印前五行 可以填参数来决定显示几行
print(type(df))
df去接收从excel得到的信息,用.head()函数去查看信息,参数可以自己定,默认5行,输入几就显示几行
import pandas as pd
import numpy as np
df=pd.read_excel("鸢尾花训练数据.xlsx",engine="openpyxl")
print(df.head())#打印前五行 可以填参数来决定显示几行
print(type(df))
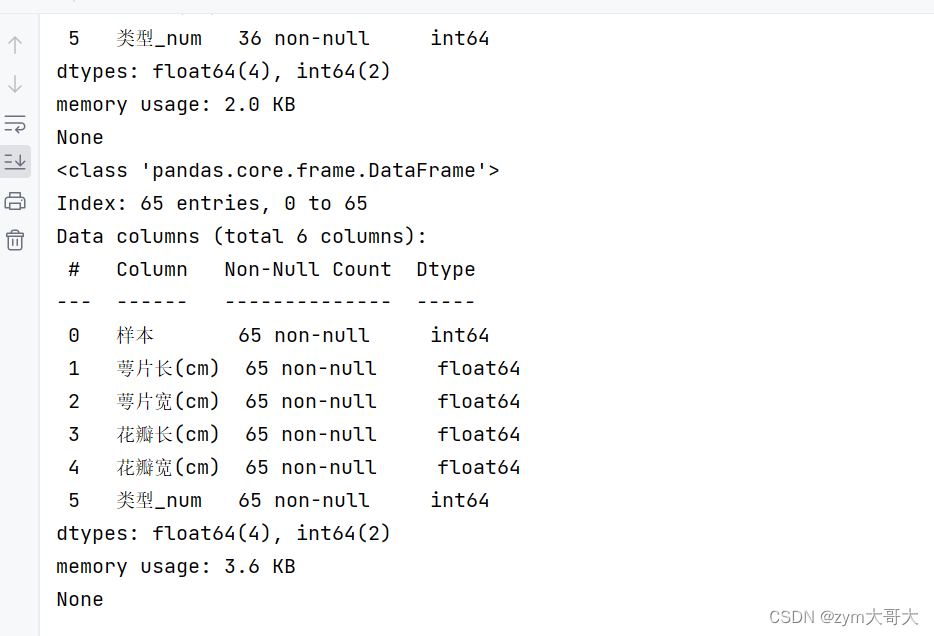
print(df.info())
用.info()函数可以查看完整详细excel的信息
3.在python里面形成与df一样的类型
arr=np.array([1,2,3])
data={'x':[1,2,3],'y':[2,3,4],'z':[4,5,6]}
dataf=pd.DataFrame(data)
print(dataf)通过打印出df的类型,在构建一个字典后放进DataFrame()中

4.对缺失的数据处理以及对数据类型的转换
.dropna()函数会把数据中有缺少的值哪一行都去除掉(NaN)
.astype(哪一个类型) 里面是float就会把int转换为float
df=df.dropna()
print(df.head())
df['类型_num']=df['类型_num'].astype(float)
print(df.info())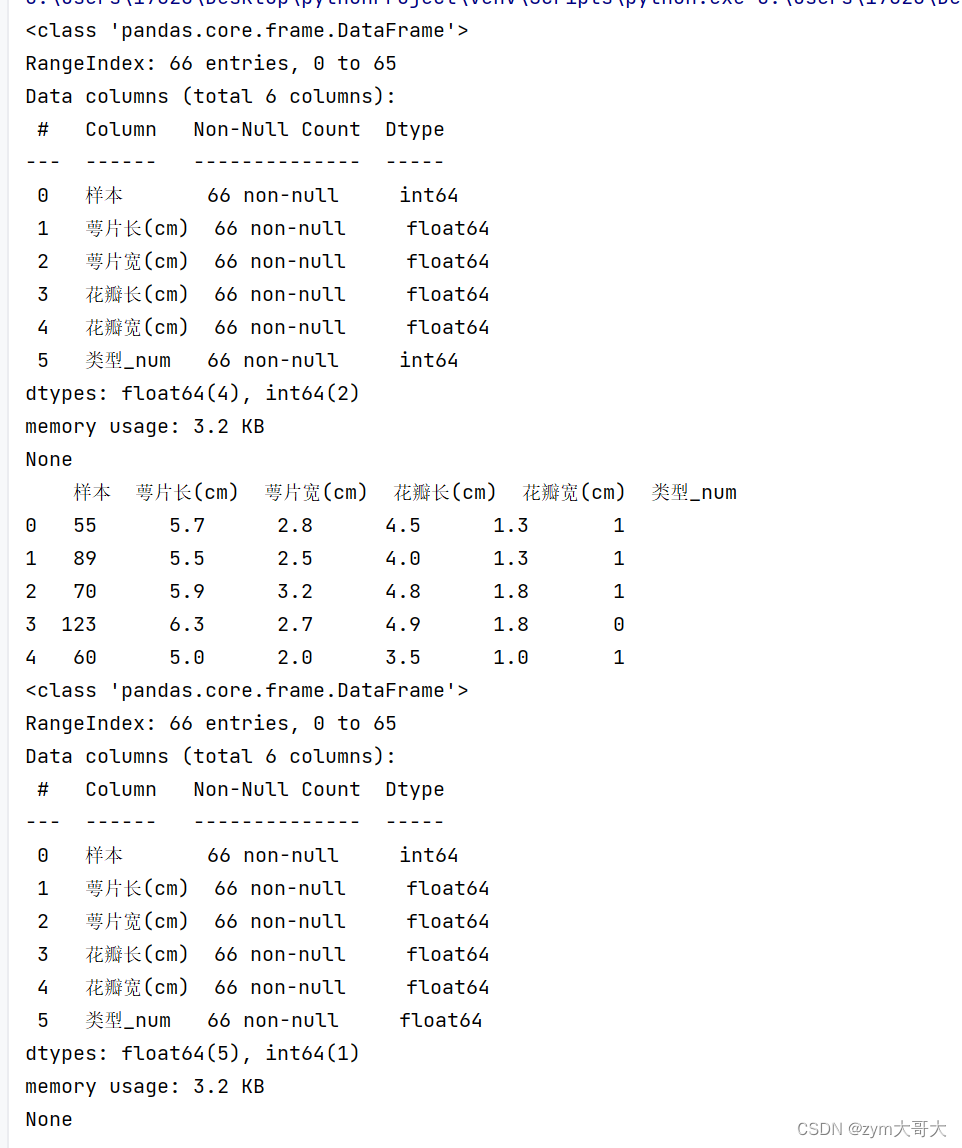
5.数据的选择和过滤
#数据选择和过滤
de1=df[df['类型_num']==1]#把为1的一整列都留下来
print(de1.info())
lb=df['花瓣宽(cm)'].mean()-3*df['花瓣宽(cm)'].std()
ub=df['花瓣宽(cm)'].mean()+3*df['花瓣宽(cm)'].std()
selected_df=df[(df['花瓣宽(cm)']>=lb)&(df['花瓣宽(cm)']<=ub)]
print(selected_df.info())比较会返回True和False
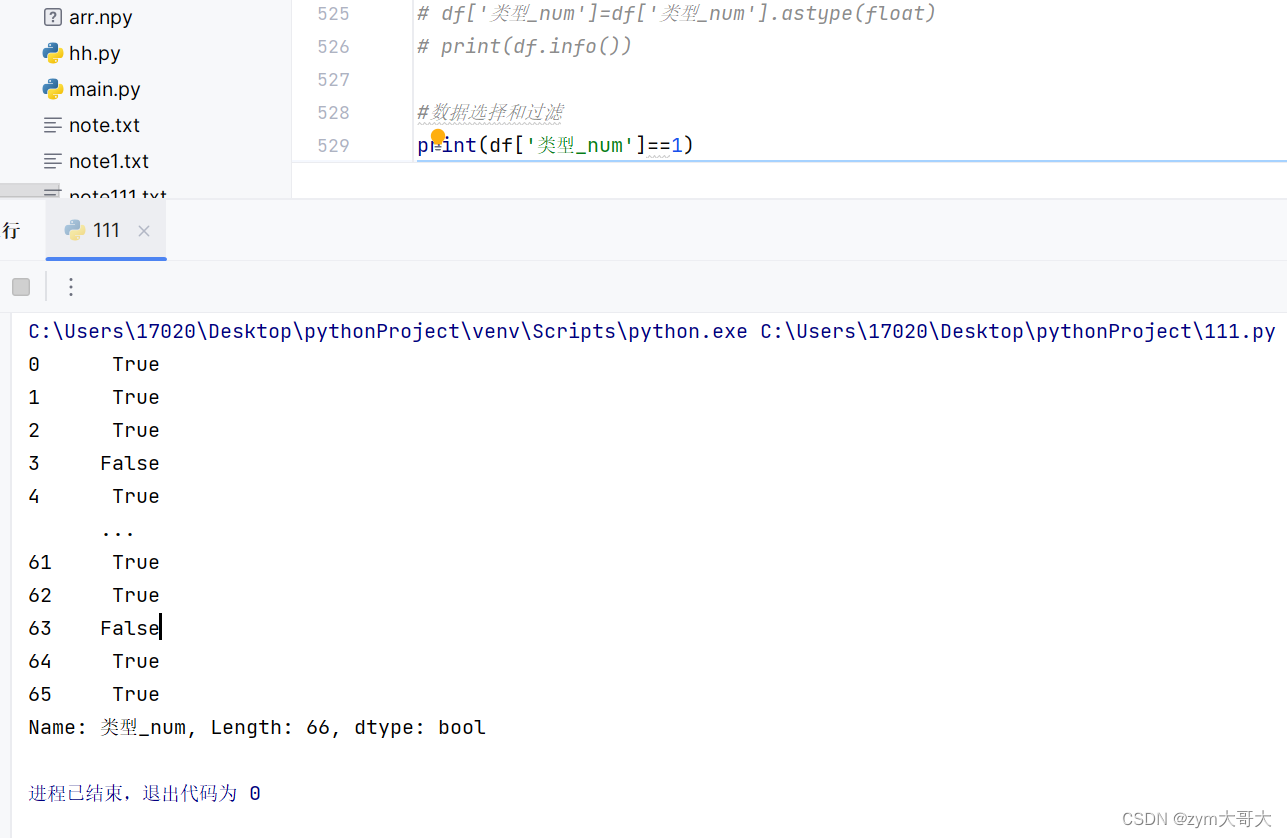
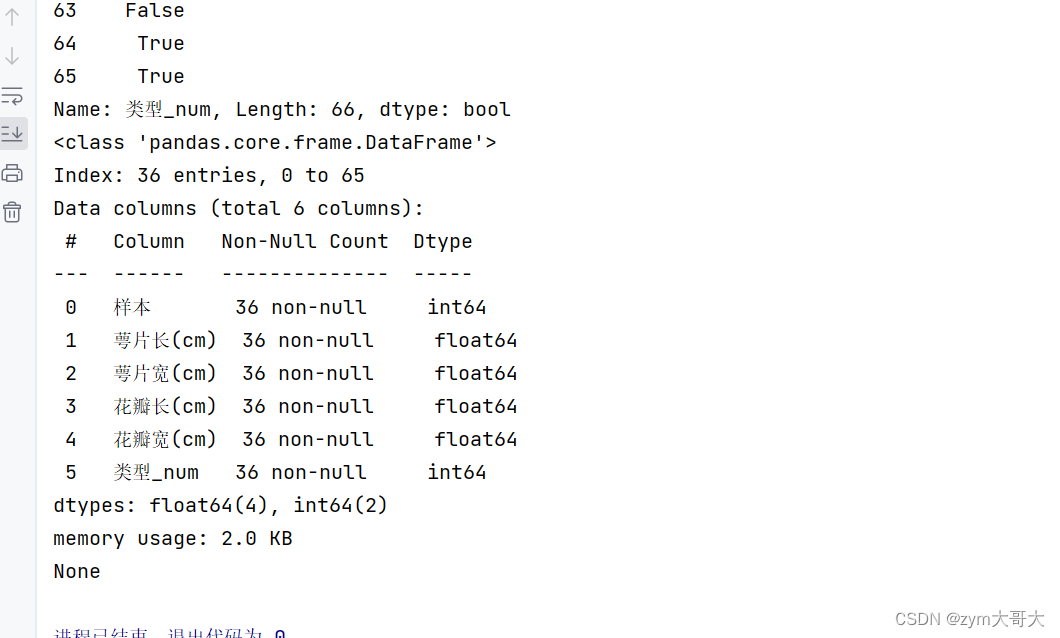
lb=df['花瓣宽(cm)'].mean()-3*df['花瓣宽(cm)'].std()
ub=df['花瓣宽(cm)'].mean()+3*df['花瓣宽(cm)'].std()
selected_df=df[(df['花瓣宽(cm)']>=lb)&(df['花瓣宽(cm)']<=ub)]
print(selected_df.info())