一、摘要
随着大模型(LLM)在自然语言处理领域的快速崛起,如何高效地进行大规模模型的训练,成为业界和学术界共同关注的焦点。近期发表的技术报告 “Muon is Scalable for LLM Training”(以下简称“论文”)以及开源代码,展示了一种基于矩阵正交化(Matrix Orthogonalization)的新型优化器 Muon,并在此基础上训练了一个 3B/16B 规模的混合专家(MoE)模型 “Moonlight”,累计训练语料达 5.7T tokens。论文的核心结论是:Muon 相较于传统 AdamW,在大规模训练场景下可提供近乎 2 倍的计算效率,并在多项任务上超越同等规模的主流模型。
- 代码 :https://github.com/MoonshotAI/Moonlight
- 全系列模型:https://huggingface.co/moonshotai
- 技术报告 Paper:https://github.com/MoonshotAI/Moonlight/blob/master/Moonlight.pdf
二、论文的主要内容
论文标题为 “Muon is Scalable for LLM Training”,作者来自 Moonshot AI、UCLA 等多家机构。主要内容可概括为以下几个方面:
1. Muon 优化器背景与原理
(1)动机
在当今 LLM 训练中,AdamW(Loshchilov et al. 2019)是最常用的优化器。然而,AdamW 在某些方面可能并非最优,比如其对不同方向的更新会动态调整,无法保证对矩阵范数的良好约束。
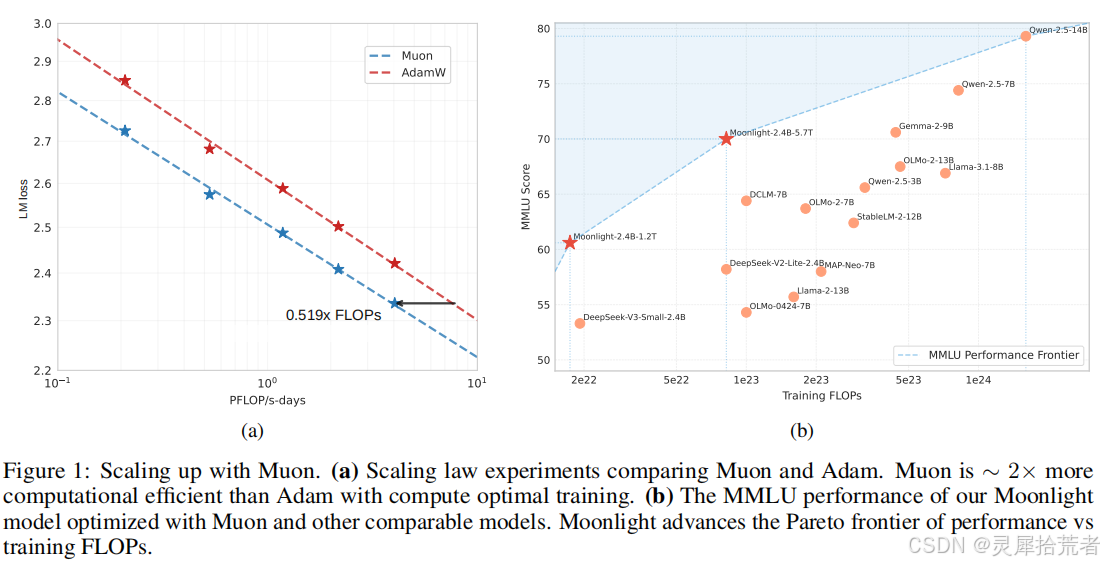
- 图1(论文 Figure 1a):作者通过 Scaling Law(Kaplan et al. 2020;Hoffmann et al. 2022)对比了 Muon 与 Adam 的性能,发现 Muon 在计算最优(Compute-Optimal)训练下只需大约 52% 的 FLOPs 即可达到与 AdamW 相当的性能。
- 图1(论文 Figure 1b):展示了作者提出的 “Moonlight” 模型在 MMLU 等基准上的表现,与同规模或更大规模的模型相比,Moonlight 进一步推动了训练 FLOPs 与模型性能的折中前沿。
(2)基本原理:矩阵正交化
Muon(K. Jordan et al. 2024)针对可用矩阵表示的网络权重,在梯度动量(Momentum)上采用近似正交化(Orthogonalization),即通过 Newton-Schulz 迭代来求解 (M M^T)^{-1/2}M,从而保证梯度更新在光谱范数(Spectral Norm)上具有更合理的约束。
- Newton-Schulz 迭代:在计算 (M M^T)^{-1/2}M 时,为了避免完整 SVD 带来的昂贵计算,作者采用了基于多步迭代的近似方法,每一步均在 bf16 精度下进行,并可通过硬件并行加速。
- 谱范数约束:作者指出,与 Adam 不同,Muon 的思路类似“在一个更合理的矩阵范数空间中进行最速下降(Steepest Descent)”,使得网络权重不会过度集中在少数方向上,有利于更好的收敛与泛化。
2. Muon 在大规模训练中的改进
论文强调,在小规模模型(如几千万到上亿参数)上,Muon 已展现优于 AdamW 的初步效果,但要真正扩展到数十亿、上百亿规模(甚至万亿级)模型,需要解决以下问题:
(1) 权值衰减(Weight Decay):

- 图2(论文 Figure 2):对比了引入权值衰减与否时的验证集 Loss 曲线。可见不加权值衰减的 Muon 在初期收敛更快,但后期可能出现权值过大、精度受限等问题。
- 最终作者将 Muon 与 AdamW 中的 Weight Decay 机制结合,得到类似 AdamW 中的 “λW” 更新项,从而在大规模训练中保持更稳定的 RMS。
(2) 更新尺度一致性:
- 传统 AdamW 的更新 RMS 在 0.2~0.4 范围较为稳定,但 Muon 的更新尺度依赖于参数矩阵的大小sqrt{1/max(A,B)}。
- 为此,作者提出为每个矩阵参数乘以 sqrt{\max(A,B)} 以抵消此效应,并通过在全局上将更新控制在与 AdamW 相近的 RMS 范围内(如 0.2),保证训练稳定性。
(3) 分布式实现(Distributed Muon):

- 算法 1(论文 Algorithm 1):基于 ZeRO-1(Rajbhandari et al. 2020)和 Megatron-LM(Shoeybi et al. 2020)的思路,对 Muon 的动量和梯度进行分块存储与通信。
- 与普通的分布式 AdamW 不同,Muon 需要先 gather 到完整矩阵以执行正交化,再 scatter 回本地分块,这带来了额外通信;但论文指出其通信量约为 AdamW 的 1.5 倍,而计算部分仅增加 1%~3% 的开销,整体可接受。
3. 实验结果与分析
论文在多个层面进行了验证,包括小规模的消融实验、大规模预训练、SFT(监督微调)以及对比更多模型:
(1)小规模消融与一致性测试
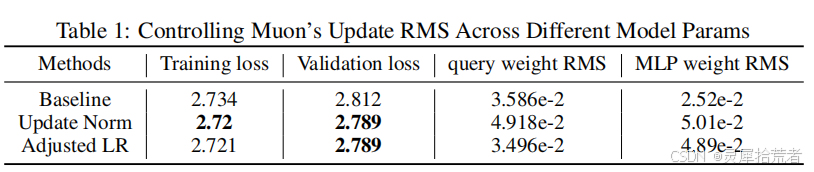
- 表1(论文 Table 1):展示了在 800M 参数模型上,三种更新尺度策略(Baseline、Update Norm、Adjusted LR)的对比,结果表明当更新尺度与参数形状相匹配时,能获得更佳的训练效果。
(2)Scaling Law 研究

- 图3(论文 Figure 3):在一系列 399M~1.5B 参数的模型上进行多种计算预算(FLOPs)下的训练,结果表明 Muon 在满足 compute-optimal 时只需约 52% 的 FLOPs 就能达到与 AdamW 相当的验证损失。
(3)大规模预训练:Moonlight 模型
-
作者在 Deepseek-v3-small(DeepSeek-AI et al. 2024)的基础上,构建了一个 2.24B 激活参数 / 15.29B 总参数(MoE)模型,经过 5.7T tokens 的训练,命名为 Moonlight。

-
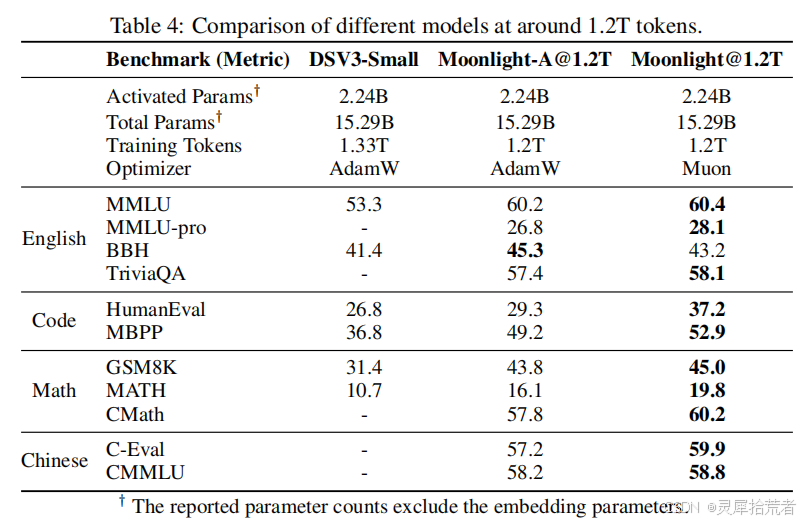
表4、表5(论文 Table 4、Table 5):对比了 Moonlight 与 Deepseek-v3-Small、LLAMA3-3B、Qwen2.5-3B 等多种同规模或更大规模模型。
- Moonlight 在 MMLU、BBH、TriviaQA、HumanEval、MBPP 等多项任务上都表现优异;
- 在数学推理(GSM8K、MATH)和中文理解(C-Eval、CMMLU)上也取得了可观提升;
- 与 Qwen2.5-3B、LLAMA3-3B 等大规模训练(9T~18T tokens)模型相比,Moonlight 仅用 5.7T tokens 就在多个基准上表现相当或更优,提升了性能-FLOPs的折中前沿。
-
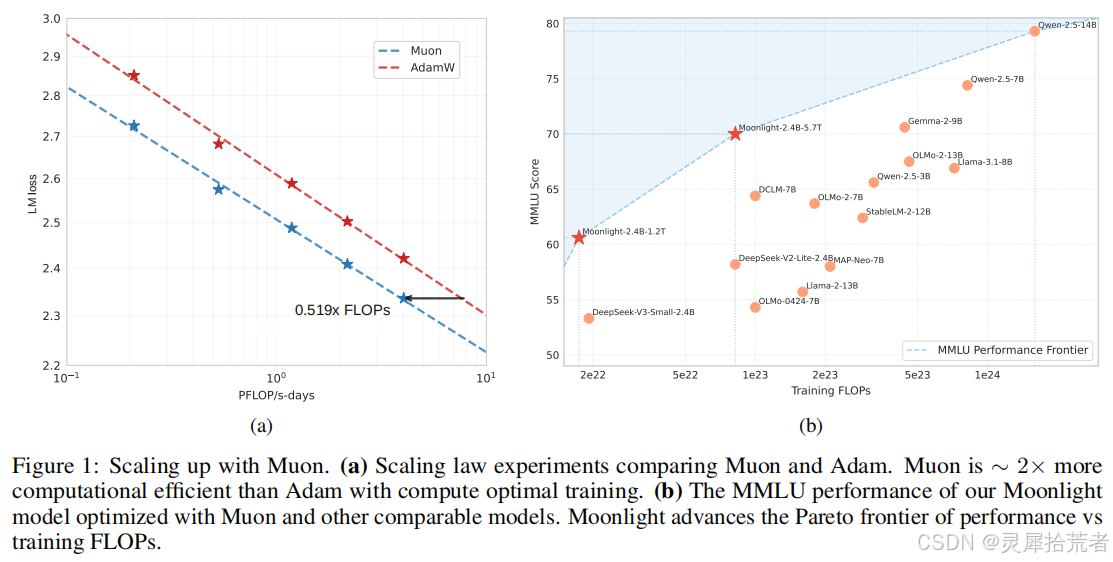
图1(论文 Figure 1b) 直观地呈现了 Moonlight 在 MMLU 上与其他模型的对比,确认了其在“训练预算 vs. 性能”曲线上的领先地位。
(4)监督微调(SFT)阶段
作者进一步在微调阶段测试了 Muon 与 AdamW 的混合使用。结果表明,如果预训练时使用 Muon,再使用 Muon 进行 SFT 能保持优势;但若预训练与微调的优化器不同,优势会部分消失,暗示还需后续研究如何让“不同阶段的优化器切换”更平滑。
4. 奇异值谱(Singular Spectrum)与可解释性
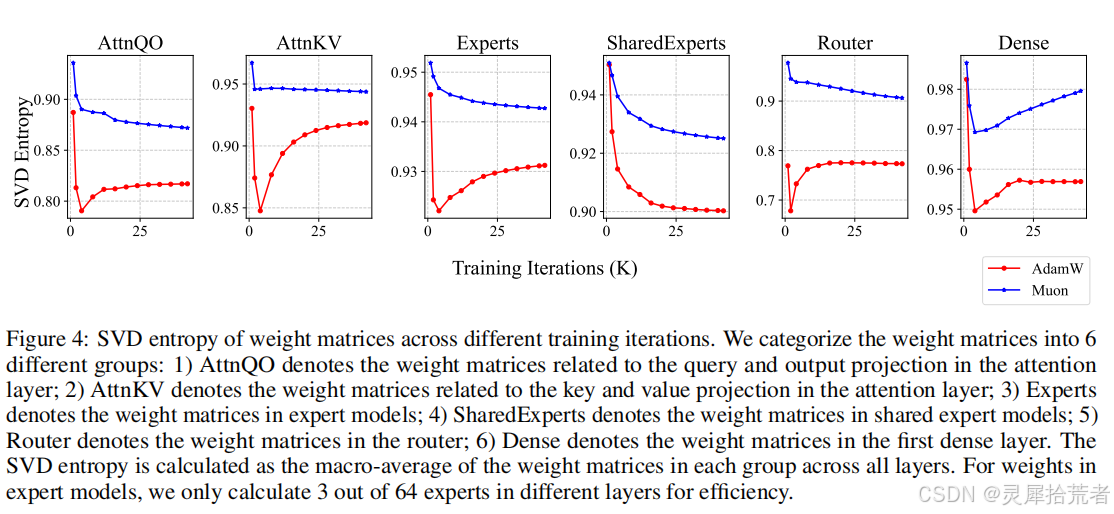
- 图4(论文 Figure 4):作者对比了 AdamW 与 Muon 在不同训练迭代下的 SVD Entropy。Muon 的权重矩阵奇异值分布更加分散(熵更高),说明 Muon 能在更丰富的方向上进行更新,从而获得更好的表达能力。
- 论文附录还可视化了每个权重矩阵的奇异值分布,进一步证明了 Muon 在大多数矩阵上都能带来更“平坦”的谱分布。
三、创新点
结合论文各章节与实验,我们可总结出 Muon 在大规模 LLM 训练中的主要创新点如下:
-
矩阵正交化(Orthogonalization)策略
不同于常见的 AdamW,Muon 通过近似(M M^T)^{-1/2} 来对梯度进行正交化,保证在光谱范数层面更合理的约束。其Newton-Schulz 迭代实现方法具有通用性。 -
可扩展到数十亿乃至万亿规模
作者通过在分布式训练中结合 ZeRO-1、Megatron-LM,将 Muon 的全矩阵更新拆分为“gather + 正交化 + scatter”,通信量虽增至 AdamW 的 1.5 倍,但实际计算/通信开销在大模型中只占 1%~3%,可接受。 -
权值衰减 + 动态更新尺度
- 加入 Weight Decay 以防止模型权值在大规模训练时无限增大;
- 对各参数矩阵根据形状自适应地进行更新缩放,使其与 AdamW 的更新 RMS 相匹配,从而“开箱即用”地复用 AdamW 的学习率与超参数。
-
Scaling Law 证明
论文以多组模型与不同训练预算(FLOPs)进行实验,定量表明 Muon 相较于 AdamW 在 compute-optimal 训练下可节省约 48% 的训练成本(FLOPs)。 -
Moonlight 模型:实验验证
- 训练了一个 3B/16B 的 MoE 模型 Moonlight,累积 5.7T tokens,并在 MMLU、GSM8K、HumanEval 等众多基准上超越同规模乃至更大规模的模型。
- 在奇异值谱分析、SVD 熵等方面给出了充分的可解释性证据。
四、代码实践
1.Moonlight-16B-A3B
1.1 完整代码
这段代码的目的是使用指定的语言模型(Moonlight-16B-A3B)基于提供的提示(“1+1=2, 1+2=”)生成后续文本。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "moonshotai/Moonlight-16B-A3B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
force_download=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
prompt = "1+1=2, 1+2="
inputs = tokenizer(prompt, return_tensors="pt", padding=True, truncation=True).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=100)
response = tokenizer.batch_decode(generated_ids)[0]
print(response)
1.2 代码详解
(1) 导入所需库:
from transformers import AutoModelForCausalLM, AutoTokenizer
这行导入了 Hugging Face transformers 库中的 AutoModelForCausalLM 和 AutoTokenizer 类。AutoModelForCausalLM 用于加载语言模型,AutoTokenizer 用于加载与模型匹配的分词器。
(2) 加载模型:
model_name = "moonshotai/Moonlight-16B-A3B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
force_download=True
)
model_name设置了模型的名称。AutoModelForCausalLM.from_pretrained()函数从 Hugging Face Hub 加载指定的模型。torch_dtype="auto"让模型自动选择适当的张量类型。device_map="auto"自动选择设备,如CPU或GPU。trust_remote_code=True允许加载远程模型代码(通常是为了加载自定义或特定格式的模型)。force_download=True强制重新下载模型,而不使用缓存。
(3) 加载分词器:
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
这里加载了与模型匹配的分词器。分词器的作用是将文本转换为模型可以理解的输入格式,并在模型生成文本后将其转换回可读的文本。
(4) 准备输入数据:
prompt = "1+1=2, 1+2="
inputs = tokenizer(prompt, return_tensors="pt", padding=True, truncation=True).to(model.device)
prompt设置了一个简单的数学表达式作为输入。tokenizer()将输入文本转换为模型所需的张量格式,使用return_tensors="pt"以 PyTorch 张量形式返回,padding=True自动填充文本至固定长度,truncation=True如果输入超长则进行截断。.to(model.device)将数据移动到与模型相同的设备(GPU或CPU)。
(5) 生成文本:
generated_ids = model.generate(**inputs, max_new_tokens=100)
model.generate()调用模型进行文本生成。**inputs将输入的词汇和其他设置传递给generate函数。max_new_tokens=100设置了生成的最大长度为 100 个新的 token。
(6) 解码生成结果并输出:
response = tokenizer.batch_decode(generated_ids)[0]
print(response)
tokenizer.batch_decode()将生成的 token IDs 转换为人类可读的文本。generated_ids是生成的 token ID,batch_decode()处理批量解码,[0]获取第一条生成的文本(如果生成了多条)。- 最后,打印出生成的文本
response。
2. Moonlight-16B-A3B-Instruct
2.1 完整代码
这段代码实现了与一个经过调优的语言模型(Moonlight-16B-A3B-Instruct)进行对话。用户提出问题“Is 123 a prime?”,模型根据对话上下文生成一个回答。模型处理输入时考虑了对话历史,并生成合理的回复。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "moonshotai/Moonlight-16B-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
messages = [
{"role": "system", "content": "You are a helpful assistant provided by Moonshot-AI."},
{"role": "user", "content": "Is 123 a prime?"}
]
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
generated_ids = model.generate(inputs=input_ids, max_new_tokens=500)
response = tokenizer.batch_decode(generated_ids)[0]
print(response)
2.2 代码详解
(1) 导入所需库
from transformers import AutoModelForCausalLM, AutoTokenizer
这行代码导入了 Hugging Face transformers 库中的两个重要类:
AutoModelForCausalLM: 用于加载一个因果语言模型(Causal Language Model)。AutoTokenizer: 用于加载与模型匹配的分词器。
(2) 加载模型
model_name = "moonshotai/Moonlight-16B-A3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
model_name指定了要加载的模型(Moonlight-16B-A3B-Instruct),这可能是一个经过指令调优(Instruction-tuned)的版本,优化了与用户交互的能力。AutoModelForCausalLM.from_pretrained()用于加载预训练模型。torch_dtype="auto": 自动选择合适的张量数据类型。device_map="auto": 自动选择设备(CPU 或 GPU),以确保模型加载到正确的硬件上。trust_remote_code=True允许从远程加载模型的代码,这对于一些自定义模型非常重要。
(3) 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
- 使用
AutoTokenizer.from_pretrained()来加载与模型相对应的分词器。这个分词器能够将文本转换为模型可以理解的格式,并在模型生成后将其转换回可读文本。 trust_remote_code=True允许加载远程代码。
(4) 准备对话消息
messages = [
{"role": "system", "content": "You are a helpful assistant provided by Moonshot-AI."},
{"role": "user", "content": "Is 123 a prime?"}
]
messages是一个对话历史的列表,包含role和content字段:"role"可以是"system"(系统消息),"user"(用户消息),或"assistant"(助手回复)。"content"是消息的实际文本内容。
这个输入表示了一个系统消息(说明助手的角色)和一个用户提问(是否 123 是质数)。
(5) 应用对话模板
input_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
tokenizer.apply_chat_template()用于将消息列表应用到特定的聊天模板,生成模型的输入格式。这样,模型能够识别对话上下文。add_generation_prompt=True会在输入中添加生成提示,帮助模型理解它的任务是生成对话中的一部分。return_tensors="pt"返回一个 PyTorch 张量。.to(model.device)将输入张量移动到与模型相同的设备(CPU 或 GPU)。
(6) 生成模型输出
generated_ids = model.generate(inputs=input_ids, max_new_tokens=500)
model.generate()调用模型进行文本生成。inputs=input_ids:将准备好的输入传递给模型。max_new_tokens=500:设置生成的最大 token 数为 500。这表示模型最多生成 500 个新的 token。
(7) 解码生成的输出
response = tokenizer.batch_decode(generated_ids)[0]
print(response)
tokenizer.batch_decode(generated_ids)将生成的 token ID 转换为人类可读的文本。generated_ids是生成的 token ID,batch_decode()会处理批量解码(即使生成了多个结果),[0]获取第一个生成的文本(如果有多个)。print(response)打印模型生成的回答。
五、总结与思考
1. 学术价值
Muon 作为一种“谱范数”约束下的优化器,为大规模 LLM 训练提供了与 AdamW 不同的思路。它从矩阵正交化出发,通过 Newton-Schulz 迭代来近似实现对梯度矩阵的正交化操作,避免网络在少数特征方向上过度拟合。结合 Weight Decay、更新尺度匹配、分布式实现等改进,论文在大规模场景下证明了 Muon 对 AdamW 的替代潜力。
Moonlight 模型的实验显示,Muon 在训练效率与最终性能之间取得了优良平衡,对小目标场景与多任务能力都有明显提升。奇异值谱与注意力可视化分析也验证了“多方向优化”这一理论推断,为后续研究提供了宝贵参考。
2. 工程应用
- 大模型预训练:当训练规模达到数十亿到千亿参数时,Muon 提供了一个比 AdamW 更高效的选择,能在相同计算预算下取得更佳性能或在相同性能下节省约一半的 FLOPs。
- 混合专家(MoE)场景:论文强调了 Muon 在 MoE 中的优势,特别是对路由器(Router)与专家权重的正交化更新,有助于专家分工更清晰、减少冲突。
- 分布式部署:Distributed Muon 的实现思路与 ZeRO-1、Megatron-LM 高度兼容,开发者可在大规模集群上替换 AdamW 为 Muon,而无需大改训练管线。
需要注意的方面包括:
- SFT 与预训练优化器切换:若预训练使用 Muon,再在微调时切换 AdamW 或反之,可能导致性能衰减,需要更深入的理论与实践研究。
- 通信量:与 AdamW 相比多了约 50% 的分布式通信,需要确保集群带宽充足。
3. 未来方向
论文最后提出了一些可能的后续工作:
- 扩展至其他 Schatten 范数:Muon 针对的是光谱范数(Schatten-∞),若将其拓展至一般的 Schatten-p 范数,或许能衍生更多优化器形式。
- 全面替代 AdamW:当前 Muon 主要用于矩阵参数,对非矩阵(如 LN、Embedding)的部分仍需依赖 AdamW;后续如何统一到 Muon 框架是一大课题。
- 适应预训练-微调优化器不一致问题:若社区已有大量 AdamW 预训练的权重,如何在微调时使用 Muon 仍需理论与实践层面的探索。
- 自适应迭代次数:Newton-Schulz 迭代固定为 5~10 步,是否可根据梯度大小、训练阶段自适应调整以进一步降低开销?
【作者声明】
本文基于技术报告 “Muon is Scalable for LLM Training”(Moonlight.pdf)以及作者公开的相关代码与实验结果撰写。文中引用的图示(如“图1”“图2”“图3”“图4”)对应论文原文示意,仅用于学术研究与技术交流之目的。本文内容为专业审稿人视角的分析与整理,不代表任何机构立场,如需引用请注明来源。
【关注我们】
如果您对机器学习、群智能算法及人工智能技术感兴趣,请关注我们的公众号,获取更多前沿技术文章、实战案例及技术分享!欢迎点赞、收藏并转发,与更多朋友一起探讨与交流!我们将定期更新最新的研究动态和技术分享,助力各位科研人员了解并应用最新的技术。
获取完整指南:关注公众号,回复【Muon】获取相关PDF资源和代码。