在介绍该知识点之前,我们首先介绍一下关于 PostgreSQL 的参数 shared_buffers 和 effective_cache_size。
shared_buffers (integer)
Sets the amount of memory the database server uses for shared memory buffers. The default is typically 128 megabytes (128MB), but might be less if your kernel settings will not support it (as determined during initdb). This setting must be at least 128 kilobytes. However, settings significantly higher than the minimum are usually needed for good performance. If this value is specified without units, it is taken as blocks, that is BLCKSZ bytes, typically 8kB. (Non-default values of BLCKSZ change the minimum value.) This parameter can only be set at server start.
If you have a dedicated database server with 1GB or more of RAM, a reasonable starting value for shared_buffers is 25% of the memory in your system. There are some workloads where even larger settings for shared_buffers are effective, but because PostgreSQL also relies on the operating system cache, it is unlikely that an allocation of more than 40% of RAM to shared_buffers will work better than a smaller amount. Larger settings for shared_buffers usually require a corresponding increase in max_wal_size, in order to spread out the process of writing large quantities of new or changed data over a longer period of time.
On systems with less than 1GB of RAM, a smaller percentage of RAM is appropriate, so as to leave adequate space for the operating system.
那么这一段介绍讲了啥呢?主要是介绍 shared_buffers 的默认值是 128MB,通常设置该值是服务器物理内存的 25%,超过 40% 的设置并不一定会带来比 40% 更好的性能。也就是说建议你设置为不超过总物理内存的 40%,但是并不是数这个参数不能设置为总物理内存的 75% 等值。在别的平台你可能会遇到不同的设置。
effective_cache_size (integer)
Sets the planner's assumption about the effective size of the disk cache that is available to a single query. This is factored into estimates of the cost of using an index; a higher value makes it more likely index scans will be used, a lower value makes it more likely sequential scans will be used. When setting this parameter you should consider both PostgreSQL's shared buffers and the portion of the kernel's disk cache that will be used for PostgreSQL data files, though some data might exist in both places. Also, take into account the expected number of concurrent queries on different tables, since they will have to share the available space. This parameter has no effect on the size of shared memory allocated by PostgreSQL, nor does it reserve kernel disk cache; it is used only for estimation purposes. The system also does not assume data remains in the disk cache between queries. If this value is specified without units, it is taken as blocks, that is BLCKSZ bytes, typically 8kB. The default is 4 gigabytes (4GB). (If BLCKSZ is not 8kB, the default value scales proportionally to it.)
这一段又说了啥呢?该参数主要是针对单个 SQL 的磁盘缓存,他并不影响你对 shared_buffers 的分配,该参数的默认值是 4GB,一个更大的值有利于查询的时候使用索引扫描。
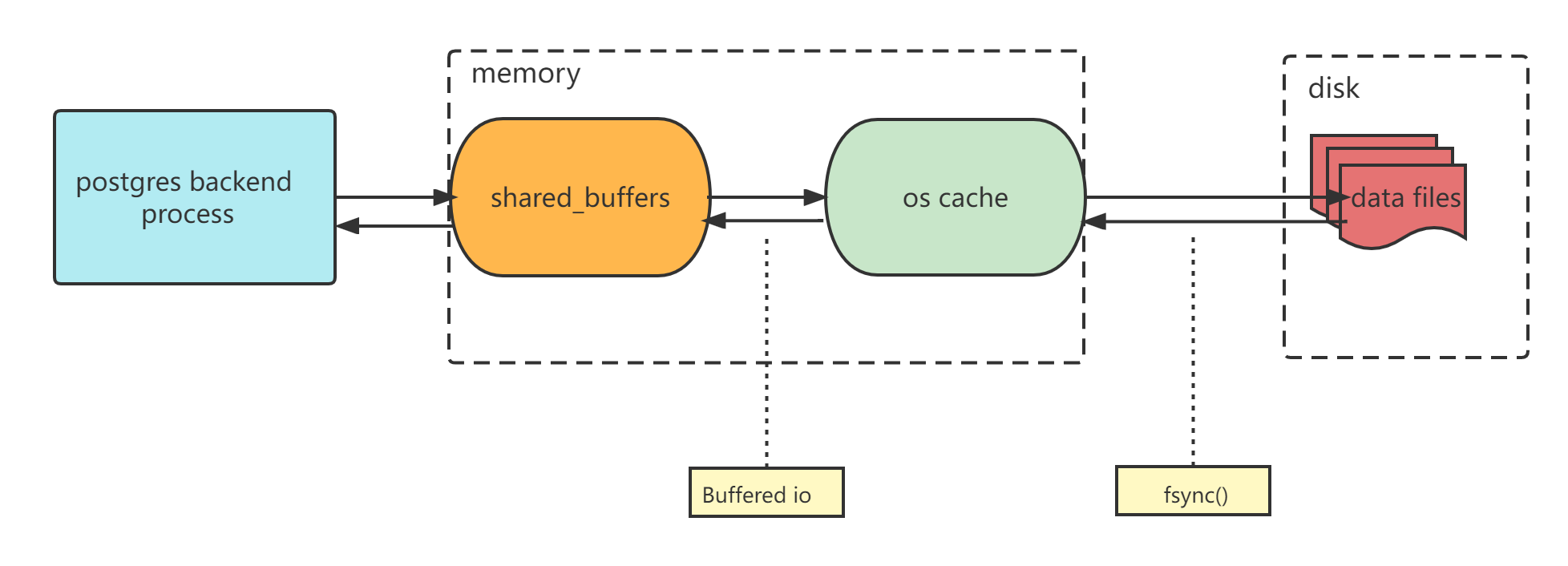
PostgreSQL 采用数据库实例的 shared_buffers 和操作系统双缓存的工作模式,PostgreSQL 数据库必须高度依赖操作系统缓存,它依赖于操作系统来了解文件系统、磁盘布局以及如何读写数据文件。缓存作为数据库的一个核心组件,shared_buffers 决定了数据库实例层面的可用内存,而系统中预计有多少缓存是 OS cache 决定的。而且 OS cache 不仅是缓存经常访问的数据,它同时帮助优化器确定实际存在多少缓存,指导优化器生成最佳执行计划。而 MYSQL 把大部分系统内存给到了数据库缓存,倾向于不使用 OS cache,支持使用 direct IO,在应用层 Buffer 和磁盘之间直接建立通道,绕过操作系统缓存。这样在读写数据的时候就能够减少上下文切换次数,同时也能够减少数据拷贝次数,从而提高效率。而原生 PostgreSQL 是不支持 direct IO 的,这一点和 MySQL 还是有着比较本质上的差异的。
当我们在数据库里写入数据后,bgwriter 进程将脏缓冲区刷新到磁盘时,页面实际上是先刷新到 OS 缓存,然后再刷新到磁盘。而执行查询会先从 shared_buffers 里查找,一旦在 shared_buffers 里命中了数据页,就永远不会再到操作系统缓存里进行查找。但如果在 shared_buffers 里没命中,则会继续从 OS cache 里找寻,如果在 OS cache 里命中了,则把数据加载到 shared_buffers 里去。如果在 shared_buffers 和 OS cache 里都没有命中的话,则会把数据先加载到操作系统缓存 OS cache,然后再加载到 shared buffers。这种双缓存的工作模式意味着 OS cache 和 shared_buffers 可以保存相同的页面。有一定的可能可能会导致空间浪费,但 OS 缓存使用的是 LRU 算法,而不是 shared_buffers 的时钟扫描算法 clock sweep algorithm,他们二者是采用不同的算法实现数据的交换。一旦在 shared_buffers 里命中了数据页,就永远不会到操作系统缓存里进行查找,因此在 shared_buffers 里长期使用到的部分,在 OS cache 里实际上会很容易就被清理掉了。
shared_buffers 过小、OS cache 较大会发生什么?
当我们给 shared_buffers 过小而 OS cache 较大的时候,虽然数据会集中在 OS cache 里,但实际的数据库的操作都是在共享缓冲区里执行的,所以做一些复杂查询的时候,性能是很差的。除此之外,shared_buffers 采用的时钟扫描算法 clock sweep algorithm 算法为每个最近被使用的页面增加了权重,使用越频繁越不容易被替换出去,比 OS cache 的 LRU 算法更加符合真实的场景,shared_buffers 里其实比 OS cache 更加容易缓存到常用的数据。
shared_buffers 过大、OS cache 较小会发生什么?
而当我们给 OS cache 很小,但是 shared_buffers 很大的时候,shared_buffers 里一旦页被标记成了脏页,就会被刷新到 OS cache 里,如果 OS cache 过小的话,它就不能重新排序写操作以及优化 IO,可能导致大量的离散写,对于有大量繁重写入操作的数据库而言,这一点十分的不友好。此外 PostgreSQL 数据目录里 pg_clog 目录下存储了提交日志信息,是定期读取和写入的,因此OS cache 的大小还和 clog 的读写任务性能息息相关,通过 OS cache 会更直接。并且,shared_buffers 管理内存也需要代价,检查点、脏页判断的代价也会随着 shared_buffers 的增大而增大。
那么如何查看 shared_buffers 或 OS cache 里缓存数据量?
git clone git://git.postgresql.org/git/pgfincore.git
make
make install
[xmaster@mogdb-kernel-0005 pgfincore]$ psql
psql (14.14)
Type "help" for help.
postgres=# create extension pg_buffercache;
CREATE EXTENSION
postgres=# CREATE EXTENSION pgfincore;
CREATE EXTENSION查看换成的使用率的 SQL
select c.relname,
pg_size_pretty(count(*) * 8192) as pg_buffered,
round(100.0 * count(*) /
(select setting
from pg_settings
where name='shared_buffers')::integer,1) as pgbuffer_percent,
round(100.0*count(*)*8192 / pg_table_size(c.oid),1) as percent_of_relation,
( select round( sum(pages_mem) * 4 /1024,0 )
from pgfincore(c.relname::text) ) as os_cache_MB ,
round(100 * (
select sum(pages_mem)*4096
from pgfincore(c.relname::text) )/ pg_table_size(c.oid),1) as os_cache_percent_of_relation,
pg_size_pretty(pg_table_size(c.oid)) as rel_size
from pg_class c
inner join pg_buffercache b on b.relfilenode=c.relfilenode
inner join pg_database d on (b.reldatabase=d.oid and d.datname=current_database()
and c.relnamespace=(select oid from pg_namespace where nspname='public'))
group by c.oid,c.relname
order by 3 desc limit 30;那么 shared_buffers 到底存了什么数据进去呢?
数据页 data pages。表数据、索引数据
元数据页 metadata pages。系统表数据:如 pg_class、pg_attribute 等。统计信息:一些统计页面也可能会被缓存,以加速查询优化器的决策过程。
临时数据页 temporary data pages。临时表数据、排序和哈希操作。
WAL 缓冲区。WAL:虽然 wal 日志有专门的缓冲区 wal_buffers,但是某些情况下,wal 日志的部分数据也会暂时存在 shared_buffers 中,比如数据页的修改、延迟写刷写、事务提交等。
检查点数据 checkpoint data。checkpoint:在执行 checkpoint 时,脏页已修改但未写回磁盘的页会被写回磁盘。这些脏页在写回之前存储在 shared_buffers 中。
其他数据页。多版本并发控制 MVCC:pg 用 MVCC 管理事务,这涉及多个版本的数据页,这些页也会被缓存到 shared_buffers中。
什么时候加载 shared_buffers?
在访问数据的时候,如果数据没有存在在 shared_buffers 中,数据会先加载到 os 缓存,然后再加载到 shared_buffers 中。os 使用简单的 LRU,而数据库采用的优化时钟扫描,即缓存使用频率高的会被保存,低的被移除。这样可以基本上保证虽然使用双缓存,OS cache 和 shared_buffers 可以保存相同的页面,可能会导致空间浪费,但是两份一样的缓存一直在 shared buffers 和 os 缓存中概率不大,因为数据库优化的时钟扫描算法,一旦页面在 shared_buffers 上命中,读取就永远不会到达操作系统缓存。
说明:关于双 BUFFER 的一个理解其实这些理论并不能完全支撑整个知识体系,关于 OS cache 的刷盘其实还涉及到操作系统内核参数脏页刷新比。
说明:在上面介绍有哪些数据会被加载到 shared_buffers 中时,介绍到一个数据预热的问题,关于这个数据预热我在后面会有一篇文章介绍到这个插件以及其使用案例。