目录
1. 单例模式
单例模式, 是设计模式中最典型的一种模式, 是一种比较简单的模式, 同时也是面试中最容易被问到的模式.
什么是设计模式呢?
我们可以把设计模式模式理解为棋谱, 大佬们将棋局中技巧记录下来, 而我们只要根据棋谱来下棋, 结果就不会太差~
而设计模式就是我们程序的"棋谱", 大佬们把一些典型的问题整理出来, 并且告诉我们针对这些问题, 代码该如何写, 给出了一些指导和建议.
而我们程序员根据设计模式来写代码, 不管水平高低, 写出来的代码也都不会太差~
而单例模式, 就是设计模式的一种.
在单例模式中, 强制要求某个类, 在一个程序(进程)中, 只能有唯一一个实例(不允许创建多个实例, 不允许 new 多次).
举两个例子:
- 在学习 MySQL JDBC 时, 编写 JBBC 的第一步的就是要创建 DataSource, DataSource描述了数据库服务器的信息(URL, user, password). 由于数据库只有一份, 即使创建多个这样的对象也没有意义(即使创建了多个对象, 存的也都是一样的信息). 所以 DataSource 是非常适合于用作单例的.
- 还比如在实际开发中, 会通过类组织大量的数据, 而这个类的实例就可能管理几百G的内存数据, 而一个服务器的内存容量也可能就几百G, 所以从开销来说, 也必须只能有一个实例.
而单例模式, 就是强制要求某个类, 在程序中, 只能有一个实例.
而这样的规定, 并不是口头上的一个"君子协定", 而是通过程序 / 代码技巧 / 机器, 来强制要求只能用一个实例.(如果菜鸡程序员 new 了两个对象, 直接编译失败~)
单例模式式具体的实现方式有很多种(通过编程技巧). 最常见的是 "饿汉模式" 和 "懒汉模式" 两种
1.1 饿汉模式
饿汉模式, 是单例模式的一种.
顾名思义, "饿汉", 就是迫切的意思, 通过创建 static 修饰的实例作为成员, 使得实例在类加载时就被创建.
类加载在程序一启动时就被触发, 所以静态的成员的初始化也是在类加载的阶段完成的.
同时, 我们也要确保类的实例只能被创建一次, 所以可以通过构造方法私有化的形式完成, 这样一来, 在类外面进行 new 操作, 就会编译报错.
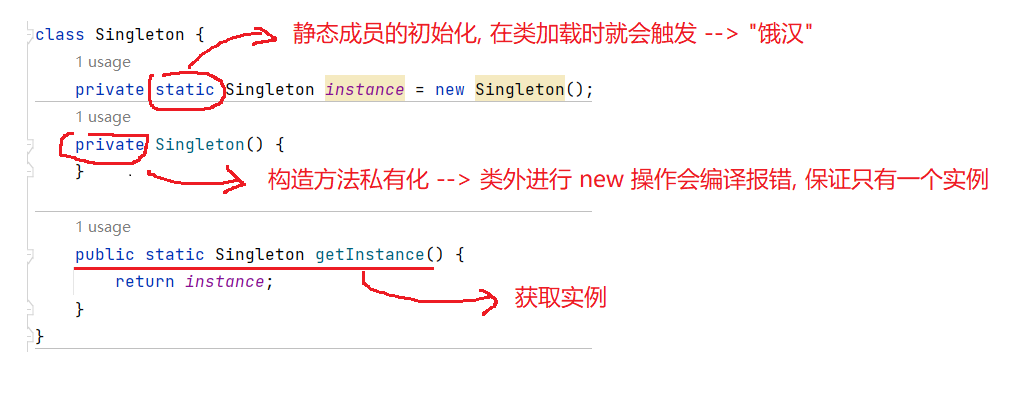
/**
* 饿汉模式
*/
class Singleton {
//在类加载时就对实例进行初始化
private static Singleton instance = new Singleton();
//构造方法私有化 -> 防止类外的 new 操作
private Singleton() {}
//获取实例
public static Singleton getInstance() {
return instance;
}
}1.2 懒汉模式
懒汉模式, 也是单例模式的一种.
"懒"和"饿"是相对的一组概念. "饿", 是尽早创建实例; 而"懒", 是尽量晚的去创建实例(延迟创建, 甚至不创建).
在实际生活中, "懒"意味着拖拖拉拉, 不勤快, 不靠谱~
但是在计算机中, "懒"是一个 褒义词~~
举个例子:
当我们打开一个很大的文件时(千万字的小说), 编辑器可以有两个选择:
- 加载所有内容到内存中后, 再显示到你的屏幕.
- 只加载一部分内容, 随着用户翻页而再加载其他内容.
很明显, 计算机肯定会选择第二个方式来加载数据, 如果采用第一个方式肯定会占用大量内存空间, 造成设备卡顿.
所以, 在懒汉模式下, 这一个实例创建的时机, 是在我们第一次使用的时候的才创建, 而不是程序刚开始启动的时候.

/**
* 懒汉模式
*/
class SingletonLazy {
private static SingletonLazy instance = null;
private SingletonLazy() {}
public static SingletonLazy getInstance() {
if(instance == null) {
instance = new SingletonLazy();
}
return instance;
}
}饿汉 / 懒汉 的模式是存在缺陷的, 比如可以通过 反射 来创建类的实例.
但是, 反射本就是一个"非常规"的编程手段, 所以在开发中, 也不推荐使用反射.
2. 懒汉模式下的问题
2.1 线程安全问题
在上文, 我们分别编写了 饿汉 / 懒汉 单例模式的代码, 那这两份代码是否是线程安全的呢???
换句话说, 两个版本的getInstance方法, 在多线程环境下调用, 是否会出现 bug 呢???
- 在饿汉模式下, 由于实例在类加载时就被创建好了, getInstance方法只是返回实例, 并非涉及修改, 所以必然是线程安全的~
- 而再懒汉模式下, getInstance方法出现了赋值 " = " 操作, 故涉及到了数据的修改, 故可能存在线程安全问题.
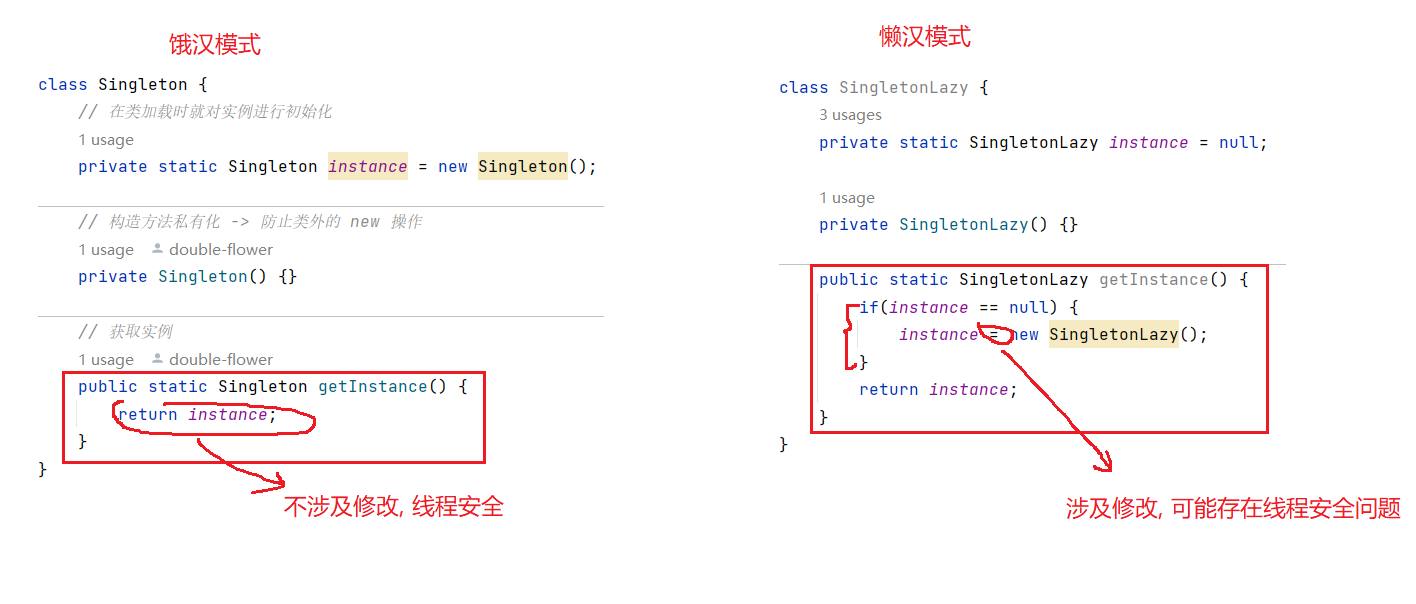
到这里, 相信大家心里有了疑问 : "虽然 = 是修改操作, 但是它是原子的啊 , 不是说原子的操作是线程安全的吗???"
是的, 没错, = 虽然是原子的, 但是 = 和其上面的 if 搭配起来, 就并非原子的了~ 再加上操作系统的随机调度, 可能就会导致线程安全问题.
我们来看以下两个线程这样的调度情况:

调度过程如下 :
- t1 先进入 if , 此时还没有进行 new 操作,
- t1 被调度走, t2 被调度来,
- t2 仍然满足 if 的条件判断,
- t1 再调度来, 进行 new 操作, 返回实例
- t1 被调度走, t2 调度来,
- t2 进行 new 操作, 返回实例
虽然, 随着 t2 的 new 操作返回, t1 new 的对象覆盖, 也会被 GC 回收, 但是, 在 new 的过程中, 可能要把大量的数据从硬盘加载到内存中, 这将是双倍的开销, 将大幅度拉低程序性能.
2.2 如何解决 --- 加锁
对于线程安全问题, 加锁是一个常规手段~~
我们上文说到, 虽然 = 是原子的, 但是 = 和 if 组合起来就并非原子的了, 那我们就可以使用 synchronized 将这些操作打包成原子的.

注意: 一定要把赋值操作和 if 一起打包放在 synchronized 中, 不能只放赋值操作. 我们希望的是将 条件和修改 一起打包成原子操作.
加上锁后, 后执行的线程就会在加锁的位置阻塞, 直到前一个线程 new 操作后才解除阻塞状态, 而此时的 instance 不再为 null , 后执行的线程也就不能进入 if 中, 不会再进行 new 操作.
我们同样也可以通过给方法加锁的方式来解决(相当于给类对象 SingletonLazy.class 加锁):
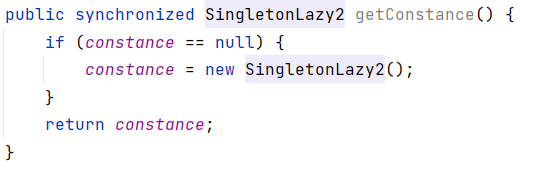
综上, 通过将 条件和修改 加锁打包成原子, 解决了线程安全问题.
2.3 加锁引入的新问题 --- 性能问题
将 条件和修改 通过加锁打包成原子后, 解决了线程安全问题, 但是又引入了一个新问题 : 性能问题.
我们上文所说的线程安全问题, 是在 instance 还没有创建的情况下.
但是当实例已经被创建好后, getInstance方法的作用就只是单独的读操作(只需返回实例即可), 而读操作, 不涉及线程安全问题.
但是, 我们加上锁后, 每次的读操作都会进行加锁操作, 在多线程下意味着线程间会发生阻塞等待, 从而影响程序的执行效率.
有句古话说得好, "温饱思淫欲" , 现在程序已经解决了线程安全问题(温饱问题解决了), 但是现在我们想要他跑的更快, 效率更高(思淫欲)~~
那么该如何做呢?
--- 按需加锁, 当涉及到线程安全问题的时候, 就加锁; 当不涉及线程安全问题的时候, 就不用加锁.
锁的外面再加上一个 if 判断即可:

在以往的单线程环境下, 连续的两个相同的 if 是没有意义的.
但是在多线程环境下, 程序中有多个执行流, 很可能在两个 if 间, 就有其他线程把值给修改了, 从而导致两次的 if 结果不同.
并且若中间有锁, 一旦阻塞, 阻塞的时间间隔, 对于计算机来说就是"沧海桑田". 这中间变量的变化, 都是不得而知的, 所以要再加一次 if 的条件判断.
这里的代码上的两个 if , 作用也是完全不一样的:
- 最外层的 if 是判断是否需要加锁
- 里面的 if 是判断是否需要 new 对象

2.4 指令重排序问题
到目前为止, 通过对上述代码的改进, 已经解决了线程安全问题和性能问题.
但是, 上述代码仍旧存在由 指令重排序 而引起的问题~
2.4.1 指令重排序
指令重排序和之前提到的内存可见性问题一样, 都是编译器优化的体现形式.
指令重排序: 编译器会在原有代码逻辑不变的情况下, 对代码的执行的先后顺序进行调整, 以达到提升性能的效果.
举个例子:
放假后在家, 你妈给了你一个清单, 叫你去超市买清单上的蔬菜, 清单上的蔬菜如下:
- 西红柿
- 土豆
- 茄子
- 白菜
到了超市后, 你会严格的按照清单上的顺序去买菜吗?
并不是, 你会根据菜和你的位置, 来决定先买哪个后买哪个, 以至可以走"最小路径".
所以, 编译器也是一样, 在逻辑不变的大前提下, 会调整代码的执行顺序来提高性能.
但是在多线程的环境下, 编译器的调整就可能出现错误, 导致指令重排序问题的发生.
2.4.2 指令重排序引发的问题
比如, 在上述代码中对 instance 的 new 操作(即创建实例的过程), 分为以下三步:
- 申请内存空间
- 在空间上构造对象(完成初始化)
- 将内存空间的首地址, 赋值给引用变量
正常来说, 这三步是按照 1 2 3 的步骤执行的, 但是经过指令重排序, 可能成为 1 3 2 这样的顺序.
在单线程的环境下, 这两个顺序都无所谓, 最后得到的都是一个囫囵个的完整的对象.
但是在多线程下, 就会出现问题了 :

如上图所示, 若经过指令重排序, 创建实例的过程被修改为 1 3 2. 一个线程在进行 new 时, 只进行了 1 3 步骤(还没有对实例进行初始化), 此时该线程被切走, 另一个线程执行时, 发现 instance 不为空, 直接返回了对象, 但是这个对象却还没有初始化, 那么后续使用这个对象就会出 bug 了~~
对于指令重排序问题, 依然需要用到 volatile 关键字, 我们可以使用 volatile 关键字来修饰 instance 来避免指令重排序带来的问题.
所以, volatile 关键字的功能有两点:
- 确保每次的读取操作, 都是从内存读取
- 被 volatile 修饰的变量, 关于该变量读取和修改操作, 不会触发重排序.
并且, 编译器优化这个事情, 是非常复杂的, 所以我们也不能确保内存可见性问题是否存在, 所以为了稳妥起见, 从根本上杜绝内存可见性问题, 我们也可以给 instance 加上 volatile.
综上, volatile 禁止了指令重排序, 保证了内存可见性.
END