基础知识
什么是索引
索引也是一个数据库对象,如果将数据库比喻成一本书,那么索引就相当于一本书的一个目录。其作用是帮助数据库更快的查询,合格的使用索引可以大大地减低i/o次数,从而提高数据访问性能
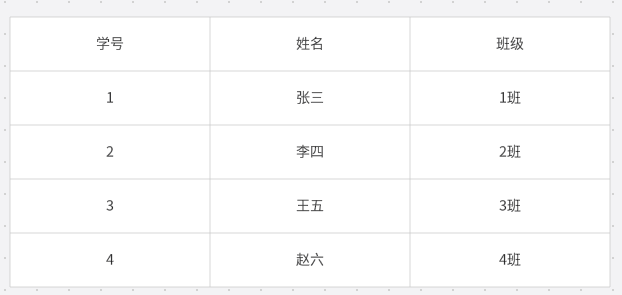
普通查询,当我们使用select语句查询的时候,数据库将会对表的数据进行一次遍历,直到查询到自己想要的一个数据,才会进行将目标数据进行返回,如我们要找到姓名为赵六的行,数据库将会将张三、李四、王五和赵六的数据都读一遍,知道找到赵六才会进行停止
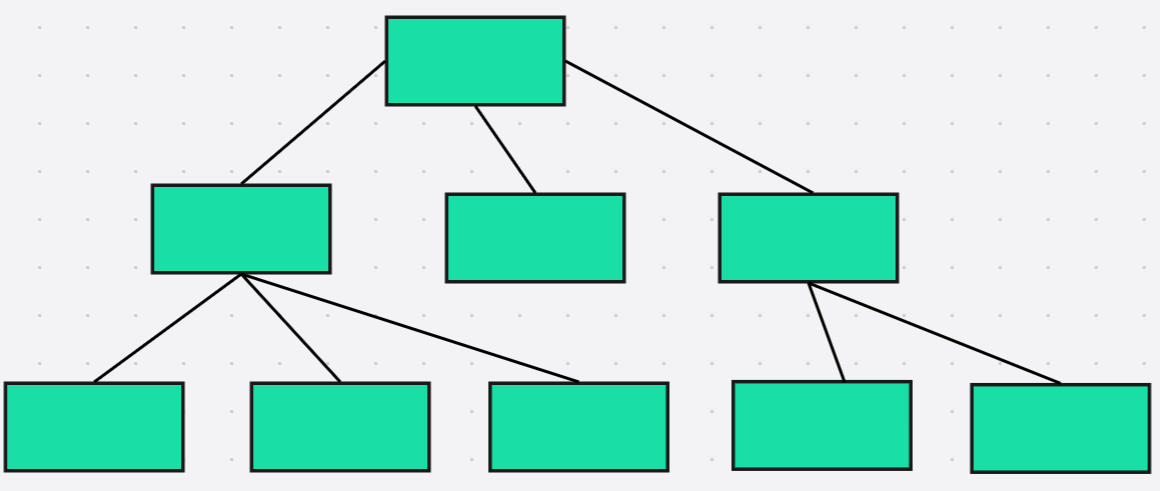
当我们建立一个索引后,数据库就不会遍历了,而是通过索引来快速定位到物理地址,如按名字进行索引,则会将这些数据整理成一个数据结构,这个数据结构像一个树(B-tree)一样,然后通过这棵树快速的找到这个符合条件的物理地址,这个物理地址就是我们所说的oid
并且索引是根据查询来建立的,在表中是基于列来建立的,而最好建立在我们经常根据那个列进行查询的列;例如,我们在查询数据时,就进场根据姓名这一列来进行查询,所以我们一般都将索引建立在姓名这一列上
索引的作用
综上所述,索引的使用场景是数据量较大,为了加快查询速度时使用的。并且索引就是像一颗树;如下图,树的每一个节点对应的就是对着存表的物理地址,并且索引是基于列来建立的,如将名字进行索引,则会将名字中相同的值都整理到一块,打上一个uid
同时,在索引节省时间的同时,它还占用了我们的磁盘空间,即时间换空间,空间换时间
而这个树就是我们在索引中最常使用的B-tree,KES默认创建的索引类型就是B-tree
创建索引
语法:
CREATE index 索引名 ON 表名(列名);
注:KES V8R6仅B-树索引支持使用UNIQUE、ASC、DESC(降序)、NULLS FIRST、NULLS LAST
KES支持使用WHERE来创建部分索引
修改索引
使用ALTER INDEX命令可以修改索引名、索引所存储的表空间、索引的存储参数等
语法:
ALTER INDEX [ IF EXISTS ] name RENAME TO new_name;
ALTER INDEX [ IF EXISTS ] name SET TABLESPACE tablespace_name;
ALTER INDEX name ATTCH PARTITON index_name;
ALTER INDEX name DEPENDS ON EXTENSION extension_name;
| 参数 | 简介 |
|---|---|
| RENAME TO | 用于修改索引名,前面是旧索引名,后面是新索引名 |
| SET TABLESPACE | 要修改索引存储的表空间时,该参数后面带上有效的表空间名称 |
| SET | 用于修改索引的存储参数 |
| ATTCH PARTITION | 用于将一个分区加到索引上 |
| DEPENDS ON EXTENSION | 将一个索引标记为依赖于特定的数据库扩展(extension) |
查看索引
1、使用数据字典查询索引
| 数据字典 | 简介 |
|---|---|
| sys_indexs | 对于数据库中每一个索引信息的访问 |
| dba_indexs | 对于数据库中每一个索引信息的访问 |
| user_indexs | 提供当前用户拥有的索引信息 |
| user_ind_columns | 提供当前用户的所有建有索引的列的信息 |
| sys_stat_all_indexes | 提供索引相关信息,包含索引扫描数、行读取数等信息 |
2、使用元命令查看索引
| 命令 | 简介 |
|---|---|
| \di[+] [index_name] | 列出索引的相关信息 |
3、使用系统函数查看索引
| 系统索引 | 简介 |
|---|---|
| sys_get_indexdef | 获得索引的CREATE INDEX命令 |
| sys_index_has_property | 测试一个索引是否有指定的性质,如clusterable、index_scan、bitmap_scan、backward_scan |
| sys_index_column_has_property | 测试一个索引列是否有指定的性质,如asc、desc、search_nulls等 |
| sys_indexam_has_property | 测试一个索引访问方法是否有指定的性质,如can_order、can_unique、can_multi_col、can_exclude |
删除索引
语法:
DROP INDEX [ CONCURRENTLY ] [ IF EXISTS ] name [,...] [CASCADE | RESTRICT]
| 参数 | 简介 |
|---|---|
| CONCURRENTLY | 使用这个选项的时候,不支持CASCADE选项,因此带UNIQUE或PRIMARY KEY约束的索引不能这样删除 |
| CASCADE | 自动删除依赖于该索引的对象,然后删除所以依赖于那些对象的对象 |
| RESTRICT | 如果有任何对象依赖于该索引,则拒绝删除它。这个是默认值 |
重建索引
1、REINDEX命令用于重建一个索引,并且替换掉旧索引的数据文件。以下这些场景是需要重建索引的
①一个索引已经损坏,并且不再包含合法数据
②一个索引变得"臃肿",其中包含很多空的或者近乎为空的页面
③修改了一个索引的存储参数(例如填充因子),并且希望确保这种修改完全生效
④使用CONCURRENTLY选项创建索引失败,导致索引是无效的
语法:
REINDEX [ (VERBOSE) ] { INDEX | TABLE | SCHEMA | DATABASE | SYSTEM } [ CONCURRENTLY ] name
| 参数 | 简介 |
|---|---|
| INDEX | 重新创建指定的索引 |
| TABLE | 重新创建指定表的所有索引。如果该表有一个二级"TOAST"表。他也会被重索引 |
| SCHEMA | 重新创建指定模式中的所有索引。共享的系统目录上的索引也会被处理。这种形式的REINDEX不能在一个事务块内执行 |
| DATABASE | 重新创建当前数据库内的所有索引。共享的系统目录上的索引也会被处理。这种形式的REINDEX不能在一个事务块内执行 |
| SYSTEM | 重新创建当前数据库中在系统目录上的所有索引。共享系统目录上的索引也被包括在内,用户表上的索引则不会被处理。这种形式的REINDEX不能在一个事务块内执行 |
| VERBOSE | 在每个索引被重建时打印进度报告 |
实验1:创建索引–CREATE INDEX
创建非唯一索引
1、创建测试表t01(id int,name text),并插入1万行数据
test=# create table t01(id int,name text);
2、收集t01表的统计信息
generate_series()是一个用来生成整数序列对的函数,generate_series(1,10000)就是用来生成1到10000的整数序列对的
generate产生,series系列
MD5(random())是函数嵌套函数
MD5()是一个加密函数,用于生成一个32位的十六进制数字字符串
random()函数生成一个0到1之间的随机浮点数,MD5函数对这个随机数进行加密。
test=# insert INTO t01 select generate_series(1,10000),MD5(random());
3、在id列上创建名为idx_t01_id的非唯一索引
test=# create index idx_t01_id ON t01(id);
4、使用元命令查看idx_t01_id索引的信息
test=# \di+ idx_t01_id

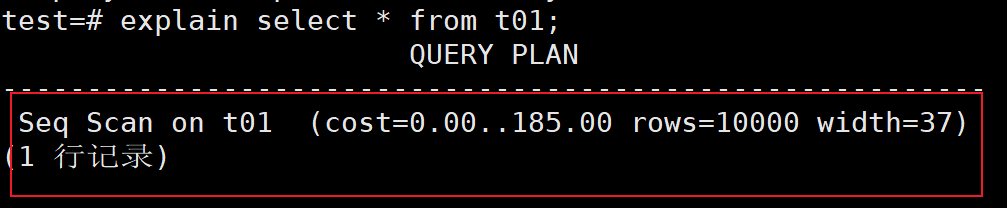
5、测试查询是否使用索引扫描
test=# explain select * from t01;
创建唯一索引
创建唯一索引,唯一索引创建的需求:在索引对应的列中没有重名的列值,如身份证等
不能创建唯一索引的场景:姓名有可能会重名
创建唯一索引从性能上来说,创建唯一索引会比普通索引的性能高出不少。并且,随着唯一索引的创建,唯一索引对应的列上也会自动创建一个唯一约束,从而导致了创建唯一索引之后,不能再往那一列中插入相同的数据(需要保证数据的唯一性)
当创建唯一索引不成功的原因可能是创建唯一索引的那一列本身就有重复数据
1、创建测试表t01
test=# create table t01(id int,name text);
2、在id列上创建名为idx_t01_id的唯一索引
test=# create unique INDEX idx_t01_id ON t01(id);
3、使用函数查看idx_t01_id索引的定义信息
‘idx_t01_id’::regclass::oid,将字符串’idx_t01_id’转换为regclass类型,再将regclass类型转换OID类型
通过regclass取出idx_t01_id的oid,然后再通过sys_get_indexdef这个函数查询出这个是怎么创建的
test=# select sys_get_indexdef('idx_t01_id'::regclass::oid);

创建表达式索引
表达式索引并不是基于表中的单个列,而是基于列上的某个表达式或函数的结果,就像这本书的目录只有满足该表达式的内容一样
如国外的时间存入数据库时要立刻转换成所对应的中国时间,就需要使用某种表达式达到这种效果再存到数据库中
表达式索引的优点在于
①索引不是原始的列值,而基于列值经过某种计算或函数处理后的结果
②对于经常使用特定表达式的查询,表达式索引可以显著提高查询效率,因为数据库不需要在查询执行时动态计算表达式
③表达式索引可以创建基于复杂表达式的索引,例如字符串函数(LEFT、RIGHT等)以及其它函数等
1、创建测试表t01
test=# create table t01(id int,name text);
2、在name列上创建名为idx_t01_name的表达式索引,要求表达式能从name列中提取左侧第一个字符
test=# create index idx_t01_name ON t01(left(name,1));
3、使用函数查看是如何创建idx_t01_name索引的
test=# select sys_get_indexdef('idx_t01_name'::regclass::oid);

创建部分索引
部分索引是索引表中满足特定条件的一部分行,而不是整个表中的所有行,就像目录上只有满足特定条件的内容一样。因为要求是满足特定条件,所以在创建特定索引的时候,必然离不开where子句
部分索引可以极大地减少我们索引的大小,因为只有满足特定条件的内容才被放到索引的那棵树内
1、创建测试表
test=# create table t01(id int,name text);
2、在name列上创建名为idx_t01_id的部分索引,要求id值在500到1000之间
test=# create index idx_t01_id ON t01(id) where id between 500 and 1000;
3、使用函数查看创建idx_t01_id索引的语句
test=# select sys_get_indexdef('idx_t01_id'::regclass::oid);

创建复合索引
复合索引,并不是像先前那样基于某一列来创建索引,而是基于某几列来创建索引,即一个表内有多个索引;如在班级全中,我们既需要按照两位数学号来查询,又需要按照班级来查询,要求为学号和班级创建索引,加快查询速度
在对两个列创建索引的时候,其实还是只生成了一棵树(快),并且在创建复合索引时,字段的顺序和查询时使用索引的结果息息相关,例如,“create index index_student on student(id,class)”,在查询时若是想用到索引,也必须按照这样的顺序,select * from student where id=1 and class =‘1班’;
如建立一个复合索引(c1,c2,c3),功能上相当于建立了(c1),(c1,c2),(c1,c2,c3)四个索引
1、创建测试表t01表
test=# create table t01(id int,name text);
2、在id、name列上创建名为idx_t01_id的复合索引
test=# create index idx_t01_id ON t01(id,name);
3、使用函数查看idx_t01_id索引的定义信息
test=# select sys_get_indexdef('idx_t01_id'::regclass::oid);

实验2:修改索引–ALTER INDEX
重命名索引
1、创建测试表,并使用gererate_series插入1万行数据
test=# create table t01(id int,name text);
test=# insert INTO t01 select generate_series(1,10000),MD5(random());
2、在id列上增加名为pk_t01的主键约束(系统会自动创建跟主键约束同名的索引)
test=# alter table t01 add constraint pk_t01 primary key (id);
3、使用元命令查看t01表的id列上是否已创建索引
test=# \d+ t01
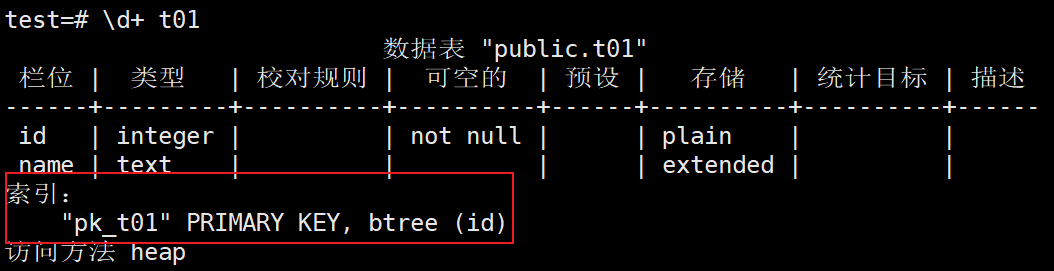
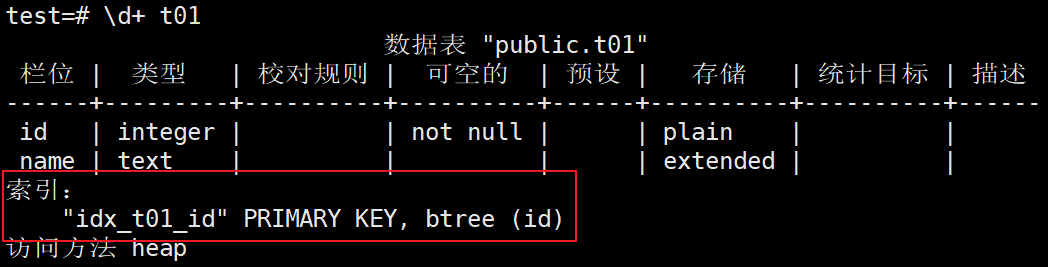
4、修改pk_t01的索引名称未idx_t01_id
test=# alter index pk_t01 rename to idx_t01_id;
6、查看索引修改结果
test=# \d+ t01
移动索引到其它表空间
1、新建表空间tbs01和tbs02
①创建表空间所使用的目录并设置目录的属主,表空间tbs01和tbs02所对应的物理地址分别是/tbs01和/tbs02
[root@node1 ~]# mkdir /tbs01
[root@node1 ~]# mkdir /tbs02
[root@node1 ~]# chown kingbase.kingbase /tbs01
[root@node1 ~]# chown kingbase.kingbase /tbs02
[root@node1 ~]# ll -d /tbs*
drwxr-xr-x 2 kingbase kingbase 6 11月 20 10:20 /tbs01
drwxr-xr-x 2 kingbase kingbase 6 11月 20 10:20 /tbs02
②创建两个表空间分别指向对应的目录
test=# create tablespace tbs01 location '/tbs01';
CREATE TABLESPACE
test=# create tablespace tbs02 location '/tbs02';
CREATE TABLESPACE
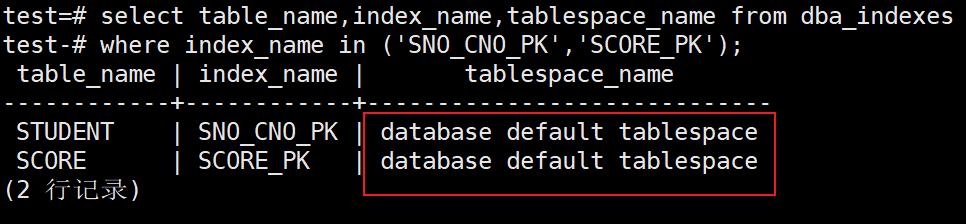
2、查看待移动索引的原始索引空间,然后迁移索引到索引空间tbs01中,查询SNO_CNO_PK和SCORE_PK这两个索引
test=# select table_name,index_name,tablespace_name from dba_indexes
test-# where index_name in ('SNO_CNO_PK','SCORE_PK');
test=# select table_name,index_name,tablespace_name from dba_indexes
test-# where index_name in('SNO_CNO_PK','SCORE_PK');
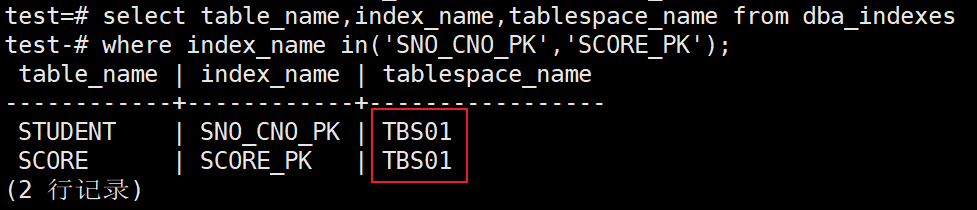
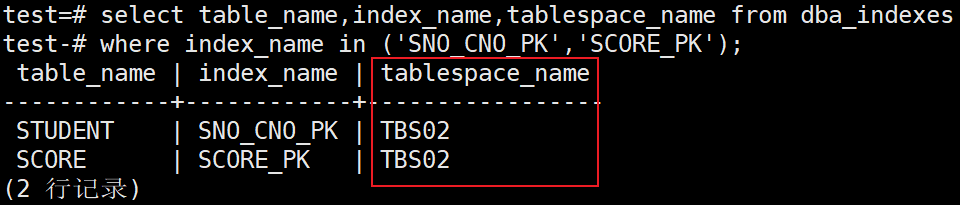
3、将tbs01索引空间中的所有索引全部迁移到索引空间tbs02内
test=# alter index all in tablespace tbs01 set tablespace tbs02;
test=# select table_name,index_name,tablespace_name from dba_indexes
test-# where index_name in ('SNO_CNO_PK','SCORE_PK');
修改索引的填充因子
索引的填充因子是什么?索引的填充因子(Fill Factor)是用于优化数据库索引性能的一个参数。指定了再创建或重新组织索引时,索引页可以被填充到多大程度。填充因子的范围是从0到100,其中0表示完全未填充,100表示完全填充
索引页又是什么?索引页是存储索引数据的物理存储单元,数据库的索引通常以一种有特殊的数据结构(就是B-tree)来组织,这些数据结构被存储在一系列的页中,每一个页就被成索引页
1、创建测试表t01
test=# create table t01(id int,name text);
2、在id列上创建名为idx_t01_id的索引
test=# create index idx_t01_id on t01(id);
3、使用函数查看idx_t01_id索引信息
test=# select sys_get_indexdef('idx_t01_id'::regclass::oid);

4、修改idx_t01_id索引的填充因子为75
test=# alter index idx_t01_id set (fillfactor=75);
5、再次使用函数查看idx_t01_id索引修改后的信息
可以看到fillfactor(填充因子)已经被修改为75了
test=# select sys_get_indexdef('idx_t01_id'::regclass::oid);

实验3:重建索引—REINDEX
索引膨胀时重建索引
1、创建测试表t01,并插入100万行数据
test=# create table t01(id int,name text);
test=# insert INTO t01 select generate_series(1,1000000),MD5(random());
2、在id列上创建名为idx_t01_id的索引
test=# create index idx_t01_id ON t01(id);
3、使用元命令查看idx_t01_id索引信息,主要看的是索引的大小
test=# \di+ idx_t01_id

4、删除t01表中50%的数据
test=# delete from t01 where id<=25000 or id>75000;
5、使用元命令查看idx_t01_id索引信息(索引空间未释放),可以看到索引的大小还是和删除前是一样的
test=# \di+ idx_t01_id
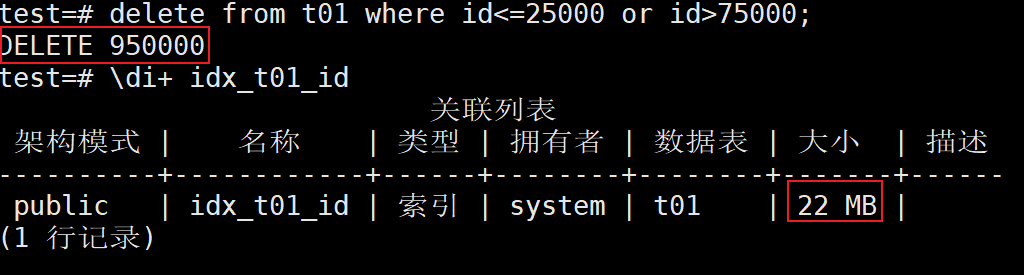
6、重建idx_t01_id索引
test=# reindex index idx_t01_id ;
7、再次使用元命令查看idx_t01_id索引信息,这时的索引空间应该是释放的
test=# \di+ idx_t01_id

索引文件损坏时重建索引
1、创建测试表t01,并插入100万行数据
test=# insert INTO t01 select generate_series(1,1000000),MD5(random());
2、在id列上创建名为idx_t01_id的索引
test=# create index idx_t01_id on t01(id);
3、查看idx_t01_id索引的存储信息,查找物理存储位置,这里查找到为base/12259/16603,又因为KES数据库的数据都存放在/date目录下,所以这里指的物理路径应该是/date/base/12259/16603,这还表示了该索引的oid号为16603
test=# select sys_relation_filepath('idx_t01_id');
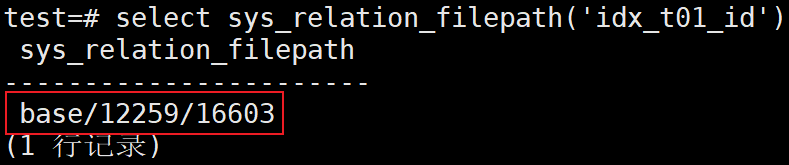
4、清空idx_t01_t01_id索引的存储文件,使索引文件中的数据全部为空
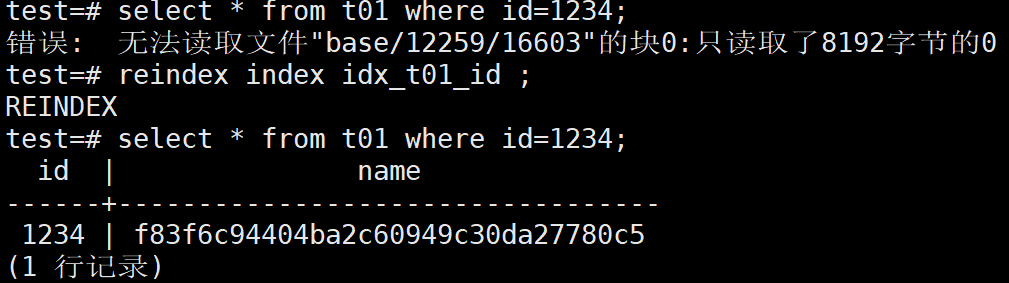
test=# \! > /data/base/12259/16603
5、测试使用索引扫描查询数据,因为到这里索引文件应该是损坏的,所以将会查询失败
test=# select * from t01 where id=1234;

6、重建idx_t01_id索引
test=# reindex index idx_t01_id ;
7、测试使用索引扫描查询数据,经过重建索引后,再次查询应该是执行成功的
test=# select * from t01 where id=1234;
重建索引分为5个级别
| 例子 | 简介 |
|---|---|
| REINDEX INDEX idx_t01 | 只重建idx_t01这个索引 |
| REINDEX TABLE emp01 | 重建指定表下的全部索引,将emp01表下的索引给重建一遍 |
| REINDEX SCHEMA public | 将public模式下的全部索引都给重建一遍,重建指定模式下的全部索引 |
| REINDEX DATABASE test | 重建指定数据库下的全部索引,将test数据库下的全部索引重建一遍 |
| REINDEX SYSTEM test | 重建指定数据库中系统模式下的全部索引 |
实验4:删除索引—DROP INDEX
使用DROP INDEX语法删除索引
1、创建测试表t01,并插入1万行数据
test=# create table t01(id int,name text);
test=# insert INTO t01 select generate_series(1,10000),MD5(random());
2、在id列上创建名为idx_t01_id的索引
test=# create index idx_t01_id on t01(id);
3、查看查询t01表的SQL执行计划,因为这个时候索引还存在,所以查询时是根据索引来扫描的,即扫描B-tree
test=# explain select * from t01 where id=99999;

4、删除idx_t01_id索引
test=# drop index idx_t01_id;
5、查看查询t01表的SQL执行计划,这个时候所以已经被删除了,所以查询时是直接将整个数据表扫描一遍
test=# explain select * from t01 where id=99999;
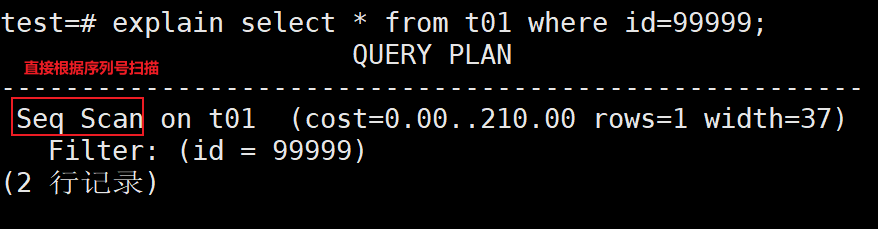
删除主键约束时会自动删除索引
1、创建测试表t01,并插入1万行数据
test=# create table t01(id int,name text);
test=# insert INTO t01 select generate_series(1,10000),MD5(random());
2、在id列上增加名为pk_t01的主键约束
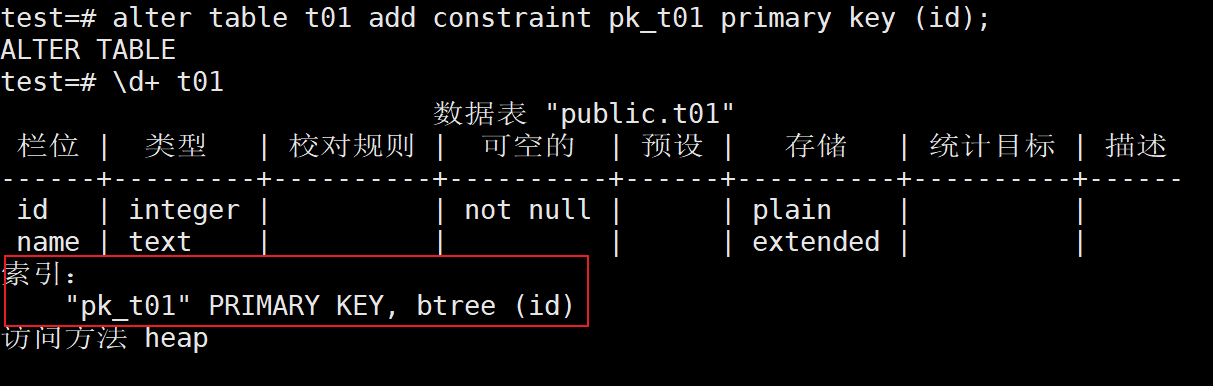
test=# alter table t01 add constraint pk_t01 primary key (id);
3、查看t01表中自动创建的索引信息
test=# \d+ t01
4、删除主键约束
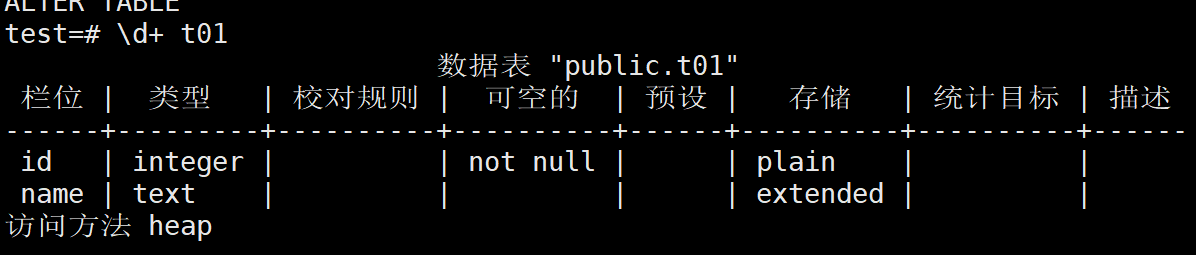
test=# alter table t01 drop CONSTRAINT pk_t01 ;
5、查看t01表中的索引是否被删除
test=# \d+ t01
小结
索引的优点
1、合理使用索引可以大大提高数据的检索速度
2、唯一性索引可以保证表中每一行数据的唯一性
3、索引可以加速表和表之间的连接以及实现数据的参考完整性
4、在使用分组和排序子句进行数据检索时,索引可以显著减少分组和排序的时间
索引的缺点
1、索引需要占用物理空间
2、增删改表的记录行的时候,索引需要动态维护,这降低了性能
3、建立和删除索引比较耗时,消耗服务器资源