import threading
import time
#5.定义一个全局的变量
mutext=threading.Lock()
#1.定义一个全局变量
g_num=0
#2.定义2个函数-用他们来充当线程要执行的代码
def task1(num):
global g_num
for i in range(num):
#上锁
mutex.acquire()
g_num+=1
#解锁
print('task1中,g_num=%d'%g_num)
def task2(num):
global g_num
for i in range(num):
#上锁
mutex.acquire()
g_num+=1
#解锁
print('task2中,g_num=%d'%g_num)
#3.创建线程对象
t1=threading.Thread(target=task1,args=(100,))
t2=threading.Thread(target=task2,args=(100,))
#4.调用start创建线程,让线程开始运行
t1.start()
#time.sleep(2) #让主线程延迟一会,保证让task1这个任务先执行完毕
t2.start()注意点1:
当线程task1,task2执行的时候,双方要抢着给mutex这个互斥锁上锁。不管是那个线程先抢到,都会保证一件事情:其他的线程会卡在上锁的那个位置。例如:task1先对mutex上锁,会导致在调用release解锁之前,task2线程会堵塞在mutex.acquire上锁的那个位置,一直到task1线程调用了mutex.release()释放锁
当task1调用了release释放锁后,接下来task1与task2线程依然会抢着给mutex上锁,不确定会让哪个线程上锁,这是操作系统做的事情,我们程序不能控制
注意点2:
如果在task1与task2中2个线程都抢着上锁的时候,恰巧task1线程抢到l999999次。当下一次的时候task2抢到了500000次,再下一次的时候task1抢到了,此时task1总执行的100万次已经完成,而此时打印出来的g_num的值是150万,而不是100万
1.进程
进程:一个程序运行起来后,代码+用到的资源称之为进程,它是操作系统分配资源的基本单元。
程序vs进程
1.程序:一段代码,这个代码规定了将来运行时程序执行的流程
2.进程:运行中的程序+它需要的资源(cpu、网络、内存等)
2.创建进程方式1
from multiprocessing import Process
import time
def test();
'''子进程单独执行的代码'''
while True:
print('-----test-----')
time.sleep(1)
if __name___='__main__':
p=Process(target=test)
p.start()
#主进程单独执行的代码
while True:
print('-----main-----')
time.sleep(1)
#1.导入模块
import multiprocessing
#2.定义一个函数,表示执行要执行的代码
def task1():
while True:
print('我是子进程....')
time.sleep(1)
#3.创建一个进程对象
p=multiprocessing.Process(target=task1)
#4.调用它的start方法才会真正的创建进程
p.start()
#5.主进程继续向下进行
while True:
print('我是主进程....')
time.sleep(1)
小结
1.创建子进程的流程:
1.导入multiprocessing模块
2.定义一个函数
3.创建Process对象并且通过target指定刚刚定义的那个函数
4.调用start()
2.创建多线程的流程(继承threading.Thread)
1.导入threading
2.定义一个类,继承threading.Thread。可以重写__init__方法,这个方法可以用来接收创建对象时要传递的参数。一定要实现run方法。
3.通过自己定义的类,创建出一个对象,这个对象就是线程对象。如果要是给这个自定义的类传递了参数,类名(参数)
4.对象.start()
3.创建进程方式2
import multiprocessing
import time
class MyProcess(multiprocessing.Process):
def run(self):
while True:
print('我是子进程....')
time.sleep(1)
p=MyProcess()
p.start()
while True:
print('我是主进程....')
time.sleep(1)4.创建进程对象时传递参数
创建线程时传递参数:
def task(a,b,c,mm,nn):
Thread(target=task,args=(11,22,33,),kwargs={'mm':44,'nn':55})创建进程时传递参数:
import multiprocessing
def task(name,age,**kwargs):
print('name',name)
print('age',age)
print(kwargs)
p=multiprocessing,Process(target=task,args=('xaioming',18),kwargs={'mm':10})
p.start()
5.进程不共享全局变量
import multiprocessing
NUM=100
def task1():
global NUM
NUM=00
print('-----in task1,NUM is %d'%NUM)
def task2():
print('----in task2,NUM is %d'%NUM)
p1=multiprocessing.Process(target=task1)
p2=multiprocessing.Process(target=task2)
#先让p1标记的进程执行
p1.start()
#让主进程延时1秒,保证在这个1秒内,p1标记的进程执行完毕代码
time.sleep(1)
#让p2标记的继承开始运行,看看获取的值是否是200?
p2.start()
1.当创建一个子进程的时候,会复制父进程的很多东西(全局变量等)
2.子进程和主进程是单独的2个进程,不是一个
1.当一个进程结束的时候,不会对其他的进程产生影响
线程之间共享全局变量
1.所有的线程都在同一个进程中,这个进程是主进程
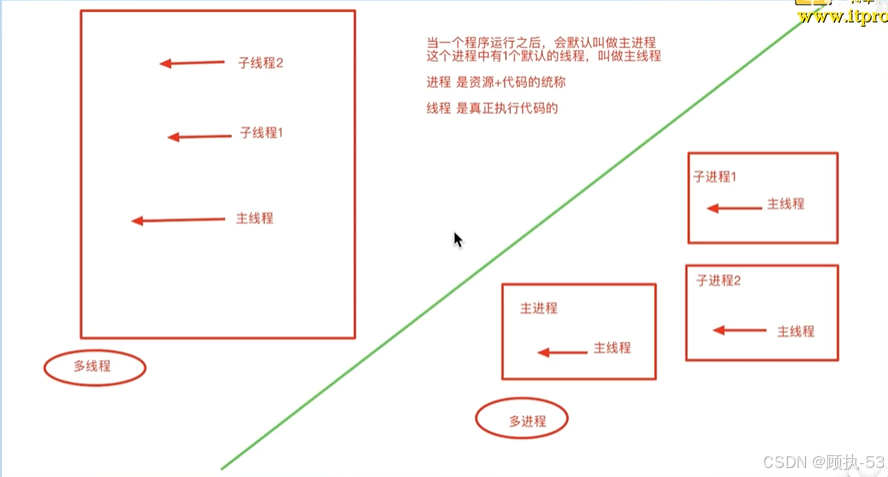
当一个程序运行之后,会默认叫做主进程。这个进程中有1个默认的线程,叫做主线程。进程是资源+代码的统称,线程是真正执行代码的
6.进程间通信-Queue
import multiprocess
import time
def task1(q):
for i in ['A','B','C']:
q.put(i)
def task2(q):
while True:
time.sleep(0.5)
if not q.empty():
value=q.get()
print('提取出来的数据是:',value)
else:
break
if__name__='__main__':
q=multiprocessing.Queue()
p1=multiprocessing.Process(target=task1,args=(q,))
p2=multiprocessing.Process(target=task2,args=(q,))
p1.start()
p2.start()
进程之间是独立的,所有的数据各自用各自的,因此为了能够让这些进程之间共享数据,不能使用全局变量,可以使用Linux(Unix)给出的解决办法:
1.进程通信(IPC)
1.管道
2.命名管道
3.socket(重点):能够实现多台电脑上的进程间通信
4. 。。。。
2.为了更加简单的实现进程间的通信,可以使用队列Queue
import multiprocessing
q=multiprocessing.Queue()
#进程1
#可以通过q.put()放入数据
#进程2
#可以通过q.get()来获取数据7.进程与线程的对比
-进程 能够完成多任务,比如在一台电脑上能够同时运行多个QQ
-线程 能够完成多个任务,比如一个QQ中的多个聊天窗口
-线程的花费尺度小于进程(资源比进程少),使得多线程程序的并发性高。
-进程在执行过程中拥有独立的内存单元,而多个线程共享内存,,从而极大地提高了程序的运行效率
-线程不能够独立执行,必须依存在进程中
-可以将进程理解为工厂中的一条流水线,而其中的线程结束这个流水线上的工人
定义的不同
-进程是系统进行资源分配和调度的一个独立单位
-线程是进程的一个实体,是cpu调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
区别
-一个程序至少有一个进程,一个进程至少有一个线程。
-线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高
-进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
8.创建进程方式3-进程池
from multiprocessing import Pool
import os
import random
import time
def worker(num):
for i in range(5):
print('===pid=%d==num=%d='%(os.getpid(),num))
timne.sleep(1)
#3表示进程池中最多有三个进程一起执行
pool=Pool(3)
for i in range(10):
print('---%d---'%i)
#向进程中添加任务
#注意:如果添加的任务数量超过了进程池中进程的个数的话,那么就不会接着往进程池中添加,
# 如果还没有执行的话,他会等待前面的进程结束,然后往进程池中添加进程
pool.apply_async(worker,(i,))
pool.close() #关闭进程池
pool.join() #主进程在这里等待,只有子进程全部结束之后,再开启主进程
import multiprocessing
import random
import time
def task(num):
time.sleep(random.randint(1,5))
print('i=%d'%i)
#创建一个进程池,它最多有3个进程可以一起执行
pool=multiprocessing.Pool(3)
#向进程池中添加任务
for i in range(10):
pool.apply_async(task,(i,))
#主进程不会等待进程池中所有进程结束之后再结束
print('主进程添加任务结束.....')
#如果使用延时的方式在这个地方让主进程等待子进程结束的话,时间不容易把握
#time.sleep(100)
#会等待所有的pool标记的进程池中所有的进程都结束之后,主进程才会继续向下运行
pool.join()