mongodb.py: 数据库接口,包含了MongoAPI类,负责建立与本地数据库的连接并实现基础操作。stealth.min.js: 一个 javascript 文件,用来抹掉 selenium 中的自动化特征。
爬取逻辑
a. 爬取帖子信息
- 设定爬取的帖子页数
page后,爬虫将会爬取第一页到第page页的所有帖子信息,包括标题、评论个数、浏览量、发帖时间和帖子对应的跳转链接(非股吧帖子的链接将会被剔除),以post_XXXXXX为名保存到本地名为post_info的数据库中(后续爬取对应股票的评论信息需要用到这一步的数据)。 - 注意保存的时间为发帖时间,而非更新时间。而如何确立发帖时间年份的函数集成在了
PostParser类(不是通过访问帖子跳转链接获取),其中还有一些特殊情况的处理,不在此赘述。 - 当爬取帖子到 660 页左右时,一般会被限制访问,此时程序会自动退出
webdriver并重新实例一个继续爬取。(ps: 暂时只知道这个解决方法,试过清理 cookies 和更改 user-agent,并不管用orz)
b. 爬取评论信息
- 爬取评论信息一定要等帖子信息爬取完之后才可以进行,因为要用到帖子对应的跳转链接,和该帖子是否有评论的信息(没有评论的帖子会从爬取列表中剔除,节省时间)。
- 输入
start_date和end_date后,会自动从集合post_XXXXXX中筛选出该时间范围内且评论数不为零的帖子链接,爬取这些帖子下的一级评论、二级评论(sub_comment为 1 代表是二级评论,0 代表一级评论)、点赞数和评论时间,以comment_XXXXXX为名保存到本地名为comment_info的数据库中。 - 对于无法显示的违规评论,会自动略过该帖。有时帖子评论未能成功加载,则会在 0.2s 后刷新网页,若依旧加载失败,也会略过该帖子。
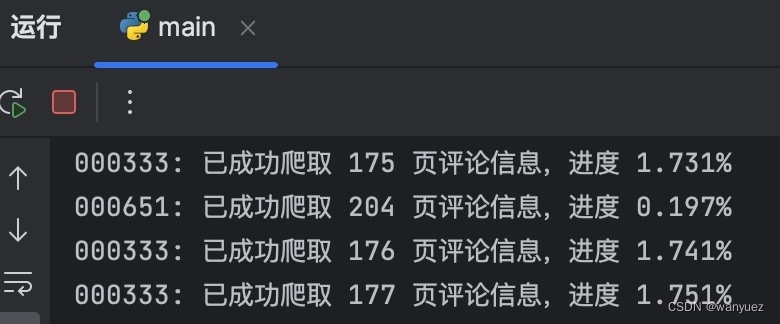
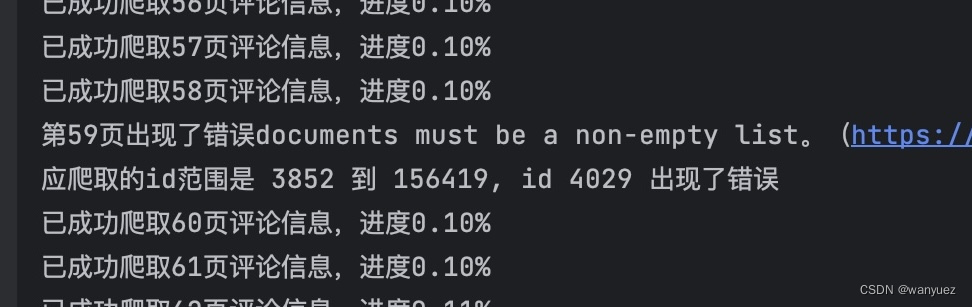
- 在爬取的时候会显示爬取页数和完成进度。若爬虫中途中断,会显示需要爬取的
_id范围和出错的id值,可通过find_by_id方法从上次终止的地方接着抓取评论数据。
使用步骤
1. 下载代码
项目仓库链接:EastMoney_Crawler
可以直接 git clone 或 Download ZIP ,或者点击 release 下载。
2. MongoDB 安装
若没有 MongoDB,需要先下载,mac 推荐直接使用 homebrew 进行安装(官网教程)。
安装后记得在终端中启动 MongoDB,命令如下:
brew services start [email protected]
如果 MongoDB 运行在本地计算机上,而且也没有修改端口或者添加用户名及密码,那么不需要进行任何操作;若有更改,则需在 mongodb.py 中修改对应参数。
最后在 MongoDB 中创建两个数据库 post_info 和 comment_info ,分别用来储存 发帖信息 和 评论信息。
3. Webdriver 安装
在电脑上下载 Chromedriver ,版本需要与 Chrome 一致,安装教程见 Chromedriver (mac),Chromedriver (win)。
4. 运行 main.py
进入主程序 main.py ,安装没有安装的包,对参数进行修改( main.py 中有相关参数的解释)即可开始爬取(注意在爬取评论信息前需要先爬取发帖信息)。
a. 爬取发帖信息参数设置示例:
thread1 = threading.Thread(target=post_thread, args=('000333', 500)) # 设置想要爬取的股票代码和页数
thread2 = threading.Thread(target=post_thread, args=('000729', 500)) # 可同时进行多个线程
第一个参数为 stock_symbol ,第二个参数为 page 。thread1 表示爬取 000333 股吧的 500 页帖子信息。
b. 爬取评论信息参数设置示例:
thread1 = threading.Thread(target=comment_thread_date, args=('000333', '2020-01-01', '2023-12-31'))
thread2 = threading.Thread(target=comment_thread_date, args=('000729', '2020-01-01', '2023-12-31'))
第一个参数为 stock_symbol ,第二个参数为 start_date ,第三个参数为 end_date 。thread1 表示爬取 2020-01-01 到 2023-12-31 范围中 000333 股吧帖子下的评论信息。
5. 查看数据
爬取成功后,帖子相关信息以 post_XXXXXX 为集合名储存在 post_info 数据库中,评论相关信息以 comment_XXXXXX 为集合名储存在 comment_info 数据库中。
附录(运行结果)
- 股吧发帖界面
- 股吧评论界面
- 爬取进度与报错提醒
- 爬取结果(发帖信息 和 评论信息)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!**
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
