2.5 存在的问题
随着规模的逐渐发展和更多用户场景的提出,这套架构也逐渐暴露出了一些问题。
2.5.1 TCPCopy 存在性能问题
TCPCopy 在实现上没有进行多线程的设计,因此实际的转发吞吐能力较为有限,对于一些高带宽的测试场景无法很好地支持。
2.5.2 现有实现无法支持响应录制等更多场景
TCPCopy 定位只是请求复制转发工具,只会复制线上流量的请求部分,而不会复制线上流量的响应。我们接到了一些想要对线上流量进行分析的用户的需求,他们希望能够同时收集线上流量的请求和响应,TCPCopy 没法支持这类场景。
3. 自研 ByteCopy,开启海量流量和复杂业务场景的支持
================================
前面提到了第一代引流系统存在一些性能和灵活性的问题,与此同时业务也提出了一些新的需求,例如支持 MySQL 协议,支持历史流量的存储和回放等。考虑到在现有的 TCPCopy 的架构上很难做扩展,所以我们考虑推翻现有架构,重新构建字节新一代的引流系统 - ByteCopy (寓意是复制线上每一个字节)
在以上演进的基础上,我们可以按职责把七层流量复制大致分解为下面三个模块
-
流量采集
-
流量解析
-
流量应用
针对 3 个模块我们分别展开介绍
3.1 流量采集
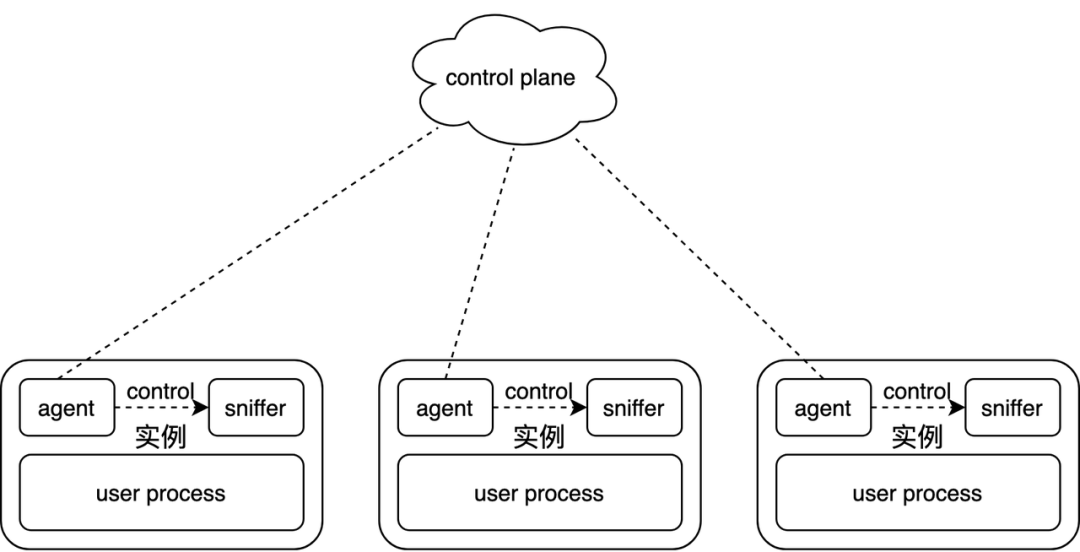
流量采集模块会依据服务部署的平台以不同方式拉起,如在 Kubernetes 会由 Mesh Agent 唤起,使用 libpcap 监听特定端口流量,在用户态重组 TCP 层包,batch 发送至 Kafka。
默认场景下,流量采集模块只会对被采集的服务监听的 IP 和端口进行抓包。此外,为了提供出口流量采集(即采集某一服务对其下游依赖发的调用)的能力,流量采集模块还对接了公司的服务发现框架。在需要对出口流量进行采集时,流量采集模块会查询下游依赖服务所有实例的 IP 和端口,对这部分流量也进行采集。(这一方案存在一定问题,后续会详细介绍)
由于流量采集进程和应用进程是部署在同个 Docker 实例或物理机里,业务会对流量采集模块的资源占用比较敏感,我们除了在代码层优化,还会用 cgroups 对资源使用做硬性限制。
此外流量采集平台是多租户设计,对一个服务可能同时存在多个用户的不同规格的采集需求,如用户 A 希望采集 env1 环境 5% 实例流量,用户 B 希望采集 env1 环境 1 个实例的流量及 env2 环境 1 个实例的流量,如果简单地独立处理用户 A 和 B 的请求,会出现 env1 环境部署 5%+1 实例 env2 部署 1 实例这种冗余部署。我们的做法是把用户的请求规格和采集模块的实际部署解耦,用户提交一个规格请求后,会先和已有的规格合并,得到一个最小部署方案,然后更新部署状态。
3.2 流量解析
引流源采集上来的原始流量还是第四层协议,为了支持一些更复杂的功能,比如过滤,多路输出,历史流量存储,流量查询及流量可视化等等,我们需要将四层流量解析到七层。字节跳动内部服务使用得比较多的协议是 Thrift 和 HTTP ,这两个根据协议规范即可很好地完成解析。
流量解析有一个难点是判断流量的边界,区别于 HTTP/2 等的 Pipeline 连接复用传输形式,Thrift 和 HTTP/1.X 在单条连接上严格按照请求-响应对来进行传输,因此可以通过请求和响应的切换分隔出完整的请求或响应流量。
3.3 流量应用
对于线上采集的流量,不同用户会有不同的业务用途,如压测平台可能希望将流量先持久化到 Kafka,然后利用 Kafka 的高吞吐发压;有些研发同学只是简单从线上引一份流量转发到自己的开发环境做新特性测试;有些同学希望转发 QPS 能达到一定水位以实现压测的目的;还有的是特定流量会触发线上 coredump ,他们希望把这段流量录制下来线下 debug 等等。针对不同的场景,我们实现了若干流量输出形式。
下面会着重介绍转发和存储。
3.3.1 转发

结构如上图,emitter 会在 zookeeper 上注册自身,scheduler 感知到 emitter 节点信息,将任务根据各个 emitter 节点的标签和统计信息过滤/打分,然后调度到最合适的节点上。这里有个问题是为什么不直接使用无状态服务,由每个 emitter 实例均等地转发,而采用 sharding 方案,主要是基于下面几点考虑:
-
如果每个任务均摊到所有实例上执行,那每个实例需要和全部下游 endpoint 建立连接,在海量任务下的 goroutine、连接、内存等资源占用是不可接受的
-
通过将单个任务的处理收敛到少数实例上,提高了对单个 endpoint 的请求密度,从而避免因为连接 idle 时间过长被对端 close,复用了连接。
由于 emitter 对性能比较敏感,我们为此也做了很多优化,比如使用了 fasthttp 的 goroutine 池避免频繁申请 goroutine,对连接的 reader/writer 对象池化,动态调节每个 endpoint 的工作线程数量以自适应用户指定 QPS,避免 goroutine 浪费及闲置长连接退化成短连接,全程无锁化,通过 channel+select 做线程同步和数据传递等等。
3.3.2 存储
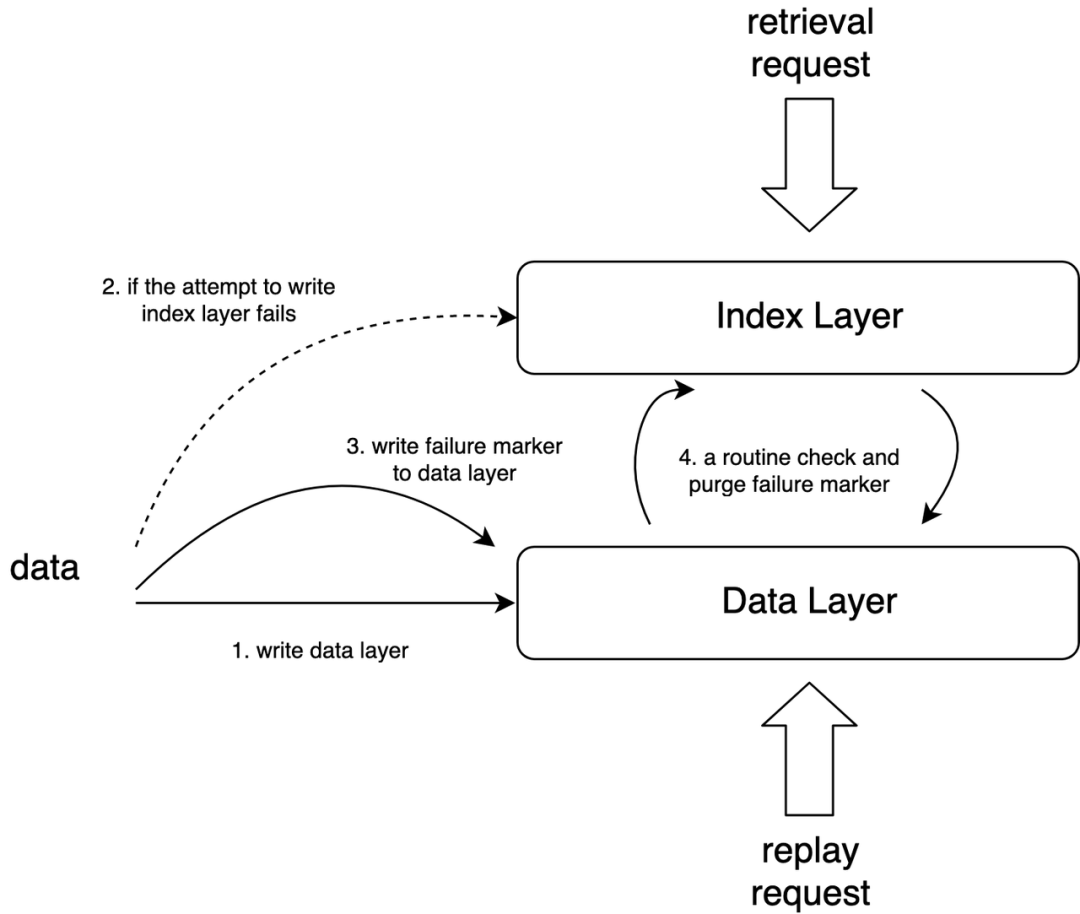
存储分为了两层,数据层和索引层,采用双写模型,并有定时任务从数据层纠错索引层保证两者的最终一致性。存储需 要支持回放和查询两种语义,Data Layer 抽象成了一个支持 KV 查询,按 Key 有序,大容量的存储模型,Index Layer 是 Multi-index->Key 映射模型,通过这两层即可满足流量查询+回放的需求。所以 Data Layer 和 Index Layer 底层实现是模块化的,只需符合上述模型并实现模型定义 API。
Data Layer 的理想数据结构是 LSM tree,写入性能出色,对于流量回放场景,需要按 key 有序扫描流量记录,因为 LSM 满足按 key 的局部性和有序性,可以充分利用 page cache 和磁盘顺序读达到较高回放性能。分布式 LSM Tree 业界比较成熟的开源产品是 HBase,字节跳动内部也有对标产品 Bytable,我们同时实现了基于这两个引擎的 Data Layer,经过一系列性能 benchmark 我们选择了 Bytable 作为 Data Layer 实现。
Index Layer 使用了 ES 的能力,因而可以支持用户的复合条件查询,我们会预先内置一些查询索引,如源服务,目标服务,方法名,traceid 等等,流量查询目前的使用场景一个是作为服务 mock 的数据源,可以屏蔽掉功能测试或者 diff 中不必要的外部依赖,还有一个功能是流量可视化,用户通过请求时间,traceid 等等,查看特定请求的内容。其他场景功能还有待进一步发掘。
3.4 业务场景支持
3.4.1 支持通用的 diff 能力
Diff 验证是互联网公司在快速迭代下保持产品质量的一个利器,类似 Twtiter 的 Diffy 项目,都是通过线上流量的录制回放来实现。但是它的适用场景也很有限,因为是直接在生产环境上通过 AB 环境做回放,无法支持写的流量。虽然阿里巴巴的 doom 平台可以解决写场景的回放隔离问题,但是它是在应用程序中通过 AOP 来实现的,强绑定 java 生态。
通过 ByteCopy 的无侵入引流和流量存储回放能力,结合我们自研的 ByteMock 组件,我们提供了面向业务的无侵入 diff 解决方案,并解决了写隔离的问题。
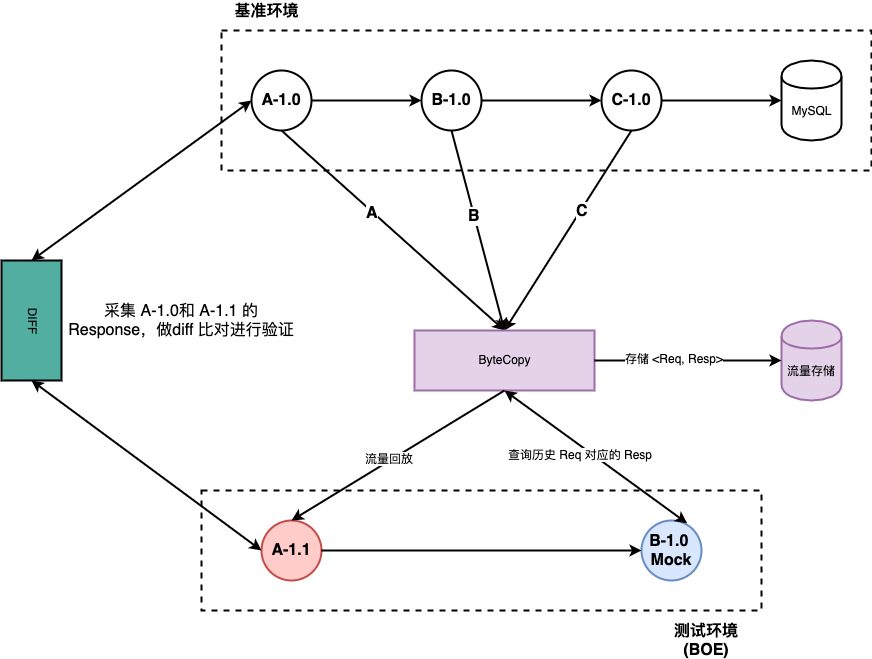
在一个生产环境下的 (A,B,C) 链路中,通过 ByteCopy 实现了针对每一跳 (request, response) 的采集,在做 A 的 diff 验证的时候,通过 ByteCopy 实现对于 A 服务请求的回放,同时,基于 ByteMock 来实现对于服务 B 的 mock,并支持针对一个 trace 的 response 回放 (依赖 ByteCopy 中流量存储,实现精准的回放)。因为 B 是 mock 的,即使是一个写的请求,也可以做到对于线上没有任何影响。
4. 未来展望
========
4.1 更精准的流量采集
前面提到,在进行出口流量的采集时,会对下游依赖服务的所有实例的 IP:端口 进行抓包。而实际的生产环境中,同一台服务器上,可能会部署具有相同下游依赖的多个服务,只依赖四层数据,无法判断抓到的数据到底来自哪一个服务,会造成抓包、处理和转发流程中都会存在资源浪费的问题。目前来看基于网卡抓包的方案应该没法很好地解决这个问题,我们也在尝试探索一些其他的流量采集的方案,比如探索用 ebpf 进行进程级别的流量采集。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip204888 (备注Android)

尾声
评论里面有些同学有疑问关于如何学习material design控件,我的建议是去GitHub搜,有很多同行给的例子,这些栗子足够入门。
有朋友说要是动真格的话,需要NDK以及JVM等的知识,首现**NDK并不是神秘的东西,**你跟着官方的步骤走一遍就知道什么回事了,无非就是一些代码格式以及原生/JAVA内存交互,进阶一点的有原生/JAVA线程交互,线程交互确实有点蛋疼,但平常避免用就好了,再说对于初学者来说关心NDK干嘛,据鄙人以前的经历,只在音视频通信和一个嵌入式信号处理(离线)的两个项目中用过,嵌入式信号处理是JAVA->NDK->.SO->MATLAB这样调用的我原来MATLAB的代码,其他的大多就用在游戏上了吧,一般的互联网公司会有人给你公司的SO包的。
至于JVM,该掌握的那部分,相信我,你会掌握的,不该你掌握的,有那些专门研究JVM的人来做,不如省省心有空看看计算机系统,编译原理。
一句话,平常多写多练,这是最基本的程序员的素质,尽量挤时间,读理论基础书籍,JVM不是未来30年唯一的虚拟机,JAVA也不一定再风靡未来30年工业界,其他的系统和语言也会雨后春笋冒出来,但你理论扎实会让你很快理解学会一个语言或者框架,你平常写的多会让你很快熟练的将新学的东西应用到实际中。
初学者,一句话,多练。
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算
csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算