在探索最新的大语言模型(LLM)时,“MoE”这一术语频繁出现在各种标题之中。
最近春招和实习已开启了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。
技术交流

DeepSeek-V3便是一个实力强劲的混合专家(MoE)模型,其总参数量高达6710亿,且在处理每个标记(token)时,能够智能地激活约370亿的参数,实现高效计算。
同样引人注目的还有Qwen2.5-Max,这一大规模MoE模型通过精心设计的监督微调(SFT)流程以及基于人类反馈的强化学习(RLHF)方法进行了后训练,大大提升了其性能与实用性。
这个“ MoE ”代表什么?为什么这么多大语言模型(LLM)都在使用它?
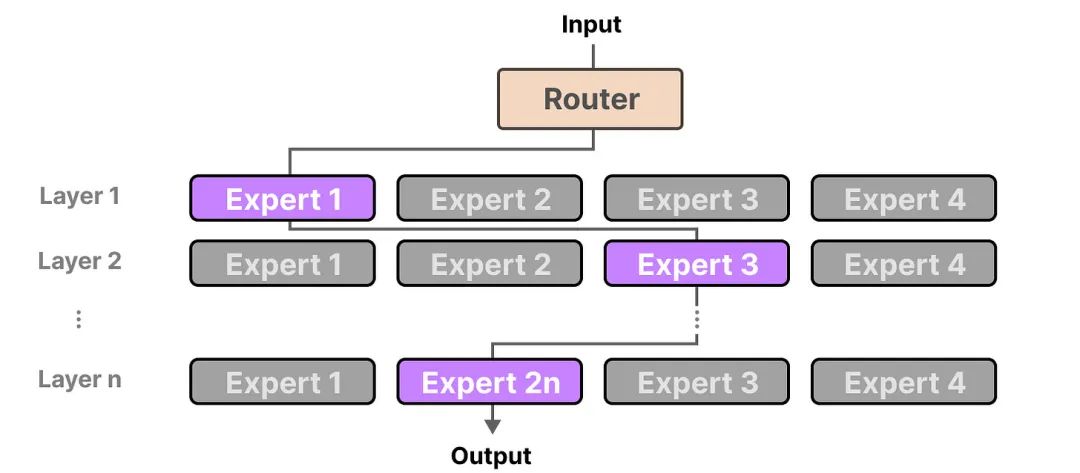
混合专家(Mixture of Experts,MoE)模型将一个复杂的任务分解为多个子任务,每个子任务由一个专门的专家来处理。
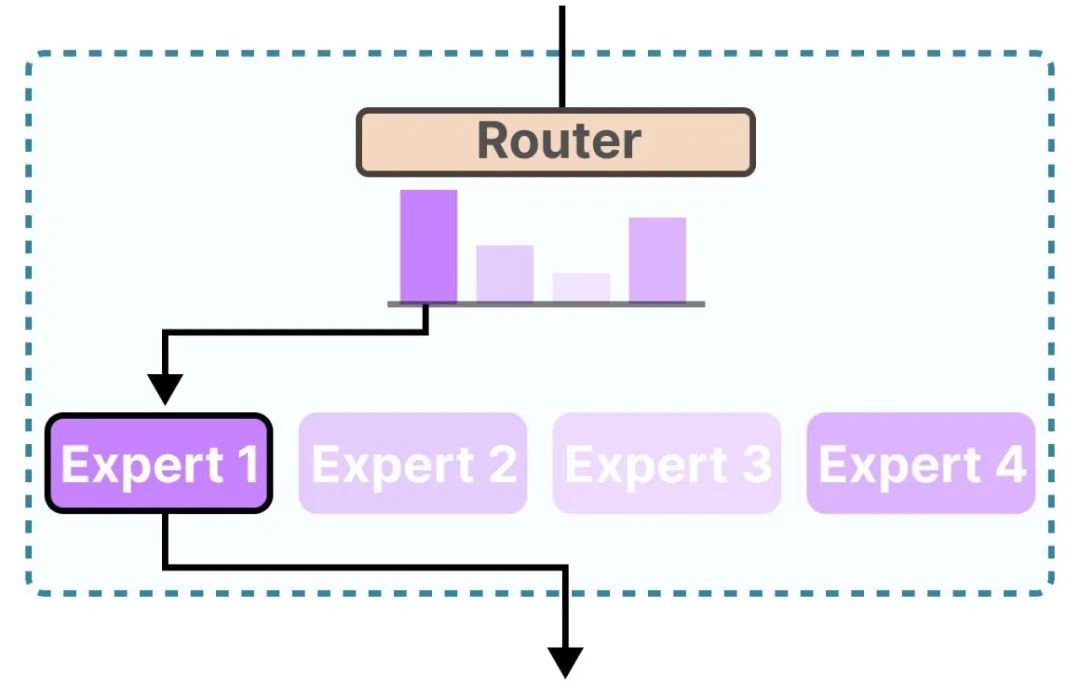
在MoE模型中,“专家”负责学习并处理不同的信息,而“路由器”则负责根据输入智能地选择最合适的专家进行处理,并将选定专家的输出作为最终输出。
一、专家(Expert)
混合专家(MoE)模型的专家(Expert)是什么?专家(Expert)是训练好的子网络(神经网络或层),通常是一个独立的前馈神经网络(FFNN),也可以是更复杂的网络结构。
MoE模型将一个复杂的任务拆分成多个子任务,每个子任务都交给一个专门的“专家”来处理。这些专家各自拥有独特的专长,专门处理特定的数据或任务,就像不同领域的专家一样。
如何将密集模型(Dense)转换为混合专家(MoE)模型?这个过程通常被称为MoE化,将稠密模型的参数和计算分解为多个专家模块,每个专家模块只处理输入数据的一部分,并专注于特定的任务或数据特征。
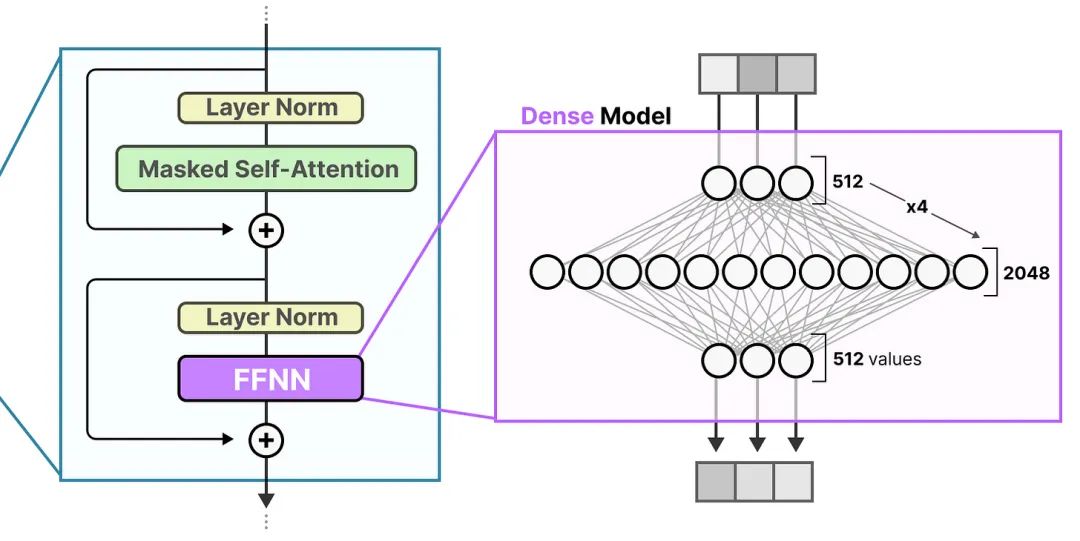
MoE模型通常被用于替换传统的FFNN层。传统 Transformer 中的 FFNN 被称为密集模型(Dense),因为所有参数(其权重和偏差)均已激活。
稠密模型是一个“通才”模型,能够处理多个不同的任务,但可能在处理复杂或特定任务时效率不高。
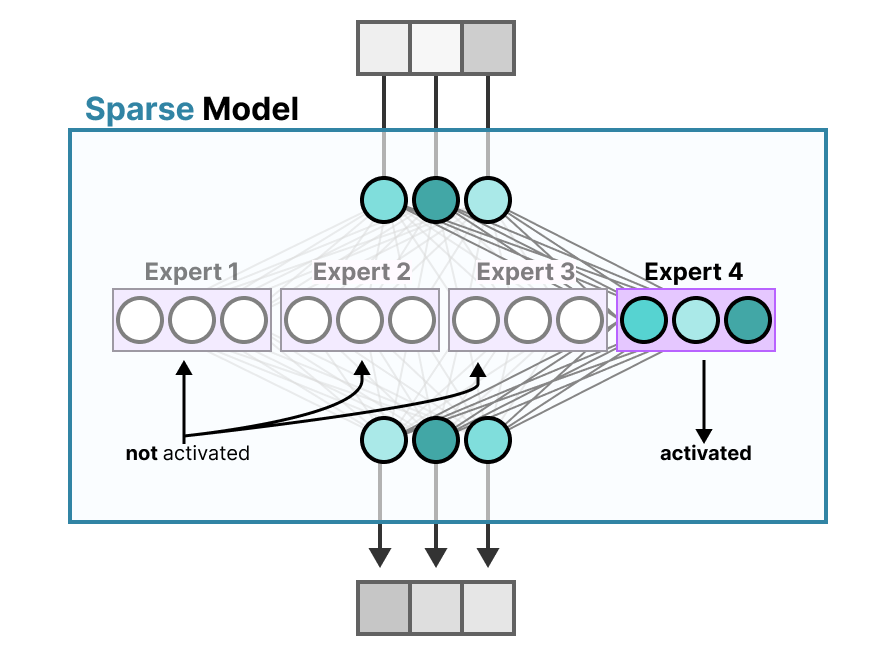
相比之下,稀疏模型仅激活其总参数的一部分,并且与专家混合密切相关。将密集模型分成几部分(所谓的专家),重新训练它,并且在给定时间内只激活一部分专家。
二、路由器(Router)
混合专家(MoE)模型的路由器(Router)是什么?路由器也是一个前馈神经网络(FFNN),用于根据特定输入选择专家。
路由器(Router)输出概率,用于混合专家(MoE)模型选择最佳匹配专家(Expert),选择的专家(Expert)也是一个前馈神经网络(FFNN)。
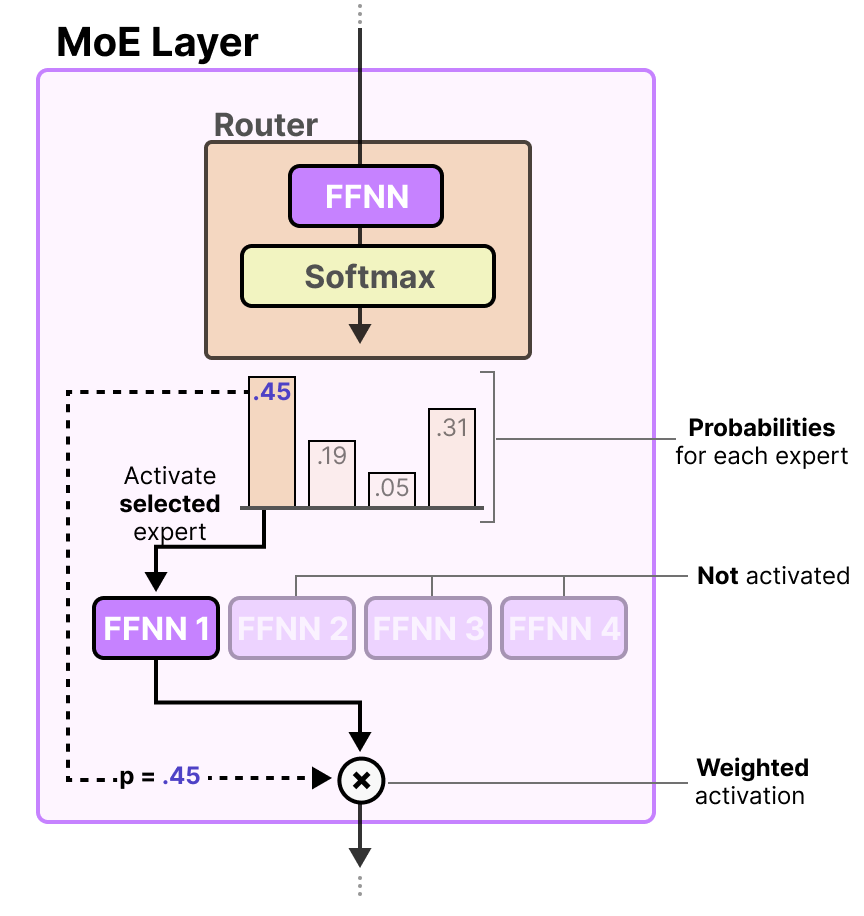
混合专家层(MoE Layer)是什么?路由器与专家(其中仅选定少数)一起构成了混合专家层(MoE Layer)。
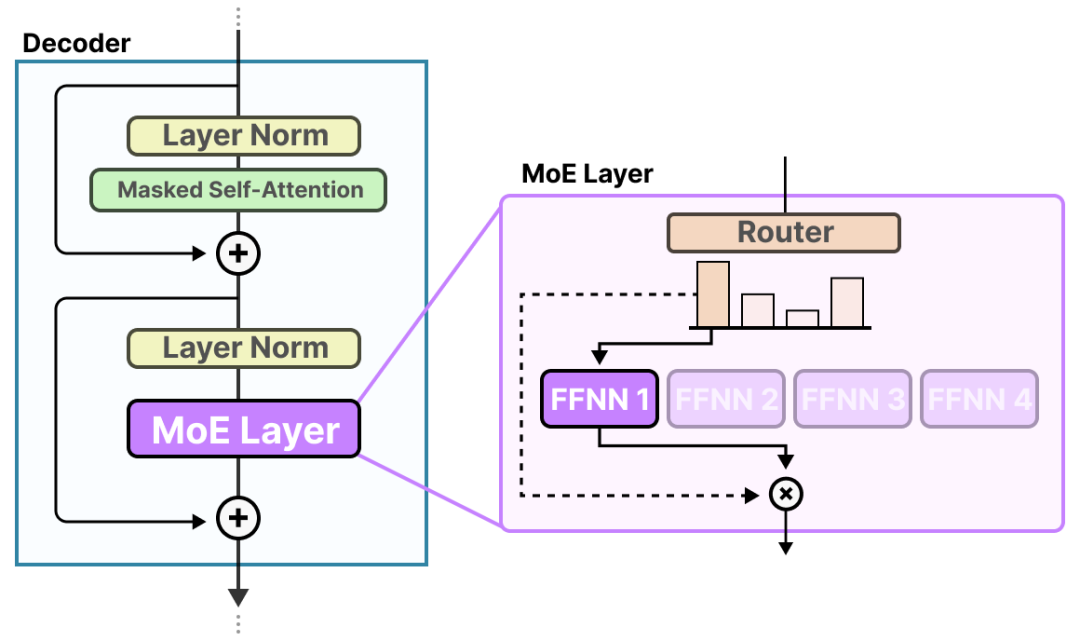
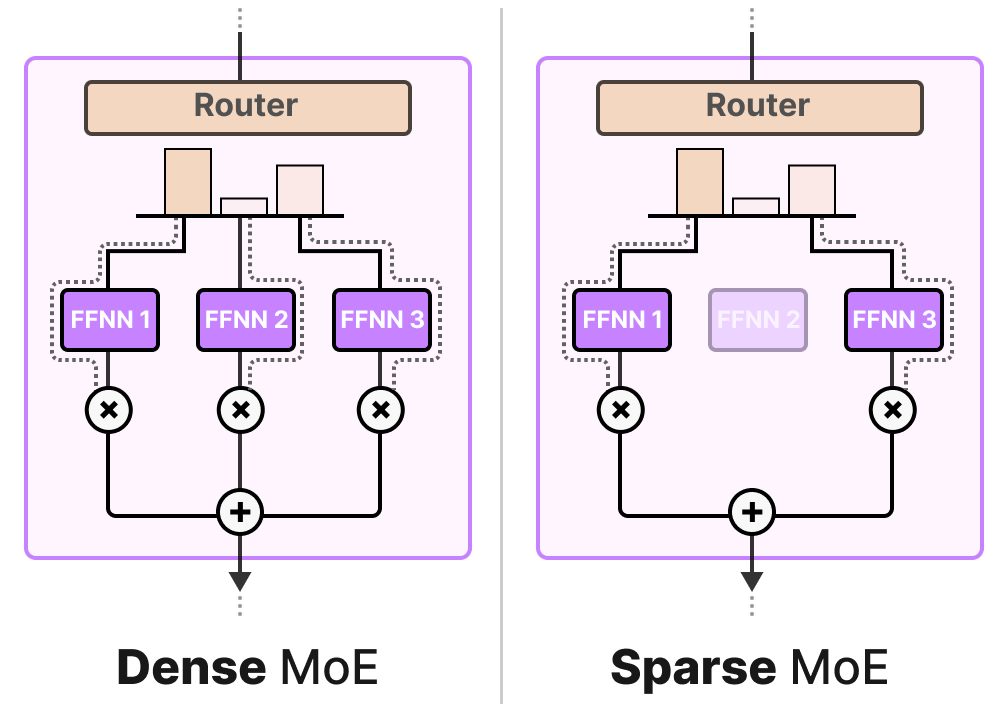
MoE Layer有两种,一种是_稀疏的专家混合(Sparse MoE)_,另一种是_密集_的专家混合(Dense MoE)。
两者都使用路由器来选择专家,但是稀疏混合专家模型通过路由器仅选择少数关键专家处理输入,实现高性能与低计算开销的平衡;而密集混合专家模型则利用路由器激活所有专家,但可能以不同权重分布,以全面捕捉输入数据的多样特征。