网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
4. JDK环境验证
java -version

第六步:安装Hadoop
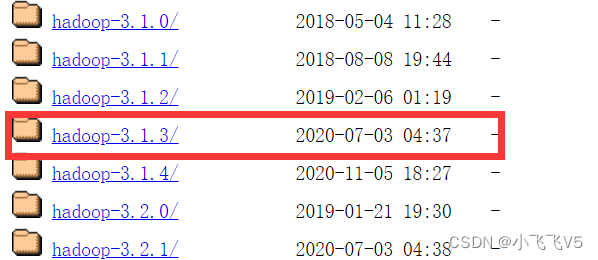
1. 下载Hadoop 3.1.3
2. 安装Hadoop
同样通过mobaxterm的上的SFTP功能(或其他工具)上传到/export/software目录下,然后解压到/export/servers目录下
cd /export/software
mobaxterm的上的SFTP功能
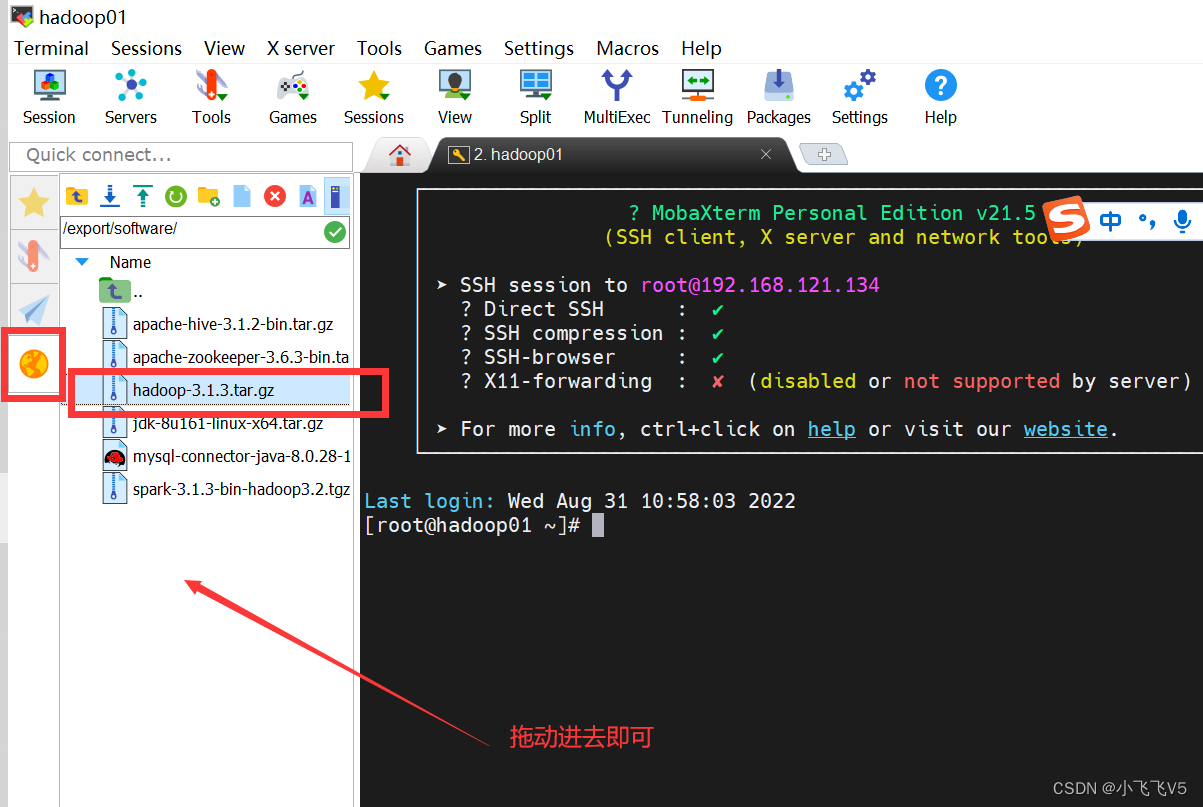
tar -zxvf hadoop-3.1.3.tar.gz -C /export/servers/
3. 配置Hadoop系统环境变量
vim /etc/profile
配置环境变量
export HADOOP_HOME=/export/servers/hadoop-3.1.3
export PATH=: H A D O O P _ H O M E / b i n : HADOOP\_HOME/bin: HADOOP_HOME/bin:HADOOP_HOME/sbin:$PATH
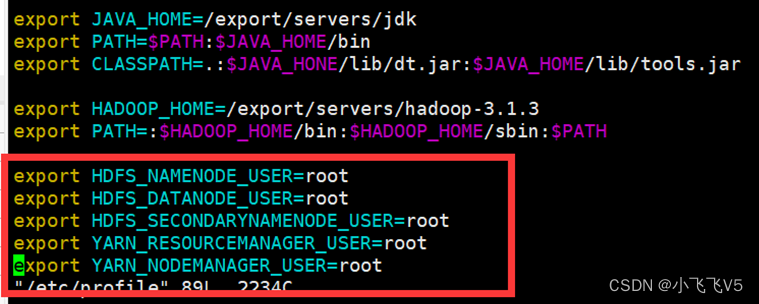
同时添加hadoop为root用户,否则启动的HDFS的时候可能会报错
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

执行source /etc/profile命令,让配置生效
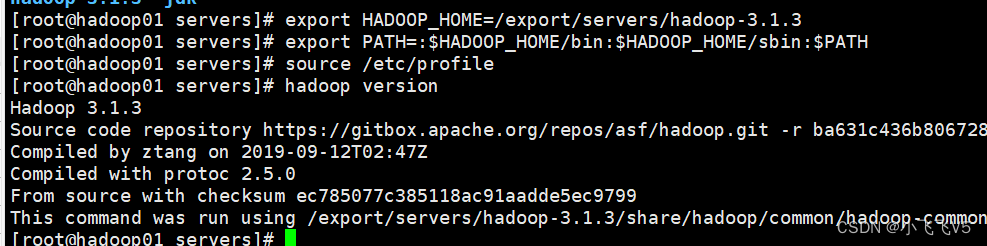
4. 验证Hadoop环境
hadoop version
========================== 快照 ==================================
第七步:Hadoop集群配置
集群配置如下:
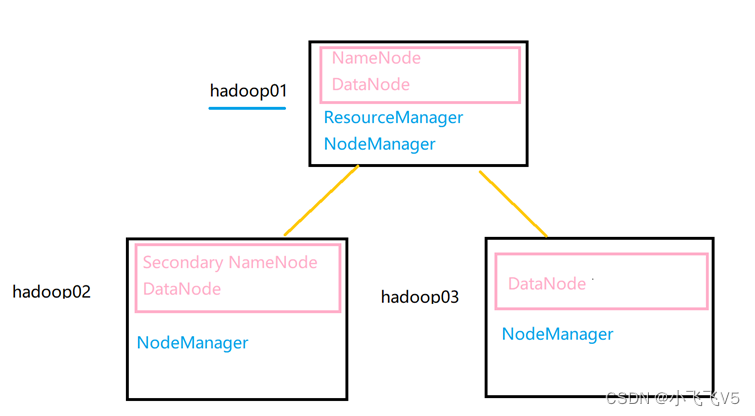
1、配置Hadoop集群主节点
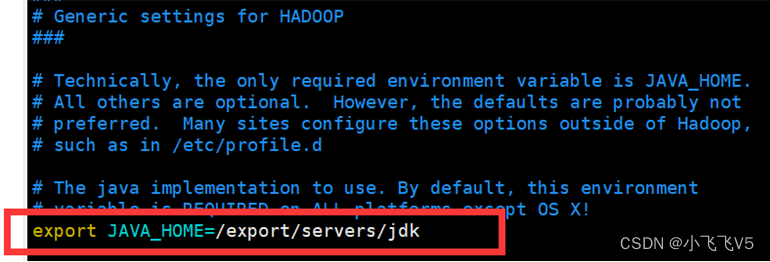
(1)修改hadoop-env.sh文件
cd /export/servers/hadoop-3.1.3/etc/hadoop
vim hadoop-env.sh
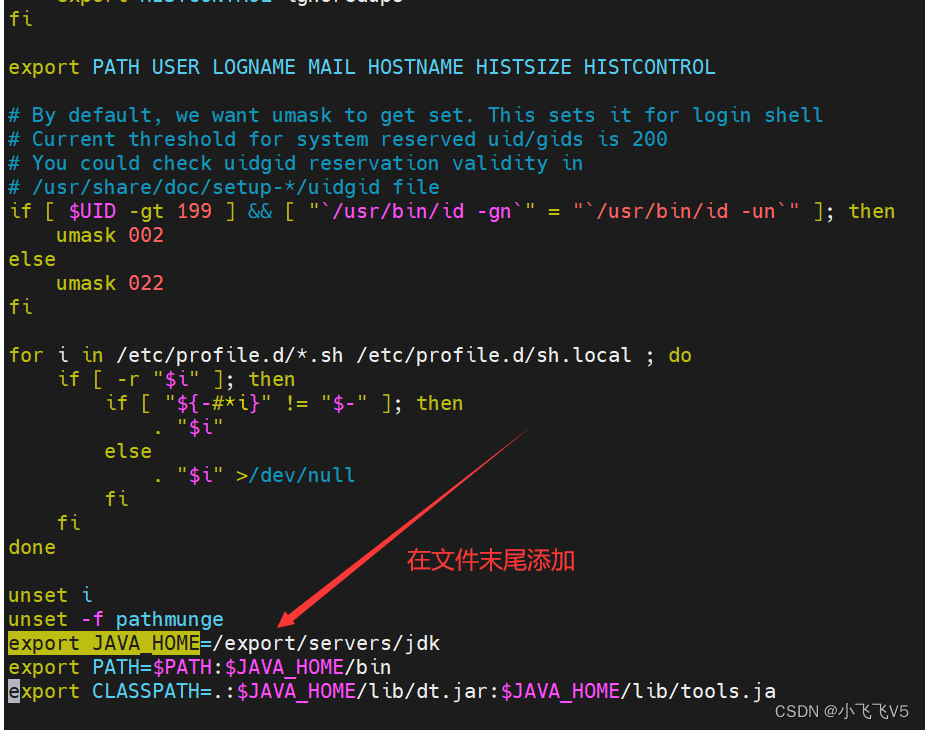
找到export JAVA_HOME的位置修改
export JAVA_HOME=/export/servers/jdk
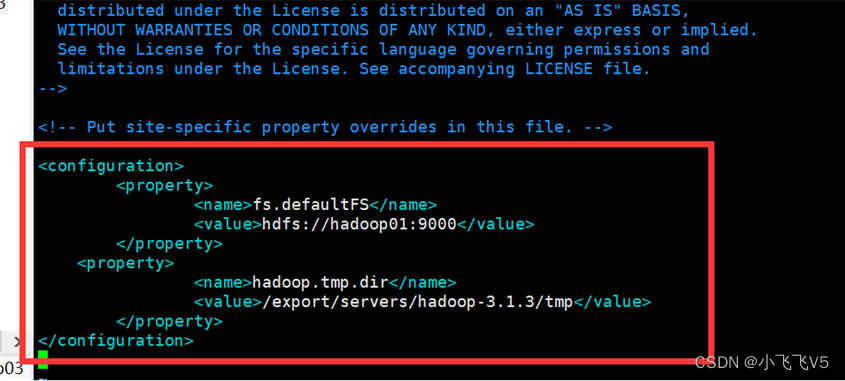
(2)修改core-site.xml文件
主要是配置主进程NameNode的运行主机和运行生成数据的临时目录
vim core-site.xml
写入以下内容
fs.defaultFS
hdfs://hadoop01:9000
hadoop.tmp.dir
/export/servers/hadoop-3.1.3/tmp
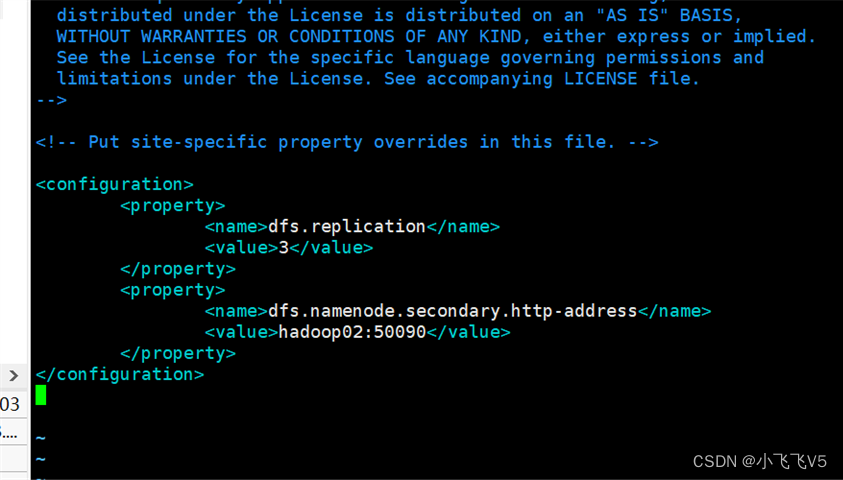
(3)修改hdfs-site.xml文件
设置HDFS数据块的副本数量以及second namenode的地址
vim hdfs-site.xml
写入以下内容
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop02:50090
(4)修改mapred-site.xml文件
设置MapReduce的运行时框架
vim mapred-site.xml
写入以下内容
mapreduce.framework.name
yarn

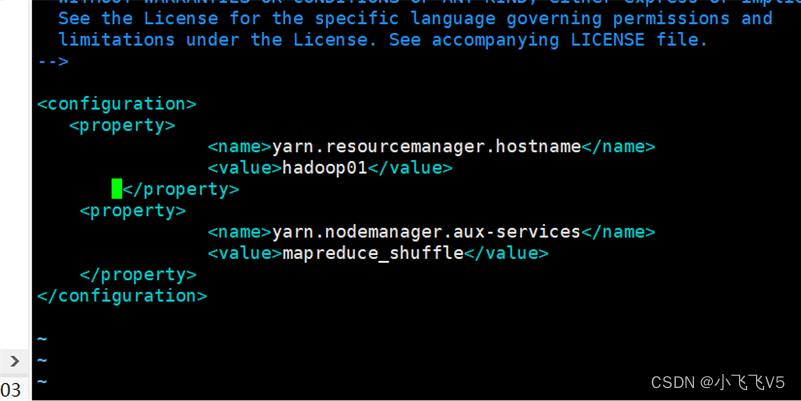
(5)修改yarn-site.xml文件
设置yarn集群的管理者
vim yarn-site.xml
写入以下内容
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services
mapreduce_shuffle
(6)修改workers文件
该文件用来记录从节点的主机名(hadoop 2.x中为slaves文件)
打开该配置文件,先删除里面的内容(默认localhost),然后配置如下内容。
vim workers
删除默认内容,添加以下内容
hadoop01
hadoop02
hadoop03

2、将集群主节点的配置文件分发到其他子节点
完成Hadoop集群主节点hadoop01的配置后,还需要将系统环境配置文件、JDK安装目录和Hadoop安装目录分发到其他子节点hadoop02和hadoop03上,具体指令:
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
传完之后要在hadoop02和hadoop03上分别执行 source /etc/profile 命令,来刷新配置文件
如果使用scp时需要输入密码,请重新检查ssh配置!
第八步:格式化文件系统
初次启动HDFS集群时,必须对主节点进行格式化处理。在hadoop01上执行
格式化文件系统指令如下:
hdfs namenode -format
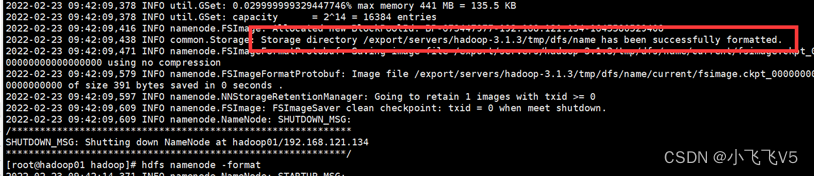
不要多次格式化主节点!
第九步:启动和关闭hadoop集群
脚本一键启动:
hadoop01主节点上执行:
start-dfs.sh
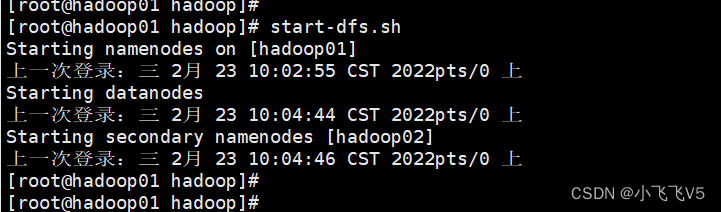
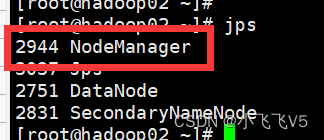
可以通过jps看到
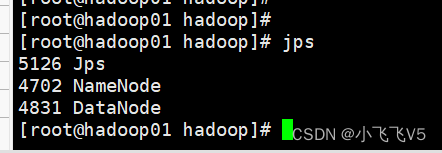
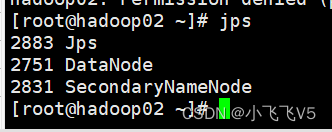
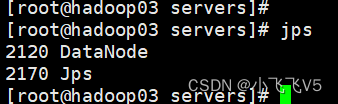
在主节点上执行
start-yarn.sh

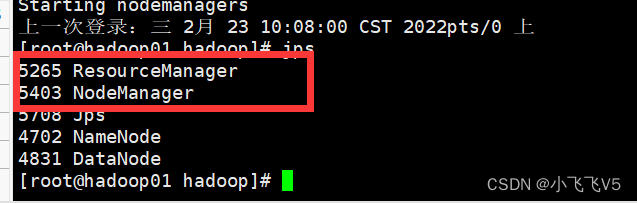

如果想要关闭,输入stop-dfs.sh即可(不要执行)
第十步:通过UI界面查看hadoop运行状态
1. 关闭防火墙功能
在3台虚拟机上均执行以下命令
本次临时关闭防火墙、永久关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
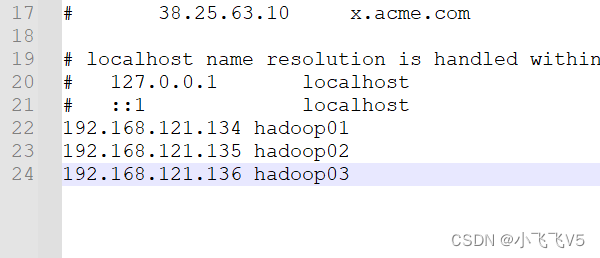
2. 修改windows下ip映射
打开C:\Windows\System32\drivers\etc下的hosts文件,添加以下内容(注:如果没有notepad++这类软件,可以通过记事本保存在其他位置,然后拖动到该文件夹下)
192.168.121.134 hadoop01
192.168.121.135 hadoop02
192.168.121.136 hadoop03
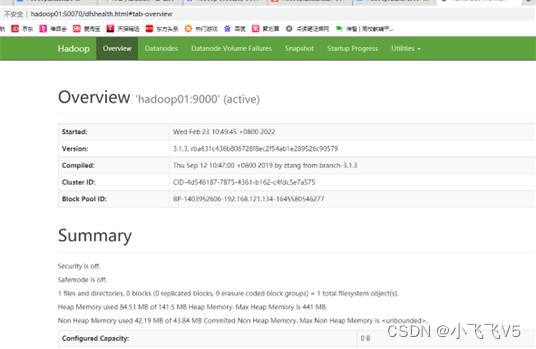
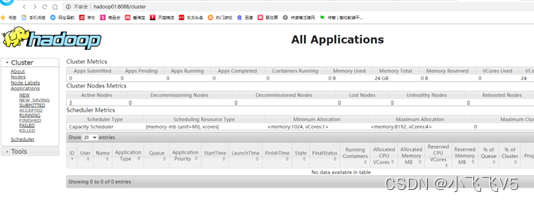
在浏览器输入
http://hadoop01:9870
http://hadoop01:8088
即可访问HDFS和Yarn
========================== 快照 ==================================
第十一步:hadoop集群初体验
统计word.txt中各单词出现的次数
在Hadoop01创建如下目录,并添加测试文件
mkdir -p /export/data
cd /export/data
vi word.txt
写入下列内容
hello world
hello hadoop
hello students

在HDFS上创建 /wordcount/input目录
hadoop fs -mkdir -p /wordcount/input
创建完成后可以在HDFS的网站上看到

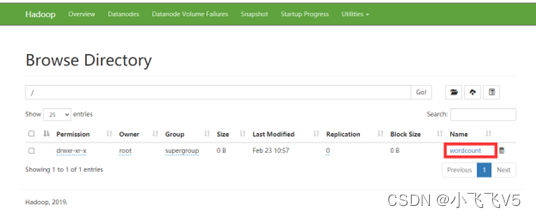
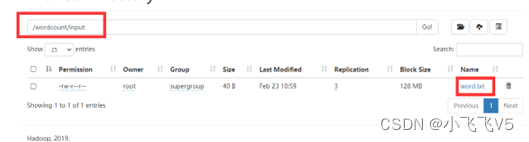
将word.txt上传到该目录下
hadoop fs -put /export/data/word.txt /wordcount/input
执行该程序(参考下文中可能遇到的问题,问题1、2为必现问题,建议直接修改)
cd /export/servers/hadoop-3.1.3/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
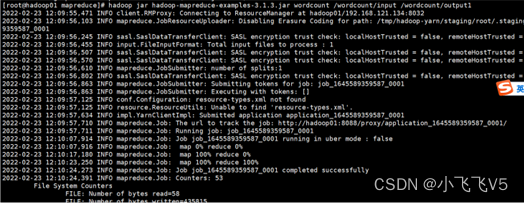
查看结果如下:


注意:
可能遇到的问题1:
找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
解决方法:
输入 hadoop classpath
复制返回的信息
修改yarn-site.xml
cd /export/servers/hadoop-3.1.3/etc/hadoop
vim yarn-site.xml
新增以下内容
yarn.application.classpath
输入刚才返回的Hadoop classpath路径
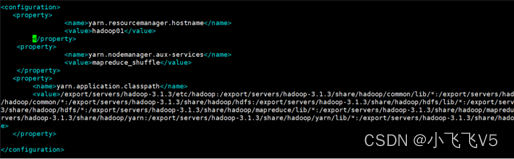
可能遇到的问题2:
Container killed on request. Exit code is 143
解决方法:
cd /export/servers/hadoop-3.1.3/etc/hadoop
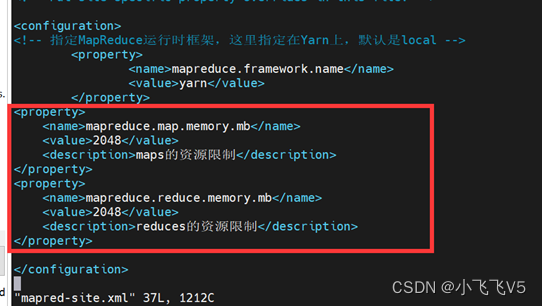
vim mapred-site.xml
mapreduce.map.memory.mb
2048
maps的资源限制
mapreduce.reduce.memory.mb
2048
reduces的资源限制
可能遇到的问题3:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
2048
maps的资源限制
mapreduce.reduce.memory.mb
2048
reduces的资源限制
可能遇到的问题3:
[外链图片转存中…(img-s7jxFCc3-1715241465601)]
[外链图片转存中…(img-AjnmgvmT-1715241465601)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!