分类模型:
二分类和多分类:
对于二分类模型
,我们将介绍逻辑回归和Fisher线性判别分析两种分类算法;
对于多分类模型,我们将简单介绍Spss中的多分类线性判别分析和多分类逻辑回归的操作步骤
二分类:
基于广义线性模型,假设因变量(类别)服从伯努利分布(二分类情况)。它通过构建逻辑函数,将自变量的线性组合映射到[0,1]区间,得到属于某一类别的概率
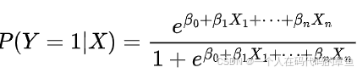
其中Y是类别变量,X是自变量,β是待估计的参数
引例:
根据水果的一些属性来判断水果的类别
| ID | mass | width | height | color_score | fruit_name |
| 1 | 192 | 8.4 | 7.3 | 0.55 | apple |
| 2 | 180 | 8 | 6.8 | 0.59 | apple |
| 3 | 176 | 7.4 | 7.2 | 0.6 | apple |
| 4 | 178 | 7.1 | 7.8 | 0.92 | apple |
| 5 | 172 | 7.4 | 7 | 0.89 | apple |
| 6 | 166 | 6.9 | 7.3 | 0.93 | apple |
| 7 | 172 | 7.1 | 7.6 | 0.92 | apple |
| 8 | 154 | 7 | 7.1 | 0.88 | apple |
| 9 | 164 | 7.3 | 7.7 | 0.7 | apple |
| 10 | 152 | 7.6 | 7.3 | 0.69 | apple |
| 11 | 156 | 7.7 | 7.1 | 0.69 | apple |
| 12 | 156 | 7.6 | 7.5 | 0.67 | apple |
| 13 | 168 | 7.5 | 7.6 | 0.73 | apple |
| 14 | 162 | 7.5 | 7.1 | 0.83 | apple |
| 15 | 162 | 7.4 | 7.2 | 0.85 | apple |
| 16 | 160 | 7.5 | 7.5 | 0.86 | apple |
| 17 | 156 | 7.4 | 7.4 | 0.84 | apple |
| 18 | 140 | 7.3 | 7.1 | 0.87 | apple |
| 19 | 170 | 7.6 | 7.9 | 0.88 | apple |
| 20 | 342 | 9 | 9.4 | 0.75 | orange |
| 21 | 356 | 9.2 | 9.2 | 0.75 | orange |
| 22 | 362 | 9.6 | 9.2 | 0.74 | orange |
| 23 | 204 | 7.5 | 9.2 | 0.77 | orange |
| 24 | 140 | 6.7 | 7.1 | 0.72 | orange |
| 25 | 160 | 7 | 7.4 | 0.81 | orange |
| 26 | 158 | 7.1 | 7.5 | 0.79 | orange |
| 27 | 210 | 7.8 | 8 | 0.82 | orange |
| 28 | 164 | 7.2 | 7 | 0.8 | orange |
| 29 | 190 | 7.5 | 8.1 | 0.74 | orange |
| 30 | 142 | 7.6 | 7.8 | 0.75 | orange |
| 31 | 150 | 7.1 | 7.9 | 0.75 | orange |
| 32 | 160 | 7.1 | 7.6 | 0.76 | orange |
| 33 | 154 | 7.3 | 7.3 | 0.79 | orange |
| 34 | 158 | 7.2 | 7.8 | 0.77 | orange |
| 35 | 144 | 6.8 | 7.4 | 0.75 | orange |
| 36 | 154 | 7.1 | 7.5 | 0.78 | orange |
| 37 | 180 | 7.6 | 8.2 | 0.79 | orange |
| 38 | 154 | 7.2 | 7.2 | 0.82 | orange |
二元逻辑回归
这里的y就是水果的类别,这里是Apple和orange,x就是mass,weight等等
接下来使用spss来进行逻辑回归
spss操作
1,生成虚拟变量:
如果apple就是1
不是apple就是0
2,使用spss进行二元逻辑回归
这里的原理就是极大似然估计
(分析->回归->二元logic回归)
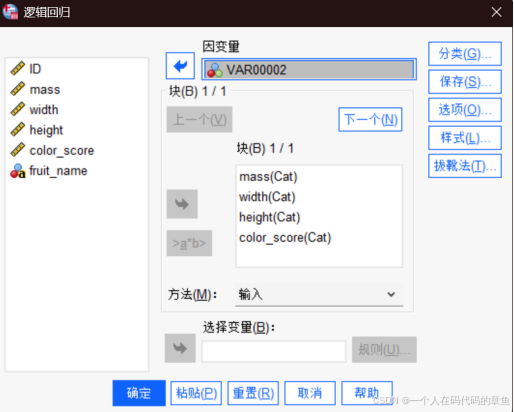
紧接着对协变量进行分类;
如果有一些变量是定性变量,那么就要在这里面进行设置
选中那些定性变量,让他们表示为指示符
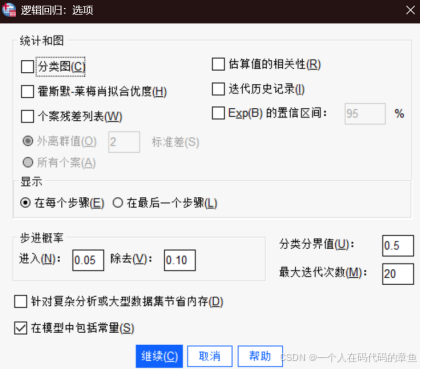
上面的如果是向前回归,就是0.05,向后的就是除去的概率就是0.1,基本不用调整什么
自助抽样运用于少量数据的时候
直接进行回归
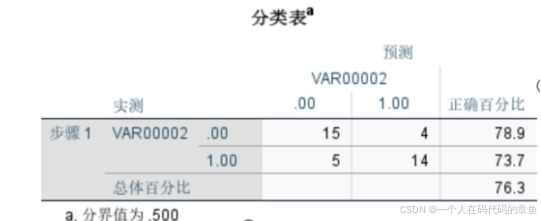
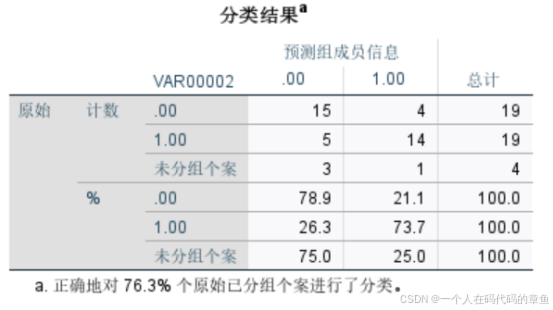
这里告诉我们预测总体的预测正确率有76.3%
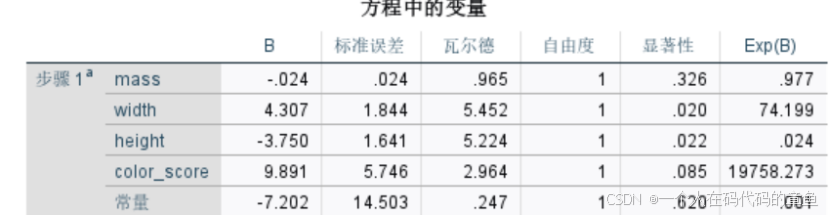
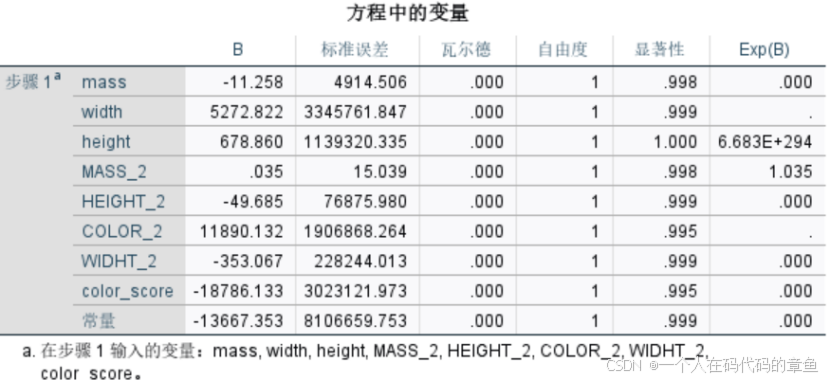
这里显著的只有width和height
针对新的数据进行预测,用到的是下面的公式
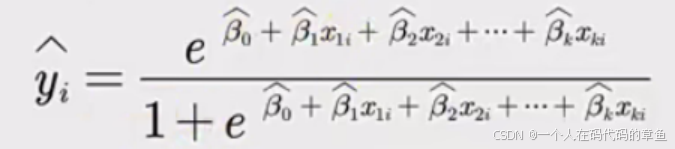
也就是
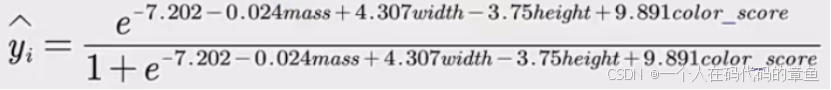
如何提高预测的准确率:
加入平方项和交互项目,
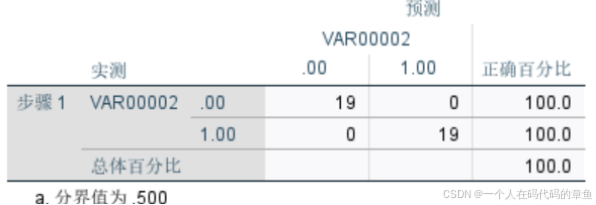
这样提高了预测的准确性,但是导致了每一个变量都不再显著了
(过拟合),只是对样本预测的好,但是不能代表对样本外的数据也有这样的预测准确性
所以可以80%作为训练组,20%为测试组,这样根据训练后的对测试组进行预测(手动扣掉已经知道的值)
假设条件
二元逻辑回归:
1对自变量的分布没有严格要求,可以是连续变量、离散变量或二者混合。
2假设观测值之间相互独立,即每个样本的取值不受其他样本的影响。
3要求自变量与对数几率(logit)之间存在线性关系,即
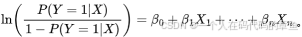
Fisher线性判别分析
是一种经典的有监督的线性降维与分类方法,由罗纳德・费希尔(Ronald A. Fisher)提出。它的主要思想是找到一个最优的投影方向,将高维数据投影到低维空间,使得不同类别的数据在投影后能够尽可能地分开,同时同一类别的数据尽可能紧凑。
让他们在投影点上尽可能集中,不同的类的投影点中心尽可能的远离
它通过最大化类间散度与类内散度的比值(即 Fisher 准则函数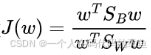
Spss软件的操作
分析里面的分类的判别式
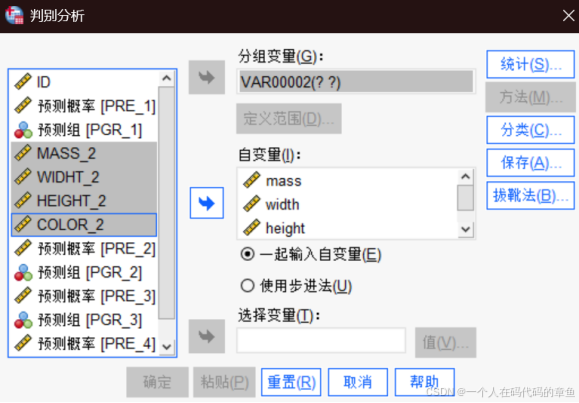
然后定义范围,在这里是 0-1

统计需要统计我们的费希尔判别系数和未标准化
分类
保存

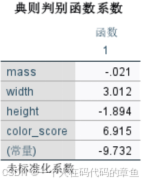
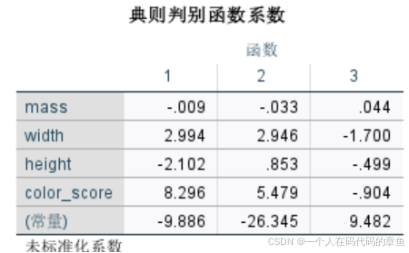
下面是未标准化的w系数
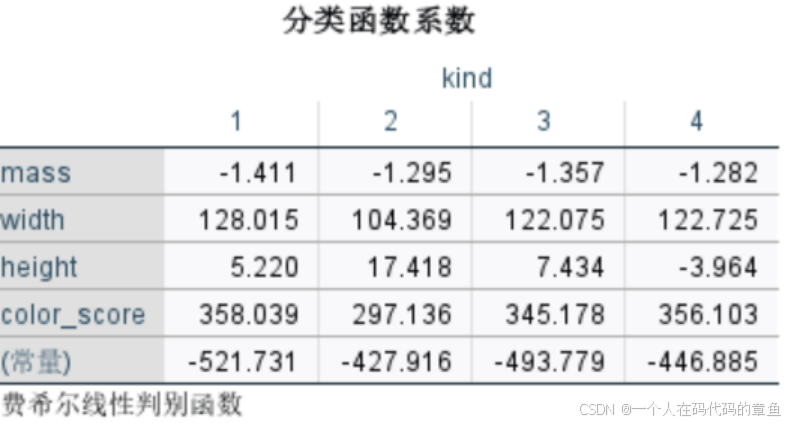
最后会给出两列尺度,第一列表示属于0的概率,第二列表示属于1的概率
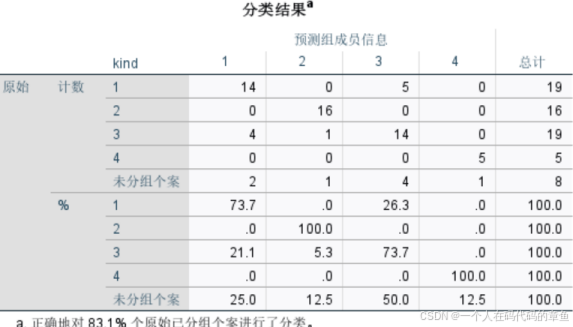
最后的结果
假设条件:
Fisher 判别分析:
1通常假设各类数据服从正态分布,且各类数据的协方差矩阵相等。在这些假设下,Fisher 判别分析能达到较好的效果。
2数据的特征之间具有线性关系,因为它是基于线性投影进行分类的。v
多分类问题:
| ID | mass | width | height | color_score | fruit_name | kind |
| 1 | 192 | 8.4 | 7.3 | 0.55 | apple | 1 |
| 2 | 180 | 8 | 6.8 | 0.59 | apple | 1 |
| 3 | 176 | 7.4 | 7.2 | 0.6 | apple | 1 |
| 4 | 178 | 7.1 | 7.8 | 0.92 | apple | 1 |
| 5 | 172 | 7.4 | 7 | 0.89 | apple | 1 |
| 6 | 166 | 6.9 | 7.3 | 0.93 | apple | 1 |
| 7 | 172 | 7.1 | 7.6 | 0.92 | apple | 1 |
| 8 | 154 | 7 | 7.1 | 0.88 | apple | 1 |
| 9 | 164 | 7.3 | 7.7 | 0.7 | apple | 1 |
| 10 | 152 | 7.6 | 7.3 | 0.69 | apple | 1 |
| 11 | 156 | 7.7 | 7.1 | 0.69 | apple | 1 |
| 12 | 156 | 7.6 | 7.5 | 0.67 | apple | 1 |
| 13 | 168 | 7.5 | 7.6 | 0.73 | apple | 1 |
| 14 | 162 | 7.5 | 7.1 | 0.83 | apple | 1 |
| 15 | 162 | 7.4 | 7.2 | 0.85 | apple | 1 |
| 16 | 160 | 7.5 | 7.5 | 0.86 | apple | 1 |
| 17 | 156 | 7.4 | 7.4 | 0.84 | apple | 1 |
| 18 | 140 | 7.3 | 7.1 | 0.87 | apple | 1 |
| 19 | 170 | 7.6 | 7.9 | 0.88 | apple | 1 |
| 20 | 194 | 7.2 | 10.3 | 0.7 | lemon | 2 |
| 21 | 200 | 7.3 | 10.5 | 0.72 | lemon | 2 |
| 22 | 186 | 7.2 | 9.2 | 0.72 | lemon | 2 |
| 23 | 216 | 7.3 | 10.2 | 0.71 | lemon | 2 |
| 24 | 196 | 7.3 | 9.7 | 0.72 | lemon | 2 |
| 25 | 174 | 7.3 | 10.1 | 0.72 | lemon | 2 |
| 26 | 132 | 5.8 | 8.7 | 0.73 | lemon | 2 |
| 27 | 130 | 6 | 8.2 | 0.71 | lemon | 2 |
| 28 | 116 | 6 | 7.5 | 0.72 | lemon | 2 |
| 29 | 118 | 5.9 | 8 | 0.72 | lemon | 2 |
| 30 | 120 | 6 | 8.4 | 0.74 | lemon | 2 |
| 31 | 116 | 6.1 | 8.5 | 0.71 | lemon | 2 |
| 32 | 116 | 6.3 | 7.7 | 0.72 | lemon | 2 |
| 33 | 116 | 5.9 | 8.1 | 0.73 | lemon | 2 |
| 34 | 152 | 6.5 | 8.5 | 0.72 | lemon | 2 |
| 35 | 118 | 6.1 | 8.1 | 0.7 | lemon | 2 |
| 36 | 342 | 9 | 9.4 | 0.75 | orange | 3 |
| 37 | 356 | 9.2 | 9.2 | 0.75 | orange | 3 |
| 38 | 362 | 9.6 | 9.2 | 0.74 | orange | 3 |
| 39 | 204 | 7.5 | 9.2 | 0.77 | orange | 3 |
| 40 | 140 | 6.7 | 7.1 | 0.72 | orange | 3 |
| 41 | 160 | 7 | 7.4 | 0.81 | orange | 3 |
| 42 | 158 | 7.1 | 7.5 | 0.79 | orange | 3 |
| 43 | 210 | 7.8 | 8 | 0.82 | orange | 3 |
| 44 | 164 | 7.2 | 7 | 0.8 | orange | 3 |
| 45 | 190 | 7.5 | 8.1 | 0.74 | orange | 3 |
| 46 | 142 | 7.6 | 7.8 | 0.75 | orange | 3 |
| 47 | 150 | 7.1 | 7.9 | 0.75 | orange | 3 |
| 48 | 160 | 7.1 | 7.6 | 0.76 | orange | 3 |
| 49 | 154 | 7.3 | 7.3 | 0.79 | orange | 3 |
| 50 | 158 | 7.2 | 7.8 | 0.77 | orange | 3 |
| 51 | 144 | 6.8 | 7.4 | 0.75 | orange | 3 |
| 52 | 154 | 7.1 | 7.5 | 0.78 | orange | 3 |
| 53 | 180 | 7.6 | 8.2 | 0.79 | orange | 3 |
| 54 | 154 | 7.2 | 7.2 | 0.82 | orange | 3 |
| 55 | 86 | 6.2 | 4.7 | 0.8 | mandarin | 4 |
| 56 | 84 | 6 | 4.6 | 0.79 | mandarin | 4 |
| 57 | 80 | 5.8 | 4.3 | 0.77 | mandarin | 4 |
| 58 | 80 | 5.9 | 4.3 | 0.81 | mandarin | 4 |
| 59 | 76 | 5.8 | 4 | 0.81 | mandarin | 4 |
Fisher判别分析
spss处理:
分析->分类->判别式
其他的统计,分类和保存的选择和之前的一样
下面是结果:
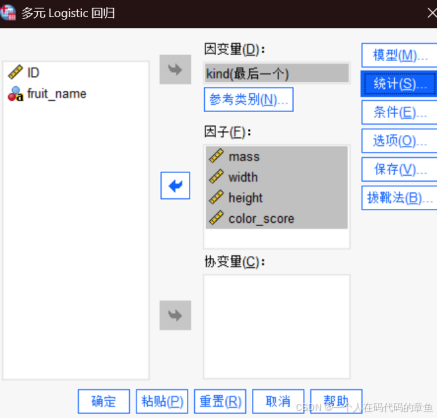
多元逻辑回归
spss操作:
分析->回归->多元逻辑回归
检测出来100%正确率
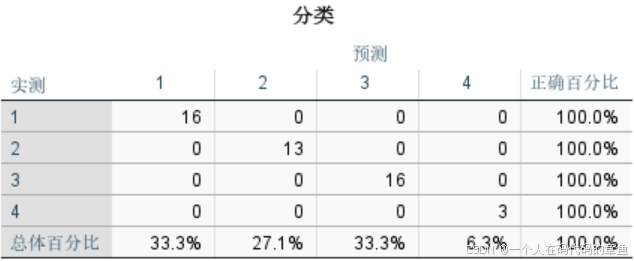
感觉有过拟合的问题,挑10%作为测试组,发现模型的预测准确率是100%,但是测试组的准确率是5/11,不到一半
所以有明显的过拟合的现象