(注:文末扫码获取AI工具安装包和AI学习资料)
以下是正文部分
在上一篇里我已经为大家介绍了关于ControlNet的基本功能、安装和使用技巧,相信大家对这款神级插件已经有了基本认识,今天我会为大家更详细的介绍14种官方控图模型的差异和使用技巧,以及最近刚面向SDXL更新的社区模型。
01
官方模型和社区模型
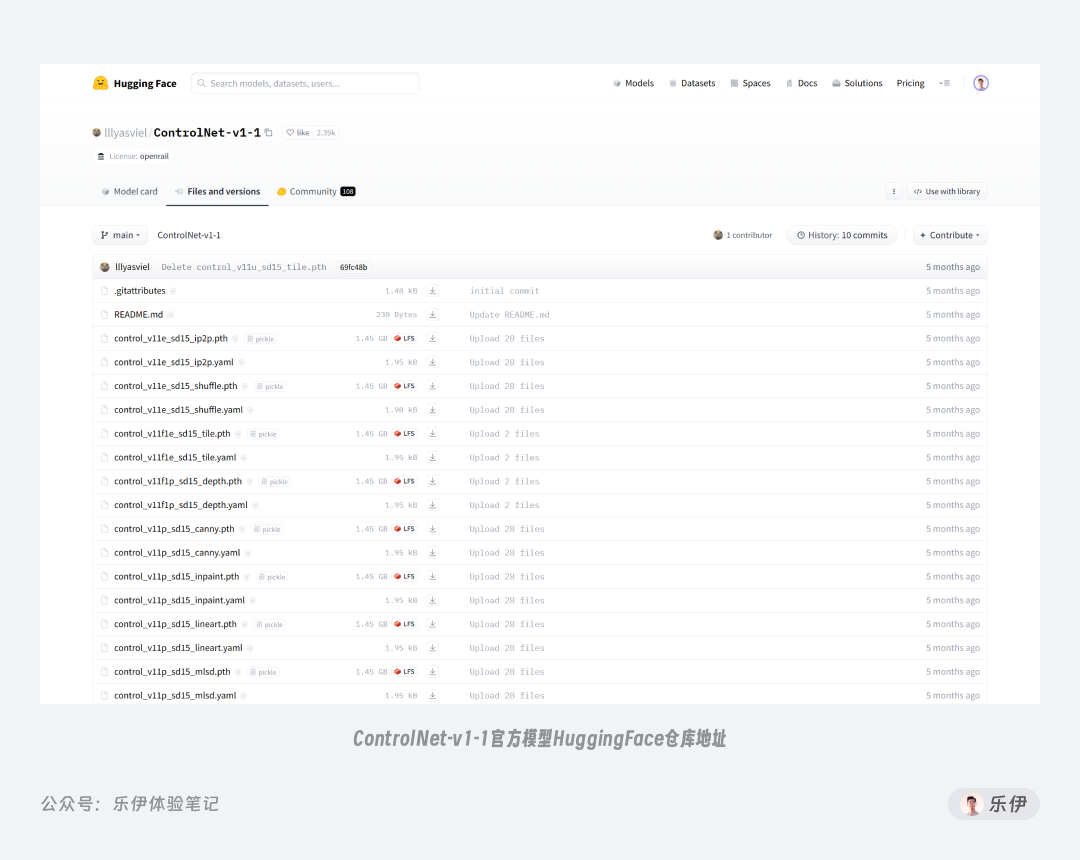
前文我们提到 ControlNet 模型是由张吕敏开源的,目前开源的模型包括以下这 14 种,作为 ControlNet 的布道者,我们可以将这些称之为经典的官方模型。
官方模型下载地址:https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
虽然官方模型很强,但最近新的 SDXL 大模型发布后还没有做适配,之前的 ControlNet 插件也基本都是配合 SD1.5 模型来使用,加上 SDXL 对硬件的要求颇高,导致 SDXL 系列模型无法使用 ControlNet 控图一直是广大SD玩家的痛点。
而这段时间里,社区里不少热心开发者训练出了不少针对 SDXL 使用的 ControlNet 模型,就在前几天 ControlNet 插件更新到 v1.1.400 版本后,终于支持配合 SDXL 模型来使用。为方便大家使用,ControlNet 的作者张吕敏将这些社区模型都统一镜像在 HuggingFace 的代码仓库中,有需要的朋友可以自行下载使用:
社区 ControlNet 模型下载地址:https://huggingface.co/lllyasviel/sd_control_collection/tree/main

这类社区模型虽然没有完全遵照官方模型的命名规则,但也能从名称上看出模型的类型,比如xl表示是针对SDXL使用的模型,sai表示 StabilityAI 开发的模型,其中也有一些无需 ControlNet 模型也能使用,比如revision (SDXL)和reference (SDXL)。
02
官方模型解析
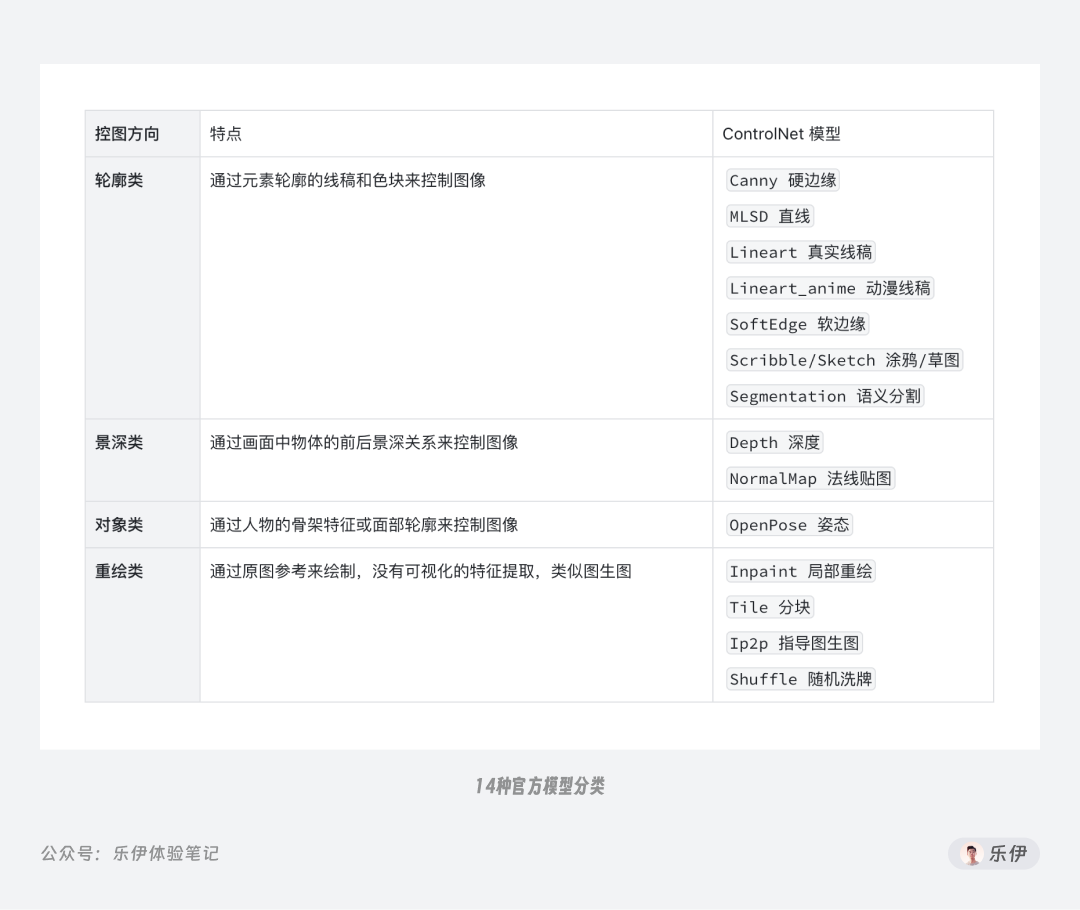
我们先来了解下最基础的官方模型,最早时候开源的模型只有depth、hed、normal、scribble、seg、openpose、mlsd、canny这 8 种,随着这半年的迭代已经更新到 14 种之多。每种模型都有各自的特点,对新手来说想每个都完全记住实在有点困难,因此这里我按照模型的控图方向分为 4 种类型,分别是轮廓类、景深类、对象类和重绘类。
在下面的内容中我会为大家仔细介绍每种 ControlNet 的特点和差异,并配上展示效果图,但案例样本较少所以并不能排除绘图模型本身的影响,大家重点学习模型的控图特点和使用场景即可。
2.1 轮廓类
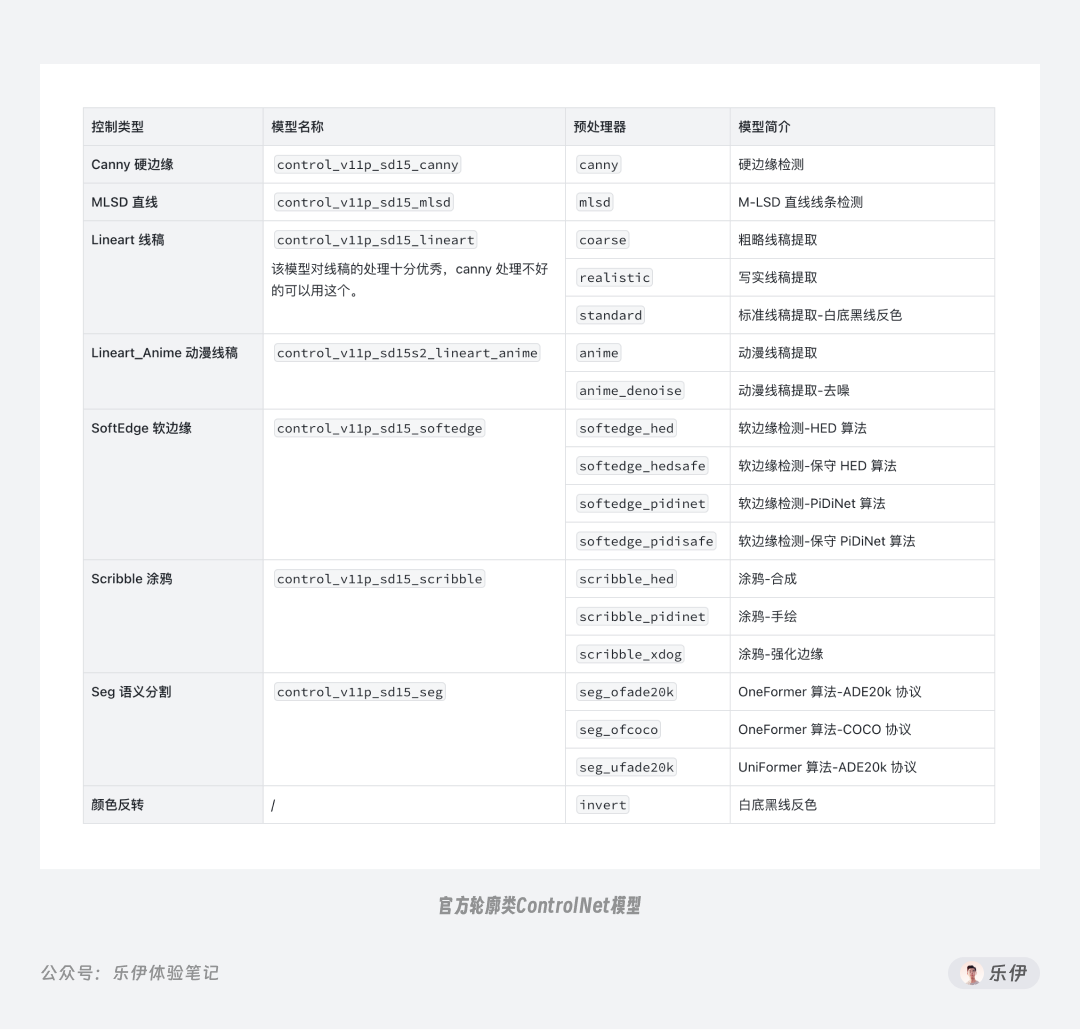
顾名思义,轮廓类指的是通过元素轮廓来限制画面内容,轮廓类模型有Canny 硬边缘、MLSD 直线、Lineart 真实线稿、Lineart_anime 动漫线稿、SoftEdge 软边缘、Segmentation 语义分割、Shuffle 随机洗牌这7种,且每种模型都配有相应的预处理器,由于算法和版本差异,同一模型可能提供多种预处理器供用户自行选择。
2.1.1 Canny硬边缘
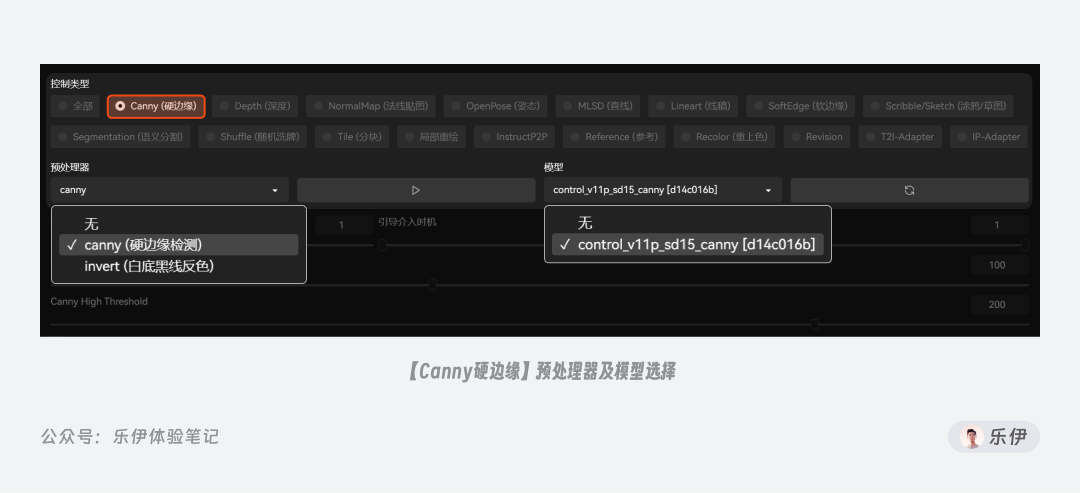
我们先来看看第一种控制类型:Canny 硬边缘,它的使用范围很广,被作者誉为最重要的(也许是最常用的)ControlNet 之一,该模型源自图像处理领域的边缘检测算法,可以识别并提取图像中的边缘特征并输送到新的图像中。
Canny 中只包含了canny(硬边缘检测)这一种预处理器。下图中我们可以看到,canny可以准确提取出画面中元素边缘的线稿,即使配合不同的主模型进行绘图都可以精准还原画面中的内容布局。

在选择预处理器时,我们可以看到除了canny(硬边缘检测)还有invert(白底黑线反色)的预处理器选项,它的功能并非是提取图像的空间特征,而是将线稿进行颜色反转。我们通过 Canny 等线稿类的预处理器提取得到的预览图都是黑底白线,但大部分的传统线稿都是白底黑线,为方便使用,很多时候我们需要将两者进行颜色转换,传统做法都是导出到 PS 等工具进行额外处理,非常繁琐。而 ControlNet 中贴心的内置了颜色反转的预处理功能,可以轻松实现将手绘线稿转换成模型可识别的预处理线稿图。
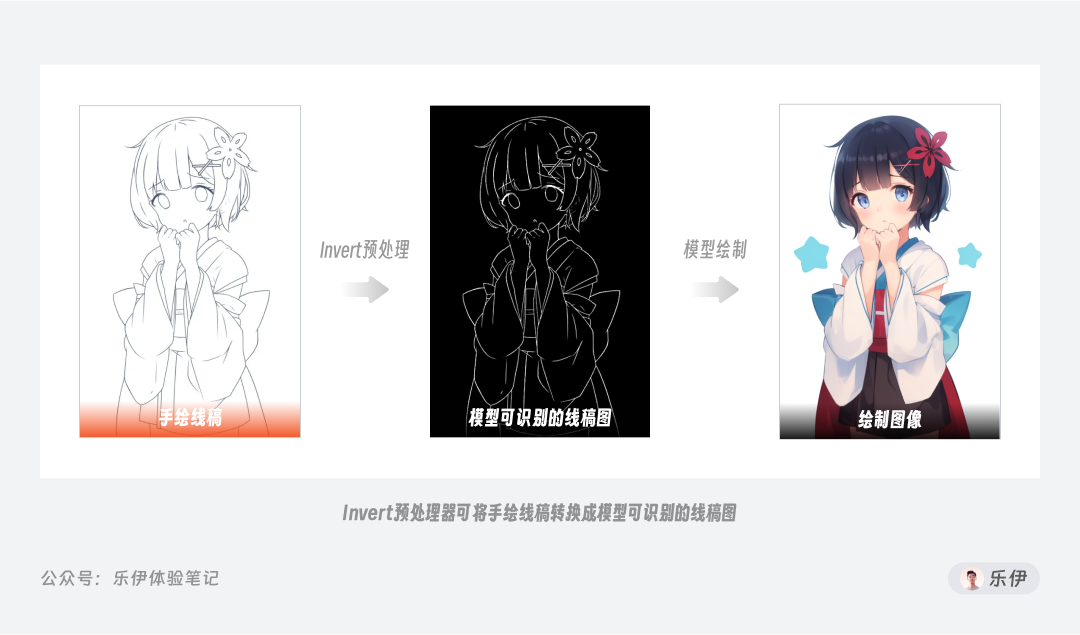
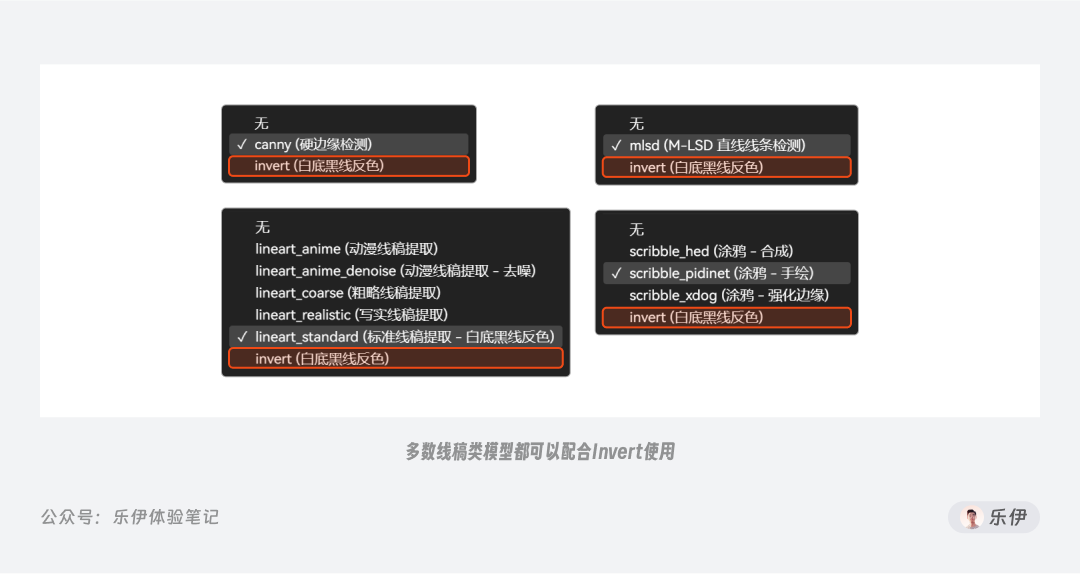
理解了invert的功能,我们就知道该预处理器并非 Canny 独有,而是**可以配合大部分线稿模型使用。**在最新版的 ControlNet 中,当我们选择 MLSD 直线、Lineart 线稿等控制类型时,预处理器中都能看到它的身影,后续就不挨个赘述了。
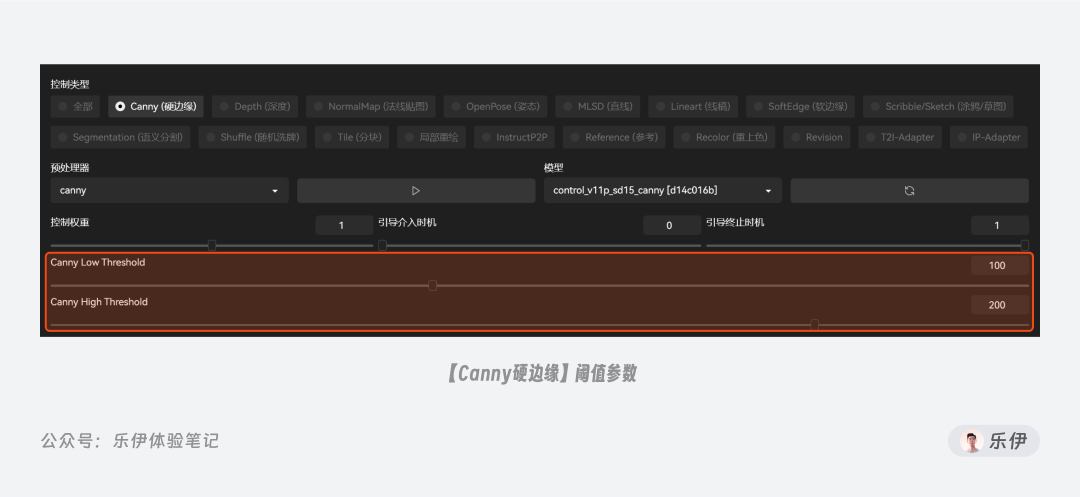
有些预处理器在选择后,下方会多出用于调节特征提取效果的特定参数,比如当我们选择canny(硬边缘检测)时,下方会增加Canny low threshold 低阈值和 Canny high threshold 高阈值2 项参数。
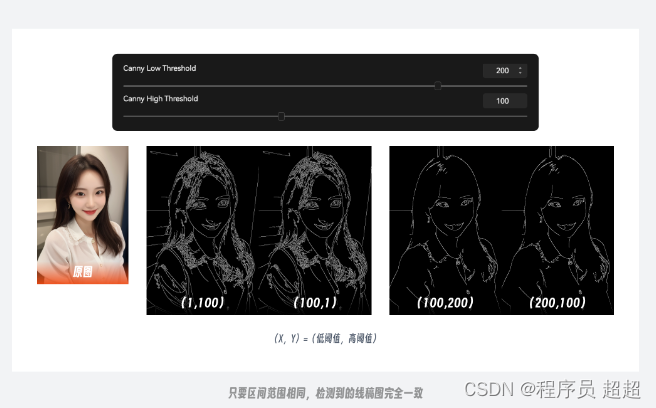
先给大家解释下关于 canny 阈值参数的控制原理,以便你更好的理解其使用方法。在使用 canny 进行预处理时,提取的图像像素边缘线会被 2 个阈值参数划分为强边缘、弱边缘和非边缘 3 类,其中强边缘会直接保留,而非边缘的线稿会被忽略,处于中间弱边缘范围的线稿则会进行计算筛选。
以下面这张图为例,预处理过程中检测到 3 条边缘线,其中 D 点位于非边缘区域,因此直接被排除,而 A 点位于强边缘区域被保留。虽然 B、C 点都位于弱边缘区域,但由于 B 点和 A 点是直接相连的,因此 B 点也被保留,而与 C 点相连的线全都位于弱边缘区域所以被排除。由此得到画面中最终被保留的边缘线只有 AB 这条线。

理解了上面的概念,你也就知道**阈值参数控制的实际上是边缘线被识别的区间范围,只要区间一致最终的线稿图就会完全一样。**因此高低阈值参数之间实际上并没有高低之分,低阈值的数值同样可以比高阈值要大。
总结来看,Canny 高低阈值参数作用是控制预处理时提取线稿的复杂程度,两者的数值范围都限制在 1~255 之间。
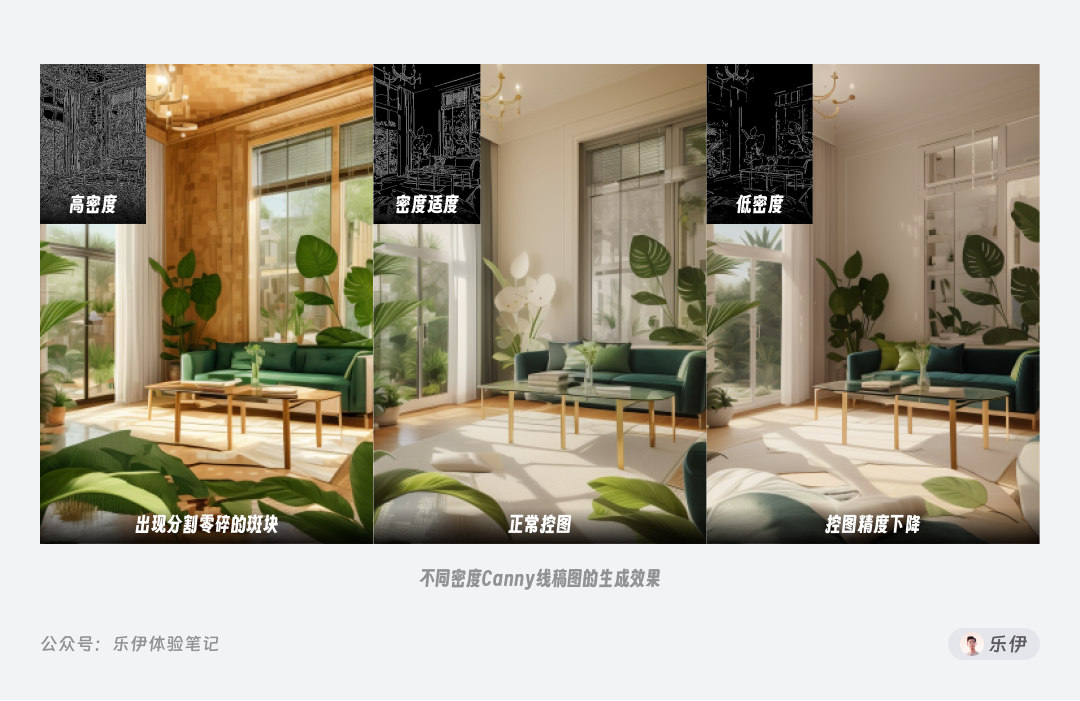
下图中我们可以看到不同密度的预处理线稿图对绘图结果的影响,密度过高会导致绘图结果中出现分割零碎的斑块,但如果密度太低又会造成控图效果不够准确,因此我们需要调节阈值参数来达到比较合适的线稿控制范围。
2.1.2 MLSD直线边缘
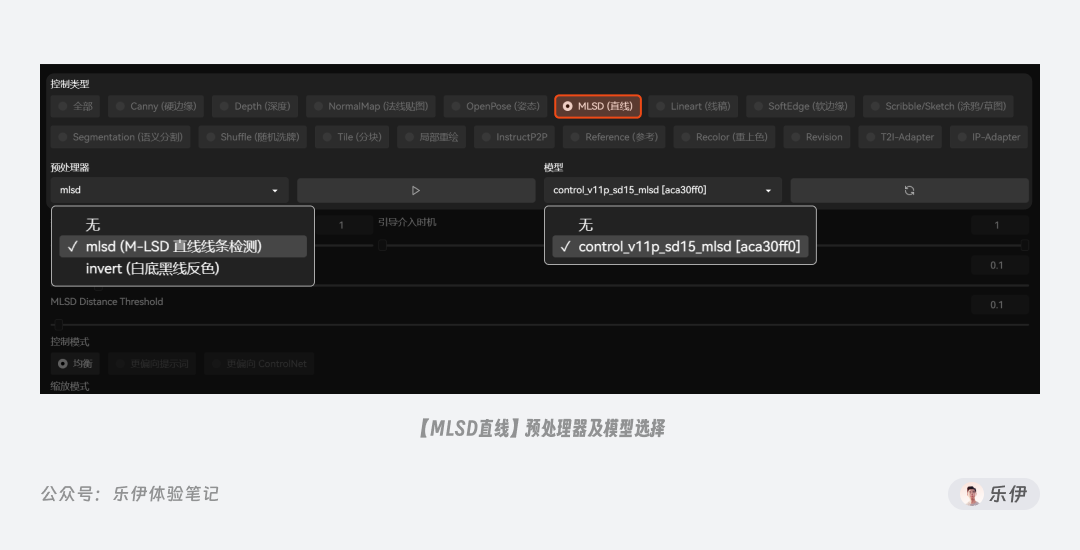
下面我们再来看第二种控图类型:MLSD 直线。MLSD 提取的都是画面中的直线边缘,在下图中可以看到mlsd(M-LSD直线线条检测)预处理后只会保留画面中的直线特征,而忽略曲线特征。

因此 MLSD 多用于提取物体的线型几何边界,最典型的就是几何建筑、室内设计、路桥设计等领域。

MLSD 预处理器同样也有自己的定制参数,分别是MLSD Value Threshold 强度阈值和MLSD Distance Threshold 长度阈值。MLSD 阈值控制的是 2 个不同方向的参数:强度和长度,它们的数值范围都是 0~20 之间。
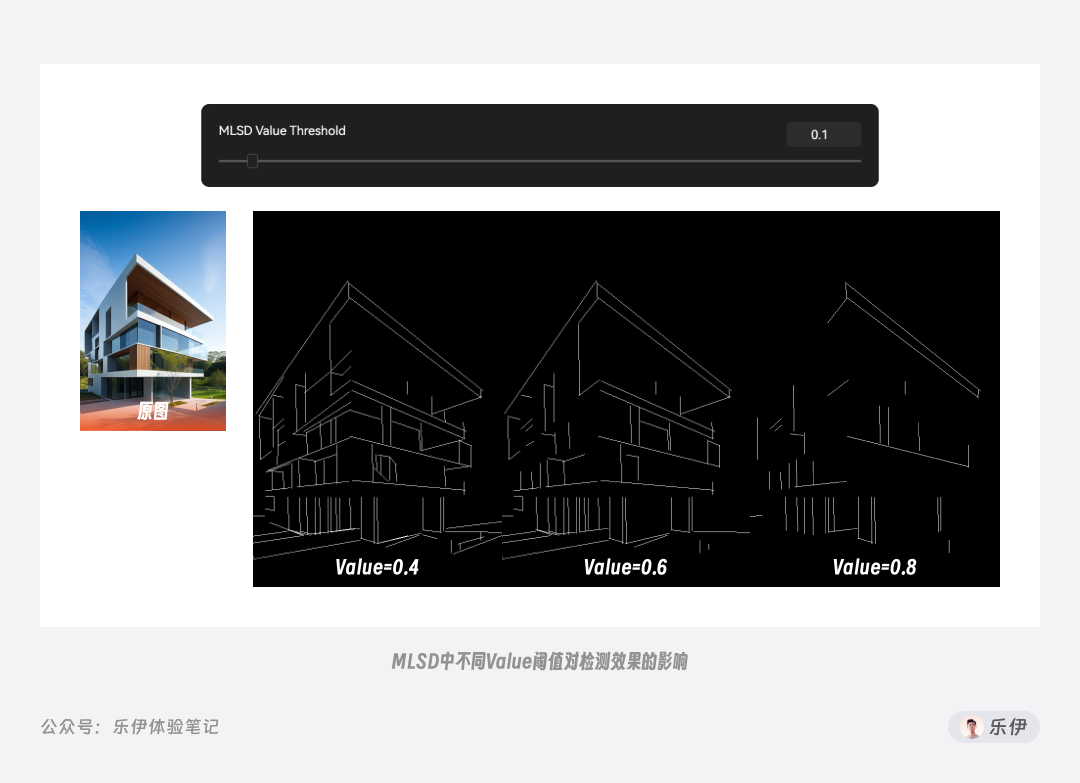
**Value 强度阈值用于筛选线稿的直线强度,简单来说就是过滤掉其他没那么直的线条,只保留最直的线条。**通过下面的图我们可以看到随着 Value 阈值的增大,被过滤掉的线条也就越多,最终图像中的线稿逐渐减少。
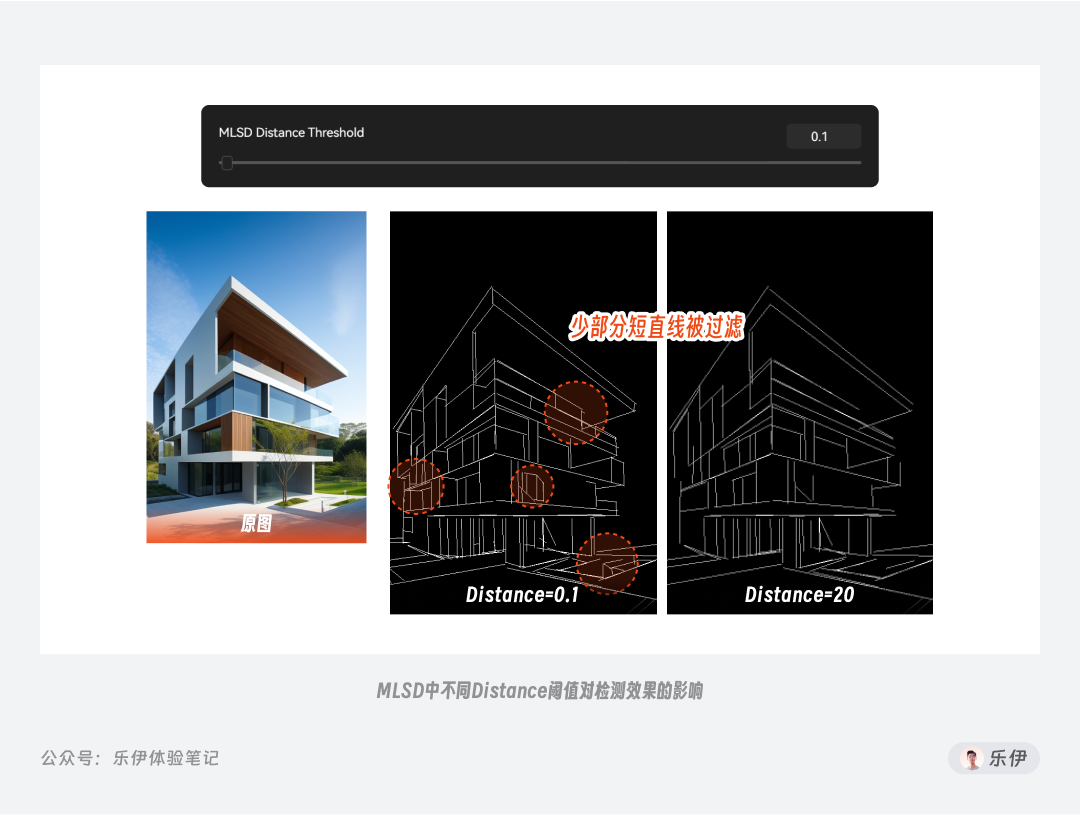
**Distance 长度阈值则用于筛选线条的长度,即过短的直线会被筛选掉。**在画面中有些被识别到的短直线不仅对内容布局和分析没有太大帮助,还可能对最终画面造成干扰,通过长度阈值可以有效过滤掉它们。不过该参数对线稿密度的影响没有那么明显,在下图中可以看到在极值情况下会有少部分线条被过滤掉。
2.1.3 Lineart线稿
Lineart 同样也是对图像边缘线稿的提取,但它的使用场景会更加细分,包括Realistic真实系和Anime动漫系 2 个方向。
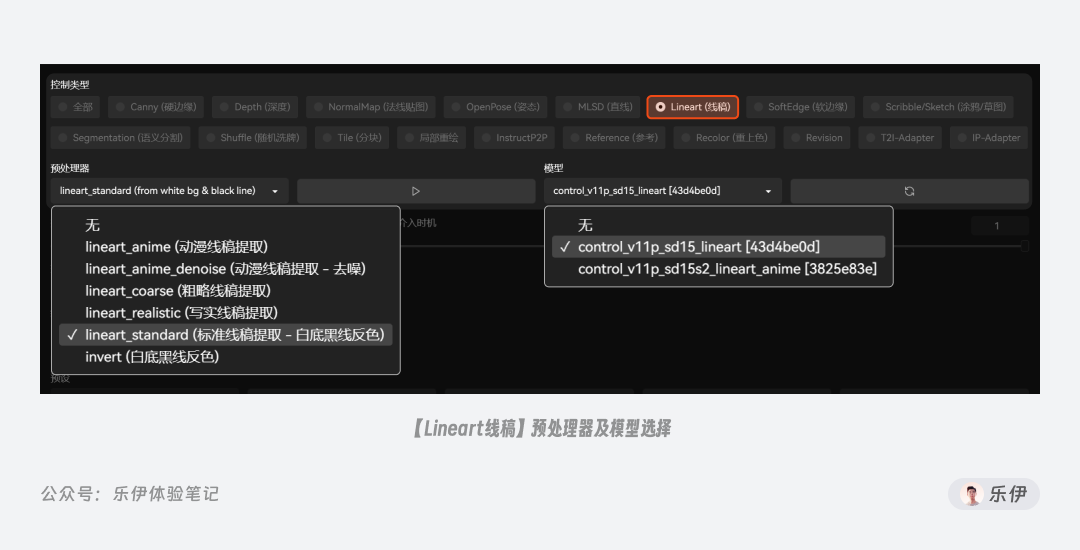
在 ControlNet 插件中,将lineart和lineart_anime2 种控图模型都放在【Lineart(线稿)】控制类型下,分别用于写实类和动漫类图像绘制,配套的预处理器也有 5 个之多,其中带有anime字段的预处理器用于动漫类图像特征提取,其他的则是用于写实图像。
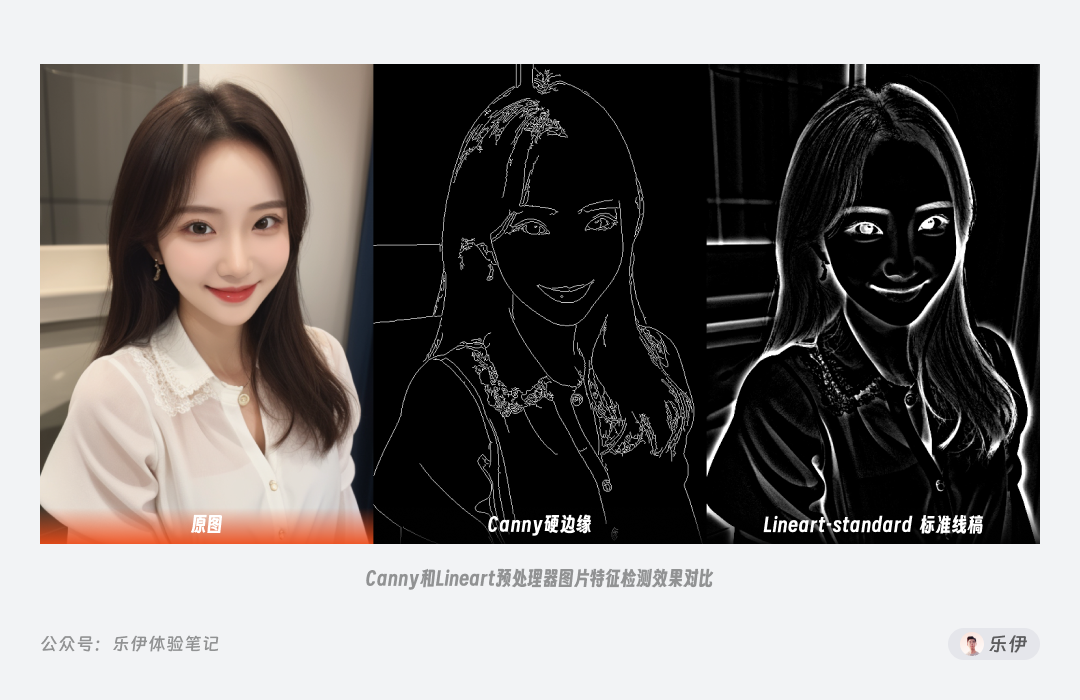
在下图中我们可以看到,Canny 提取后的线稿类似电脑绘制的硬直线,粗细统一都是 1px 大小,而 Lineart 则是有的明显笔触痕迹线稿,更像是现实的手绘稿,可以明显观察到不同边缘下的粗细过渡。
虽然官方将 Lineart 划分为 2 种风格类型,但并不意味着他们不能混用,实际上我们可以根据效果需求自由选择不同的绘图类型处理器和模型。
下图中为大家展示了不同预处理器对写实类照片上的处理效果,可以发现后面 3 种针对真实系图片使用的预处理器**coarse、realistic、standard提取的线稿更为还原,在检测时会保留较多的边缘细节,因此控图效果会更加显著,而anime、anime_denoise****这 2 种动漫类则相对比较随机。**具体效果在不同场景下各有优劣,大家酌情选择使用。

为方便对比模型的控图效果,选用一张更加清晰的手绘线稿图分别使用lineart和lineart_anime模型进行绘制,可以发现**lineart_anime模型在参与绘制时会有更加明显的轮廓线,这种处理方式在二次元动漫中非常常见,传统手绘中描边可以有效增强画面内容的边界感,对色彩完成度的要求不高,因此轮廓描边可以替代很多需要色彩来表现的内容,并逐渐演变为动漫的特定风格。可以看出lineart_anime相比lineart**确实更适合在绘制动漫系图像时使用。

2.1.4 SoftEdge软边缘

Soft Edge 是一种比较特殊的边缘线稿提取方法,它的特点是可以提取带有渐变效果的边缘线条,由此生成的绘图结果画面看起来会更加柔和且过渡自然。

在 SoftEdge 中提供了 4 种不同的预处理器,分别是HED、HEDSafe、PiDiNet和PiDiNetSafe。
在官方介绍的性能对比中,模型稳定性排名为PiDiNetSafe > HEDSafe > PiDiNet > HED,而最高结果质量排名HED > PiDiNet > HEDSafe > PiDiNetSafe,综合考虑后PiDiNet被设置为默认预处理器,可以保证在大多数情况下都能表现良好。在下图中我们可以看到 4 种预处理器的实际检测图对比。

下图中分别使用不同预处理器进行绘图效果对比,体感上没有太大差异,正常情况下使用默认的PiDiNet即可。

2.1.5 Scribble涂鸦边缘
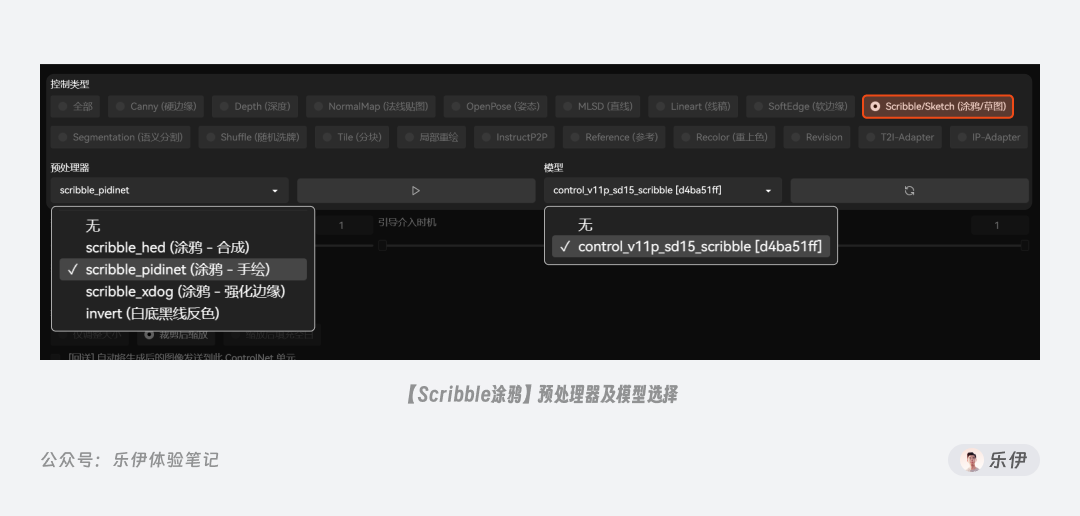
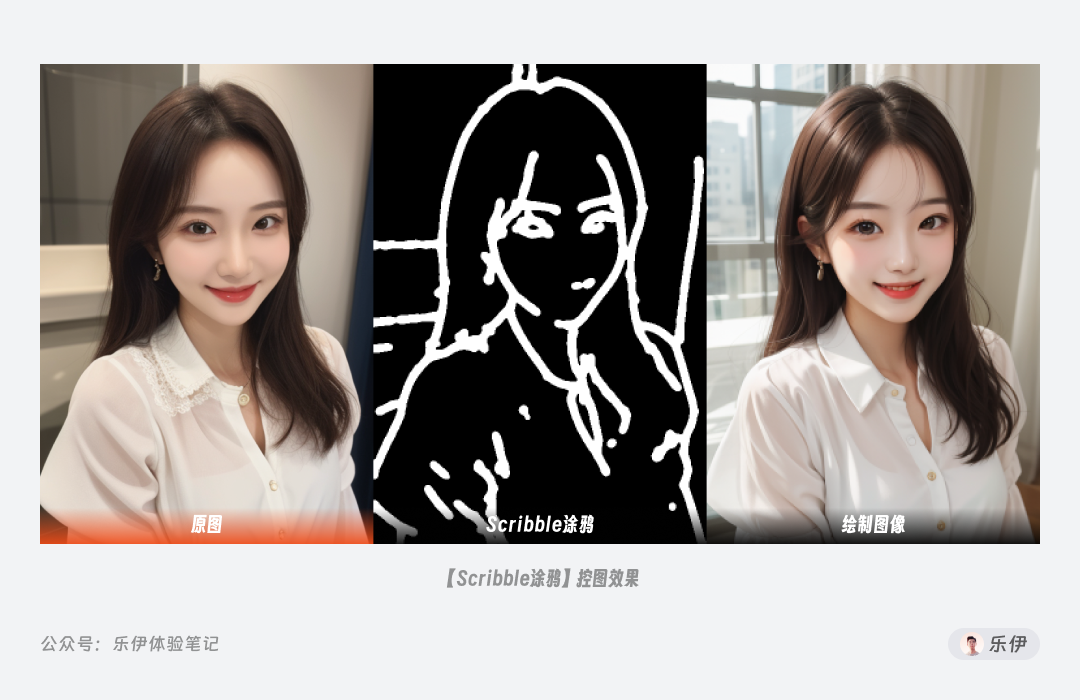
Scribble 涂鸦,也可称作 Sketch 草图,同样是一款手绘效果的控图类型,但它检测生成的预处理图更像是蜡笔涂鸦的线稿,在控图效果上更加自由。
Scribble 中也提供了 3 种不同的预处理器可供选择,分别是HED、PiDiNet和XDoG。通过下图我们可以看到不同 Scribble 预处理器的图像效果,由于HED和PiDiNet是神经网络算法,而XDoG是经典算法,因此前两者检测得到的轮廓线更粗,更符合涂鸦的手绘效果。

再来看看选择不同预处理器的实际出图效果,可以发现这几种预处理器基本都能保持较好的线稿控制。

2.1.6 Seg语义分割

Segmentation 的完整名称是 Semantic Segmentation 语义分割,很多时候简称为 Seg。和以上其他线稿类控制类型不同,它可以在检测内容轮廓的同时将画面划分为不同区块,并对区块赋予语义标注,从而实现更加精准的控图效果。

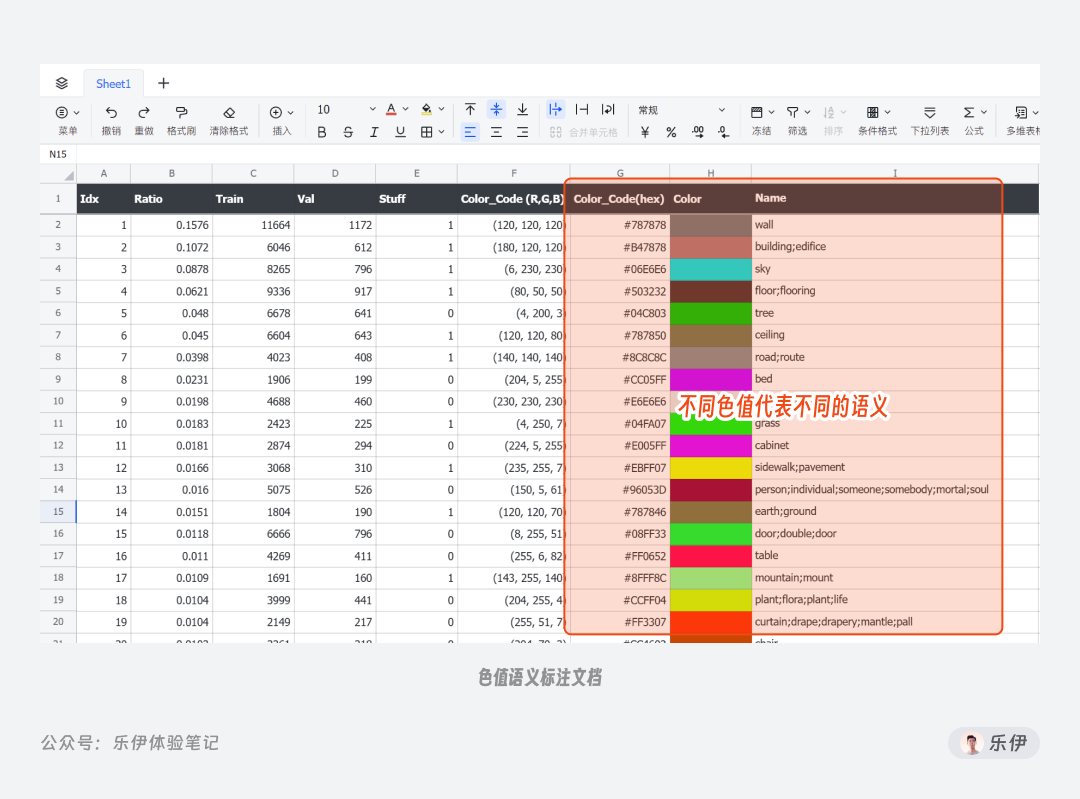
观察下图我们可以看到,Seg 预处理器检测后的图像包含了不同颜色的板块图,就像现实生活中的区块地图。画面中不同的内容会被赋予相应的颜色,比如人物被标注为红色、屋檐是绿色、路灯是蓝色等,这样限定区块的方式有点类似局部重绘的效果,在生成图像时模型会在对应色块范围内生成特定对象,从而实现更加准确的内容还原。

针对不同颜色色值表示的含义,我这边已经为大家整理好完整的色值语义标注文档,需要的小伙伴可以在文章结尾处获取。
Seg 也提供了三种预处理器可供选择:OneFormer ADE20k、 OneFormer COCO、 UniFormer ADE20k。尾缀ADE20k和COCO代表模型训练时使用的 2 种图片数据库,而前缀OneFormer和UniFormer表示的是算法。

其中UniFormer是旧算法,但由于实际表现还不错依旧被作者作为备选项保留下来,新算法OneFormer经过作者团队的训练可以很好的适配各种生产环境,元素间依赖关系被很好的优化,平时使用时建议大家使用默认的**OneFormer ADE20k**即可。

再来看看不同预处理器的实际出图效果,这里我们将环境由白天切换到黑夜,可以发现由于算法数据库不同,可识别的物体会稍有差异,比如第二种算法OneFormer COCO对书店雨棚的还原效果不是很好。实际使用时大家也可以根据语义数据表自行填充色块来标识对应的画面元素。
2.2 景深类
前面的轮廓类都是在二维平面角度的图像检测,有没有可以体现三维层面的控图类型呢?这就不得不提景深类 ControlNet 模型了。景深一词是指图像中物体和镜头之间的距离,简单来说这类模型可以体现元素间的前后关系,包括Depth深度和NormalMap法线贴图这 2 种老牌模型。

2.2.1 Depth 深度
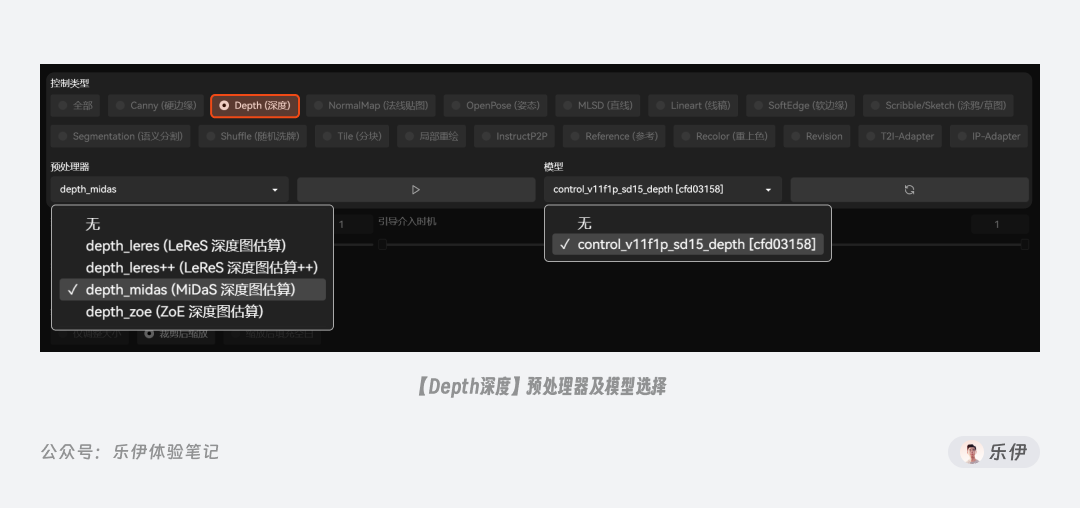
深度图也被称为距离影像,可以将从图像采集器到场景中各点的距离(深度)作为像素值的图像,它可以直接体现画面中物体的三维深度关系。学习过三维动画知识的朋友应该听说过深度图,该类图像中只有黑白两种颜色,距离镜头越近则颜色越浅(白色),距离镜头越近则颜色越深(黑色)。

Depth 模型可以提取图像中元素的前后景关系生成深度图,再将其复用到绘制图像中,因此当画面中物体前后关系不够清晰时,可以通过 Depth 模型来辅助控制。下图中可以看到通过深度图很好的还原了建筑中的空间景深关系。
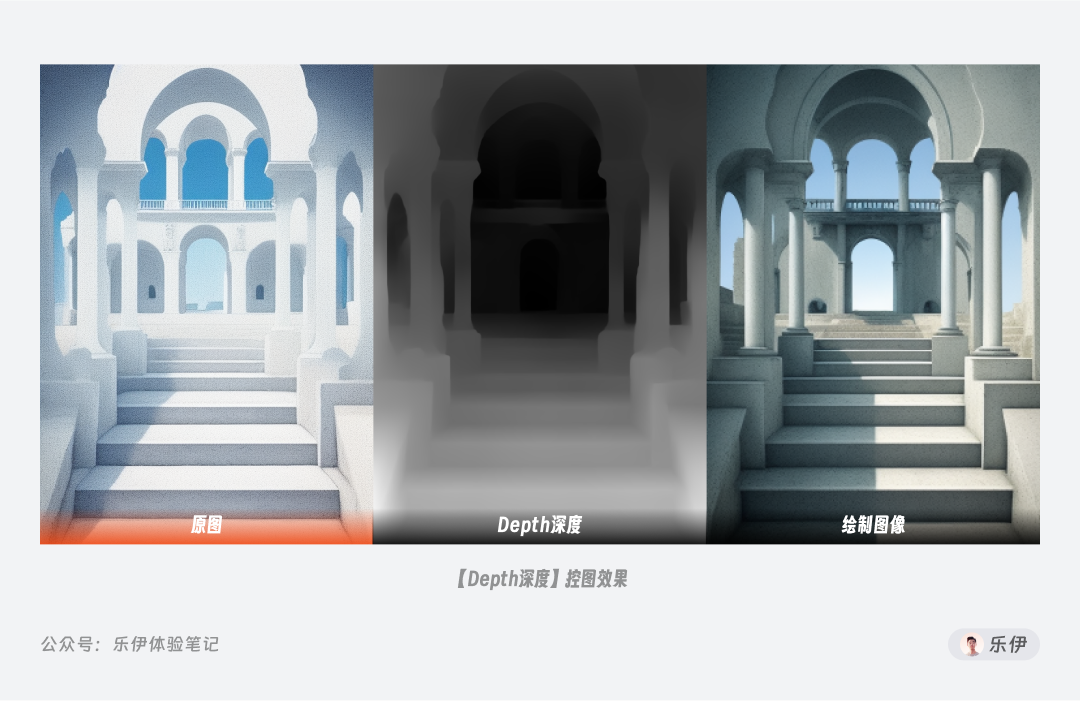
Depth 的预处理器有四种:LeReS、LeReS++、MiDaS、ZoE,下图中我们可以看到这四种预处理器的检测效果。
对比来看,LeReS和LeReS++的深度图细节提取的层次比较丰富,其中LeReS++会更胜一筹。而MiDaS和ZoE更适合处理复杂场景,其中ZoE的参数量是最大的,所以处理速度比较慢,实际效果上更倾向于强化前后景深对比。

根据预处理器算法的不同,Depth在最终成像上也有差异,下面案例中可以看到MiDaS算法可以比较完美的还原场景中的景深关系,实际使用时大家可以根据预处理的深度图来判断哪种深度关系呈现更加合适。

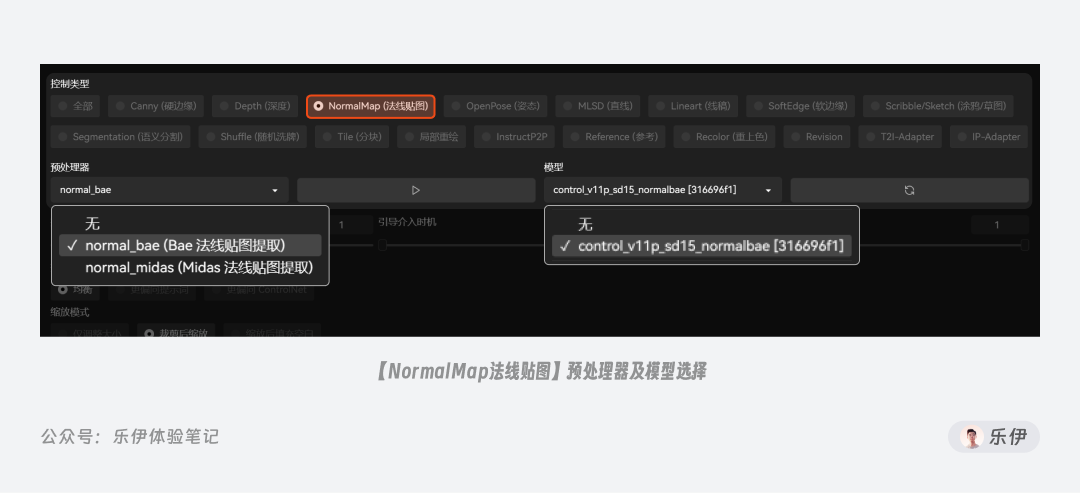
2.2.2 NormalMap法线贴图
另一种可以体现景深关系的图像叫 NormalMap 法线贴图,要理解它的工作原理,我们需要先回顾下法线的概念。
我们在中学时期有学过法线,它是垂直与平面的一条向量,因此储存了该平面方向和角度等信息。我们通过在物体凹凸表面的每个点上均绘制法线,再将其储存到 RGB 的颜色通道中,其中 R 红色、G 绿色、B 蓝色分别对应了三维场景中 XYX 空间坐标系,这样就能实现通过颜色来反映物体表面的光影效果,而由此得到的纹理图我们将其称为法线贴图。由于法线贴图可以实现在不改变物体真实结构的基础上也能反映光影分布的效果,被广泛应用在 CG 动画渲染和游戏制作等领域。

ControlNet 的 NormalMap 模型就是根据画面中的光影信息,从而模拟出物体表面的凹凸细节,实现准确还原画面内容布局,因此 NormalMap 多用于体现物体表面更加真实的光影细节。下图案例中可以看到使用NormalMap模型绘图后画面的光影效果立马有了显著提升。

NormalMap 有Bae和Midas2 种预处理器,MiDaS是早期 v1.0 版本使用的预处理器,官方已表示不再进行维护,平时大家使用默认新的Bae预处理器即可,下图是2种预处理器的提取结果。

当我们选择MiDaS预处理器时,下方会多出 Background Threshold背景阈值的参数项,它的数值范围在0~1之间。通过设置背景阈值参数可以过滤掉画面中距离镜头较远的元素,让画面着重体现关键主题。下图中可以看到,随着背景阈值数值增大,前景人物的细节体现保持不变,但背景内容逐渐被过滤掉。
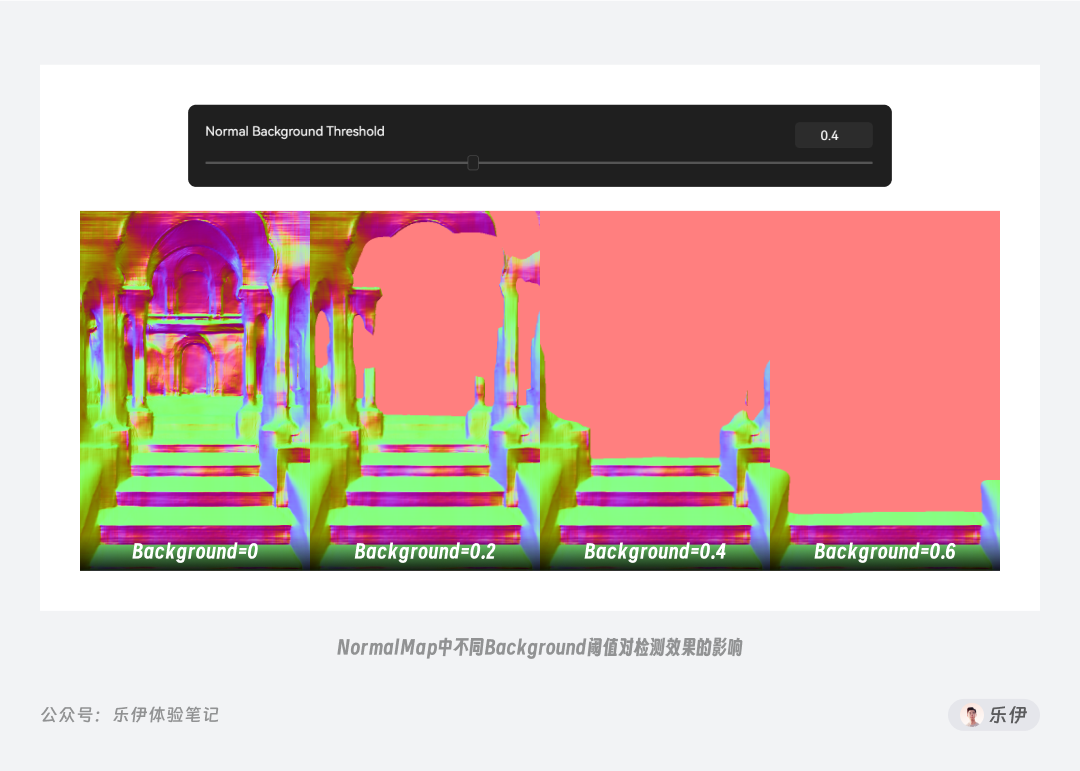
对比Bae和Midas预处理器的出图效果,也能看出Bae在光影反馈上明显更胜一筹。

2.3 对象类
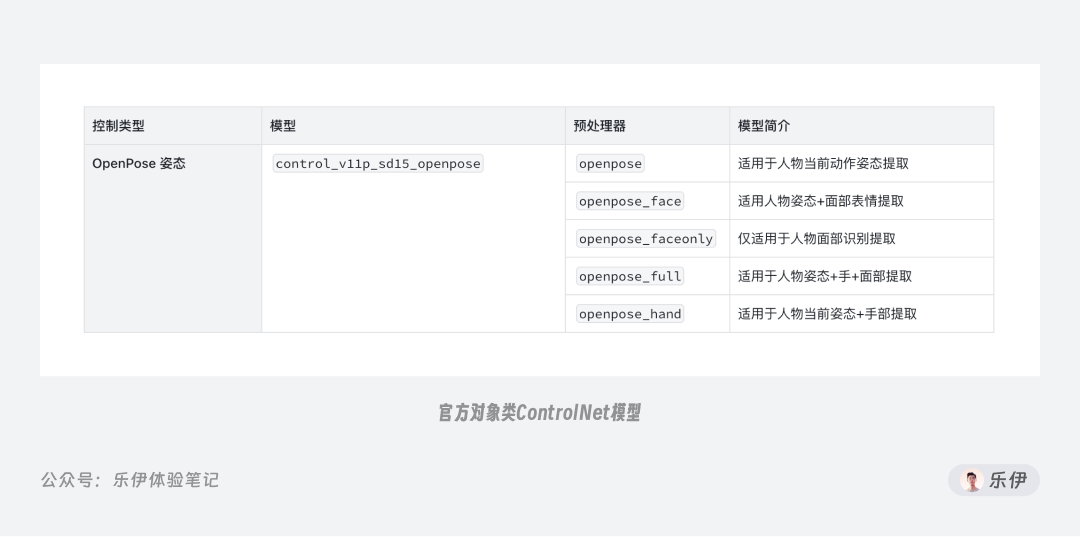
终于到了我们大名鼎鼎的 OpenPose,作为唯一一款专门用来控制人物肢体和表情特征的关键模型,它被广泛用于人物图像的绘制。
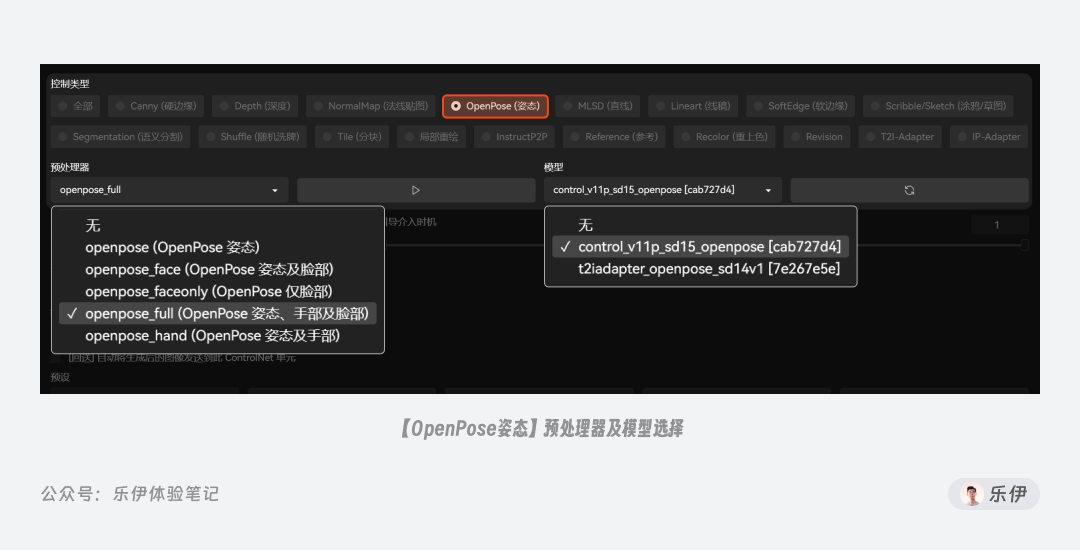
2.3.1 OpenPose姿态
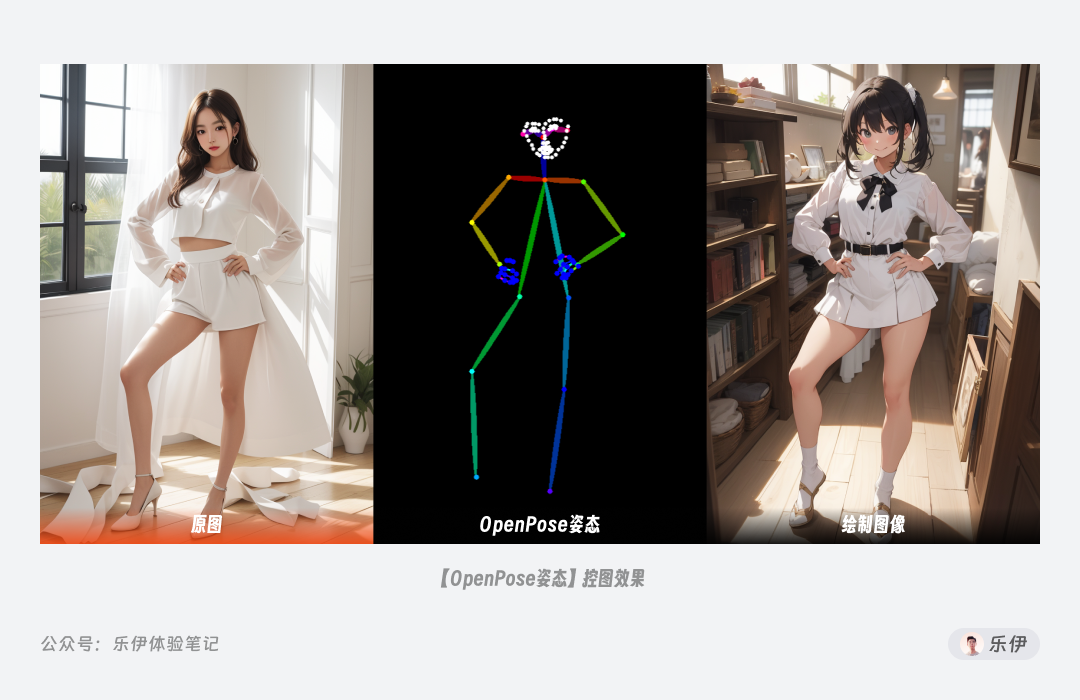
OpenPose 特点是可以检测到人体结构的关键点,比如头部、肩膀、手肘、膝盖等位置,而将人物的服饰、发型、背景等细节元素忽略掉。它通过捕捉人物结构在画面中的位置来还原人物姿势和表情。
在 OpenPose 中为我们内置了openpose、face、faceonly、full、hand这 5 种预处理器,它们分别用于检测五官、四肢、手部等人体结构。

-
openpose是最基础的预处理器,可以检测到人体大部分关键点,并通过不同颜色的线条连接起来。 -
face在openpose基础上强化了对人脸的识别,除了基础的面部朝向,还能识别眼睛、鼻子、嘴巴等五官和脸部轮廓,因此face在人物表情上可以实现很好的还原。 -
faceonly只针对处理面部的轮廓点信息,适合只刻画脸部细节的场景。 -
hand相当于在openpose基础上增加了手部结构的刻画,可以很好的解决常见的手部变形问题。 -
full是对以上所有预处理功能的集合,可以说是功能最全面的预处理器。
想要将上面的处理器挨个记下十分麻烦,平时使用时建议直接选择包含了全部关键点检测的full预处理器即可。

除了基本的人体姿势,预处理器中包含了对人物五官和手部的结构信息,因此OpenPose在处理表情和手部等人体细节上是很不错的控图工具。
2.4 重绘类
接着是最后的重绘类模型,在之前图生图篇我们有重点介绍过图像重绘的功能,而在 ControlNet 中对图像的重绘控制更加精妙,我们可以理解成这类重绘模型是对原生图生图功能的延伸和拓展。

2.4.1 Inpaint局部重绘
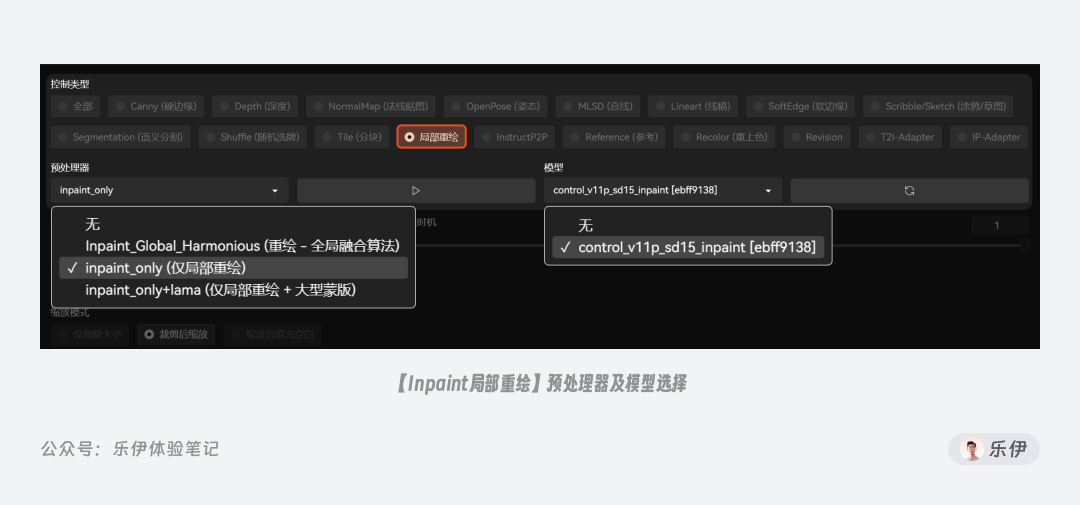
先来看看我们熟悉的局部重绘 ,ControlNet中的Inpaint相当于更换了原生图生图的算法,在使用时还是受重绘幅度等参数的影响。如下图的案例中我们使用较低的重绘幅度,可以实现不错的真实系头像转二次元效果,且对原图中的人物发型、发色都能比较准确的还原。

想配合 ControlNet 使用局部重绘 ,同样需要在图生图中进行操作,在涂抹完蒙版并设置参数后,我们打开 ControlNet 选择局部重绘控制项。注意在图生图板块使用 ControlNet 的局部重绘时默认无需再额外上传图片,ControlNet 会自动读取图生图中上传的图片。
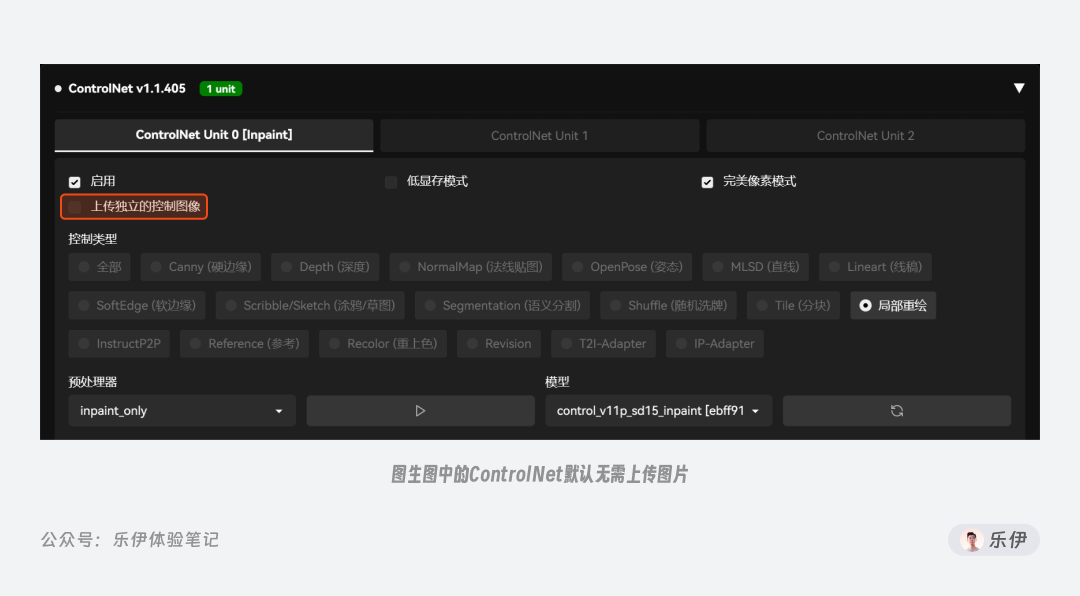
下图是图生图中局部重绘关闭和开启ControlNet时的效果对比,同样是在重绘幅度=1的情况下,开启ControlNet的画面稳定性会更强,在和环境融合方面也可以处理的更好。

局部重绘这里提供了 3 种预处理器,Global_Harmonious、only和only+lama,通过下图案例整体来看出图效果上差异不大,但在环境融合效果上Global_Harmonious处理效果最佳,only次之,only+lama最差。

2.4.2 Tile分块
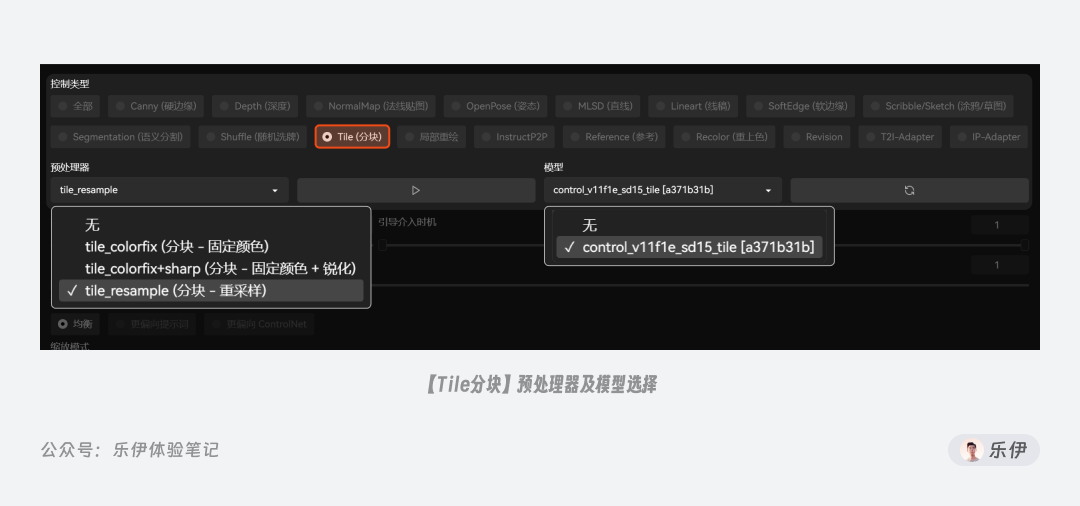
Tile 可以说是整个重绘类中最强大的一种模型,虽然还处于试验阶段,但依旧给社区带来了很多惊喜,因此值得我们多花点时间来好好介绍下它。
在 SD 开源这大半年中,绘制超分辨率的高清大图一直是很多极客玩家的追求,但限于显卡高昂的价格和算力瓶颈,通过 WebUI 直出图的方式始终难以达到满意的目标。后来聪明的开发者想到 Tile 分块绘制的处理方法,原理就是将超大尺寸的图像切割为显卡可以支持的小尺寸图片进行挨个绘制,再将其拼接成完整的大图,虽然绘图时间被拉长,但极大的提升了显卡性能的上限,真正意义上实现了小内存显卡绘制高清大图的操作。

但这个过程中始终有个问题困扰着很多开发者,那就是**分块后的小图始终难以摆脱全局提示词的影响。**举个例子,我们的提示词是1girl,当图像分割为 16 块进行绘制时,每个块都会被识别成一张独立的图片,导致每个块中可能都会单独绘制一个女孩。而 ControlNet Tile 巧妙的解决了这个问题。在绘制图像时启用 Tile 模型,它会主动识别单独块中的语义信息,减少全局提示的影响。具体来说,这个过程中 Tile 进行了 2 种处理方式:
-
忽略原有图像中的细节并生成新的细节。
-
如果小方块的原有语义和提示词不匹配,则会忽略全局提示词,转而使用局部的上下文来引导绘图。
在之前图生图给大家介绍重绘幅度参数时,有提到增大重绘幅度可以明显提升画面细节,但问题是一旦设定重绘幅度画面内容很容易就发生难以预料的变化,而配合 Tile 进行控图就能完美的解决这个问题,因为 Tile 模型的最大特点就是在优化图像细节的同时不会影响画面结构。

基于以上特点,ControlNet Tile 被广泛用于图像细节修复和高清放大,最典型的就是配合Tile Diffusion等插件实现 4k、8k 图的超分放大,相较于传统放大,Tile可以结合周围内容为图像增加更多合理细节。关于图像放大还有很多玩法可以给大家介绍,后面会单独给大家出一期文章。理论上来说,只要分得块足够多,配合Tile可以绘制任意尺寸的超大图。

Tile 中同样提供了3种预处理器:colorfix、colorfix+sharp、resample,分别表示固定颜色、固定颜色+锐化、重新采样。下图中可以看到三种预处理器的绘图效果,相较之下默认的resample在绘制时会提供更多发挥空间,内容上和原图差异会更大。

2.4.3 InstructP2P指导图生图
InstructP2P 的全称为 Instruct Pix2Pix 指导图生图,使用的是Instruct Pix2Pix数据集训练的ControlNet。它的功能可以说和图生图基本一样,会直接参考原图的信息特征进行重绘,因此并不需要单独的预处理器即可直接使用。
下图中为方便对比,我们将重绘幅度降低到0.1,可以发现开启InstructP2P 后的出图效果比单纯图生图能保留更多有用细节。

IP2P 目前还处于试验阶段,并不是一种成熟的 ControlNet 模型,平时使用并不多,大家大致了解其功能即可。
2.4.4 Shuffle随机洗牌

随机洗牌是非常特殊的控图类型,它的功能相当于将参考图的所有信息特征随机打乱再进行重组,生成的图像在结构、内容等方面和原图都可能不同,但在风格上你依旧能看到一丝关联。

不同于其他预处理器,Shuffle 在提取信息特征时完全随机,因此会收到种子值的影响,当种子值不同时预处理后的图像也会是千奇百怪。

Shuffle 的使用场景并不多,因为它的控图稳定性可以说所有 ControlNet 模型中最差的一种,你可以将它当作是另类的抽卡神器,用它来获取灵感也是不错的选择。

03
社区模型解析
介绍完14种官方模型,下面我们再来看看一些常见的社区模型,由于没有经过系统测试和调整,这类模型可能存在质量参差不齐的情况,且有些控制类型无需预处理器或无ControlNet模型也能使用。
以下社区模型的使用频率并不高,很多效果也是对现有功能的优化或调整,大家大致了解其功能即可,如果有特定需求可以下载对应模型进行尝试,其中有些已经支持配合SDXL使用。
3.1 Reference参考
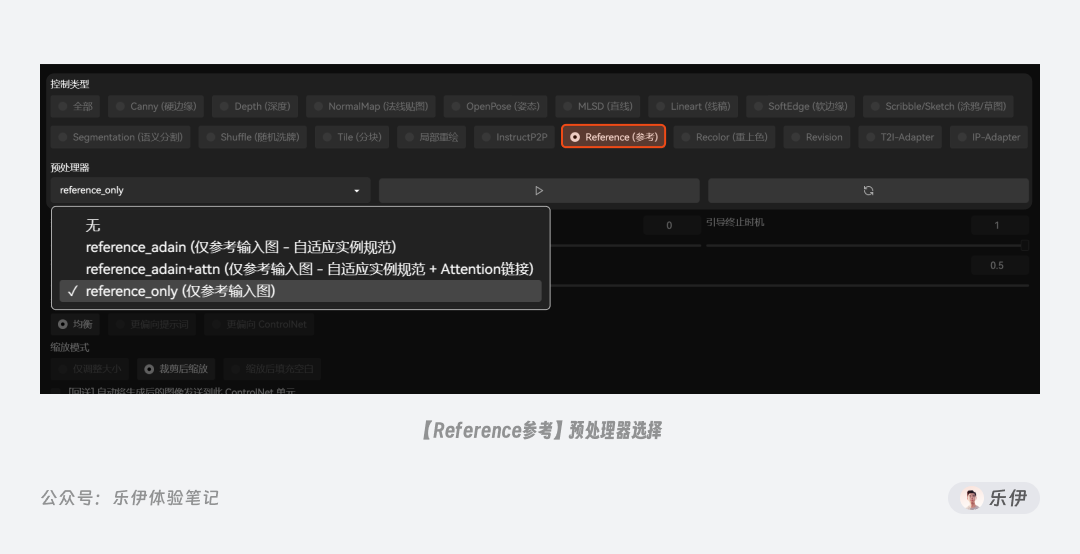
Reference使用时不需要使用模型,它的功能很简单,就是参考原图生成一张新的图像,想使用它需要将ControlNet更新到至少v1.1.153以上。

Reference的实际效果类似InstructP2P的图生图,这里提供了3个预处理器adain、adain+attn、only。其中adain、adain+attn是V1.1.171版本后新增的预处理器,其中adain表示Adaptive Instance Normalization 自适应实例规范化,+attn表示Attention链接。
根据作者测试,adain+attn使用的是目前最先进的算法,但有时效果过于强烈,因此依旧建议使用默认的only预处理。

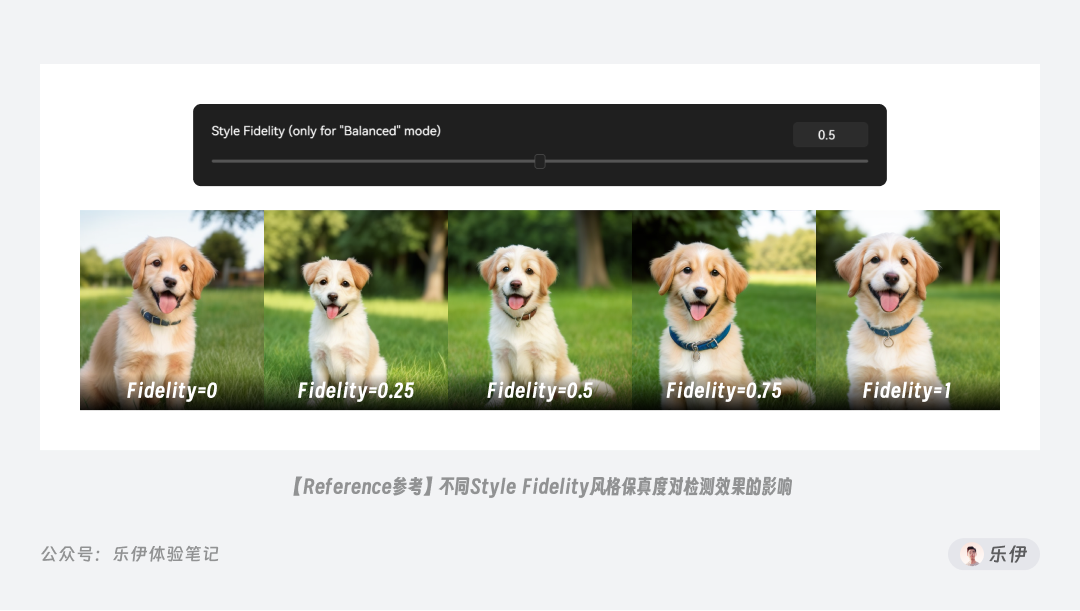
Reference启用后下方会出现Style Fidelity风格保真度的参数项,数值越大则画面的稳定性越强,原图的风格保留痕迹会越明显。
3.2 Recolor重上色
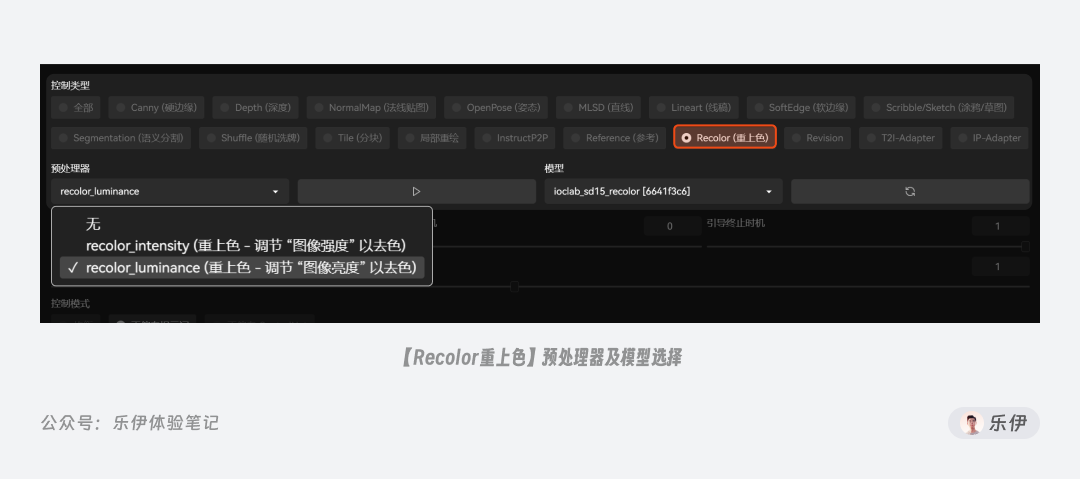
Recolor也是近期刚更新的一种ControlNet类型,它的效果是给图片填充颜色,非常适合修复一些黑白老旧照片。但Recolor无法保证颜色准确出现特定位置上,可能会出现相互污染的情况,因此实际使用时还需配合如打断等提示词语法进行调整。

Recolor无需配合模型使用,这里也提供了intensity和luminance2种预处理器,通常推荐使用luminance,预处理的效果会更好。

Recolor的参数Gamma Correction伽马修正用于调整预处理时检测的图像亮度,下图中可以看到随着数值增大,预处理后的图像会越暗。

3.4 T2I-Adapter文生图适配器
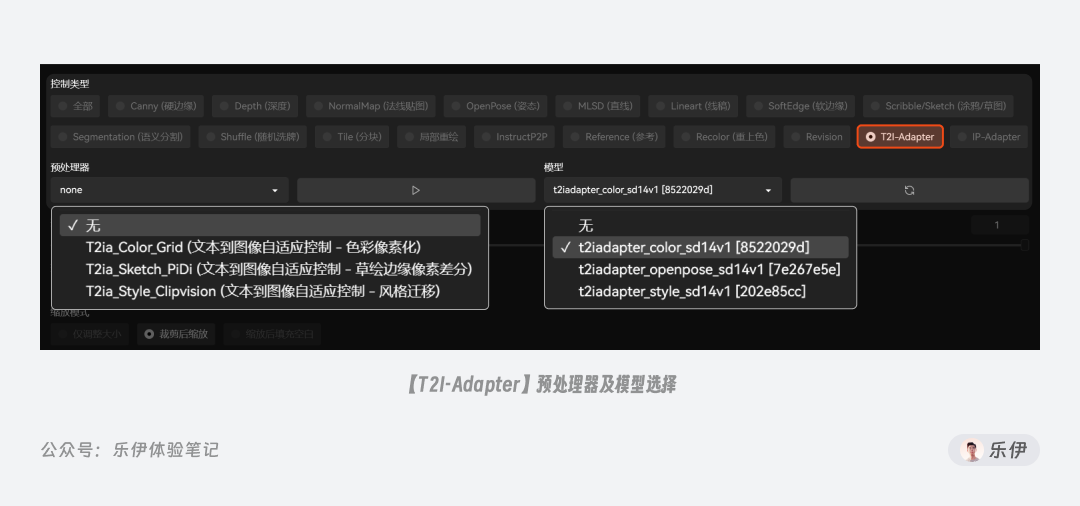
T2I-Adapter由腾讯ARC 实验室和北大视觉信息智能学习实验室联合研发的一款小型模型,它的作用是为各类文生图模型提供额外的控制引导,同时又不会影响原有模型的拓展和生成能力。名称中T2I 指的是的 text-to-image,即我们常说的文生图,而Adapter是适配器的意思。
T2I-Adapter 被集成在ControlNet中作为某一控制类型的选项,但实际上它提供了Lineart、Depth、Sketch、Segmentation、Openpose等多个类型的控图模型来使用。
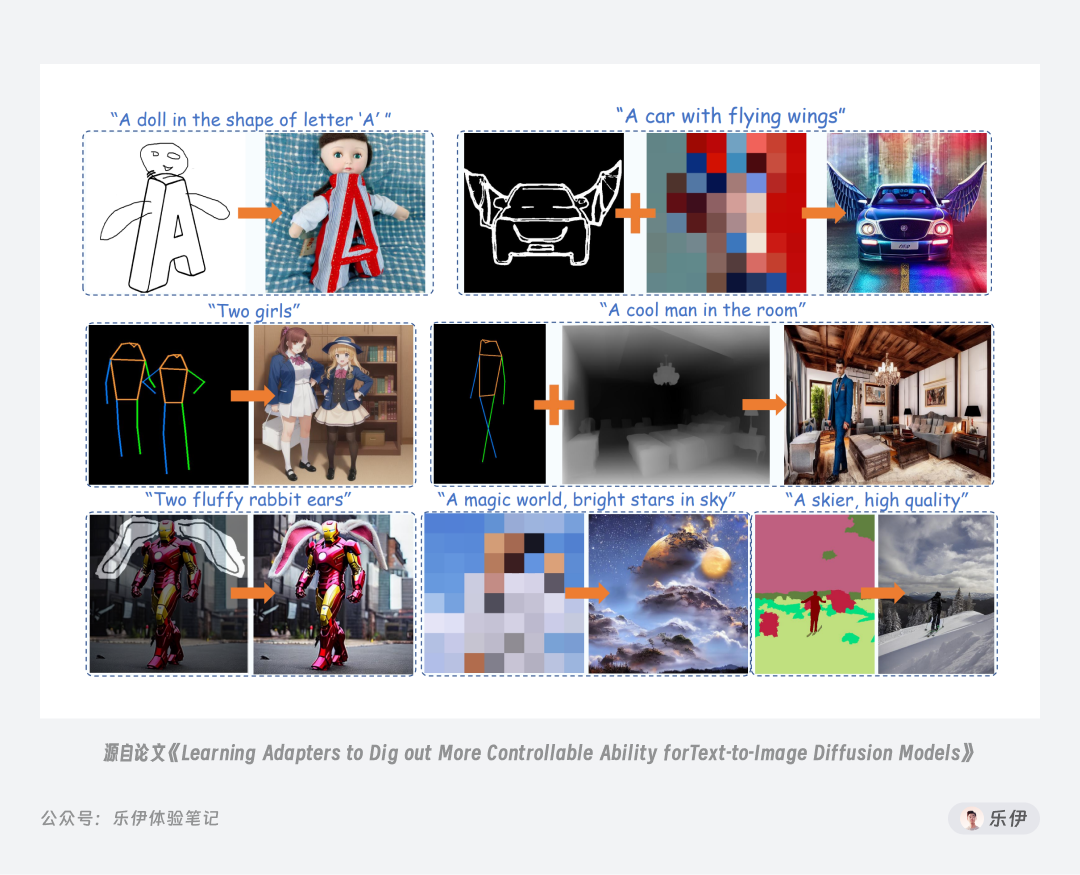
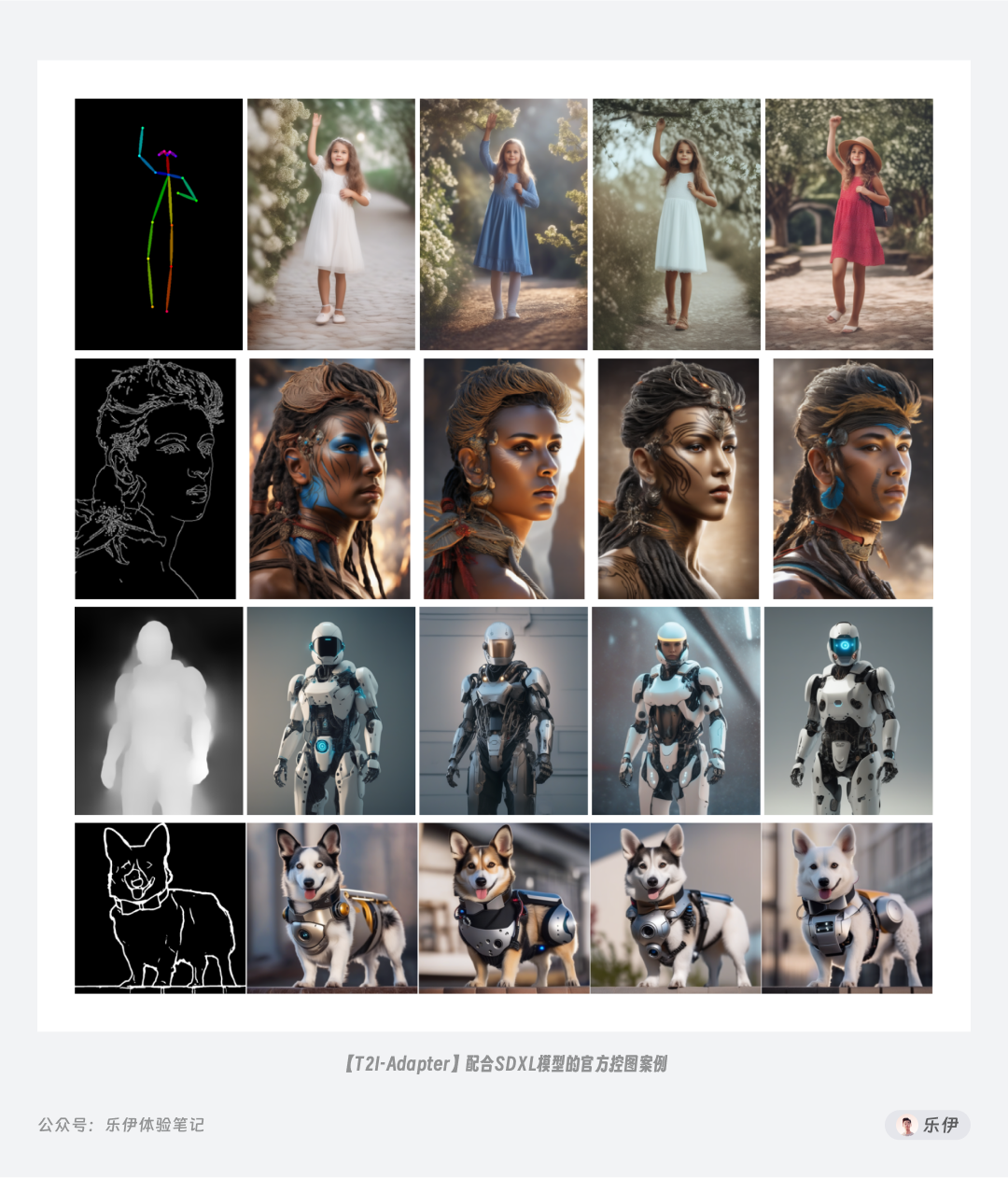
T2I-Adapter 的特点是体积小,参数级只有77M,但对图像的控制效果已经很好,且就在9月8日,它们针对SDXL训练的控图模型刚刚发布,是目前最推荐用于SDXL的ControlNet模型,但需要注意的是SDXL类模型对硬件要求较高,官方建议至少需要15GB的显卡内存,想体验的小伙伴可在下面地址中自行下载安装到本地。
T2I-Adapter控图模型代码仓库地址:https://huggingface.co/TencentARC/T2I-Adapter/tree/main/models
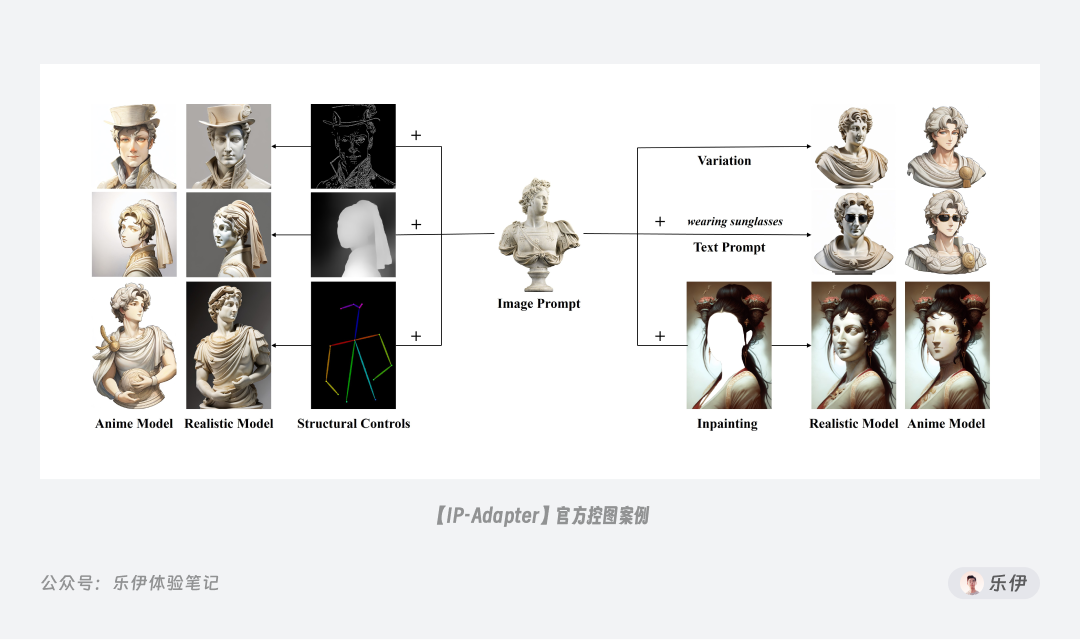
3.5 IP-Adapter图生图适配器

IP-Adapter是腾讯的另一个实验室Tencent AI Lab研发的控图模型。名称中的IP指的是Image Prompt图像提示,它和T2I-Adapter一样是一款小型模型,但是主要用来提升文生图模型的图像提示能力。IP-Adapter自9月8日发布后收到广泛好评,因为它在使用图生图作为参考时,对画面内容的还原十分惊艳,效果类似Midjourney的V按钮。它也同样内置了多种控图模型,下图中是官方提供的绘图案例。
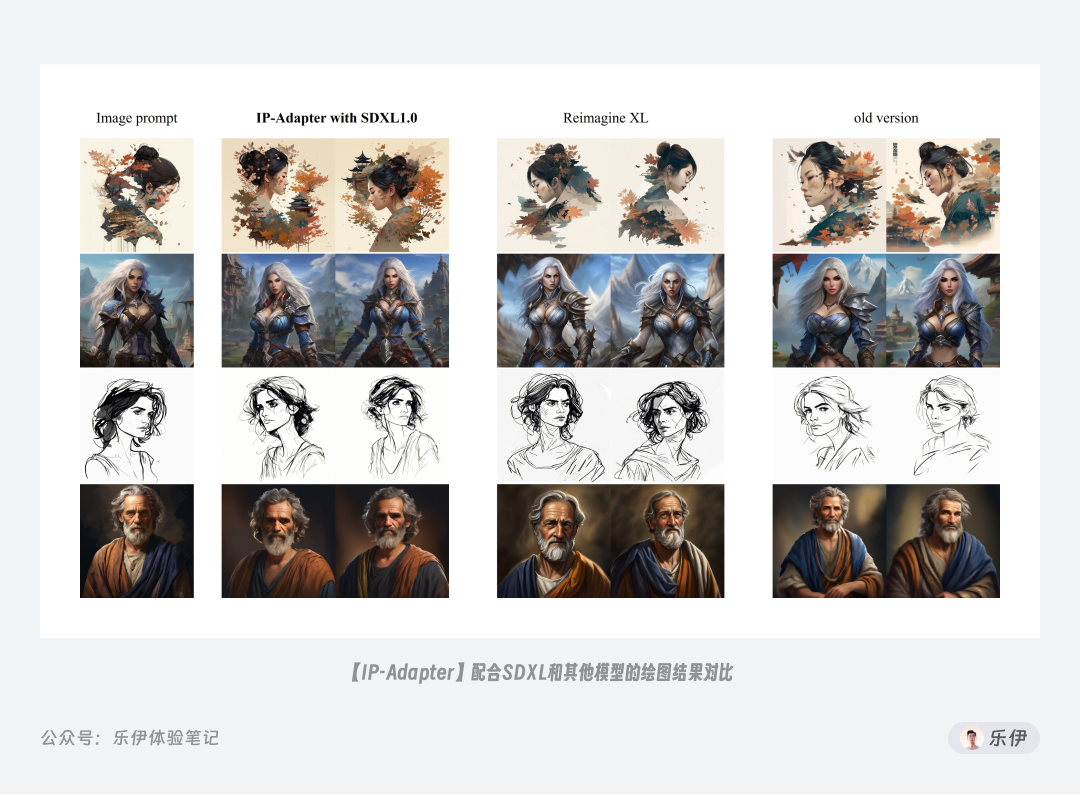
IP-Adapter的参数级比T2I-Adapter更小,只有22MB。IP-Adapter也发布了针对SDXL_1.0的控图模型,感兴趣的小伙伴可以通过扫描文末二维码找我拿。
文末扫码可获取 Stable Diffusion 的全部资源。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
 若有侵权,请联系删除
若有侵权,请联系删除