LangChin 是一门最早的用于AI应用开发的,他降低了我们开发AI应用的门槛,今天我这个写了很久的教程免费开放给大家,希望大家借助这个教程快速入门。
部分表格在手机端显示不全,建议在PC端浏览。

这个教程是小白学习 LangChain AI 开发的喂饭级教程。教程从 LangChain 的基本概念讲起,再到每个场景的代码具体编写,以及涉及每一个核心类如何使用,都进行细致的讲解,确保每一个初学者能够轻松快速掌握。
LangChain 是什么
LangChain 可以让开发人员像搭积木一样进行AI应用开发,它提供了很多的组件,例如调用不同的LLM、自建知识库时需要与各种数据的对接、自动执行一个任务等等。
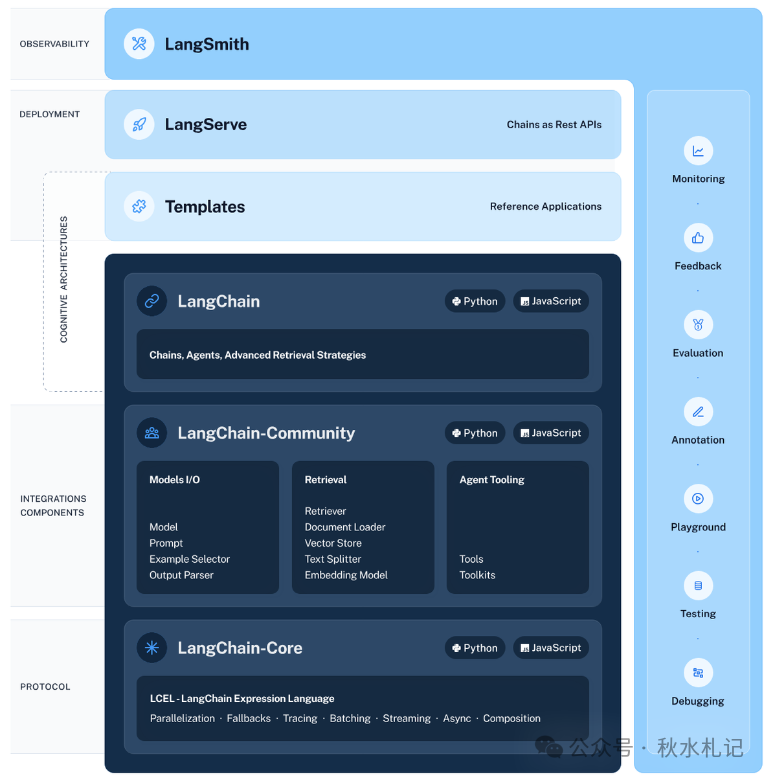
六大模块
模型I/O(Model I/O)
与不同LLM进行输入和输出的交互,封装了常用的提示模版,包含提示、与不同LLM对接输入和输出。
检索(Retrieval)
自建知识库,实现检索增强生成(Retrieval Augmented Generation ,RAG),包含文档加载、文本拆分、转换成向量、向量存储、知识检索
代理(Agents)
根据问题自动执行某个或多个任务,例如查询天气预报、发送一封邮件等
链(Chain)/ LCEL
分为Chain和LangChain表达式(LangChain Expression Language,LCEL),LCEL为更新后的方法,两者可以独立使用,LCEL里也可以调用Chain。
LCEL(LangChain Expression Language)可以用于构建和优化各种自动化和数据处理链条。举个例子,假设你正在开发一个自动化的内容摘要系统,该系统需要从多个数据源提取信息,然后使用自然语言处理(NLP)技术生成摘要。
LCEL和Chain的相同点和不同点
示例场景:自动化新闻摘要生成
假设我们要构建一个自动化系统,它的任务是从多个新闻网站收集新闻文章,然后生成这些文章的摘要。
使用Chain
定义Chain:首先,我们定义一个Chain,这个Chain包含了整个数据处理流程的步骤。例如,这个Chain可能包括以下步骤:
从新闻网站获取文章。
提取文章的主要内容。
使用自然语言处理技术生成摘要。
将摘要保存或展示给用户。
实现步骤:每个步骤都是Chain的一部分,可以使用不同的工具或方法实现。例如,从网站获取文章可能使用网络爬虫,提取内容可能使用文本处理库,生成摘要可能使用语言模型等。
使用LCEL
定义步骤:在这个Chain中,我们可以使用LCEL来定义和优化特定的步骤。例如,我们可以使用LCEL来声明性地描述如何从文章中提取关键信息,或者如何结合不同的数据源来改进摘要的质量。
优化流程:LCEL允许我们以高效和优化的方式组织这些步骤。例如,我们可以使用LCEL来定义并行处理规则,以便同时从多个新闻网站获取文章,或者定义如何在生成摘要时有效地处理和分析文本数据。
结合使用
在这个例子中,Chain定义了整个新闻摘要生成的流程,而LCEL用于优化这个流程中的特定步骤。LCEL提供了一种高级的方式来声明性地描述和组织数据处理逻辑,而Chain则是这些逻辑实际执行的框架。通过结合使用Chain和LCEL,我们能够构建一个既高效又灵活的自动化新闻摘要生成系统。
记忆(Memory)
用合适的方式存储对话内容,用户发送问题后先读取历史会话内容,返回答案之后,将本次交互内容进行存储。
回调(Callback)
回调在LangChain中提供了一种强大的方式来干预和管理LLM应用的不同阶段,无论是用于日志记录、监控、流式处理还是错误处理。通过使用回调,开发者可以更好地控制和优化他们的应用。
例如:
- 日志记录和监控:例如,您可以使用回调来记录LLM的每次调用或监控链条的性能。
- 流式处理:在处理流式数据时,例如,您可以使用回调来处理每个新生成的令牌或消息。
- 错误处理:在出现错误时,您可以使用回调来触发错误处理逻辑,例如重新尝试或发送警报。
- 用户交互:在聊天模型或交互式应用中,您可以使用回调来处理用户的每个输入或模型的每个响应。
三大工具
Templates、LangSmith、LangServe三大工具共同使,让你能够轻松开发、生产和部署AI应用程序。首先你可以参考Templates模板作为指导,编写AI应用程序。然后,LangSmith 帮助您检查、测试和监控您的链,确保您的AI应用程序不断改进并准备好部署。最后,使用 LangServe,您可以轻松地将任何链转换为 API,使部署变得轻而易举。
Templates
已经写好的一些常用的功能模版,可以直接拿来使用,例如RAG聊天机器人、从非结构化数据中提取结构化数据。
开发:在LangChain/LangChain.js中编写应用程序。使用模板作为参考,立即开始运行。
LangSmith
可帮助开发人员跟踪和评估开发的AI应用。为 LangChain 生态增加了运行监测与分析的能力。它可以收集 LLM 应用的各类运行指标,并进行分析展示,帮助开发者更深入地理解应用的运行状况。
生产化:使用 LangSmith 检查、测试和监控您的链,以便您可以自信地不断改进和部署。
LangServe
一个工具,用于将你的LangChain应用转换为可以通过REST API访问的服务。你的程序实际上是部署在你自己的服务器或云环境上,而LangServe负责创建和管理这些服务的API接口。
部署:使用 LangServe 将任何链转换为 API。
LangChain库
https://api.python.langchain.com/en/stable/langchain_api_reference.html
langchain :构成应用程序认知架构的链、代理和检索策略。
langchain-core :基本抽象和LangChain表达式语言。
langchain-community :第三方集成。
基础入门
安装和配置
#安装
pip install langchain
pip install openai
#更新到最新版本
pip install --upgrade langchain
pip install --upgrade openai
Hello world
Hello world,一个基础的LangChain程序
安装LangChain和OpenAI的Python包
OpenAI密钥的配置方式
方法1:代码中直接写入
方法2:数据库中写入,代码中调用
方法3:环境变量中配置
Hello LangChain
一个复杂的涉及到LangChain所有模块(模型、模版、代理、链、记忆、回调)的最简单的例子,讲解初步使用方式。
模型I/O(Model I/O)
Model I/O ,主要是封装了用户与大模型之间的交互,包含了输入(prompts 输入提示)、模型交互(Models 模型)、输出(Output Parser 输出解析器)三大部分。
概览
交互流程说明:
- 输入(prompts 输入提示),在LangChain中提供了对用户输入内容的prompts提示管理,在上图示例中,可以在提示中使用变量替代变化的内容。
- 模型调用(Models 模型),通过prompts组件可以将组装后的提示内容发送给不同的模型,LangChain已经对接了很多大模型,例如OpenAI,谷歌的Palm,微软云的OpenAI模型等,从而方便开发者开发的AI应用调用不同的模型。
- 解析,对于模型输出的内容,LangChain提供了解析组件,例如解析成字符串、JSON格式,或者其他类似函数调用的格式等。
代码示例:
一段入门代码示例,体现输入、交互、解析
prompt 输入提示
如何撰写出询问大模型好的prompt 提示
我们在询问大模型问题的时候,需要遵循一定规则,才能让大模型输出的答案更加准确,这个在OpenAI的官方文档中有详细的说明,概括起来就是如下六项。
- 写清晰的指示
- 给模型提供参考(也就是示例)
- 将复杂任务拆分成子任务
- 给 GPT 时间思考
- 使用外部工具
- 反复迭代问题
问大模型prompt 提示的组成结构
在使用ChatGPT时,一个完整的提示示例
#背景信息
你将得到一份用三引号包含的文章,你的任务是只用所提供的文章来回答问题,并引用文件中用来回答问题的段落。如果该文章中不包含回答该问题所需的信息,那么只需背景信息号上:"信息不充分,无法回答"。
#用户输入的提示
请总结出TCL将如何实现碳中和,每一条一行。
#上下文内容
'''
7月6日,TCL正式发布碳中和白皮书,提出“不晚于2030年实现碳达峰,不晚于2050年实现碳中和”的“3050”承诺目标及碳中和行动计划TCLGreen,旨在以自身科技创新驱动产业绿色制造,打造制造业绿色生态标杆,推动产业链加快绿色变革。
本次发布了TCL科技、TCL华星、TCL中环及TCL实业共四份碳中和白皮书,TCL创始人、董事长李东生及各产业负责人在TCL全球生态合作伙伴大会主题报告中,也提出碳中和实践目标及行动计划。
'''
- 背景信息 告诉模型这个任务大概要做什么、怎么做,比如如何使用提供的外部信息、如何处理查询以及如何构造输出。这通常是一个提示模板中比较固定的部分。一个常见用例是告诉模型“你是一个有用的 XX 助手”,这会让他更认真地对待自己的角色。
- 上下文内容 则充当模型的额外知识来源。这些信息是用户输入的,或者聊天历史记录,也可以通过向量数据库检索得来,或通过其他方式(如调用 API、计算器等工具)获取。一个常见的用例是把从向量数据库查询到的知识作为上下文传递给模型。
- 用户输入的提示 通常就是具体的问题或者需要大模型做的具体事情,在使用ChatGPT时候,这个部分和“背景信息”部分作为一体。但是我们开发的自己的AI应用,一般会将背景信息和用户输入的提示拆分成为两部分,形成便于复用的提示模板。
与ChatGPT对话中的三个主要角色
- SYSTEM 在LangChain中用SystemMessagePromptTemplate表示,可以把它看成“提示的组成结构”中的“背景信息”,system角色有助于使模型了解如何回应用户提出的问题。
- USER 在LangChain中用HumanMessagePromptTemplate表示,就是用户输入的问题内容。
- ASSISTANT 在LangChain中用AIMessagePromptTemplate表示,就是AI大模型的回复内容。
什么是 LangChain 的 prompt
LangChain的prompt是一种可复制、可重复使用的制作提示模版的组件,每个提示模版都可以包含占位符,这些占位符可以在运行的时候被动态替换成实际终端用户输入的内容,最终形成调用模型时输入的内容。
区分LangChain的prompt和询问大模型的prompt
LangChain的prompt是对询问大模型的prompt内容的管理组件,它的重点是如果高效管理提示模版,由很多的Python类组成。
询问大模型的prompt是用户与大模型交互的具体输入内容,例如在ChatGPT中,用户输入的内容就是prompt提示(包含问题、背景信息等);而在我们自己开发的AI应用中,用户输入的内容,会结合AI应用中内置的提示模版,组成输入给大模型的提示内容。
常用的prompt类
prompt 提示类之间的继承关系
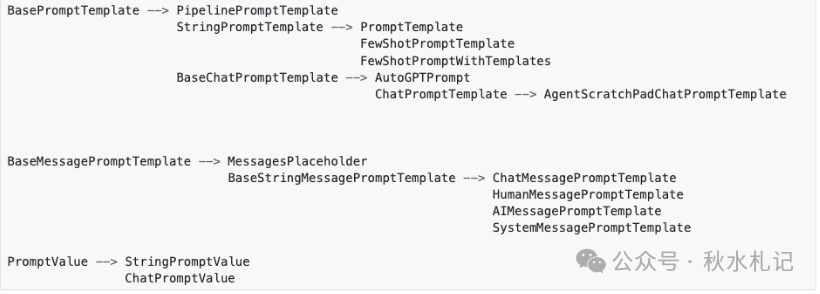
prompt 相关类
| 名称 | 说明 |
| PromptTemplate | 用于创建字符串提示的提示模板。它支持任意数量的变量,包括没有变量。您可以创建自定义提示模板,以任何您想要的方式格式化提示。 |
| ChatPrompTemplate | 用于创建聊天模型的提示模版,它是一系列聊天消息列表。每个聊天消息具有对应的角色消息模版,如SystemMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate;也可以用角色消息SystemMessage、HumanMessage、AIMessage。 |
| FewShotPromptTemplate | 用于构建少量样本学习(Few-shot learning)的提示模版。这种模板通常用于在提示中列举几个例子,让模型参照例子进行学习后,输出类似回答结果。 |
| ExampleSelector | ExampleSelector不是一个提示模板,而是一个用于从大量例子中选择最相关例子的工具(大量的例子存在向量数据库中,如果我们的示例很多,那么一次性把所有示例发送给模型是不现实而且低效的),通常与FewShotPromptTemplate结合使用,以实现更有效的少量样本学习。 |
| PipelinePromptTemplate | 将多个提示模版合并为一个提示对象,在实践中,发现对提示进行问题排除检测非常麻烦。 |
| PromptValue | to_string方法输出的字符串提示,示例如下:to_messages方法输出的聊天提示,它是一个HumanMessage对象,示例如下: |
PromptTemplate 字符串提示模版
📌
PromptTemplate的应用场景主要用于与LLM大模型生成单次请求的提示。这种模板适用于需要生成特定任务或查询的场景,例如转换文本风格、生成特定信息的文本、或者执行特定的文本分析任务。它更多地用于静态的、一次性的文本生成或文本处理任务。
它允许用户定义一个模板,其中可以包含占位符和指定的变量。当需要生成提示时,这些变量会被实际的数据替换,以形成完整的提示文本。
字符串提示模版最终形成的提示是以字符串形式存在的,在字符串模版中可以有多个占位符,每个占位符就是一个变量,后续可以将变量的位置替换成对应的字符串。
字符串提示模版,可以使用 f-strings(默认)或 jinja2 语法。
f-string,在Python中,f-strings是一种字符串格式化方法,可以方便地将变量插入到字符串中。F-string以字母"f"或"F"开头,后面跟着一对大括号,用于包含要插入的变量或表达式。大括号内可以使用变量、表达式或方法调用等Python代码。
jinja2,是Python下一个被广泛应用的模版引擎,他的设计思想来源于Django的模板引擎,并扩展了其语法和一系列强大的功能。
推荐使用f-strings,f-strings提供了一种快速简洁的格式化方式,而jinja2则提供了更强大的逻辑控制能力。然而,出于安全考虑,如果模板来自不可信的源,推荐使用f-strings,因为jinja2模板可能会执行任意的Python代码。为了减少安全风险,从LangChain 0.0.329版本开始,jinja2模板将默认在一个沙盒环境中渲染,虽然这提供了一定程度的安全保护,但仍然建议慎用来自不信任来源的jinja2模板。
主要方法概览
| 方法名 | 介绍 | 返回类型 | 参数说明 |
| init | 构造方法 | PromptTemplate | input_variables (List[str], 必需):input_types (Dict[str, Any], 可选):template (str, 必需):template_format (Literal['f-string', 'jinja2'], 可选, 默认为'f-string'):partial_variables (Mapping[str, Union[str, Callable[[], str]]], 可选):output_parser (Optional[BaseOutputParser], 可选, 默认为None):validate_template (bool, 可选, 默认为False): |
| from_template | 类方法,从一个字符串模板加载提示模板。这是创建提示模板的推荐方式。 | PromptTemplate | template (str, 必需):template_format (str, 可选, 默认为'f-string'):partial_variables (Dict[str, Any], 可选):**kwargs (Any, 可选): |
| from_file | 类方法,从文件加载提示模板。 | PromptTemplate | template_file (Union[str, Path], 必需):input_variables (Optional[List[str]], 可选):**kwargs (Any, 可选): |
| format | 对象方法,使用输入参数格式化提示模板,所有加载的模版都需要调用这个方法,对传入模版中每个变量的值。 | str | **kwargs (Any, 必需): |
| format_prompt | 对象方法,与format效果一样,只是返回的类型不一样。该方法返回的PromptValue对象可以输出str和message两种类型的格式 | PromptValue | **kwargs (Any, 必需): |
| partial | 对象方法,可以对一个有多个变量的提示模版,进行多次赋值,format方法调用一次需要对所有的变量进行赋值。 | BasePromptTemplate | **kwargs (Any, 必需): |
使用构造方法创建提示模版
# 使用构造函数创建
from langchain import PromptTemplate
template = """\
秋水札记,定位于 {product1} AI 编程推广,分享 {product2} 商业与技术。
"""
prompt = PromptTemplate(input_variables=["product1","product2"], template=template)
print(prompt.format(product1="LangChain", product2="AI"))
print(prompt.format_prompt(product1="LangChain", product2="AI").to_messages())
'''
代码执行后输出内容如下:
秋水札记,定位于 LangChain AI 编程推广,分享 AI 商业与技术。
[HumanMessage(content='秋水札记,定位于 LangChain AI 编程推广,分享 AI 商业与技术。\n')]
'''
这种方式使用类PromptTemplate的构造函数直接创建一个实例。构造函数接受一个变量列表input_variables,这个列表明确指出了模板中将要使用的变量名称,以及一个template字符串,其中包含相应的变量占位符。
这种方式在input_variables提供了额外的变量明确性,因为它要求你在创建模板时就明确指定哪些变量将会被用于格式化,这可能有助于代码的可读性和后续的维护。
📌
1、PromptTemplate构造方法中input_variables的参数为提示模版中的变量列表,可以写也可以不写,例如input_variables=[],都不影响format方法执行时对提示模版中的变量进行赋值。
2、format_prompt方法执行后输出的PromptValue对象,用于聊天模型交互,format方法执行输出的是字符串,用于LLM大模型交互。
3、format、format_prompt两个方法在格式化提示模版的时候,必须对所有的变量进行赋值,如果需要分步赋值,可以用partial方法赋值。
使用from_template方法创建提示模版
# 使用from_template方法创建
from langchain import PromptTemplate
template = """\
秋水札记,定位于 {product1} AI 编程推广,分享 {product2} 商业与技术。
"""
prompt_multiple = PromptTemplate.from_template(template)
print(prompt_multiple.format(product1="LangChain", product2="AI"))
'''
代码执行后输出内容如下:
秋水札记,定位于 LangChain AI 编程推广,分享 AI 商业与技术。
'''
from_template方法是类PromptTemplate方法,用于创建PromptTemplate的实例。这种方法直接接受一个模板字符串作为参数,其中模板字符串包含用大括号{}包裹的变量,这些变量在后续可以通过format方法被替换。
这种方式直观且易于使用,尤其是当你的模板字符串是静态的或者在编写代码时已知的。它允许你在一个步骤中定义模板,并在另一个步骤中填充具体的变量值。
使用from_file方法创建提示模版
# 假设有一个名为"model_io_prompt.txt"的文件,与当前代码文件在相同目录下,其中包含模板字符串
# 文件内容: "秋水札记,定位于 {product1} AI 编程推广,分享 {product2} 商业与技术。"
from langchain import PromptTemplate
template_path = "model_io_prompt.txt"
prompt_from_file = PromptTemplate.from_file(template_path)
print(prompt_from_file.format(product1="LangChain", product2="AI"))
'''
代码执行后输出内容如下:
秋水札记,定位于 LangChain AI 编程推广,分享 AI 商业与技术。
'''
from_file方法是类PromptTemplate的方法,用于从文件中创建PromptTemplate的实例。这个方法接受一个文件路径作为参数,该文件包含模板字符串,其中的变量用大括号{}包裹,这些变量后续可以通过format方法被替换。
这种方法非常适合于模板内容比较大或者需要频繁更改的场景,因为它允许将模板内容与代码逻辑分离,使得维护更加方便。此外,从文件中加载模板也使得在不同的项目或环境中重用模板变得简单。
partial 方法用于提示模版分多次赋值
partial是BasePromptTemplate的一个方法,继承BasePromptTemplate类的所有子类,都有这个方法,该方法执行完后返回的是BasePromptTemplate对象。
partial方法的主要用途是解决复杂 prompt 提示中含有多个变量,部分变量先赋值,剩余部分在后续逐步赋值,赋值的次数可以为多次,但是最后一步必须执行format方法。
字符串多次赋值
# 初始化模板,其中包含了两个变量:product1和product2
from langchain import PromptTemplate
template_str = "秋水札记,定位于 {product1} AI 编程推广,分享 {product2} 商业与技术。"
prompt = PromptTemplate.from_template(template_str)
# 对模板进行partial处理,先填充product1变量
partial_prompt = prompt.partial(product1="langchain")
print(partial_prompt)
# 使用partial处理后的模板,赋值剩余的product2变量
# 最后一步赋值操作需要用format方法
final_statement = partial_prompt.format(product2="AI")
print(final_statement)
'''
代码执行后输出内容如下:
input_variables=['product2'] partial_variables={'product1': 'langchain'} template='秋水札记,定位于 {product1} AI 编程推广,分享 {product2} 商业与技术。'
秋水札记,定位于 langchain AI 编程推广,分享 AI 商业与技术。
'''
带字符串的partial使用是最常见的,尤其是当某些变量提前获得而其他变量稍后获得时。在上方代码示例中,提示模板需要两个变量 product1 和 product2 。如果你提前获得了 product1 值,但是 product2 值稍后才获得,此时不需要等到两个变量同时赋值给提示模板。相反,你可以使用 product1 值对提示模板进行 partial 处理,然后继续后续的赋值操作,直到提示模版中的变量全部赋值结束。
📌
partial 方法执行后返回的 BasePromptTemplate 对象,如果需要输出 prompt 提示 ,最后还是需要执行 format 或 format_prompt 方法。
函数调用赋值
from langchain.prompts import PromptTemplatedefget_product_name(): # 这里的逻辑可以根据实际情况动态决定product2的值 # 为了示例,我们直接返回"AI" return"AI"# 更新模板字符串以包含三个参数,并预先为product3赋值prompt = PromptTemplate( template="{product3},定位于 {product1} AI 编程推广,分享 {product2} 商业与技术。", input_variables=["product1", "product2"], partial_variables={"product3": "秋水札记"} # 在构造方法中预先为product3赋值)# 使用函数Partial处理,这里我们假设product1始终为"LangChain"partial_prompt = prompt.partial(product1="LangChain", product2=get_product_name)# 格式化时,我们不需要再传递任何变量,因为它们已通过Partial处理被填充final_statement = partial_prompt.format()print(final_statement)
'''
代码执行后输出内容如下:
秋水札记,定位于 langchain AI 编程推广,分享 AI 商业与技术。
'''
在上方示例中,我们通过 partial_variables 参数在构造 PromptTemplate 对象时预先为 product3 变量赋值为"秋水札记"。product2 根据当前的某些条件动态决定,所以动态决定的过程就放在函数里执行,函数名可以直接在执行partial方法时的作为参数值。在 format 方法中,不能直接使用函数名作为参数。应先调用函数并将返回结果赋值给一个变量,然后再将这个变量传递给 format 方法。
📌
可以直接在 partial 方法或者构造函数 partial_variables 对应的参数赋值处填写函数名,进行直接调用。但是 format 方法是不可以直接调用,需要先将函数返回结果赋值给一个变量,在将变量赋值给 format 方法对应的参数。
ChatPromptTemplate 聊天模型提示模版
📌
ChatPromptTemplate 应用场景用于生成与LLM进行对话式交互的提示。用于构建聊天机器人、进行持续的对话管理或处理连续的文本交互任务。它特别适合需要考虑上下文连续性和历史对话信息的场景。
它扩展了 PromptTemplate 的功能,加入了对话历史的管理和引用能力。这意味着它可以在生成提示时考虑之前的交互内容,使得生成的文本能够更自然地融入到对话流程中。
如下为OpenAI 的 Chat Model 中的各种消息角色。
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
如下为OpenAI 对传输到 gpt-3.5-turbo 和 GPT-4 的 messsage 格式说明。
消息必须是消息对象的数组,其中每个对象都有一个角色(系统、用户或助理)和内容。对话可以短至一条消息,也可以来回多次。
通常,对话首先由系统消息格式化,然后是交替的用户消息和助理消息。
系统消息有助于设置助手的行为。例如,你可以修改助手的个性或提供有关其在整个对话过程中应如何表现的具体说明。但请注意,系统消息是可选的,并且没有系统消息的模型的行为可能类似于使用通用消息,例如“你是一个有用的助手”。
用户消息提供助理响应的请求或评论。
助理消息存储以前的助理响应,但也可以由你编写以给出所需行为的示例。
ChatPromptTemplate 这一些列的模版,就是根据如上OpenAI对聊天模型的规定而设计的。
主要方法概览
| 方法名称 | 介绍 | 返回类型 | 参数介绍 |
| init | 构造方法 | ChatPromptTemplate | input_variables (List[str], 必需):这是一个字符串列表,指定了模板中期望的变量名。这些变量是在模板字符串中被格式化时需要提供值的占位符。input_types (Dict[str, Any], 可选): 一个字典,映射模板中每个变量的名称到其期望的类型。这有助于在处理模板之前验证输入数据的类型。messagespartial_variables (Mapping[str, Union[str, Callable[[], str]]], 可选):一个映射,为模板中的一些变量提供部分或默认值。这些值可以是字符串或返回字符串的函数。在此处赋值的变量就不需要在input_variables中体现了output_parser (Optional[BaseOutputParser], 可选, 默认为None):一个输出解析器对象,用于解析调用语言模型后返回的输出。这允许对模型输出进行自定义处理。validate_template (bool, 可选, 默认为False):指定是否在实例化时验证模板字符串。启用验证可以确保模板字符串符合预期的格式,但可能会增加额外的性能开销。 |
| from_messages | 类方法,从多种消息格式创建聊天提示模板。 | ChatPromptTemplate | messages (Sequence[Union[BaseMessagePromptTemplate, BaseMessage, BaseChatPromptTemplate, Tuple[str, str], Tuple[Type, str], str]], 必需): 消息列表,列表的每一项可以是BaseMessagePromptTemplate, BaseMessage, 元组(消息类型, 模板), 字符串等。 |
| from_template | 类方法,从单一的模板字符串创建聊天提示模板。 | ChatPromptTemplate | template (str, 必需): 一个包含占位符的字符串,属于human消息类型,占位符将在调用format方法时被实际的值替换。 |
| format | 将聊天模板格式化为字符串。 | str | kwargs (Any, 必需): 给提示模板中的参数赋值。 |
| format_messages | 将聊天模板格式化为最终消息列表。 | List[BaseMessage] | - kwargs (Any, 必需):给提示模板中的参数赋值。 |
| format_prompt | 格式化提示,返回一个PromptValue。 | PromptValue | - kwargs (Any, 必需): 给提示模板中的参数赋值。 |
| partial | 创建一个新的ChatPromptTemplate实例,为部分变量先赋值。 | ChatPromptTemplate | - kwargs (Union[str, Callable[[], str]], 必需): 给提示模板中的参数赋值。 |
使用构造方法创建聊天提示
- 利用诸如SystemMessage角色消息创建聊天模版
from langchain.schema import AIMessage, HumanMessage, SystemMessage# SystemMessage、HumanMessage、AIMessage# 这种类型组成的message,content赋值只能是字符串,不能是模版messages = [ SystemMessage(content='秋水札记,定位于 LangChain AI 编程推广,分享 LangChain 商业与技术。'), HumanMessage(content='帮我列出几个AI商业案例?') ]#构造方法创建提示模版prompt = ChatPromptTemplate(messages=messages)# 格式化模板formatted_prompt_message = prompt.format_messages()print("format_messages()执行后返回List[BaseMessage] 对象:")print(formatted_prompt_message)print("\n每一个BaseMessage 对象:")for msg in formatted_prompt_message: print(msg.content)formatted_prompt = prompt.format()print("\nformat()执行后返回字符串:") print(formatted_prompt) formatted_format_prompt = prompt.format_prompt()print("\nformat_prompt()执行后返回PromptValue 对象:") print(formatted_format_prompt)
'''
代码执行后输出内容如下:format_messages()执行后返回List[BaseMessage] 对象:[SystemMessage(content='秋水札记,定位于 LangChain AI 编程推广,分享 LangChain 商业与技术。'), HumanMessage(content='帮我列出几个AI商业案例?')]每一个BaseMessage 对象:秋水札记,定位于 LangChain AI 编程推广,分享 LangChain 商业与技术。帮我列出几个AI商业案例?format()执行后返回字符串:System: 秋水札记,定位于 LangChain AI 编程推广,分享 LangChain 商业与技术。Human: 帮我列出几个AI商业案例?format_prompt()执行后返回PromptValue 对象:messages=[SystemMessage(content='秋水札记,定位于 LangChain AI 编程推广,分享 LangChain 商业与技术。'), HumanMessage(content='帮我列出几个AI商业案例?')]
'''
使用SystemMessage、HumanMessage、AIMessage角色消息创建聊天提示时,在具体的提示字符串中不能设置变量,如果需要设置变量则需要将这三种消息类型换成消息模版SystemMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate。
SystemMessage 对应的是前面讲的ChatGPT三种主要角色中的SYSTEM。
HumanMessage 对应的是USER,就是用户输入的问题内容。
AIMessage 对应的是ASSISTANT,就是AI大模型的回复内容。
📌
SystemMessage、HumanMessage、AIMessage角色消息,不是提示模版,不支持在提示中设置变量。
- 利用诸如SystemMessagePromptTemplate角色消息模版创建聊天模版
# 定义变量
brand = "秋水札记"product_promotion = "LangChain"business_case = "AI商业案例"# 使用构造函数创建提示模板# 这里的 messages 列表直接使用了字符串格式的消息,# 但同样可以根据需要扩展为更复杂的消息提示模板messages = [ SystemMessagePromptTemplate( prompt = PromptTemplate(input_variables=[], template='{brand},定位于 LangChain AI 编程推广,分享 {product_promotion} 商业与技术。') ),HumanMessagePromptTemplate( prompt = PromptTemplate(input_variables=[], template='帮我列出几个{business_case}') )]prompt = ChatPromptTemplate(input_variables=[], messages=messages)# 格式化并输出模板formatted_prompt = prompt.format_messages(brand=brand, product_promotion=product_promotion, business_case=business_case)print("format_messages()执行后返回List[BaseMessage] 对象:")print(formatted_prompt)
'''
代码执行后输出内容如下:
format_messages()执行后返回List[BaseMessage] 对象:
[SystemMessage(content='秋水札记,定位于 LangChain AI 编程推广,分享 LangChain 商业与技术。'), HumanMessage(content='帮我列出几个AI商业案例?')]
'''
使用SystemMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate创建聊天提示,这三个角色提示模版的构造方法的重要参数就是prompt,它要求传入PromptTemplate对像。
使用from_messages创建聊天提示
template = ChatPromptTemplate.from_messages([
("system", "{brand},定位于 LangChain AI 编程推广,分享 {product_promotion} 商业与技术。"), HumanMessagePromptTemplate( prompt = PromptTemplate(input_variables=[], template='帮我列出几个{business_case}') ), AIMessage(content='语音助手、聊天机器人和对话式AI。')])messages = template.format_messages( brand="秋水札记", product_promotion="LangChain", business_case="AI商业案例")print(messages)
'''
代码执行后输出内容如下:
[SystemMessage(content='秋水札记,定位于 LangChain AI 编程推广,分享 LangChain 商业与技术。'), HumanMessage(content='帮我列出几个AI商业案例'), AIMessage(content='语音助手、聊天机器人和对话式AI')]
'''
这种创建聊天提示的方式,在from_messages方法中参数值传入可以是多种形式,可以是一个包含 tuple 元组的 list 列表,也可以是AIMessage对象,也可以是HumanMessagePromptTemplate对象,可以根据具体使用情况灵活使用。
📌
1、from_messages方法中参数值传入可以是多种形式,可以是一个包含 tuple 元组的 list 列表,也可以是AIMessage对象,也可以是HumanMessagePromptTemplate对象
2、如果采用from_template方法创建聊天提示,则传入的模版对应的角色只能是human。
3、在类ChatPromptTemplate也存在partial方法,用法与类PromptTemplate中一样。
ChatPromptTemplate相关类介绍
创建聊天提示的主要是ChatPromptTemplate类,聊天提示除了可以用字符串创建以外,绝大多数情况下会用SystemMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate三个消息模版类组合创建,或者用角色消息SystemMessage、HumanMessage、AIMessage三个消息类组合创建。
消息模版类的操作使用与PromptTemplate基本一样。
FewShotPromptTemplate 少样本提示模版
什么是FewShot
Few-Shot(少样本)、One-Shot(单样本)和与 Zero-Shot(零样本)的概念都起源于机器学习。
在提示工程(Prompt Engineering)中,Few-Shot 和 Zero-Shot 学习的概念也被广泛应用。在 Few-Shot 学习中,模型会被给予几个示例,以帮助模型理解任务,并生成正确的响应,而 One-Shot 可以看作是一种最常见的 Few-Shot 。在 Zero-Shot 学习中,模型只根据任务的描述生成响应,不需要任何示例。
如下请看一个例子,认识一下One-Shot(单样本)和与 Zero-Shot(零样本)
在公园里有一个妈妈在教她的女儿拼图。小女孩一直找不到正确的位置,几次尝试后就显得有些沮丧。
妈妈说:“亲爱的,你需要耐心!”
女儿问:“妈妈,什么是耐心?”
妈妈指向旁边一个正在耐心给花园浇水的园丁说:“你看那位叔叔,他慢慢地给每一株植物浇水,从不急躁,这就是耐心,你也得慢慢来,一块一块地找到拼图的正确位置。”
这位妈妈通过实际的例子给女儿展示了什么是耐心,这是一种 One-Shot 学习。
如果她的女儿第一次听到“耐心”就明白什么含义,这就叫 Zero-Shot,表明这孩子的天赋不是一般的高,从知识积累和当前语境中就能够知道新词的含义。有时候我们把 Zero-Shot 翻译为“顿悟”,聪明的大模型,某些情况下也是能够做到的。
少样本示例的几篇论文
对于 Few-Shot Learning,一个重要的参考文献是 2016 年 Vinyals, O. 的论文《小样本学习的匹配网络》。这篇论文提出了一种新的学习模型——匹配网络(Matching Networks),专门针对单样本学习(One-Shot Learning)问题设计,而 One-Shot Learning 可以看作是一种最常见的 Few-Shot 学习的情况。
对于 Zero-Shot Learning,一个代表性的参考文献是 Palatucci, M. 在 2009 年提出的《基于语义输出编码的零样本学习(Zero-Shot Learning with semantic output codes)》,这篇论文提出了零次学习(Zero-Shot Learning)的概念,其中的学习系统可以根据类的语义描述来识别之前未见过的类。
OpenAI 在介绍 GPT-3 模型的重要论文《Language models are Few-Shot learners(语言模型是少样本学习者)》中,更是直接指出:GPT-3 模型,作为一个大型的自我监督学习模型,通过提升模型规模,实现了出色的 Few-Shot 学习性能。
Prompt 提示中的 Few-Shot 的作用和应用场景
Few-Shot 在 prompt 中的作用是通过少量样本引导模型对特定任务进行学习和执行,例如通过提供少量风格或主题示例,引导模型产出具有相似风格或主题的创作,这样可以让大模型更加理解问题,提高大模型的输出质量。
而 Zero-Shot 学习设置中,模型只根据任务的描述生成响应,不需要任何示例。
FewShotPromptTemplate 少样本提示类
FewShotPromptTemplate的继承至PromptTemplate,因此它的使用方式和PromptTemplate完全一样,只是在 FewShotPromptTemplate 上多了一些参数,例如 examples (示例)和 example_selector (示例选择器),这些参数可以在实例化模版对象的时增加示例,或者在运行时动态选择示例。
# 引入累类
from langchain import PromptTemplatefrom langchain.prompts import FewShotPromptTemplate# 定义示例examples = [ {"title": "今日份的小确幸", "content": "早上的一杯咖啡,让忙碌的生活暂时按下暂停键。在这个小小的瞬间,找到了自己的小确幸。"}, {"title": "一个人的西藏", "content": "独自一人踏上西藏之旅,每一步都是风景,每一刻都是故事。这里的蓝天白云,让我忘记了世界的喧嚣。"}, {"title": "夏日防晒必备良品", "content": "分享我这个夏天最爱的防晒霜,轻薄不油腻,让我在炎炎夏日也能享受阳光而不畏惧。"}]# 创建示例模版example_prompt = PromptTemplate( input_variables=["title", "content"], template="标题: {title}\n内容:{content}")# print(example_prompt.format(**examples[0]))# 创建 FewShotPromptTemplatefewShotprompt = FewShotPromptTemplate( examples=examples, example_prompt=example_prompt, example_separator="\n\n", prefix="想要创作出具有小红书风格的内容,请参考以下示例:", suffix="根据上述示例,尝试创作一个{user_input}。", input_variables=["user_input"])# 生成提示print(fewShotprompt.format(user_input="新的故事"))
'''
代码执行后输出内容如下:
想要创作出具有小红书风格的内容,请参考以下示例:
标题: 今日份的小确幸
内容:早上的一杯咖啡,让忙碌的生活暂时按下暂停键。在这个小小的瞬间,找到了自己的小确幸。
标题: 一个人的西藏
内容:独自一人踏上西藏之旅,每一步都是风景,每一刻都是故事。这里的蓝天白云,让我忘记了世界的喧嚣。
标题: 夏日防晒必备良品
内容:分享我这个夏天最爱的防晒霜,轻薄不油腻,让我在炎炎夏日也能享受阳光而不畏惧。
根据上述示例,尝试创作一个新的故事。
'''
上述例子是一个少样本的代码示例,LangChain 将示例单独用列表格式进行管理,然后用 PromptTemplate 生成示例提示,在代码示例中,FewShotPromptTemplate比PromptTemplate多出来的参数介绍如下:
| 参数名 | 参数说明 |
| examples (Optional[List[dict]] = None) | 要格式化的提示示例,是一个列表,具体看可以代码例子中的 examples ,它与example_selector 必须有一个存在。 |
| example_selector (Any = None) | 与examples参数起的作用一样,主要真多示例多的情况下,根据不同的规则调用合适的示例。 |
| example_separator (str = '\n\n') | examples参数提供的示例列表,在被格式化后,两个提示示例之间分隔符,默认是两个换行符。 |
| example_prompt (PromptTemplate [必需]) | 一个PromptTemplate对象,用于格式化examples或example_selector中的变量,并输出提示示例。 |
| prefix (str = '') | 在示例之前放置的提示模板字符串,这个前缀出现在所有格式化示例之前。 |
| suffix (str [必需]) | 在示例之后放置的提示模板字符串,这个后缀跟随所有格式化的示例。 |
ExampleSelector 示例选择器
ExampleSelector 的作用
ExampleSelector 是与 FewShotPromptTemplate 联合使用的,ExampleSelector的主要作用是从一个较大的示例样本库中选择最合适、最有代表性的样本来进行学习和推理,从而提高模型输出内容的质量。
ExampleSelector 四种类型选择器
| 类型名称 | 相关类 | 应用场景 |
| 按长度 | LengthBasedExampleSelector | 根据提示文本长度来选择示例 |
| 按最大边际相关性 (MMR) | MaxMarginalRelevanceExampleSelector | 从示例库中选择与输入即相关又具有多样性的示例,需要用到向量数据库 |
| 按 n-gram 重叠度 | NGramOverlapExampleSelector | 通过计算输入与示例之间n-gram(如单词、短语)的重叠度来选择最相关的示例 |
| 按相似度 | SemanticSimilarityExampleSelector | 基于语义相似性选择示例,需要用到向量数据库 |
基于长度的示例选择器 LengthBasedExampleSelector
根据示例的长度来选择示例,解决提示内容长度超出大模型处理长度。对于较长的输入,它会选择较少的示例,而对于较短输入,他会选择更多的示例。
from langchain.prompts import FewShotPromptTemplate, PromptTemplatefrom langchain.prompts.example_selector import LengthBasedExampleSelector# 创建一个包含词语及其反义词的示例集合。examples = [ {"input": "光明", "output": "黑暗"}, {"input": "快乐", "output": "悲伤"}, {"input": "上升", "output": "下降"}, {"input": "胜利", "output": "失败"}, {"input": "繁荣", "output": "衰败"},]# 定义如何将示例数据格式化为字符串的模板。example_prompt = PromptTemplate( input_variables=["input", "output"], template="词语: {input}\n反义词: {output}",)# 使用LengthBasedExampleSelector选择符合长度要求的示例。example_selector = LengthBasedExampleSelector( examples=examples, example_prompt=example_prompt, # 假设我们希望每个示例的格式化字符串长度不超过10个字符。 max_length=10,)# 创建FewShotPromptTemplate,动态地根据输入选择示例并生成提示。dynamic_prompt = FewShotPromptTemplate( example_selector=example_selector, example_prompt=example_prompt, prefix="根据词语说出反义词大赛", suffix="轮到你了,词语: {input}\n反义词:", input_variables=["input"],)print(dynamic_prompt.format(input="努力"))
上面代码中在构建LengthBasedExampleSelector实例时,通过更改max_length的大小,会直接影响到在示例提示中的数量。
LengthBasedExampleSelector的构造参数说明:
- example_prompt (PromptTemplate) [必需]: 用于格式化示例的提示模板。这个模板定义了如何将提供的示例数据通过这个提示模版转换为提示字符串。
- examples (List[dict]) [必需]: 示例列表,包含提示模板期望的所有示例。每个示例是一个字典,包含了与提示模板中定义的变量相对应的键值对。
- get_text_length (Callable[[str], int] = ): 一个函数,用于测量提示长度,默认为计算字数的函数。这个函数的目的是根据自己需要来计算提示内容的长度,例如去掉空格的字符串长度。
- max_length (int = 2048): 提示的最大长度,输入到模型中的文本总长度,长度单位是token,超过这个长度的示例会被裁剪。这个参数允许用户设置最大长度,用于处理模版生成的提示不会超过模型处理能力。
基于最大边际相关性的示例选择器 MaxMarginalRelevanceExampleSelector
MaxMarginalRelevanceExampleSelector 最大边际相关性示例选择器,可以让我们在构建少样本学习的提示模板时,确保选择的示例不仅与提问的问题高度相关,同时也尽可能地覆盖更广的信息范围,避免过度集中于某一特定类型或主题的示例。这样,即使在示例数量有限的情况下,也能最大化地利用这些示例来训练或指导大模型,提高大模型的输出质量。
📌
什么是最大边际相关性?
Maximal Marginal Relevance (MMR) 是一种在信息检索和自然语言处理中常用的策略,旨在解决当我们面对大量相关信息时,如何选择最有价值的部分呈现给用户的问题。简单来说,MMR 试图在相关性(即信息与查询的匹配度)和多样性(不同信息之间的差异)之间找到一个最佳平衡。
举个例子,如果你要组织一场关于“未来科技”的展览,并且你需要从一大堆的项目中选择几个来展示。你的目标是让参观者全方位的感受到未来科技带来的震撼。
- 从相关性进行选择:首先,你肯定想要展示那些最能代表“未来科技”主题的项目。比如,如果有一个项目是关于先进的人工智能(AI),而另一个项目是关于怎样种植更好的番茄,很明显,人工智能项目与“未来科技”的主题更加相关。
- 从多样性进行选择:但是,如果你只选择与人工智能相关的项目,那么展览就会显得单调,缺乏全面性。即使这些项目都非常优秀且紧贴主题,但整体上,它们可能覆盖的领域都很相似。因此,你可能还会选择一些关于空间探索、生物技术、可持续能源等其他领域的项目,以确保参观者能够接触到未来科技的多个方面。
这就是 MMR 策略的精髓所在,在选择要展示的项目时,MMR 会帮助你找到那些既高度相关(比如紧密贴合“未来科技”这一主题)又具有多样性(涵盖不同的未来科技领域)的项目组合。通过这种方式,你能够保证展览既丰富又全面,让参观者从多个角度了解未来科技,而不是仅仅从单一的视角。
from langchain.prompts import FewShotPromptTemplate, PromptTemplatefrom langchain.prompts.example_selector import MaxMarginalRelevanceExampleSelectorfrom langchain_community.vectorstores import FAISSfrom langchain_community.embeddings.openai import OpenAIEmbeddingsimport osexample_prompt = PromptTemplate( input_variables=["input", "output"], template="输入: {input}\n输出: {output}",)# 创建反义词任务的示例examples = [ {"input": "黑暗", "output": "光明"}, {"input": "寒冷", "output": "温暖"}, {"input": "干燥", "output": "湿润"}, {"input": "安静", "output": "喧闹"}, {"input": "平滑", "output": "粗糙"},]# 配置 OpenAI 服务OPENAI_API_KEY = os.getenv('OPENAI_API_KEY') ## 设置openai的keyOPENAI_API_BASE = os.getenv('OPENAI_BASE_URL') ## 更换为代理地址print(os.getenv("OPENAI_API_KEY"))print(os.getenv("OPENAI_BASE_URL"))example_selector = MaxMarginalRelevanceExampleSelector.from_examples( # 可供选择的示例列表 examples, # 用于生成语义相似性嵌入的嵌入类 OpenAIEmbeddings(openai_api_base=OPENAI_API_BASE, openai_api_key=OPENAI_API_KEY), # 用于存储嵌入并进行相似性搜索的VectorStore类 FAISS, # 要生成的示例数量 k=2,)mmr_prompt = FewShotPromptTemplate( # 我们提供一个示例选择器,而不是示例 example_selector=example_selector, example_prompt=example_prompt, prefix="给出每个输入的反义词", suffix="输入: {adjective}\n输出:", input_variables=["adjective"],)# 如果输入是一个情感或属性,应该首先选择相关的示例print(mmr_prompt.format(adjective="快乐"))
在上方的代码示例中,MaxMarginalRelevanceExampleSelector的构造方法参数说明如下:
- examples:这是一个列表,包含了所有可供选择的示例。每个示例通常是一个字典,包含了一组键值对。
- embeddings:embedding示例嵌入向量方式对应类实例,上方代码示例用的是OpenAIEmbeddings。
- vectorstore_cls:向量数据库对应的类,例如 FAISS。
- k:这是一个整数,指定了要从示例集合中选择的示例数量。
- input_keys(可选):这是一个字符串列表,指定了示例数据中应该考虑哪些键(字段)来进行相似性搜索,例如上方代码示例中的examples中的input字段,那么在进行相似性搜索的时候,会主要在input这个字段。
- fetch_k(可选):这是一个整数,指定了在进行重新排名(reranking)之前,初步从向量存储中检索的示例数量。
- vectorstore_kwargs(可选):这是一个字典,这些参数可以用于进一步定制向量检索的方式,例如指定搜索算法的参数。
基于相似性的示例选择器 SemanticSimilarityExampleSelector
基于语义相似性选择示例,它与MaxMarginalRelevanceExampleSelector的用法一样,如下为SemanticSimilarityExampleSelector实例代码,他与MaxMarginalRelevanceExampleSelector代码示例的区别就是类名不一样,其他的参数完全相同。
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 可供选择的示例列表
examples,
# 用于生成语义相似性嵌入的嵌入类
OpenAIEmbeddings(openai_api_base=OPENAI_API_BASE, openai_api_key=OPENAI_API_KEY),
# 用于存储嵌入并进行相似性搜索的VectorStore类
FAISS,
# 要生成的示例数量
k=2,
)
基于按 n-gram 重叠度的示例选择器
通过计算输入与示例之间n-gram(如单词、短语)的重叠度来选择最相关的示例,举例来说:
📌
n-gram,例如你在一个图书馆里寻找关于“怎样种植苹果树”的书籍,但图书馆太大,书太多,你不可能一本本查看。这时,n-gram 就像一个聪明的图书管理员,它通过检查书籍的目录和你的问题中关键词的搭配(比如“种植”和“苹果树”),快速帮你找到几本最相关的书。
from langchain.prompts import FewShotPromptTemplate, PromptTemplatefrom langchain.prompts.example_selector.ngram_overlap import NGramOverlapExampleSelector# 示例 prompt 模版example_prompt = PromptTemplate( input_variables=["input", "output"], template="输入: {input}\n输出: {output}",)# 示例列表examples = [ {"input": "See Spot run.", "output": "Ver correr a Spot."}, {"input": "My dog barks.", "output": "Mi perro ladra."}, {"input": "Spot can run.", "output": "Spot puede correr."},]# 中文提示貌似不支持example_selector = NGramOverlapExampleSelector( # 示例列表。 examples=examples, # 用于格式化示例的PromptTemplate。 example_prompt=example_prompt, # 词语重叠度,0.0-1.0区间 # 通过调整threshold在-1.0,0.0,1.0,以及0.0-1.0区间,观察示例的选择的变化 threshold=0.0,)dynamic_prompt = FewShotPromptTemplate( # 我们提供一个ExampleSelector而不是示例。 example_selector=example_selector, example_prompt=example_prompt, prefix="将输入的英语翻译成西班牙语", suffix="输入: {sentence}\n输出:", input_variables=["sentence"],)print(dynamic_prompt.format(sentence="Spot can run fast."))
📌
参数 threshold
在 NGramOverlapExampleSelector 类中用于控制示例选择的阈值。这个阈值决定了哪些示例将被选中用于进一步处理,基于它们与输入的n-gram重叠分数。n-gram重叠分数是一个浮点数,介于0.0到1.0之间,用于衡量两段文本之间的n-gram重叠度,数值越大,选择出来的示例重叠度越高。
- threshold = -1.0:默认值,所有的示例都会包含,但会根据它们与输入的n-gram重叠分数进行排序。
- threshold > 1.0:所有示例都被排除。
- threshold = 0.0:只有那些至少与输入提示有一个n-gram重叠的示例会被选中,这意味着完全不相关的示例会被排除。
举例说明
假设我们有以下输入句子和三个示例:
- 输入句子:“我喜欢吃苹果。”
- 示例1:“我不喜欢吃香蕉。”(与输入有一些词的重叠)
- 示例2:“我喜欢吃葡萄。”(与输入有较多词的重叠)
- 示例3:“太阳在东方升起。”(与输入没有重叠)
根据不同的 threshold 设置,示例的选择如下:
- threshold = -1.0:示例都包含,并根据与输入句子的n-gram重叠分数排序。因此,示例2、示例1和示例3按这个顺序被排序。
- threshold = 0.0:只包含示例1和示例2,因为它们至少与输入有一个n-gram重叠。示例3被排除,因为它与输入没有任何n-gram重叠。
四种类型选择器的区别和应用场景
| 选择器 | 场景 | 举例 |
| LengthBasedExampleSelector | 在限定提示长度前提下,尽可能多的选择示例数量 | 常规的提示,限定提问大模型的提示内容长度。 |
| MaxMarginalRelevanceExampleSelector | 示例选择的相关性和多样性 | 在为研究人员提供综述文章或文献综合分析的服务中,用户希望探索一个主题的不同方面和视角,例如,“可持续能源的最新研究趋势是什么?”此时,MaxMarginalRelevanceExampleSelector被用来选择覆盖该主题不同子领域(如太阳能、风能、生物质能源)的文献示例,确保提供给用户的信息既全面又具有多样性,避免内容的单一化。 |
| NGramOverlapExampleSelector | N-Gram词语的重叠性 | 在提供技术支持或解决具体问题的服务中,用户可能会提出非常具体的技术问题,如,“如何在Ubuntu 20.04上安装NVIDIA驱动?”在这种情况下会选择与用户问题在词汇层面上有高度重叠的技术文档或先前问答示例。这种方法确保了模型能够提供准确、针对性的操作指南,直接解答用户的具体疑问。 |
| SemanticSimilarityExampleSelector | 示例语义上的相关性 | 在心理咨询或健康问答服务中,用户可能会表达一些含糊的感受或症状,例如,“最近总是感到焦虑和失眠。”通过分析这些查询的深层语义内容,选择与用户描述在情感或症状上最相似的健康咨询示例。这允许模型以更加细腻和同理心的方式回应用户的感受,提供个性化且贴切的建议或解决方案。 |
📌
N-Gram 和相似性的区别
示例文本
- 文本A: “快乐的孩子在海边玩耍。”
- 文本B: “在海滩上,欢乐的儿童正在嬉戏。”
N-Gram分析
假设我们使用bigram(2-gram)来分析这两段文本,从相同词语重叠的角度分析:
- 文本A的部分2-grams包括:“快乐的 孩子”,“孩子 在”,“在 海边”,“海边 玩耍”。
- 文本B的部分2-grams包括:“在 海滩”,“海滩 上”,“欢乐的 儿童”,“儿童 正在”,“正在 嬉戏”。
从N-Gram的角度看,这两段文本没有共享的bigrams,因此根据N-Gram分析,它们之间的相似度可能被认为是低的。
语义相似性分析
然而,当我们从语义相似性的角度来看:
- 尽管使用了不同的词语(如“快乐的”与“欢乐的”,“孩子”与“儿童”,“海边”与“海滩”,“玩耍”与“嬉戏”),两段文本都表达了一个非常相似的场景:快乐的小孩在海边玩耍。
- 一个深度学习模型,如基于BERT的语义相似性分析工具,能够识别这两段文本在意义上的高度一致性。这是因为这样的模型能够理解词语的同义关系和上下文中的语义内容。
结论
尽管N-Gram分析显示文本A和文本B在表面结构上的相似度很低(几乎没有重叠的bigrams),语义相似性分析却能够揭示出两者在深层意义上的强烈相似性。这个例子展示了N-Gram分析和语义相似性分析在文本处理上的根本区别:前者依赖于表面的字词结构,而后者深入到语义层面,理解文本的真正含义。
PipelinePromptTemplate 多个模版合并为一个提示词
LangChain 的prompt 提示模版的好处
代码的可读性:使用模板的话,提示文本更易于阅读和理解,特别是对于复杂的提示或多变量的情况。
可复用性:模板可以在多个地方被复用,让你的代码更简洁,不需要在每个需要生成提示的地方重新构造提示字符串。
维护:如果你在后续需要修改提示,使用模板的话,只需要修改模板就可以了,而不需要在代码中查找所有使用到该提示的地方进行修改。
变量处理:如果你的提示中涉及到多个变量,模板可以自动处理变量的插入,不需要手动拼接字符串。
参数化:模板可以根据不同的参数生成不同的提示,这对于个性化生成文本非常有用。
概念介绍
Models 模型
LLMs 模型
LLM(Large Language Model),大语言模型,在这里指的LangChain封装的LLM核心组件,指的是纯文本补全模型。Langchain封装的 API 将字符串提示作为输入,输出为补全后的字符串。例如对接的OpenAI 的 GPT-3。
ChatModels 聊天模型
聊天模型是LangChain封装的基于 LLM 的对话聊天模式核心组件,LangChain封装的 API 与LLM不同。Chat Model是将聊天对话消息表作为输入,输出的是 AI 消息,而不是字符串。例如对接的GPT-4 和 Anthopic 的 Claude-2 。
不同大模型在与其对话的时候有不同的提示策略,与Anthropic对话输入提示用XML效果最好,而OpenAI用JSON效果。这意味着用于一个LLM大模型的提示词可能不会转移到其他模型,因为转移后的回答效果可能会变差。LangChain提供了许多默认提示,目前大多数提示在 OpenAI 上运行良好,但其他模型上不一定,也没有进行大量测试。
Messages 消息
在LangChain中,ChatModel 将消息(Messages)作为输入和返回的数据格式(在OpenAI中,消息就是一个json数组),消息中每个对象都包含两个基本属性:角色(role)和内容(content),以及一个可选的属性additional_kwargs,这个additional_kwargs属性主要提供不是常规的输入参数,例如OpenAI的function_call函数,角色(role)对应的就是user(用户发送的问题)、system(系统级提示)、assistant(AI回答内容)。
messages = [
SystemMessage(content="You are Micheal Jordan."),
HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
Message中主要的Python类:
HumanMessage
用户发送的消息。
SystemMessage
系统消息,与用户发送的消息一起作为输入内容,用于设定让LLM回答的时候按照一定的规则要求输出,部分大模型不支持。
AIMessage
LLM输出消息,即回答的内容。它可以作为输入传递给其他工具或模型,以进一步处理或生成响应。例如,一个AIMessage可以包含一个问题,然后传递给另外一个回答问题的工具,以获取答案。
FunctionMessage
工具输出消息,它包含了工具执行的函数调用信息。FunctionMessage中的function_call字段描述了工具执行的函数名称和参数。FunctionMessage可以作为输入传递给其他工具或模型,以执行特定的功能。例如,一个FunctionMessage可以包含一个文件移动工具的函数调用,将文件从一个位置移动到另一个位置。
ToolMessage
工具调用结果消息,它包含了工具执行的结果信息。ToolMessage中的too_call_id字段表示调用工具的唯一标识符。ToolMessage可以用于跟踪工具调用的状态和结果。例如,一个ToolMessage可以包含一个文件移动工具的调用结果,指示文件是否成功移动。
Prompts 提示
用户询问大模型(例如chatGPT)的问题内容就是提示。在ChatGPT平台上我们是直接输入内容的,但是在开发AI应用的时候,用户输入的内容未必就是直接传给ChatGPT,而是经过AI应用的转换(转换的过程中我们会增加更多的提示内容,例如系统级提示)。
在LangChain中,LangChain提供一系列管理提示的功能组件,用于指导LLM生成相关的输出。Prompt可以是一个问题、一句话、一段文字或一组指令,旨在引导LLM生成特定的响应或完成特定的任务。
Prompt在语言模型中起到了重要的作用,它可以帮助模型理解上下文、生成相关的回答、完成句子或参与对话。通过提供清晰、明确的Prompt,可以引导模型生成更准确、相关的输出。
Message中主要的Python类:
PromptValue
用于将用户输入内容转换为字符串(适用于LLMs),也可以转换为消息列表(适用于Chat Models)。
prompt_value = PromptValue("欢迎关注我的公众号秋水札记。")
# LLMs
text_input = prompt_value.to_string()
# ChatModel
chat_input = prompt_value.to_messages()
PromptTemplate
用于将用户输入格式化为适合模型处理的字符串消息。
prompt_template = PromptTemplate("你好,{name}。")
formatted_text = prompt_template.format(name="秋水札记")
MessagePromptTemplate
基于PromptTemplate的扩展,用于生成具有特定角色(如system或user)的消息。
# 创建基本的提示模板
basic_template = PromptTemplate("欢迎关注我的公众号{gzh}。")
# 定义用户消息模板
user_message_template = MessagePromptTemplate(role="user", template=basic_template)
# 生成用户消息
user_message = user_message_template.format(gzh="秋水札记")
- HumanMessagePromptTemplate
生成用户输入的消息。
basic_template = PromptTemplate("欢迎关注我的公众号{gzh}。")
human_message_template = HumanMessagePromptTemplate(template=basic_template)
human_message = human_message_template.format(gzh="秋水札记")
- SystemMessagePromptTemplate
生成系统级(system)消息。
basic_template = PromptTemplate("欢迎关注我的公众号{gzh}。")
system_message_template = SystemMessagePromptTemplate(template=basic_template)
system_message = system_message_template.format(gzh="秋水札记")
- AIMessagePromptTemplate
AI回复的内容封装成AI类型的消息,用于识别消息列表中每条消息的类型。
basic_template = PromptTemplate("我是一个秋水札记的AI助手,非常高兴为你提供帮助。")
ai_message_template = AIMessagePromptTemplate(template=basic_template)
ai_message = ai_message_template.format()
MessagesPlaceholder
用作在对话消息列表中的一个占位符,它允许在动态地引入一系列之前的消息,即该会话的历史记录。这些消息可以是用户发送的、AI生成的,或是系统消息。
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("You are a nice chatbot having a conversation with a human."),
# 指定一个变量名为 "chat_history",这个变量名将在后续的对话中用来存储历史聊天消息。
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{input}")
]
)
ChatPromptTemplate
生成完整聊天对话消息列表,包括多个不同类型的消息和占位符。
# 定义消息列表
chat_template = ChatPromptTemplate.from_messages(
[
("system", "你是公众号的AI助手,你的名称叫{name}."),
("human", "你可以做什么?"),
("ai", "我可以帮你查询公众里的内容"),
("human", "{user_input}"),
]
)
# 格式化数据
formatted_messages = chat_template.format_messages(name="秋水札记", user_input="LangChain如何快速入门?")
Output Parsers 输出解析器
模型的输出要么是字符串,要么是消息,输出解析器用于接收模型的返回结果,并格式化成我们需要的数据格式,便于我们后期我们继续使用,例如:JSON、XML、CSV、DateTime、枚举等
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈

对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)
👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)
👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;

• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
CSDN粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以扫描下方二维码&点击下方CSDN官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉CSDN大礼包:《最新AI大模型学习资源包》免费分享 👈👈