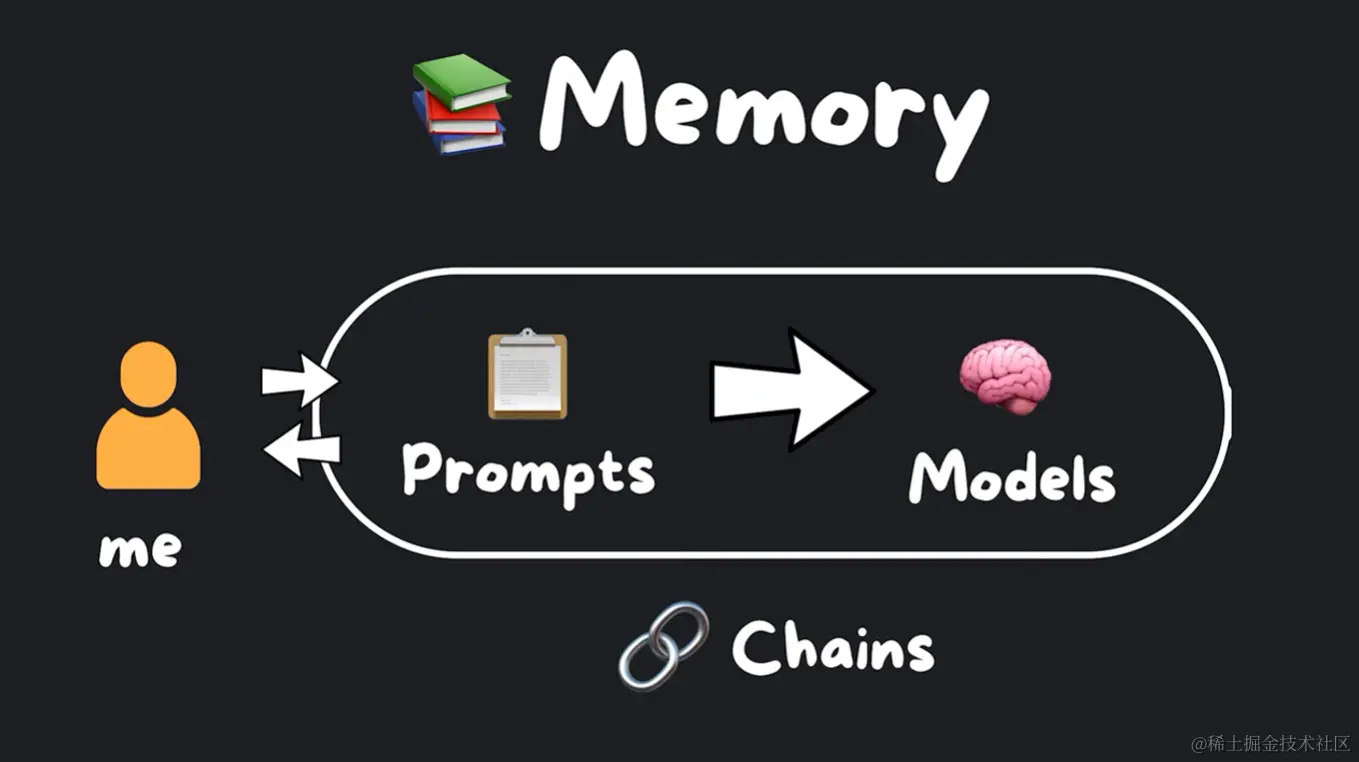
上节课,我我为您介绍了LangChain中最基本的链式结构,以及基于这个链式结构演化出来的ReAct对话链模型。
今天我将由简入繁,为大家拆解LangChain内置的多种记忆机制。本教程将详细介绍这些记忆组件的工作原理、特性以及使用方法。
①人工智能/大模型学习路线
②AI产品经理资源合集
③200本大模型PDF书籍
④超详细海量大模型实战项目
⑤LLM大模型系统学习教程
⑥640套-AI大模型报告合集
⑦从0-1入门大模型教程视频
⑧LLM面试题合集
历史对话全带上,记忆居然如此低级
随着大模型的发展,语言模型已经能够进行逻辑自洽的对话。但是与人类智能相比,机器对话仍然存在短板,其中一个重要因素就是“记忆力”的缺失。何为记忆力?简单来说,就是机器需要能够记住之前的上下文和知识,并运用这些“记忆”,使对话更加流畅合理。
ConversationBufferMemory是LangChain中最基础的记忆组件。它的工作原理非常简单:将对话历史缓存到一个队列中,并提供接口获取历史对话。
这种缓存机制实现了最基本的对话“记忆”功能。当用户询问之前提到的问题时,ConversationBufferMemory可以查找相关记忆,从而使机器人的回答更加连贯合理。
# 导入所需的库
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory
# 初始化大语言模型
# 大模型定义
api_key = ""
api_url = ""
modal= "baichuan"
llm = OpenAI(model_name=modal,openai_api_key=api_key,openai_api_base=api_url,temperature=0.0)
# 初始化对话链
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferMemory()
)
# 第一天的对话
# 回合1
conversation("我姐姐明天要过生日,我需要一束生日花束。")
print("第一次对话后的记忆:", conversation.memory.buffer)
# 回合2
conversation("她喜欢粉色玫瑰,颜色是粉色的。")
print("第二次对话后的记忆:", conversation.memory.buffer)
# 回合3 (第二天的对话)
conversation("我又来了,还记得我昨天为什么要来买花吗?")
print("/n第三次对话后时提示:/n",conversation.prompt.template)
print("/n第三次对话后的记忆:/n", conversation.memory.buffer)
如以上代码和执行结果所示,ConversationBufferMemory会将所有的对话历史存储在buffer中,开发者可以通过’conversation.memory.buffer’,访问最近的对话历史。然后基于这些历史信息进行后续处理,从而实现机器人的“记忆”功能,执行结果截图如下:

{kind=link}
这种Remember Everything的全历史记忆策略非常简单直接,但是同时也存在一些问题:
- 记忆容量有限,长对话下容易撑爆内存
- 对话噪声也全部记住,降低有效信息密度
所以这只是一个低级的记忆实现,我们还需要更智能的记忆机制,为了解决容量有限及,token耗费过高的问题,Langchain提供了时间窗口记忆组件。
容量有限?试试窗口记忆
既然全历史记忆有容量限制问题,那么可以试试只记住部分重要的对话片段。
ConversationBufferWindowMemory实现了基于时间窗口的记忆策略。
它与全历史缓存的差别在于,只维护一个滑动时间窗口,例如最近5轮对话。超出这个窗口的历史对话将被移出缓存。
# 导入所需的库
from langchain.llms import OpenAI