从 GPT3 到 ChatGPT、从GPT4 到 GitHub copilot的过程,微调在其中扮演了重要角色。什么是微调(fine-tuning)?微调能解决什么问题?什么是 LoRA?如何进行微调?
本文将解答以上问题,并通过代码实例展示如何使用 LoRA 进行微调。微调的技术门槛并不高,如果微调的模型规模不大 10B 及 10B 以下所需硬件成本也不高(10B模型并不是玩具,不少生产中会使用10B的模型),即使非专业算法同学,也可动手尝试微调自己的模型。
除了上面提到的 ChatGPT、GitHub copilot产品,微调可以做的事情还非常多。如针对特定任务让模型编排API(论文:GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction)、模拟特定人的说话方式(character.ai 产品,目前估值10亿美元)、让模型支持特定语言,还有B站上各种 stable diffusion 炼丹教程,都用到了微调技术。
微调是利用已经训练好的模型(通常是大型的预训练模型)作为起点,在新的数据集进一步训练模型,从而使其更适合特定的应用场景。本文介绍 fine-tuning 的概念与过程,并对一个微调的过程代码进行分析。
一、什么是 fine-tuning
GPT-3 使用大量互联网上的语料,训练完成后,并不适合对话这个场景。如给到 GPT3 输入“中国的首都是哪里?” GPT3 基于训练后的模型的参数进行推理,结果可能是“美国的首都是哪里?”。
训练数据中,这两句话一起出现的概率非常高,在GPT3的训练预料里面可能也会出现多次。但这种输出明显不满足 ChatGPT 的场景。还需要多阶段的优化过程使 ChatGPT 更擅长处理对话,并且能够更好地理解和回应用户的需求。
CPT3 模型的微调过程包括几个关键步骤:
1.在大规模文本数据集上进行预训练,形成基础的语言能力(GPT3)。
2.通过监督微调,让模型适应对话任务,使其生成的文本更符合人类对话习惯。
3.使用基于人类反馈的强化学习(使用用户反馈数据,如赞踩、评分),进一步优化模型的输出质量,使其在多轮对话中表现得更连贯和有效。
4.通过持续的微调和更新,适应新需求并确保输出的安全性和伦理性。
后续会对上述步骤中的一些概念如监督微调、强化学习做介绍,在开始之前,先分析微调能起到什么作用。
1.1. 为什么要 fine-tuning
1.1.1. 微调可以强化预训练模型在特定任务上的能力
1.特定领域能力增强:微调把处理通用任务的能力,在特定领域上加强。比如情感分类任务,本质上预训练模型是有此能力的,但可以通过微调方式对这一能力进行增强。
2.增加新的信息:通过微调可以让预训练模型学习到新的信息,比如常见的自我认知类的问题:“你是谁?”“你是谁创造的?”,这类问题可通过微调让模型有预期内回答。
1.1.2. 微调可以提高模型性能
1.减少幻觉:通过微调,可以减少或消除模型生成虚假或不相关信息的情况。
2.提高一致性:模型的输出一致性、稳定性更好。给模型一个适度的 temperature ,往往会得出质量高更有创造性的结果,但结果是每次输出内容都不一样。这里的一致性和稳定性,是指虽每次生成内容不同,但质量维持在一个较高的水平,而不是一次很好,一次很差。
3.避免输出不必要的信息:比如让模型对宗教作出评价,模型可以委婉拒绝回复此类问题。在一些安全测试、监管审查测试时,非常有用。
4.降低延迟:可通过优化和微调,使用较小参数的模型达到预期效果,减少模型响应的延迟时间。
1.1.3. 微调自有模型可避免数据泄漏
1.本地或虚拟私有云部署:可以选择在本地服务器或虚拟私有云中运行模型,自主控制性强。
2.防止数据泄漏:这点对于一些公司来说非常重要,不少公司的核心竞争优势是长年积累的领域数据。
3.安全风险自主可控:如果微调使用特别机密的数据,可自定义高级别的安全微调、运行环境。而不是把安全问题都委托给提供模型推理服务的公司。
1.1.4. 使用微调模型,可降低成本
1.从零创造大模型,成本高:对大部分公司而言,也很难负担从零开始训练一个大模型的成本。meta最近开源的 llama3.1 405B模型,24000张H100集群,训练54天。但在开源模型之上进行微调,使用一些量化(减少精度)微调方式,可以大大降低门槛,还可以得到不错的效果。
2.降低每次请求的成本:一般而言,相同的性能表现,使用微调的模型与通用模型比,模型的参数量会更少,成本也就更低。
3.更大的控制权:可以通过模型参数量、使用的资源,自主平衡模型性能、耗时、吞吐量等,为成本优化提供了空间。
1.2. 一些相关概念区分
1.2.1. 基于人类反馈的强化学习(RLHF)与监督微调(SFT)
目前 OpenAI 的公开信息,ChatGPT 的主要改进是通过微调和 RLHF 来实现的。从 GPT3 到 ChatGPT,大概过程如下:预训练 → 微调(SFT) → 强化学习(RLHF) → 模型修剪与优化。强化学习与微调有什么区别?
简单来说,开发 ChatGPT 过程中,微调使模型能够生成更自然、更相关的对话,而强化学习强化学习帮助模型通过人类反馈来提升对话质量。
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是一种强化学习(Reinforcement Learning)的具体方式。
强化学习(Reinforcement Learning, RL)是一种机器学习方法,模型通过与环境的交互来学习决策策略。模型在每一步的选择中会得到奖励或惩罚,目标是最大化长期的累积奖励。在自然语言处理(NLP)中,强化学习可以用于优化模型的输出,使其更符合期望的目标。
SFT(Supervised Fine-Tuning,监督微调)是一种微调的类型。如果按照是否有监督,还有无监督微调(Unsupervised Fine-Tuning,在没有明确标签的情况下,对预训练模型进行微调)、自监督微调(Self-Supervised Fine-Tuning,模型通过从输入数据中生成伪标签(如通过数据的部分遮掩、上下文预测等方式),然后利用这些伪标签进行微调。)
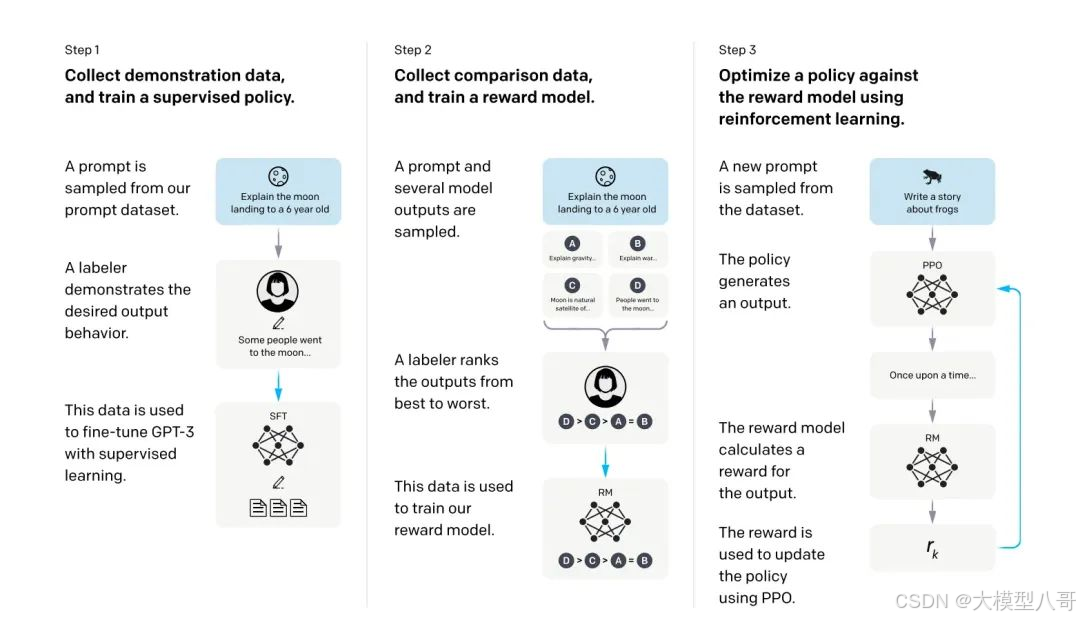
图片来自OpenAI 论文:Training language models to follow instructions with human feedback
在ChatGPT的训练中,OpenAI使用了一种称为通过人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)的方法。RLHF流程通常包括以下几个步骤:
1.初始模型生成:使用监督学习训练初始语言模型(Step1的过程),它已经能够生成合理的对话内容。
2.人类反馈:人类评审者与模型进行互动,对模型的回答进行评价,标注出哪些回答更好。Step2中的 A labeler ranks the outputs 的过程为标注员反馈的过程。
3.奖励模型训练:基于人类反馈的数据,训练一个奖励模型(Step2 中的 reward model),该模型能够根据输入的内容对模型输出进行评分。
4.策略优化:使用强化学习技术,让模型生成更高评分的输出,Step3的过程。
强化学习与微调相比,不论技术门槛、构造数据的成本、训练成本、训练时间、最终效果的不确定性,强化学习与微调都要高很多。强化学习需要使用大量人工标注的数据先训练一个奖励模型,然后需要通过大量尝试与迭代在优化语言模型。
在生产实践中,虽然强化学习也可提升具体任务表现,但对特定任务采用 SFT 的方式,往往能取得不错的效果。而强化学习成本高,非常依赖标注的数据,相对于 SFT 使用不多。
1.2.2. 继续预训练与微调
ChatGPT 的定位是一个通用场景的对话产品,在具体行业或领域内,类似 ChatGPT 的产品定位会更加细分。比如经常听到的医疗大模型、法律大模型、资金安全大模型。这种“行业大模型”不少是通过对基座继续预训练方式得到的。
继续预训练是在已经预训练的模型基础上,进一步在特定领域的数据上进行训练,以提高模型对该领域的理解和适应能力。数据集通常是未标注的,并且规模较大。
微调一般的目的在于优化模型在特定任务上的表现。微调通常是在一个小规模的任务数据集上进行的,目的是让模型在该特定任务上达到最佳表现。
两者可以结合使用,比如在安全领域内,一个特定的任务如对