建议先阅读我之前的Python数据处理以及Python专栏中的博客,掌握一定的Python前置知识后再阅读本文,链接如下:
带你从入门到精通——Python数据处理(一. 环境介绍与NumPy入门)-CSDN博客
带你从入门到精通——Python数据处理(二. NumPy中数组的基本操作)-CSDN博客
带你从入门到精通——Python数据处理(三. NumPy中数组的运算)-CSDN博客
带你从入门到精通——Python数据处理(四. Pandas入门)-CSDN博客
带你从入门到精通——Python数据处理(五. Pandas常用操作)-CSDN博客
带你从入门到精通——Python数据处理(六. Pandas中文件的读写操作)-CSDN博客
目录
七. Pandas中数据的增删改查
7.1 数据的增加
7.1.1 直接赋值
可以通过直接赋值的方式为DataFrame对象增加一列,具体示例和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [4, 5, 'b'], [7, 8, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df['col4'] = 6
df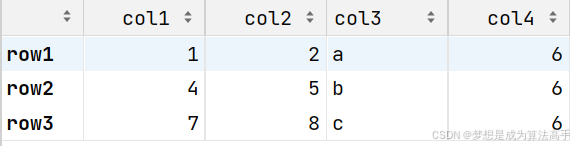
如果直接使用一个数为DataFrame对象赋值,则新增的一列全为这一个数。
还可以直接使用一列数据为DataFrame对象赋值,该列数据的行数需要与DataFrame对象的行数相同,具体示例和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [4, 5, 'b'], [7, 8, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df['col4'] = 6
df['col5'] = ['d', 'e', 'f']
df['col6'] = df['col1'] * 10
df
注意:使用直接赋值的方法为DataFrame对象增加列时,直接在原DataFrame对象上进行添加。
7.1.2 assign函数
可以使用DataFrame对象的assign函数,为DataFrame对象增加列,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [4, 5, 'b'], [7, 8, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
s = pd.Series([10, 15, 20], index=['row1', 'row2', 'row3'])
df = df.assign(col4=6, col5=['d', 'e', 'f'], col6=s)
df
注意:assign函数的形参即为新的列名,且不能加引号,实参可以传入一个数、一个列表或者一个Series对象(Series对象的行索引必须与DataFrame对象一致,否则会添加一列的NaN值)。
此外,assign函数的实参还可以是一个函数名,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [4, 5, 'b'], [7, 8, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
# 该自定义函数必须设置一个参数用于接收DataFrame对象
# 当一个DataFrame对象调用assign方法时,会自动将该DataFrame对象本身传入该自定义函数
# 该自定义函数的返回值可以为:
# 1.单个数
# 2.一组数量和DataFrame对象行数相同的数据,可以为列表、数组等
# 3.和DataFrame对象有着相同索引的Series对象
def func(df):
ret = df.index
return ret
df = df.assign(col4=lambda x:1, col5=func)
df
注意:assign函数会返回一个新的DataFrame对象。
7.2 数据的删除与去重
7.2.1 数据的删除
可以使用DataFrame对象drop方法删除数据,该方法的第一个参数接收一个列表,用于指定需要删除数据的索引值或者列名,axis参数用于指定删除行或列,默认axis=0即删除对应行,如果指定axis=1这删除对应列,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [1, 2, 'a'], [2, 4, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df = df.drop(['row1', 'row2'])
df
此外,还可以使用del关键字来删除列,但此方法是直接修改原始的DataFrame对象,而使用drop方法会返回一个新的DataFrame对象,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [1, 2, 'a'], [2, 4, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
del df['col1']
df
注意:如果使用del关键字来删除列一次只能删除一列数据。
7.2.2 数据的去重
DataFrame对象和Series对象都可以使用drop_duplicates方法进行行去重,该方法会保留原始的索引,此外,Series对象还可以使用unique方法进行行去重,但是unique方法会返回去重后的ndarray数组(即不包含索引列),而drop_duplicates方法会返回DataFrame对象或者Series对象,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [1, 2, 'a'], [2, 4, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df.drop_duplicates()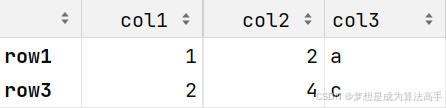
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [1, 2, 'a'], [2, 4, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df['col1'].unique()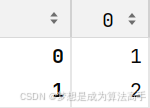
7.3 数据的修改
首先可以使用上文介绍过的直接赋值或者assign函数的方法进行数据的修改,具体使用细节和方法与数据的增加一致,只是增加数据时指定的列名需要与原DataFrame对象中已经存在的其他列的列名不一致,而修改数据时只需要指定原DataFrame对象中已经存在的一列的列名即可进行修改操作。
此外,还可以使用replace函数进行数据的修改,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [1, 2, 'a'], [2, 4, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df.replace(1, 10, inplace=True)
df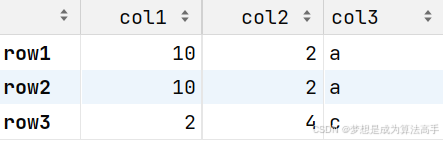
replace函数的前两个参数为被替换值和替换值,该函数会对DataFrame对象的所有值进行匹配并将所有的被替换值替换为替换值,inplace参数可以指定是否在原DataFrame对象上进行数据修改,默认为False即返回一个新的DataFrame对象,如果指定该参数为False则直接在原DataFrame对象上进行数据修改。
7.4 数据的查询
7.4.1 查询列
可以使用如下方法进行一列或者多列的查询:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [1, 2, 'a'], [2, 4, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
print(df.col1) # 查询一列, 使用该方法查询列时,列名中不能含有空格
print(df['col2']) # 查询一列
print(df[['col1', 'col2']]) # 查询多列7.4.2 查询行
进行行查询时,通常使用行索引下标切片进行查询,示例和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 'a'], [1, 2, 'a'], [2, 4, 'c']],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df[0:1]7.4.3 rank函数
DataFrame对象和Series对象都可以使用rank函数,该函数返回Series对象或者DataFrame对象中数据的行排名或列排名(排名值为浮点数)。
rank函数包含有如下6个参数:
axis:用于指定沿着哪个轴计算排名,默认为0即按行计算排名,如设置axis=1,则按列计算排名。
numeric_only:用于指定是否仅计算数字类型数据的排名,默认为False,如果设置numeric_only=True,则会丢弃有非数字类型数据的行或列后,再进行排名。
na_option:用于指定NaN值是否参与排序以及如何排序,可以使用如下参数:
'keep':NaN值不参与排序,并保留在原有位置。
'top':NaN值参与排序,并全部排在最前边。
'tbottom':NaN值参与排序,并全部排在最后边。
ascending:用于指定升序排序还是降序排序,默认为True,即升序排序。
pct:用于指定是否以对排名值进行归一化,默认False,即不进行归一化。
method:用于指定排名值的计算方式,可以使用如下参数:
'average':'average'为method参数的默认值,该计算方式中的排名值不连续,如果遇到相同数值,它们的排名值相同,都为它们排名名次的平均值。
'min':该计算方式中的排名值不连续,如果遇到相同数值,它们的排名值相同,都为它们排名名次的最小值。
'max':该计算方式中的排名值不连续,如果遇到相同数值,它们的排名值相同,都为它们排名名次的最大值。
'dense':该计算方式中的排名值连续,如果遇到相同数值,它们的排名值相同,都为它们排名名次的最大值。