建议先阅读我之前的Python数据处理以及Python专栏中的博客,掌握一定的Python前置知识后再阅读本文,链接如下:
带你从入门到精通——Python数据处理(一. 环境介绍与NumPy入门)-CSDN博客
带你从入门到精通——Python数据处理(二. NumPy中数组的基本操作)-CSDN博客
带你从入门到精通——Python数据处理(三. NumPy中数组的运算)-CSDN博客
带你从入门到精通——Python数据处理(四. Pandas入门)-CSDN博客
带你从入门到精通——Python数据处理(五. Pandas中的索引、赋值、排序和运算)-CSDN博客
带你从入门到精通——Python数据处理(六. Pandas中文件的读写操作)-CSDN博客
带你从入门到精通——Python数据处理(七. Pandas中数据的增删改查)-CSDN博客
目录
八. Pandas中的缺失值处理和数据合并
8.1 缺失值处理
8.1.1 判断缺失值
判断数据中是否存在缺失值(即NaN值)可以使用df.isnull()方法和df.notnull()方法,其中df.isnull()方法会与df对象中的每个元素进行对比,如果为NaN值,则置为True,反之置为False;df.notnull()方法会与df对象中的每个元素进行对比,如果为NaN值,则置为False,反之置为True,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 3], [2, None, None], [3, 6, 9]],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
print(df.isnull())
print(df.notnull())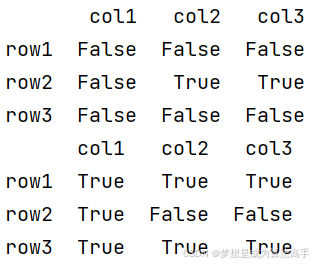
8.1.2 删除缺失值
可是使用df.dropna(axis=0)方法删除缺失值,参数axis用于指定删除行或删除列,默认为0即删除缺失值所对应的行,该方法默认会返回一个新的df对象,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 3], [2, None, None], [3, 6, 9]],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df.dropna(axis=0)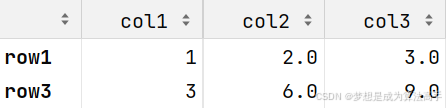
8.1.3 填充缺失值
可以使用df.fillna(val)方法填充缺失值,参数val表示用于填充缺失值的值,该方法默认会返回一个新的df对象,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 3], [2, None, None], [3, 6, 9]],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df.fillna(0)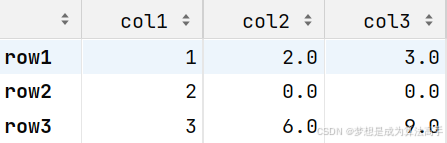
8.2 数据合并
8.2.1 concat方法
可以使用pd.concat([df1,df2],axis=0)方法完成数据的拼接,第一个参数接收一个列表表示待拼接的数据,参数axis用于指定拼接轴,默认axis=0即按行拼接,若axis=1则按列拼接,具体使用方法和输出结果如下:
import pandas as pd
df = pd.DataFrame([[1, 2, 3], [2, 4, 6], [3, 6, 9]],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
pd.concat([df, df], axis=0)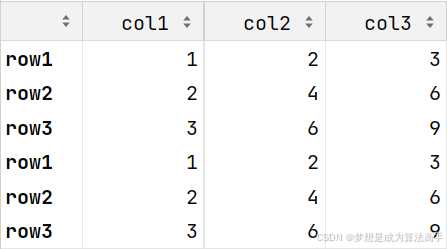
注意:按行拼接df对象时,列名相同的行直接拼接,若有列名不同的行,则拼接相应行数的NaN值;按列拼接df对象时,索引值相同的列直接平均,若有索引值不同的列,则拼接对应列数的NaN值,示例如下:
import pandas as pd
df1 = pd.DataFrame([[1, 2, 3], [2, 4, 6], [3, 6, 9]],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row3'])
df2 = pd.DataFrame([[1, 2, 3], [2, 4, 6], [3, 6, 9]],
columns=['col1', 'col2', 'col3'], index=['row1', 'row2', 'row'])
pd.concat([df1, df2], axis=1)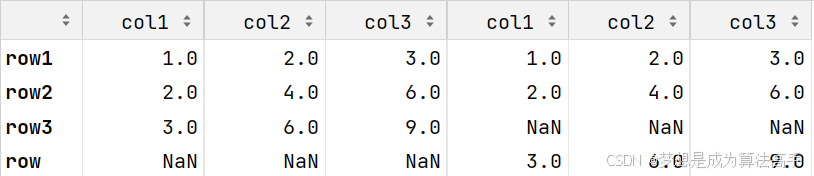
8.2.2 merge方法
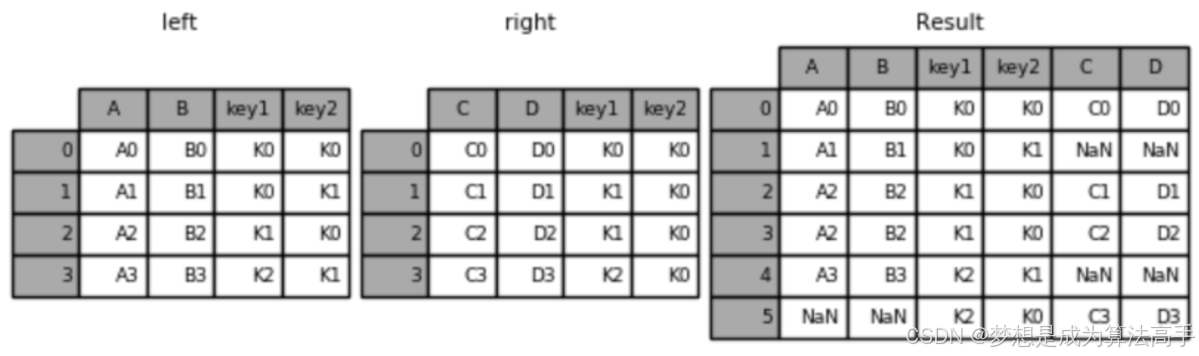
可以使用pd.merge(df1,df2,how='inner',on=None)方法完成数据的连接,默认按列进行连接,df1和df2即为参与连接的两个df对象;参数on接收一个列表,用于指定连接的共同键(列名),可以指定多个键;参数how用于指定连接方式,与SQL语句的表连接方式的对应关系如下:
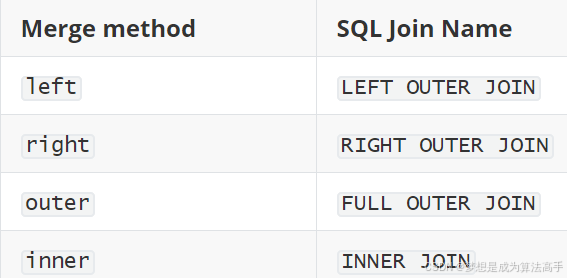
merge方法中内连接的具体使用方法和输出结果如下(后文使用相同的left对象和right对象):
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接
result = pd.merge(left, right, on=['key1', 'key2'])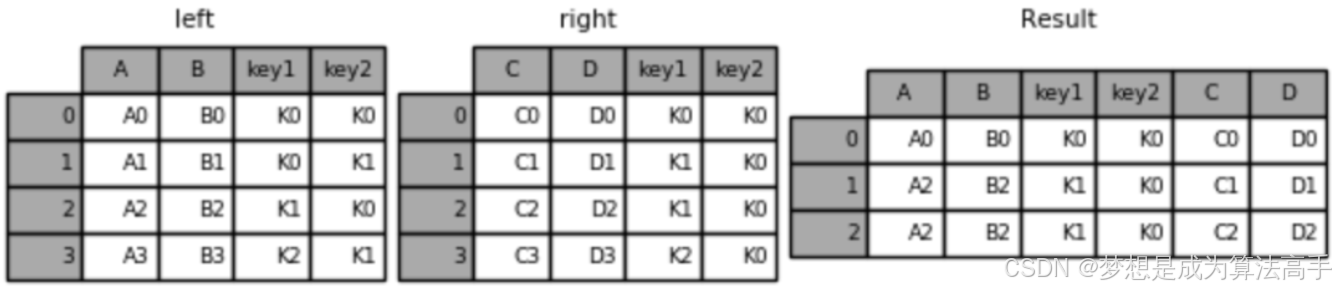
merge方法中左外连接的具体使用方法和输出结果如下:
result = pd.merge(left, right, how='left', on=['key1', 'key2'])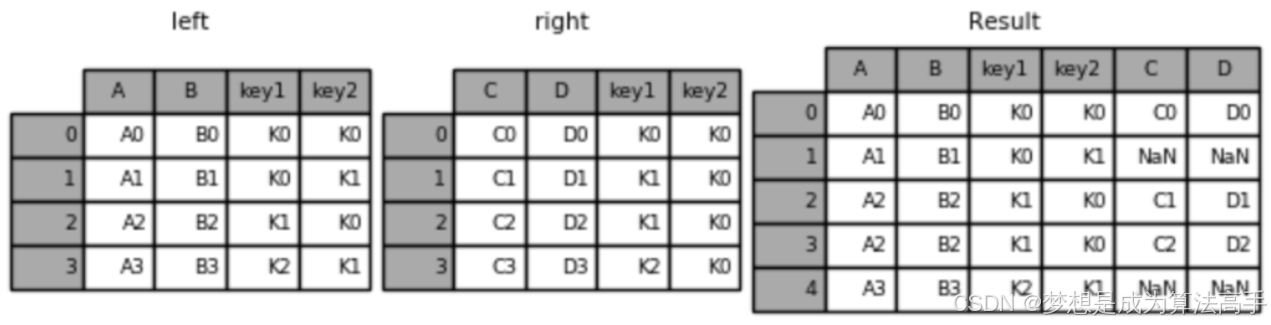
merge方法中右外连接的具体使用方法和输出结果如下:
result = pd.merge(left, right, how='right', on=['key1', 'key2'])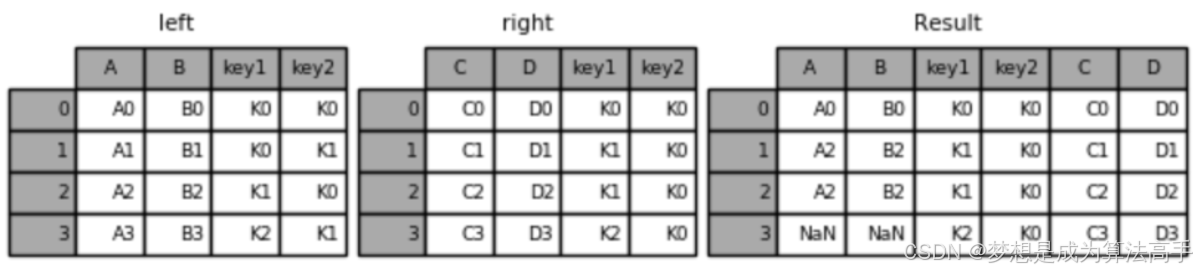
merge方法中全外连接的具体使用方法和输出结果如下:
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])